【大模型学习 | DeepSeek-V3原理】
原创
【大模型学习 | DeepSeek-V3原理】
原创
九年义务漏网鲨鱼
修改于 2025-07-25 09:22:17
修改于 2025-07-25 09:22:17
DeepSeek-V3 Technical Report
DeepSeek-V3 的基本框架还是 Transformer。该模型仍然沿用了 V2 模型中的 Multi-head Latent Attention (MLA) 和 DeepSeekMoE,在这框架的基础上,提出了auxiliary-loss-free strategy 解决了MoE的负载平衡问题。另外,V3 模型是通过将预测多token作为训练目标。本文主要是对DeepSeek-V3的模型框架以及训练目标进行讨论。
🧠 什么是负载平衡?
在 MoE 模型中,每一层有多个专家网络(Experts),比如 16 个 FFN(前馈网络)模块。但每个 token 并不会被全部专家处理,而是通过一个门控网络(Gating Network),为每个 token 分配 1~2 个专家来处理(Top-1 或 Top-2 MoE)。 👉 问题就出在这里: 如果门控分配得不好,就会导致: 某些专家被大量 token 占满(过载); 其他专家几乎没 token 要处理(空转); 这就叫做负载不均衡(load imbalance)。
🟢 前置知识:RoPE(Rotary Positional Embedding)
RoPE 是一种通过“旋转”的方式,将相对位置信息引入注意力机制中的位置编码方法,与早期直接加入位置编码信息不同,RoPE是通过做一个向量空间的旋转变换来记录向量的位置信息。每个位置对应一个角度,位置越靠后旋转角度越大。例如,旋转矩阵为
n通过$R_m$就被赋予了位置坐标信息。🧠 这个旋转矩阵仅仅适用d=2的向量,如果是512维度的向量应该怎么做?RoPE 的旋转矩就是一个分块对角矩阵,每个对角块是一个二维旋转矩阵,每个二维组的旋转角度不同。 图图图图
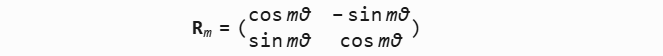
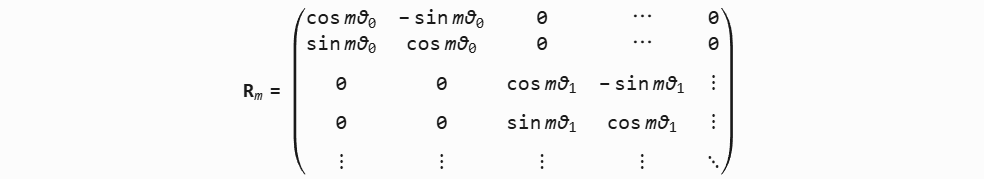
Framework
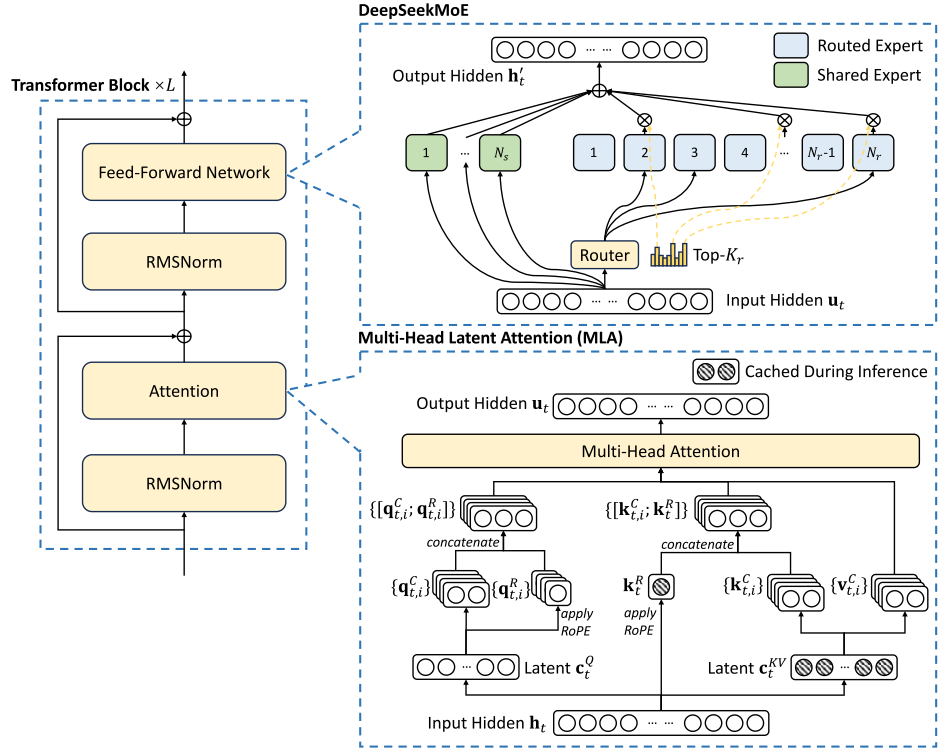
1️⃣ Multi-Head Latent Attention (MLA)
MLA是为了压缩在推理阶段K,V的缓存的低秩联合压缩
🧠 这就有一个问题了,为什么需要压缩KV内存呢?不是将input直接作为qk吗?
👉 在训练阶段确实不需要,因为模型可以一次性计算出所有KV,但是在推理阶段,token是生成输出的,当计算到第t个token时,模型需要计算当前输入Q和之前生成的所有token的Key的注意力分数,因此需要记录下每一个过程的K,V.而MLA提出了只缓存两个很小的向量来记录。
MLA相较于MHA来说,计算当前 token t 和历史 token j 的注意力时,用缓存的超小 c_KV_j 和矩阵 W_UK, W_UV 重建出该历史 token 的内容键k_C_j,i 和值
v_C_j,i。重建有低秩近似,会损失一些内容细节。
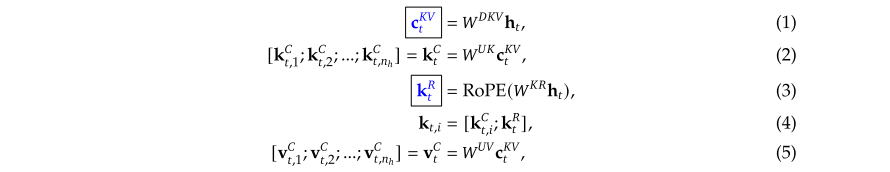
2️⃣ DeepSeekMoE
在Transformer架构中的FFN层,V3模型采用了MoE进行替换,使用更细粒度的专家,并将一些专家隔离为共享专家。这个专家系统与传统的专家系统不同,通常专家系统需要通过一个门控网络来选择专家,而传统专家系统是引入一个额外的负载均衡损失项来防止门控网络偏向于少数的专家。在DeepSeekMoE中,设置了共享专家以及路由专家router expert,共享专家是每一个token都有经过的,而路由专家是需要通过门控网络选择的。在没有采用auxiliary-loss的情况下,DeepSeekMoE通过一个超参数来控制每个专家的得分系数,具体门控流程如下所示:
step1 通过sigmoid激活函数计算每个token与每个专家的得分系数:s\_{i,t}=\text{Sigmoid}(u\_t,e\_i) ,e\_i 表示每个专家的质心向量;
step2 在得分系数上加上一个偏置系数:g_{i,t}=s_{i,t} + b\_i
step3 接着通过$\gamma$控制专家的负载:如果专家 i 被调用得太频繁: b\_i = b\_i-\gamma
step4 对专家的门控系数进行归一化;
step5 计算MoE专家FFN输出;
#️⃣ 模型架构如图所示:
Multi-Token Prediction(MTP)
MTP 通过共享的输出头预测多个额外的 token,本质上是引入多个 token-level 的训练目标以增强训练信号。具体而言,当前层的输入由两部分组成:前一层的隐藏表示和当前目标 token 的嵌入,两者经过 RMSNorm 后拼接,再通过线性投影后输入到对应的Transformer block 中。每个 block 的输出再通过共享的输出头映射为预测 logits,从而对多个位置的 token 进行联合预测。并通过交叉熵进行损失计算。
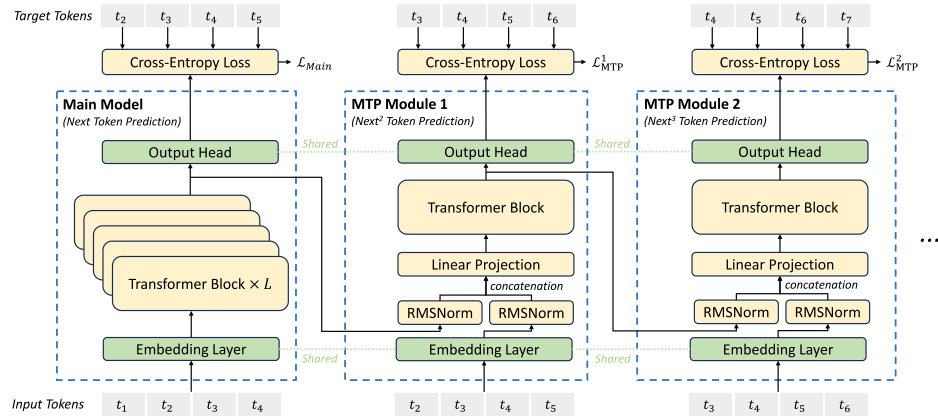
🟢 RMSNorm 是基于“层归一化中主要起作用的是缩放因子,而非平移因子”这个发现而提出的归一化方法。在层归一化中需要减去均值,而模型在训练过程中已经学会通过投影矩阵自动调节均值;而 \gamma 的作用是调整每一维的相对 scale,是表达力的核心。具体计算公式如下所示:
模型 | 是否使用 RMSNorm | 是否移除偏置项 |
|---|---|---|
GPT-2 | ❌ No | ❌ 有偏置 |
LLAMA | ✅ Yes | ✅ 无偏置 |
DeepSeek-V3 | ✅ Yes | ✅ 无偏置 |
👉目前的模型权重已开源: https://huggingface.co/deepseek-ai/DeepSeek-V3-Base 者由于设备限制无法对V3模型进行体验。有兴趣的同学可以自行下载模型权重:
mode_name_or_path = '/root/autodl-tmp/deepseek-ai/DeepSeek-V3-Base'
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, trust_remote_code=True,torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(mode_name_or_path)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
model.eval() # 设置模型为评估模式原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号