Hadoop HDFS-监控(monitor)


作者介绍:简历上没有一个精通的运维工程师,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
经过前面的介绍,我们对HDFS已经具有基本的操作能力,现在来说说每个中间件都必须要讲解的监控环节。
一、核心监控维度
服务可用性
- NameNode (NN):主/备 NN 状态、Active/Standby 切换是否正常(HA 环境下)。
- JournalNode (JN):HA 环境下,确保多数 JN 存活以保证 EditLog 同步。
- DataNode (DN):存活 DN 数量、DN 与 NN 的心跳通信状态(
hdfs dfsadmin -report)。 - ZooKeeper (ZK):若依赖 ZK(如用于 HA 故障转移或 HDFS Federation),监控 ZK 集群状态。
存储容量
- 总容量:集群物理总空间 (
DFS Capacity)。 - 已用空间:包括实际数据 (
DFS Used) 和非 DFS 使用(如临时文件、OS 占用,Non DFS Used)。 - 剩余空间 (
DFS Remaining) 及使用率百分比。 - 副本空间开销:考虑复制因子后的逻辑数据量 (
DFS Usedvs 实际物理占用)。 - 目录/用户配额使用情况 (见上节配额管理)。
文件系统元数据
- 缺失/损坏 Blocks 数 (Missing Blocks, Corrupt Blocks)。
- 待复制 Blocks 数 (Under Replicated Blocks)。
- 待删除 Blocks 数 (Pending Deletion Blocks)。
二、核心监控工具与方法
1. HDFS 内置命令
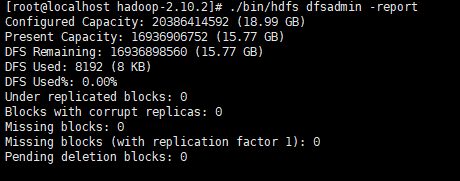
查看集群摘要、DN 状态、存储概况。
hdfs dfsadmin -report下面这里显示的全局信息。
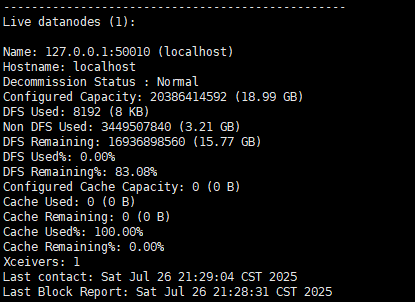
下面则是一个单机的数据节点。,如果有多个节点,这里就会显示多个节点。
检查文件系统健康,查找损坏/缺失块。
#当然这里的路径也可以更换为其他的
hdfs fsck / 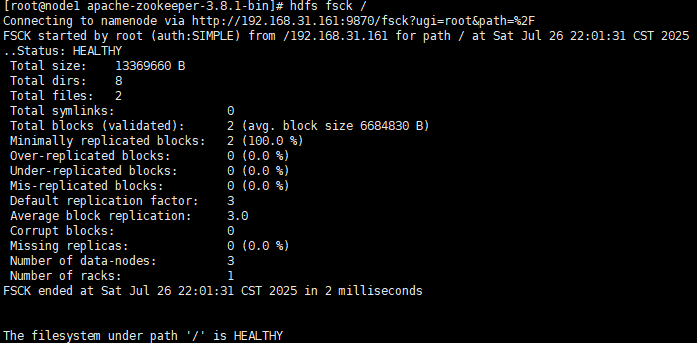
2. HDFS Web UI
- NameNode UI (默认端口 9870):
- Overview:集群总览、存储摘要、文件/块统计。
- Datanodes:所有 DN 状态、存储分布、读写流量。
- Snapshots:已创建快照列表。
- Startup Progress:NN 启动阶段耗时分析(排查启动慢)。
- Logs:直接查看 NN 日志。
3. JMX 指标 (核心监控来源)
- 访问方式:
http://<nn-host>:9870/jmx或http://<dn-host>:9864/jmx。 - 关键 MBeans:
Hadoop:service=NameNode,name=FSNamesystemState:文件系统元数据状态(文件数、块数、缺失块等)。Hadoop:service=NameNode,name=NameNodeActivity:RPC 操作统计(Ops, AvgTime, QueueLength)。Hadoop:service=NameNode,name=JvmMetrics:JVM 内存、GC、线程。Hadoop:service=DataNode,name=FSDatasetState-<uuid>:DN 存储卷状态、容量。Hadoop:service=DataNode,name=DataNodeActivity-<uuid>:DN IO 操作统计。
三、关键告警项 (必须设置)
- 服务不可用:NN/Standby NN/DN 宕机或心跳丢失。
- 存储容量:剩余空间 < 20% (或自定义阈值),配额即将耗尽。
- 块健康:
MissingBlocks> 0 或CorruptBlocks> 0 持续增长。 - 副本异常:
UnderReplicatedBlocks持续超过阈值(如 1000)。 - RPC 性能:RPC 平均响应时间 > 100ms 或 调用队列持续堆积。
- JVM 健康:堆内存使用率 > 85%, Full GC 频率过高 (> 1次/分钟)。
- 磁盘故障:DataNode 日志报告磁盘错误。
四.接入云原生
#如下这个监控
https://grafana.com/grafana/dashboards/23175-hdfs-datanode/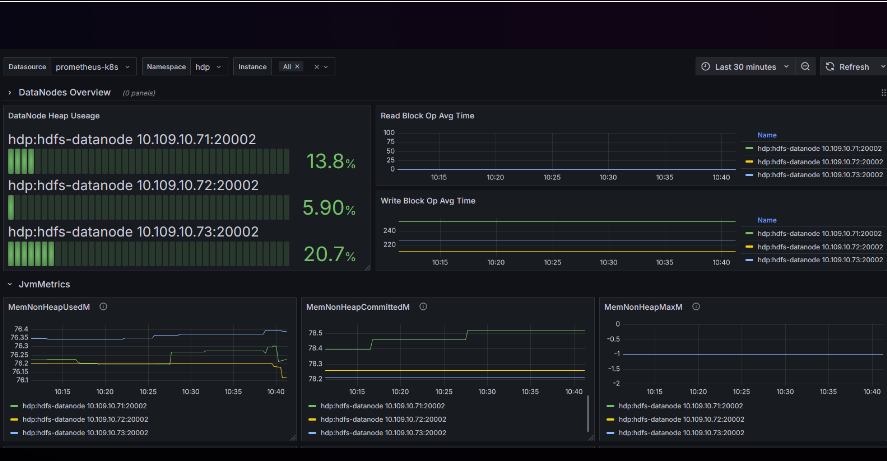
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号