今天运维那边反馈有一个设备在后台查不到,我第一时间怀疑可能是数据出了问题,导致服务报错了没有入库。

今天运维那边反馈有一个设备在后台查不到,我第一时间怀疑可能是数据出了问题,导致服务报错了没有入库。

码农编程进阶笔记
发布于 2025-07-27 10:54:45
发布于 2025-07-27 10:54:45
故事背景
今天运维那边反馈有一个设备在后台查不到,我第一时间怀疑可能是数据出了问题,导致服务报错了没有入库。
我拿着日志去本地请求接口,发现程序是没有报错的,我们的逻辑是先把唯一id放到redis里面,如果redis没有值就insert,有就update,做了一层缓存,估计是这样的话批量插入和更新数据库会快一点。
然后我看redis是有值的,以为是redis和数据库数据不一致问题,我就把redis的key删了,重新再跑一下,结果打印了insert语句,但是没有插入到数据,看来事情并没有那么简单- -
问题分析
因为数据表很大,有5E+数据,我第一反应是mysql表数据量可能爆了,但是查了下好像没有太大限制
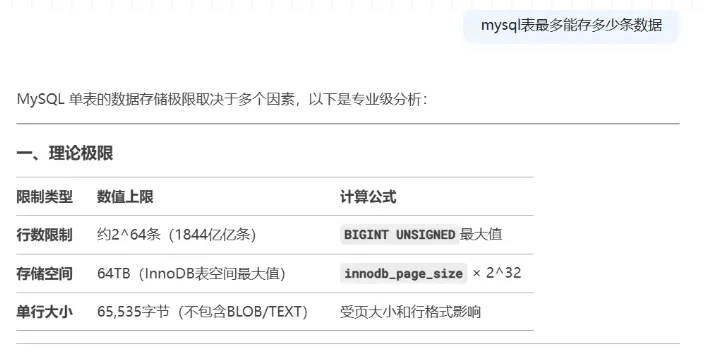
图片
再认真看了下表的自增id,这个数字让人有点熟悉的:2147483647 这个不就是int的最大值吗。意思是因为自增id超过了int,所以插入失败了,id设的就是int类型,还有个小彩蛋,目前数据库设的int长度是50,但是根本没什么鸟用。

图片
知道了问题在哪,但是这个问题处理起来很麻烦,因为数据量太大了,先请教一下deepseek吧。
方案处理
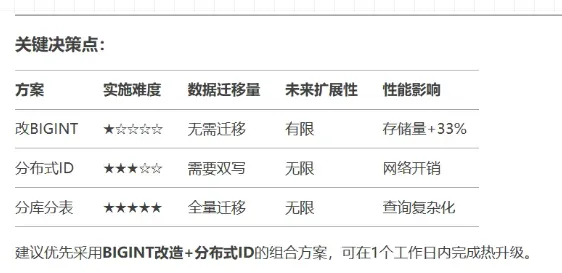
图片
deepseek给我提供了三个方案:
第一个是最简单粗暴的改BIGINT,不用迁移数据,但是会全程锁表。
第二个分布式ID需要重新设计表,需要把数据迁移到新表,而且还要redis等支撑。
第三个分库分表就更麻烦了,分库分表需要引入框架,不按照分片查询还需要引入ES,引入了ES还需要引入同步mysql和ES的中间件logstash等。
具体可移步:
https://juejin.cn/post/7444014749321461811
但是改bigint估计锁表太久,我先看看有没有其他办法先紧急处理下数据。但是按理说int最大值是21E+,数据表数据才5E+,按理说是用不完的。结果我看到自增的id值居然是不连续的
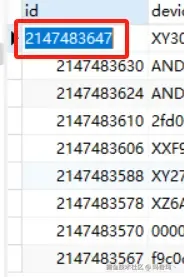
图片
按理说自增id应该是一个接着一个,不会有空隙的,后面查了一下由于数据库自增id有个高性能策略,设置了id就不一定连续。
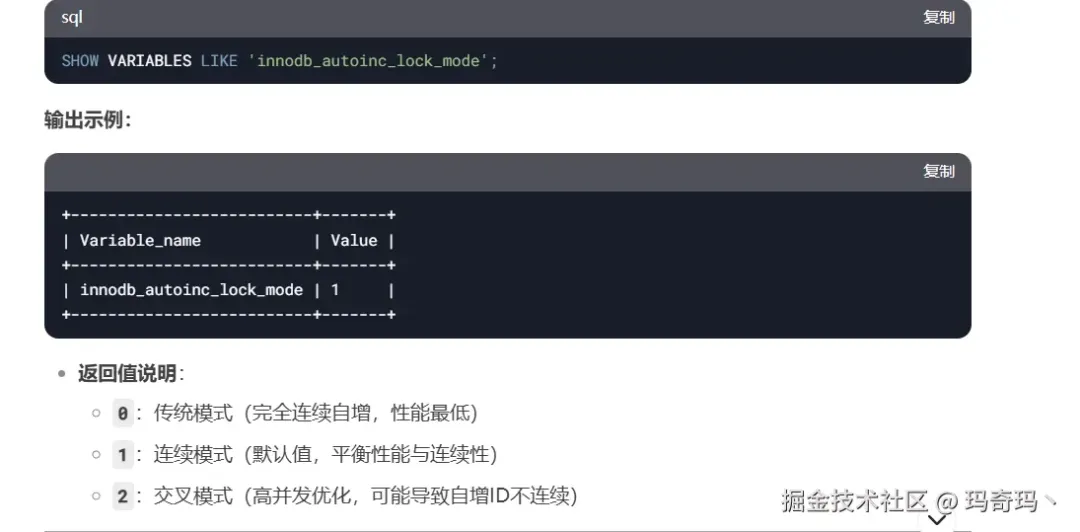
图片
后面又查了下有没有一键把数据表id重排的方法,结果也是没有的。最后我是写了一个存储过程先把最后100万的id清理出来,可以先顶个几天,后面再想办法处理。
BEGIN
DECLARE start_id INTDEFAULT;
DECLARE end_id INTDEFAULT;
DECLARE current_batch INTDEFAULT;
WHILE start_id <= end_id DO
-- 更新临时表中的ID
UPDATEtable
SET id = start_id +
WHERE id = (select original_id from (
SELECT id AS original_id
FROMtable
ORDERBY id DESC
LIMIT ) as test);
SET start_id = start_id +;
END WHILE;
END最后重新设置自增值,如果自增值已经存在,则会跳到max(id)+1
-- 重置自增值
ALTER TABLE your_table AUTO_INCREMENT =max(id)+;清理了大概500万的id段出来,然后我怀疑id间隔这么大是因为并发太高导致的。一开始程序是单线程,消费到500条就批量入库,但是后面发现单线程消费比较慢,数据量太多消费有点延迟。后面改成java批量消费,配置了30个消费者。接着我尝试了一下减少消费者数量,设置成15个,id的间隔真的变小了。
设置BIGINT
节后回来发现id还剩200万,讨论到最后还是把id的数据类型从int改成bigint
ALTER TABLE xxx MODIFY id BIGINT UNSIGNED NOT NULL AUTO_INCREMENTUNSIGNED 无符号位,不算负数,可以增加一倍数据,NOT NULL 非空 AUTO_INCREMENT自增
在测试环境有一亿数据,修改id的类型大概用了一个小时,现网我估计也是用6-7个小时也差不多了。结果改了一晚上都还没改好,然后我找了一个可以查询sql进度的语句......
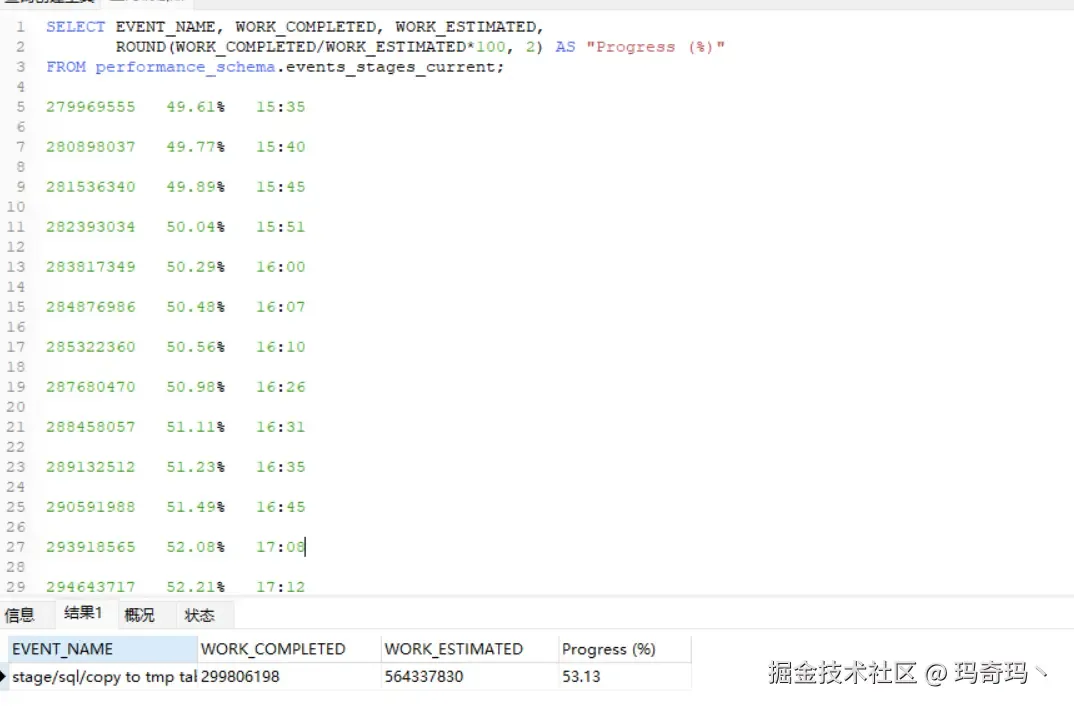
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED, ROUND(WORK_COMPLETED/WORK_ESTIMATED*100, 2) AS Progress (%) FROM performance_schema.events_stages_current;不查不知道,一查吓一跳,跑了十几个小时居然还不到50%,而且还越跑越慢。对比了一下测试环境和现网环境的buffer_pool等数据也是设置正常。
估计是索引树变大插入的数据要花多不少时间,还有一个就是现网数据库还有其他线程会抢占CPU导致速度缓慢。
统计了一下后面的数据大概是1个小时完成1.5%左右
图片
最后我是周一晚上执行的,周四早上上班的时候才跑完,用了2天多一点的时间~
总结
刚刚才在掘金刷到一篇文章《字节面试:MySQL自增ID用完会怎样?》,评论区都说有没有用完的,结果我真用完了,就感觉有点不可思议。总结一下有几个原因吧:
1、数据量确实很大,有5E多数据,然后并发也很高。其实当初他们设计的时候也预料过这个问题,所以设了个int长度50,但是这个长度没起作用- -所以设计数据库的时候一定要做好,不然几亿数据改个字段类型要2天
2、数据库的自增id策略选了高性能策略,导致并发高的时候id间隔很大。30个消费者异步处理,10条数据大概用了100个id的间隔,消耗太快了。所以这里存在一个时间和空间的取舍,使用多线程还是挺危险的操作,要谨慎一点。
还有一个小插曲,因为系统两天没消费数据,kafka的数据堆积了很多,然后我把消费者数量从30个改成50个,跑了两天,kafka还是有1天的延迟,看来麻木添加消费者数量已经没啥提升的作用了,想起八股文说多线程弄太多反而增加上下文切换的时间浪费,跟这个同理。
最后我弄成sql批量消费,消费速度马上提上去了。程序的消费策略:
单线程批量500个开始消费 ——> 30个线程单个消费 ——> 30个线程批量50个开始消费
所以说多线程异步+批量操作的策略还是很重要的!不过多线程一定要注意异步问题~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号