如何看待多主&无主复制线性一致性


点击上方小坤探游架构笔记可以订阅哦
今天继续上一篇来聊多主复制以及无主复制实现线性一致性的问题, 其中我们要建立一个前提因素是讨论都是单值层面的复制一致性.
多主复制的线性一致性
在前面的一篇文章分布式领导者复制算法模型中, 一般在我们的异地多活架构中会采用这种复制模型, 同时我们也看到了多主复制模型的复杂度, 其中主要体现为两方面, 其一是会产生写冲突, 其二是我们的数据复制的传播路径, 即需要通过反熵来消除彼此数据中心由于Replication Lag带来的一致性问题.
有了对上述的多主复制模型的基础认知之后, 为简化模型的阐述, 同样这里采用双主复制模型来进行说明, 这个时候我们再来看, 如果这个时候一份独享数据, 并且是基于双数据中心部署架构, 那么我们能否实现线性一致性呢?
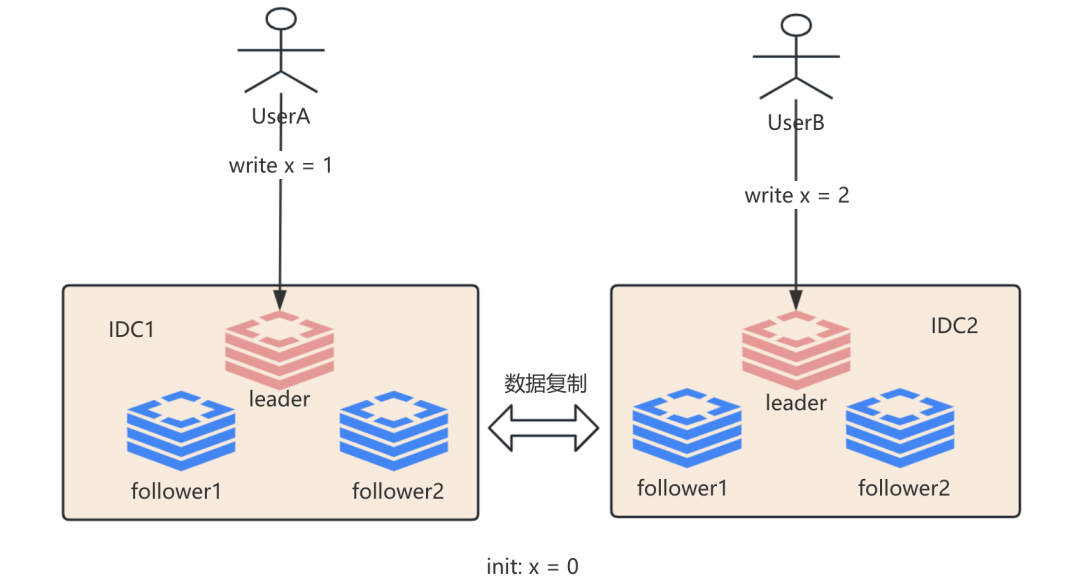
我们先看独享数据的写操作, 那么有什么样的方式呢? 首先是用户独享数据, 那么这个时候我们关注的是一个用户UserA, 假设初始化值 x = 0, 如下:
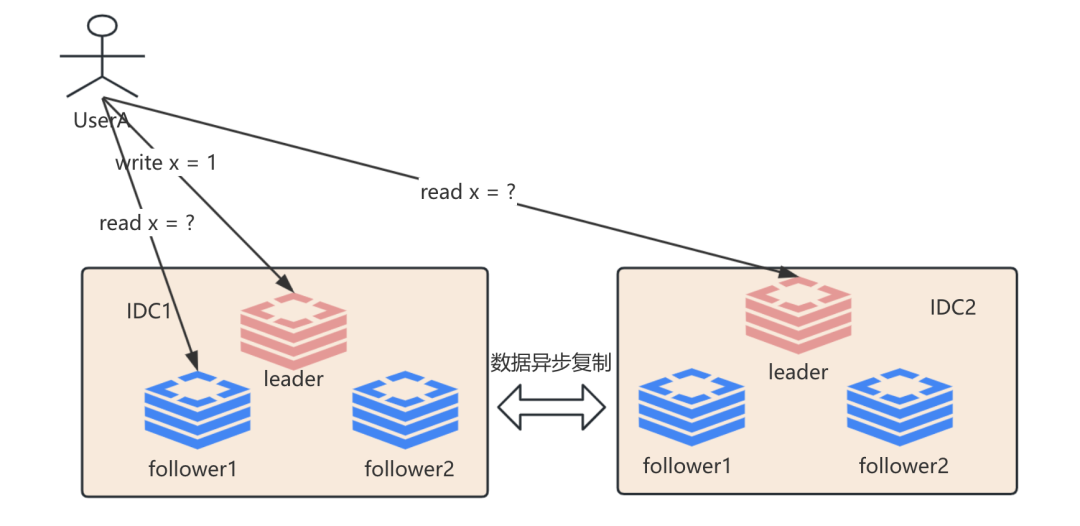
从上述的双主架构中, UserA首先向IDC1的leader节点发起write x = 1 的写操作, 这时UserA 要采用怎样的读取方式保证自己读取到 x = 1 的最新值呢?
首先, 我们先看读请求read x 到IDC2的leader节点, 能否立即读取到x = 1的最新值呢? 答案显而易见, 因为双数据中心是采用异步复制, 我们都知道异步是存在无界延迟的可能性, 因此只能实现最终一致性.
那么我们读取IDC1的follower节点呢, 这个问题又回到我们上一篇的单主复制模型策略, 如果是leader与follower是同步复制, 那么是可以的, 但是如果是异步的, 那就不一定, 只能实现最终一致性.
那么这个时候我只能从IDC1的leader节点进行读取才能保证我读取到最新的数据, 如果我们采用一个机制就是对于用户的独享数据, 我们保证读取都是在同一个数据中心的leader节点上, 那么这个时候我们称这种机制为单调写和单调读. 即通过将用户id进行哈希分散指定机器进行读写方式. 但这种方式其实也无法实现线性一致性的.
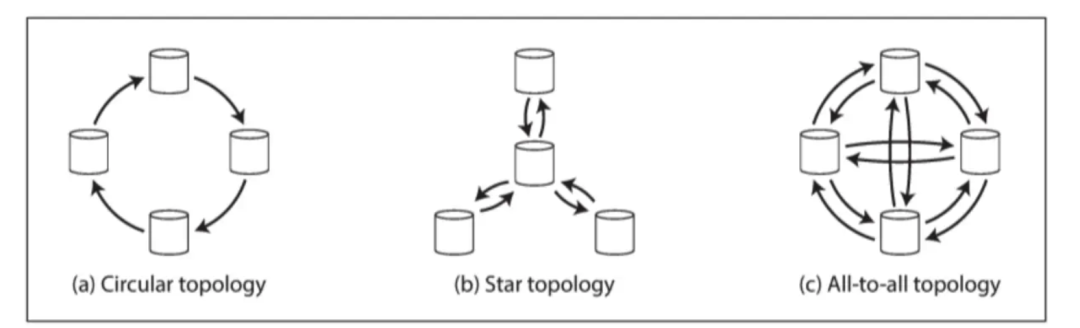
为什么呢? 我想我们都会忽略一个双主架构的本质问题, 即采用双主或者多活架构目的是应对区域性故障甚至是灾难, 那么如果我的IDC1发生故障了, 这个时候我们是可以切换到IDC2进行读取的, 但是同样的道理, 由于存在复制延迟问题, 我们只能保证最终一致性.因为我们如果把双主扩展多主模型, 那么我们的复制数据拓扑结构将会演变出以下三种拓扑模型, 这个在前面领导复制模型我们也阐述过, 即:
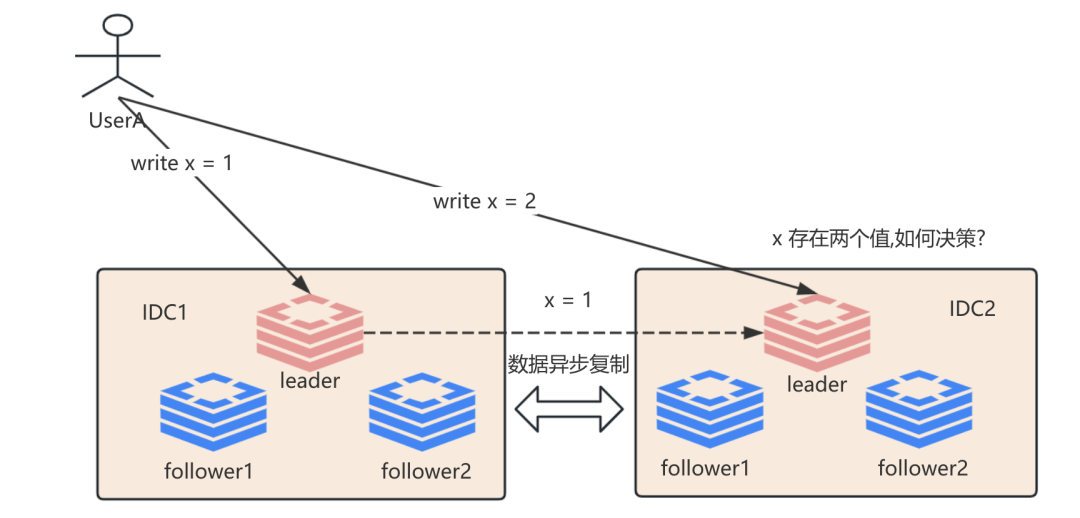
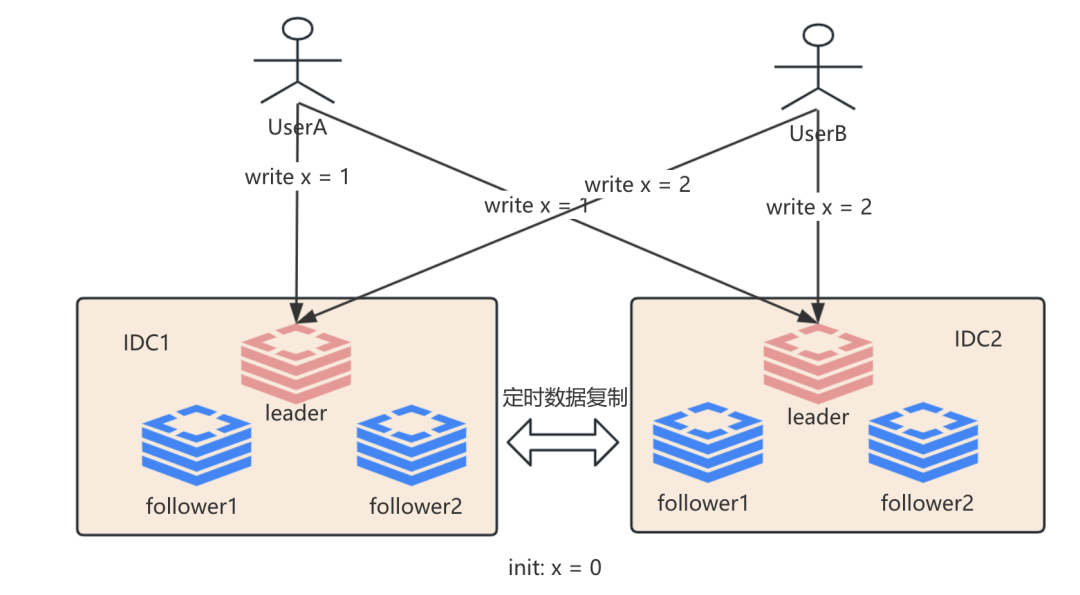
谈完多主复制模型模型之后, 我们也需要关注其本身存在的问题, 假如我不采用所谓的单调写的方式, 那么这个时候我们双主复制就会面临一个写冲突的复杂度问题, 即如果我从IDC1的leader节点写入write x = 1 之后并读取到了这个值, 这个时候又往数据中心发起 write x = 2 的操作, 此时的写操作路由到IDC2, 但是IDC2由于存在复制延迟导致x = 1 还未同步过去, 这个时候当IDC2要准备写入write x = 2的时候发现从IDC1 拉取过来 x = 1, 那么这个时候如何决策写冲突就是双主复制需要面临的问题.
关于写冲突的问题, 我们之前讨论leader复制模型聊过, 后续再做一个总结, 因为我们的无主复制模型也同样适用于多数据中心部署, 也会存在写冲突.
也许这个时候灵感一来, 咦, 我们可以采用客户端双写模式呢? 那么这个时候我们的架构就变成这样:
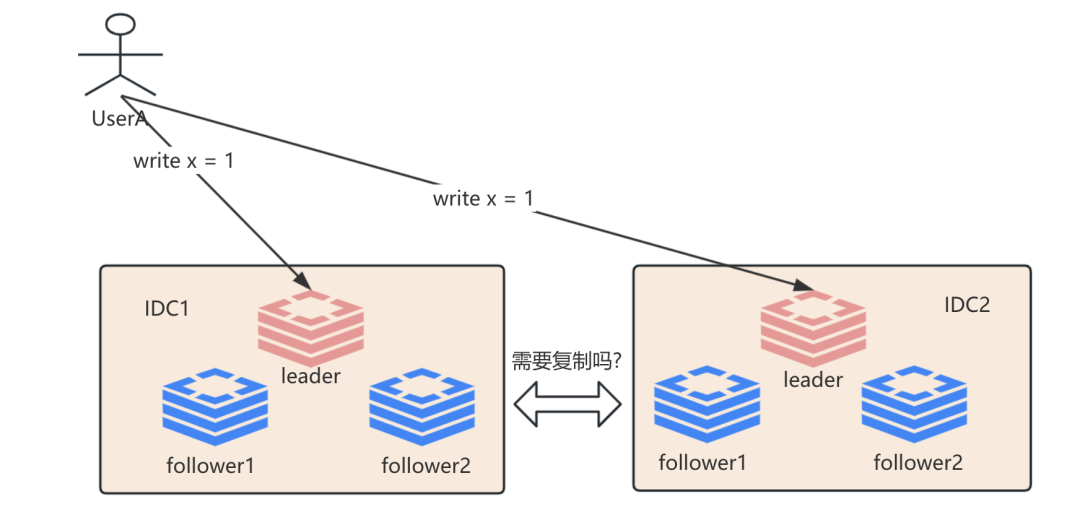
嗯,看起来好像有点那么回事.但真的是这样吗? 这个时候我们可以先问下自己, 双写过程中如果某个IDC不可用怎么办? 或者双写过程中其中一个write请求由于网络拥塞被丢弃了怎么办? 如果某个IDC不可用, 为避免双中心都不可用导致数据丢失, 那么我们一般会采用类似WAL机制记录在本地或者S3等用于后续恢复; 如果是写请求被丢弃了, 那么我们可以采用重试机制, 但重试就有可能导致数据不一致性, 那么这个时候我们就需要定时同步消除不一致性, 同样又产生了写冲突问题.
那如果是共享数据呢? 也是一样, 只能保证最终一致性, 无法保证线性一致性, 而且相比上述的独享数据, 面临的写冲突复杂度更高, 我们也可以看到共享数据的部署架构:
其实从多主复制模型可以看到, 其架构本质是高可用, 那么这个过程中我们要实现高可用就会牺牲到数据复制的强一致性, 只能满足最终的一致性.而且对于多主复制模型, 增加了写冲突以及数据复制传播消除一致性的复杂度.
无主复制的线性一致性
谈到Leaderless Replication, 我们在前面有聊过NWR机制, 那么NWR就能够线性一致性吗? 其实也是不一定的. 同样地我们按独享数据以及共享数据两个维度展开讨论.
在此之前, 我们要先了解什么是Leaderless Replication? 对于Leader Replication模型, 它本质就是客户端向leader节点发起写入请求, 然后存储系统负责将该写入操作复制到其他副本.
而对于Leaderless 则是摒弃Leader方式, 而是允许Any Replica直接接受来自客户端的写入操作, 而没有向对应的Replica发起写入操作则由写入的Replica进行异步复制保证数据最终一致. 一般有两种实现机制, 一种是客户端直接向多个Replica写入, 一种是采用一个协调者节点代表客户端来做这件事情, 在前面我们的文章分布式无领导者复制模型有介绍过, 这里不再继续阐述.
假设现在我们的存储集群有 5 个Replica, 那么这个时候我们由这 5 个Replica组成的单数据中心存储集群架构如下:
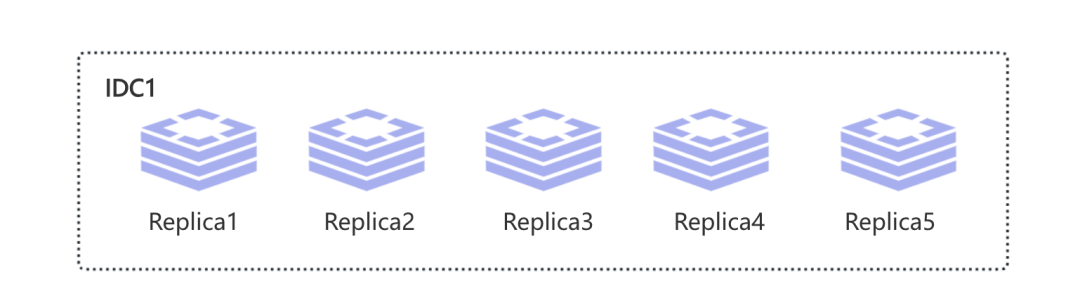
首先我们关注独享数据, 同样假设现在有UserA向存储集群发起写操作x = 1, 那么我们想让UserA 看到自己最新写入的最新数据, 这个时候有什么办法呢?
这个时候我们想是不是可以采用单调读写方式来实现线性一致性呢? 比如UserA通过hash分配到Replica2, UserB则是分配到Replica4, 那么不论是UserA还是UserB都能够看到自己最新的一份数据, 即:
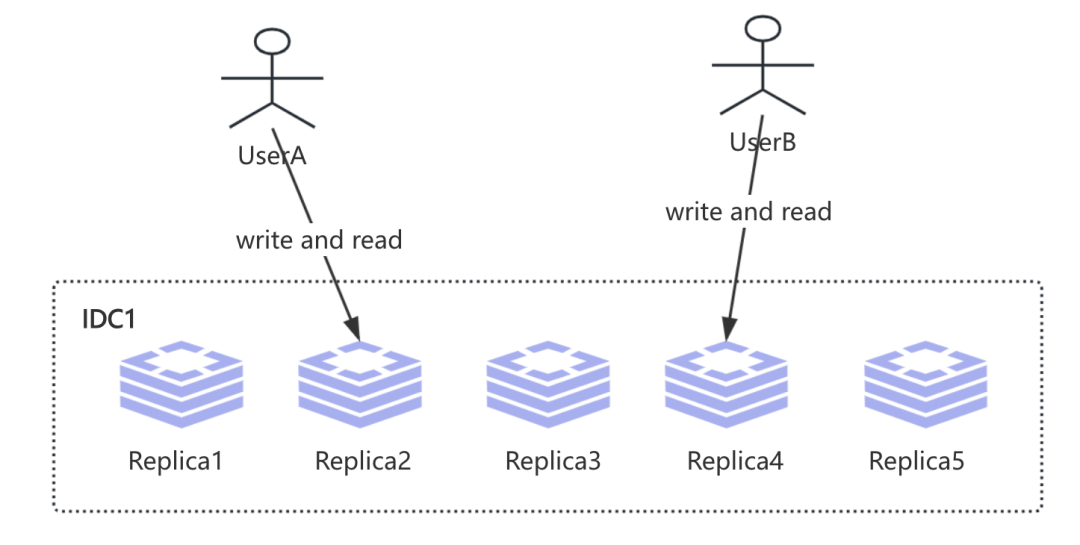
也许你已经发现上述存在的不足了, 那就是比如这个时候写入Replica2节点后不可用了咋办? 也许这个时候UserA可以路由到Replica3节点上, 这时候就变成如下:
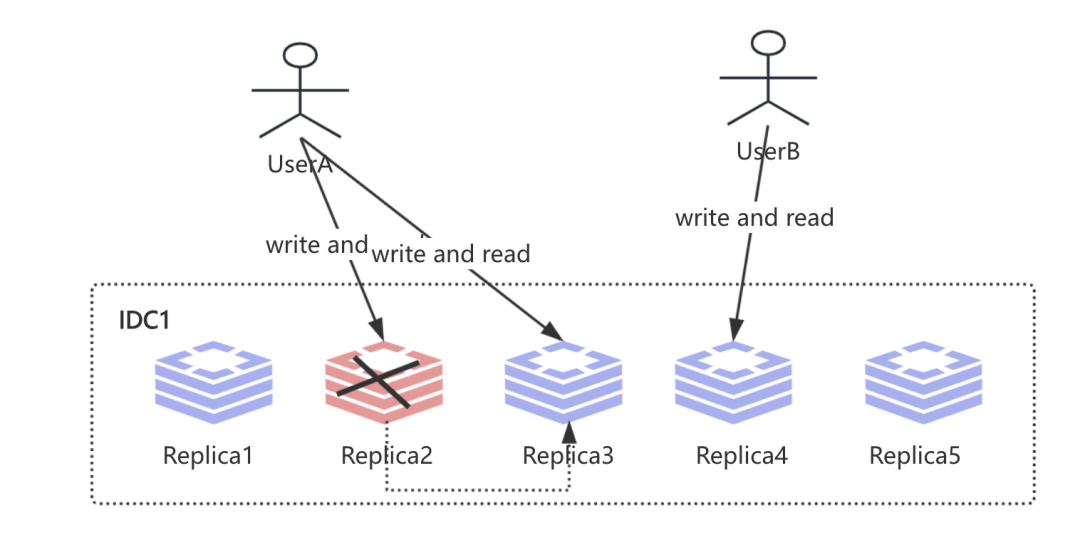
那么这个时候就无法保证线性一致性, 而如果要实现线性一致性, 采用单调读写在这种情况下就会存在单点问题.
那么如何既能保证消除单点问题又能实现我们线性一致性呢? 这个时候就是采用我们的NWR机制, 其中N代表集群的Replica副本数, 而W则代表我们客户端向集群中写入W个Replica才算成功, R就是我们要读取到多个Replica副本数据之后根据决策机制获取对应最新版本的数据返回才算成功, 即:
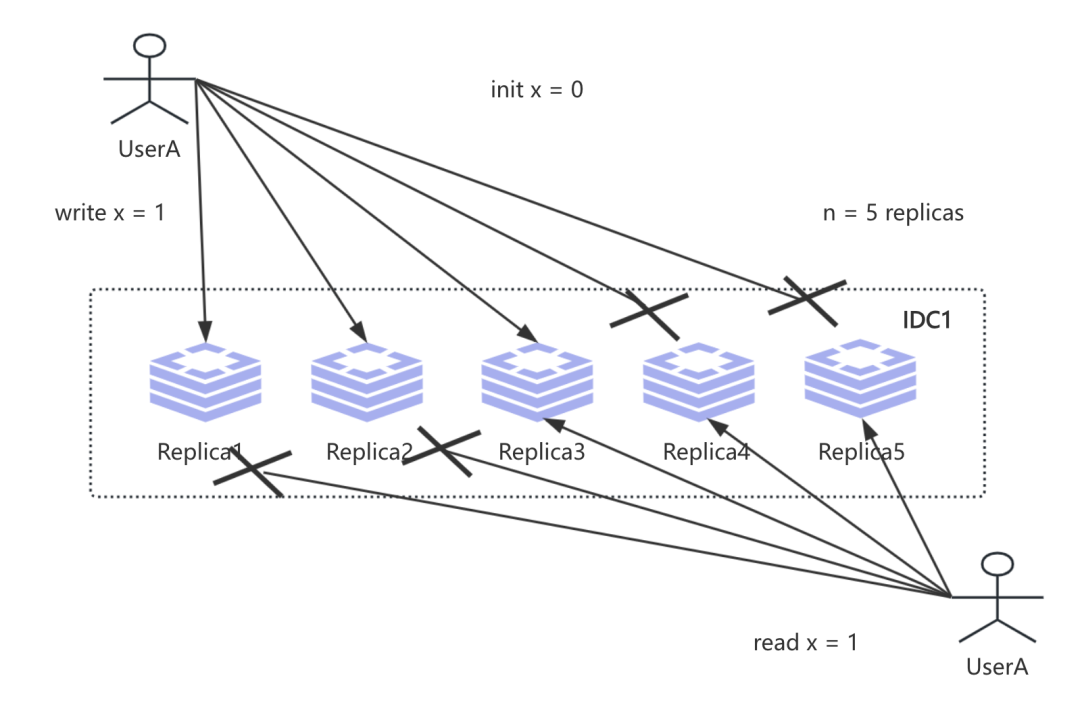
从上述我们会发现当w = 3 且 r = 3 的时候我们能够保证实现UserA看到自己最新写入的x = 1 的数据值, 同时读写都能够容忍最多两个节点不可用. 于是我们从一致性与可用性来衡量我们的NWR设置机制:
- w = 5, r = 1, 即w = n, r = 1 时, 我们能够保证UserA独享数据的线性一致性, 但我们牺牲了写性能以及可用性, 因为当其中一个Replica不可用时, 我们无法进行写入.
- w = 4, 要保证UserA独享数据的线性一致性, 那么 r 至少需要满足 r >= 2, 由此我们可以推导出如果我们要写入 w 个Replica, 那么为保证实现线性一致性, 那么r 至少满足为n - w + 1, 于是我们可以得出 w + r > n 的时候我们可以实现UserA的独享数据线性一致性.
这个时候基于Quorums的W + R > N 机制能够实现线性一致性前提下, 我们存储集群中允许容忍的故障节点数将满足:
- W = N 的时候无法保证写入的可用性, 它是一个单点写入问题.
- R = N 的时候无法保证读取的可用性, 它也是一个单点读取问题.
一般我们最常见就是设置W = R = (N + 1) / 2 向上取整, 并且是将我们的N 设置为奇数, 但实际业务场景会根据我们对于读写故障的容忍来动态配置所需的W 以及 R.
这个时候我们看到Quorums算法也许是实现线性一致性最佳选择: 如果我们存储集群有N个副本,并且选择的W 和R 满足W + R > N,那么一般来说每次读取都能返回某个键最新写入的值. 这是因为写入操作涉及的节点集合与读取操作涉及的节点集合必然有重叠, 也就是说它至少有一个节点保存最新值. 它相比Leader复制模型在节点故障容忍度以及性能上会是一个更好的选择, 然而我们并没有仔细考虑其背后的问题.
架构设计最困难的点是在于异常以及错误处理场景的设计, 同样地我们需要考虑NWR机制的故障场景.由于这些故障场景也会导致我们读取到数据是旧数据而不是最新的数据. 这里我们以n = 3, w = 2, r = 2 为准来说明, 这个时候我们需要写入 2 个Replica的场景进行说明:
第一个需要考虑是同时执行读写问题, 那么这个时候UserA分别在t1时刻写入write x = 1, 此时也异步发起读取操作, 那么这个时候我们就无法知道确定读取操作返回的是最新还是旧的数据.
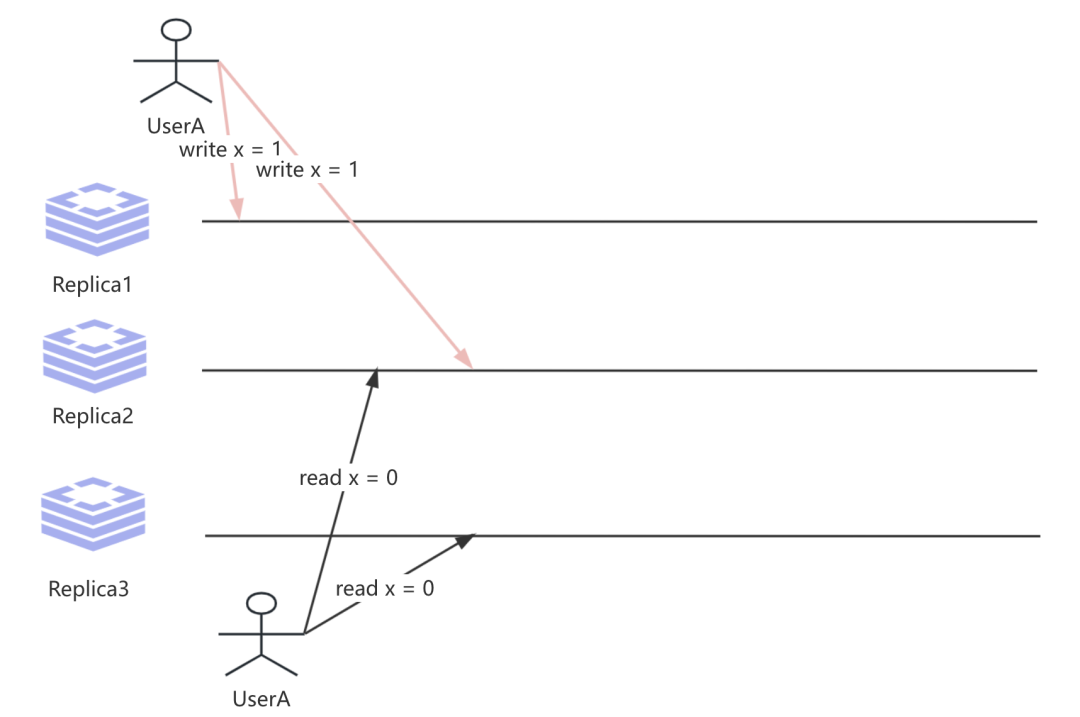
第二个需要考虑是写入最新值的Replica2节点发生故障, 但它从其他存储旧值的Replica节点中恢复数据, 又或者是向Replica2的时候写入失败, 比如磁盘已满 , 那么这个时候就间接导致 w 相比预期的携带最新值要少, 那么这个时候就会读取到旧的数据.即:
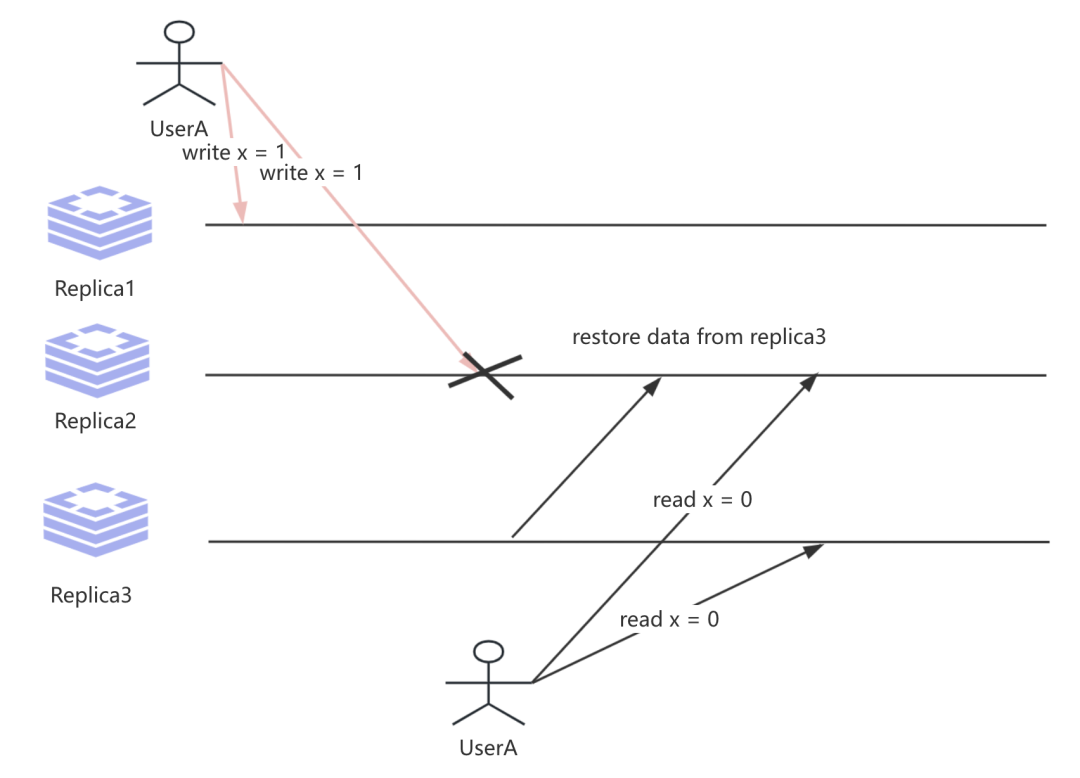
上述我们讲述的是用户独享数据基于Leaderless复制模型实现线性一致性的可能性以及存在隐藏的代价. 尽管Quorum看似能够保证读取操作返回最新的写入数据值, 但在实践中我们往往需要考虑一些故障场景并在决策与设计过程记录下来. 因此并不能将Quorums NWR机制视为实现线性一致性的绝对保证.
那么如果是共享数据呢? 且不说存在节点故障问题, 由于写入存在延迟, 比如UserA以及UserB都需要进行预订会议室R在11-12点的时间段, 那么这个时候UserB有可能看到还是旧的数据,这里我们用write x = 1 代替预订会议室R 11 - 12点时段的操作, 我们看到UserB 看见的数据值X 是旧的, 由此可见, 我们共享数据基于Qourum是无法保证线性一致性.即:
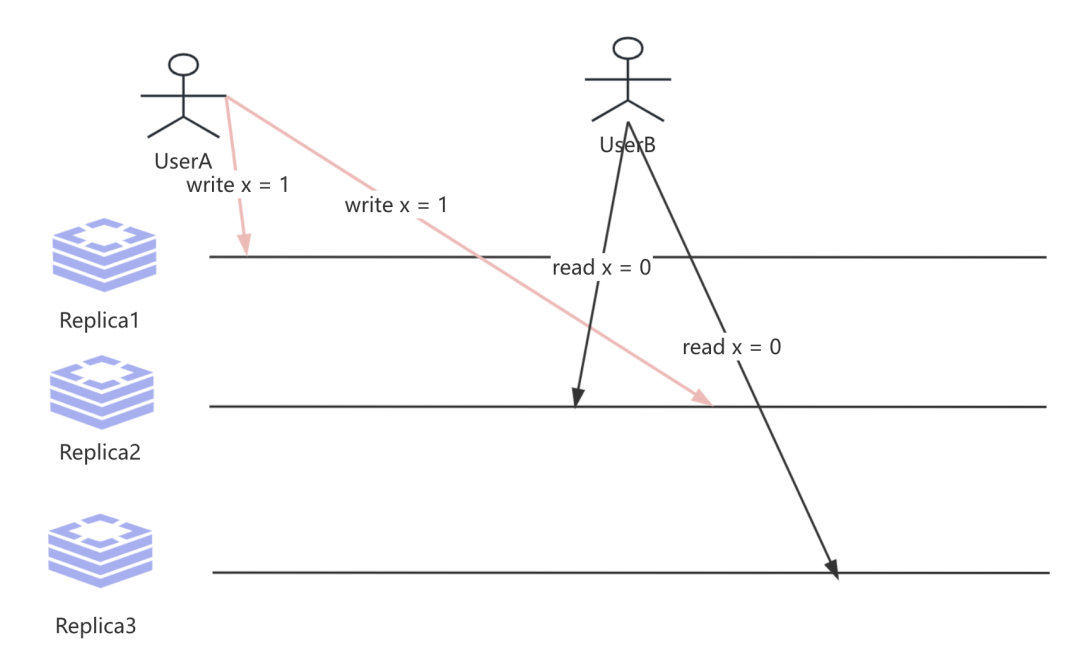
同样当我们聊到共享数据, 其实还存在一个更为复杂的问题, 那就是并发写冲突问题. 在这种情况下, 我们解决写冲突问题要么合并并发写入, 在先前我们谈多主复制模型的时候也聊到冲突的解决方案, 其本质和多主复制的问题是类似的, 后面会单独总结下写冲突问题.
Sloppy Quorums & Hinted Handoff
关于Sloppy Quorums 以及 Hinted HandOff机制, 在《Designing Data Intensive Applications》一书提到, 其实也是在阐述Quorums NWR无法完全保证线性一致性的问题. 这里我也简单阐述下.
首先我们先说说背景问题, 基于NWR机制, 我们的客户端向存储集群发起读写操作过程中, 如果我们的网络发生故障, 那么这个时候我们就会导致客户端与数据库产生大量Connection Refused的现象, 尽管这个时候数据库的Replica处于Alive状态, 但是对于客户端而言它们就像宕机一样, 在这种情况下, 我们可连接的节点数量就少于 W 或者 R , 这个时候我们的客户端就无法再满足Quorums NWR机制.
由此可见, 基于Quorums NWR机制对于故障容忍能力还有提升空间, 那么我们期望在一个大型的数据存储集群中, 其节点数量将会远多于N, 网络中断期间客户端很可能仍能连接到部分数据库节点,只是无法连接到为特定值凑齐法定人数所需的那些节点。在这种情况下,数据库设计者面临一个权衡:
- 1: 对于所有无法达到 w 或者 r 个节点的请求, 直接返回错误是否更好?
- 2: 还是说我仍然接受客户端的读写请求, 并将数据写入到一些可连接但并不属于客户端通常存储的N个节点中的其他节点呢?
对于解决方案2, 我们称之为Sloppy Quorums, 即读写操作仍然需要w 以及 r 个成功响应, 但这些响应可能来自并非某个值指定的N 个“归属”节点中的节点. 注意到上述说的是网络故障中的写操作场景.
怎么理解呢? 这里我举一个写操作的例子, 假如现在我有一个集群有5个节点, 然后基于Quorums的NWR机制, 我采用集群的Replica1-3作为值X的归属节点, 即这个时候我们的N = 3, W = 2 以及 R = 2, 那么当我们向Replica2 以及 Replica3 进行写操作的时候发生网络故障导致无法写入, 这个时候我们临时采用Replica4代替Replica2、Replica5 代替Replica3 节点接收客户端的写入, 即:
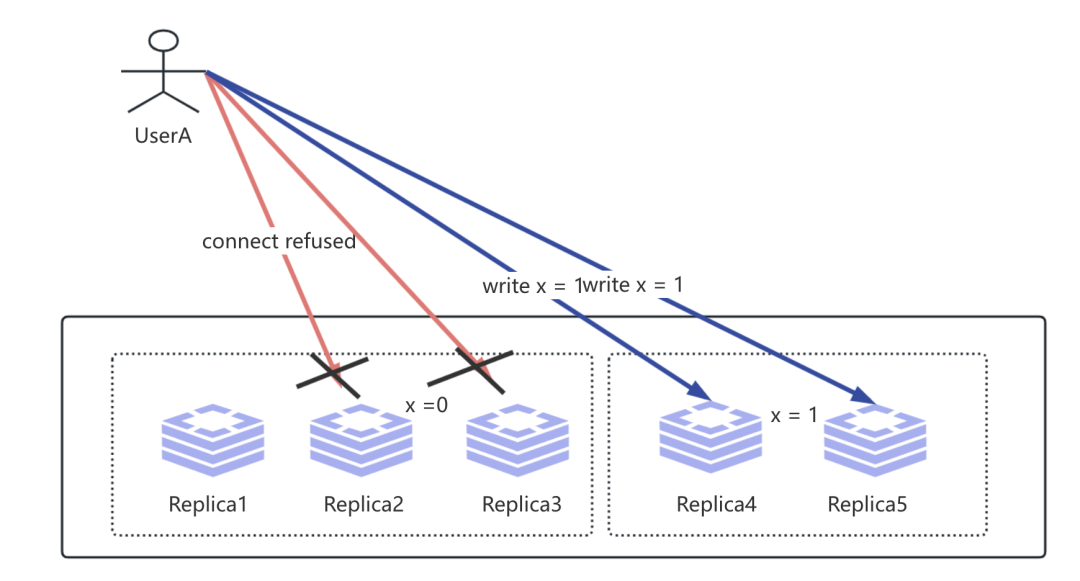
上述就是我们的Sloppy Quorums机制, 那么什么是Hinted HandOff呢? 假如现在UserA 往Replica2节点写入的操作的网络故障恢复, 那么这个时候原先代替Replica2的Replica4节点在网络故障期间发生的任何写操作都会被重新发送到Replica2节点, 这就是Hinted HandOff机制.即:
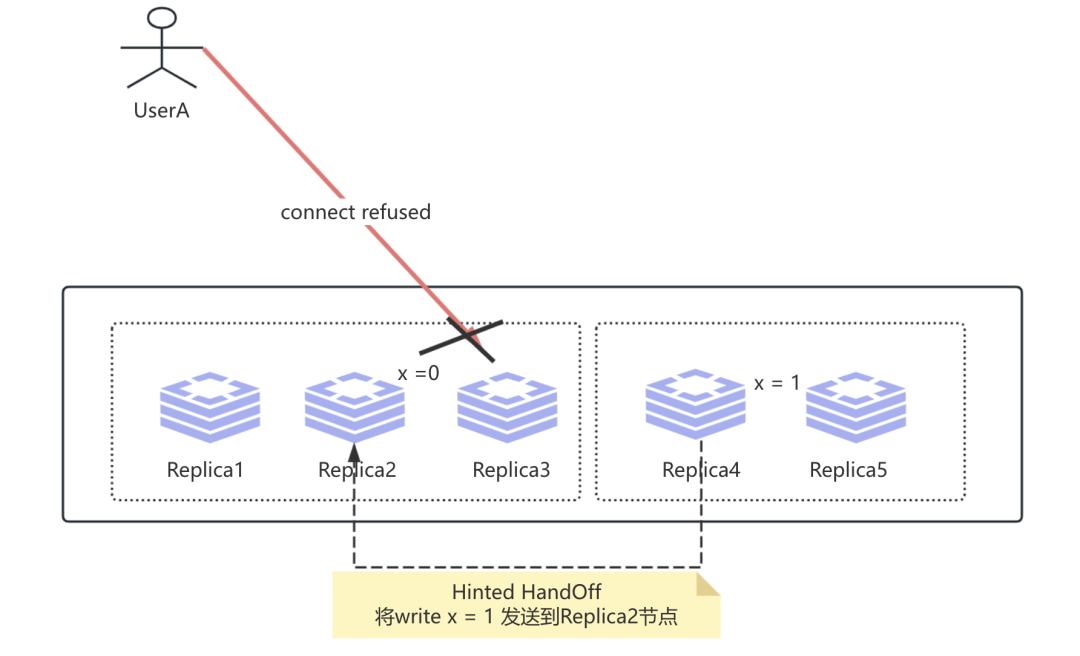
那么如果我们的存储系统是基于Sloppy Quorums 以及 Hinted HandOff 来提升我们的故障容忍能力, 这个时候也无法保证我们的线性一致性, 即在Replica4 节点发送到Replica2期间, 我们有可能会读取到值X旧的版本, 即 x = 0. 如下:
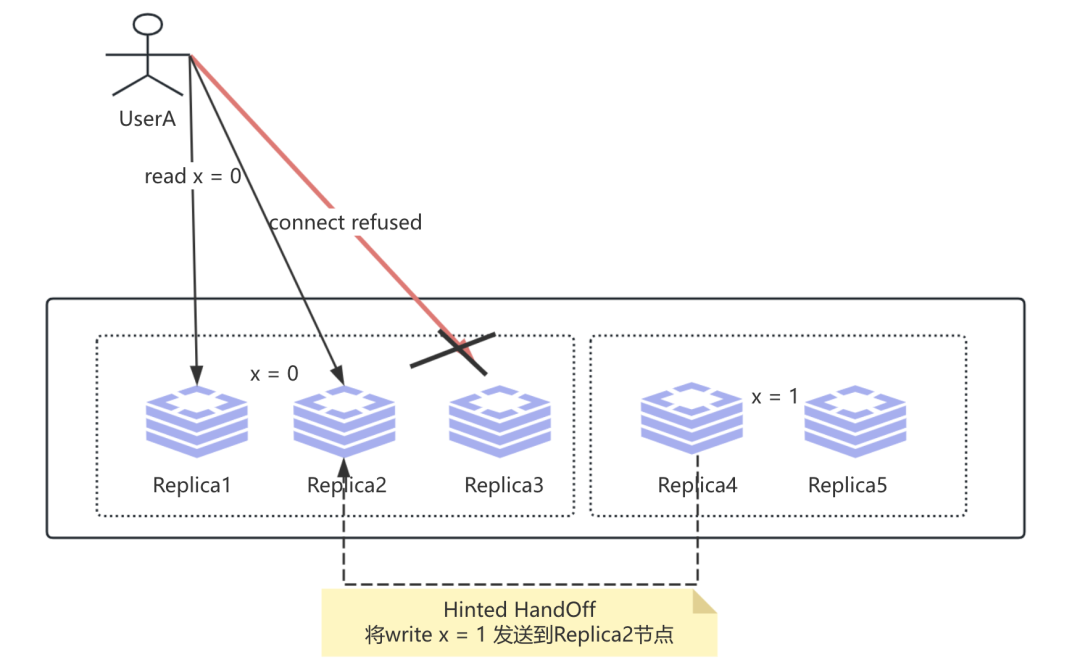
那么如果是读操作呢? 相比写操作而言会更简单, 为保证不是单点操作, 也会向Replica4 以及 Replica5 发起读操作, 但由于不满足W + R > N, 因为Replica4 以及 Replica5 不在值X归属的N个节点范围内, 因此我们读取数据也无法保证实现线性一致性.
总结
无论是Multi-Leader还是Leaderless Replication, 我们都发现在实现线性一致性上的困难与代价, 并且这两种模型都存在写冲突以及数据复制链路上的损耗.至此我们可以对于上述三种复制模型做一个总结:
- Single-Leader复制有可能实现线性一致性, 比如读己之所写的独享数据;
- 而对于Multi-Leader则不具备线性一致性, 因为我们需要考虑故障场景以及故障恢复后带来的数据一致性问题.
- 最后是Leaderless复制模型, 它基于Quorums的NWR来处理读写机制, 对于NWR机制只能说可能不具备线性一致性, 因为还是一样取决存储系统采用的Quorums是Sloppy还是非Sloppy方式, 同时也取决于我们的数据是属于共享还是独享方式的一致性.
文章有点长, 感谢您耐心阅读, 如果有用欢迎点赞和转发, 谢谢!!!
你好,我是疾风先生, 主要从事互联网搜广推行业, 技术栈为java/go/python, 记录并分享个人对技术的理解与思考, 欢迎关注我的公众号, 致力于做一个有深度,有广度,有故事的工程师,欢迎成长的路上有你陪伴,关注后回复greek可添加私人微信,欢迎技术互动和交流,谢谢!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号