从零开发,如何基于 Spark 构建一个电影推荐系统
原创
从零开发,如何基于 Spark 构建一个电影推荐系统
原创
叫我阿柒啊
修改于 2025-07-28 07:44:07
修改于 2025-07-28 07:44:07
前言
在之前的一篇二十行代码!我用Spark实现了电影推荐算法文章中,写了如何使用spark的ALS,去做一个电影推荐模型,其中使用的电影评分数据是1000多条Spark的样例数据。在文章的末尾我也提到,如果想要做一个电影推荐系统,除了电影推荐模型数据,同时也要创建一个前后端的展示系统,在数据库中将电影ID与电影名称或者电影类型对应起来,这样才能实现一个完整的推荐系统展示。
在上面提到的那篇文章,就是在创作营s9写的,本来想趁热打铁写完这篇文章,然后上面的前言部分已经写完了,然后就一直拖延到到现在,快一年过去了,已经到了s14赛季了,所以就打算在项目实战的赛道,实现电影推荐系统和完成这篇文章的创作。
数据准备
上面也提到了,之前使用的是1000多条 spark 官网提供的样例数据,所以为了验证模型的准确性,我就找到了一个电影推荐系统的数据集 MovieLens。
MovieLens
MovieLens 电影推荐数据其中包含了四个文件:movies、ratings、tags、links。

moveis共87586条数据,其中包含了电影ID和电影名称的映射:
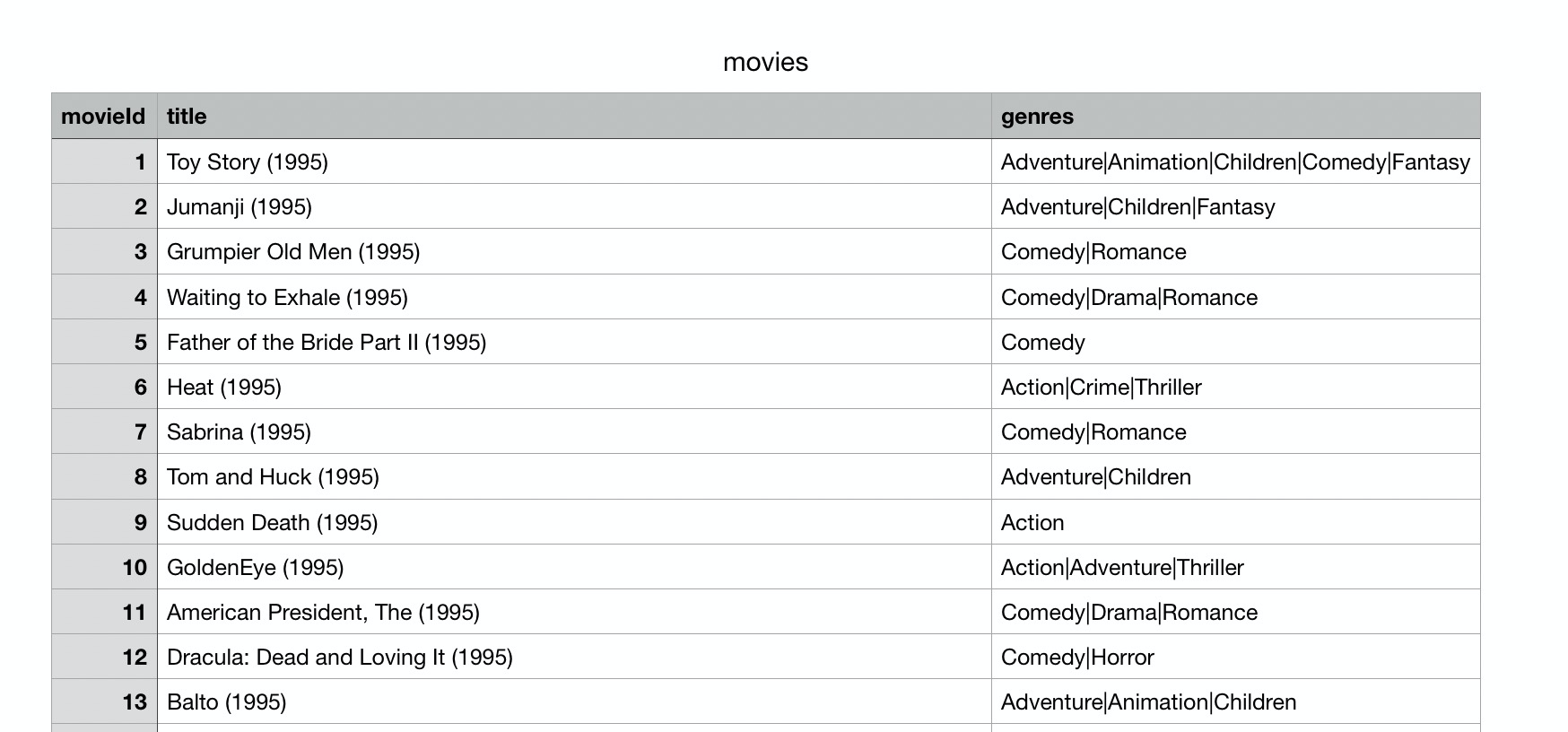
ratings是用户评分数据,和spark给出的样例数据是一样的格式,包含userId、movieId和rating评分字段,只不过和之前的1500条数据相比,这里有3000w条评分数据。
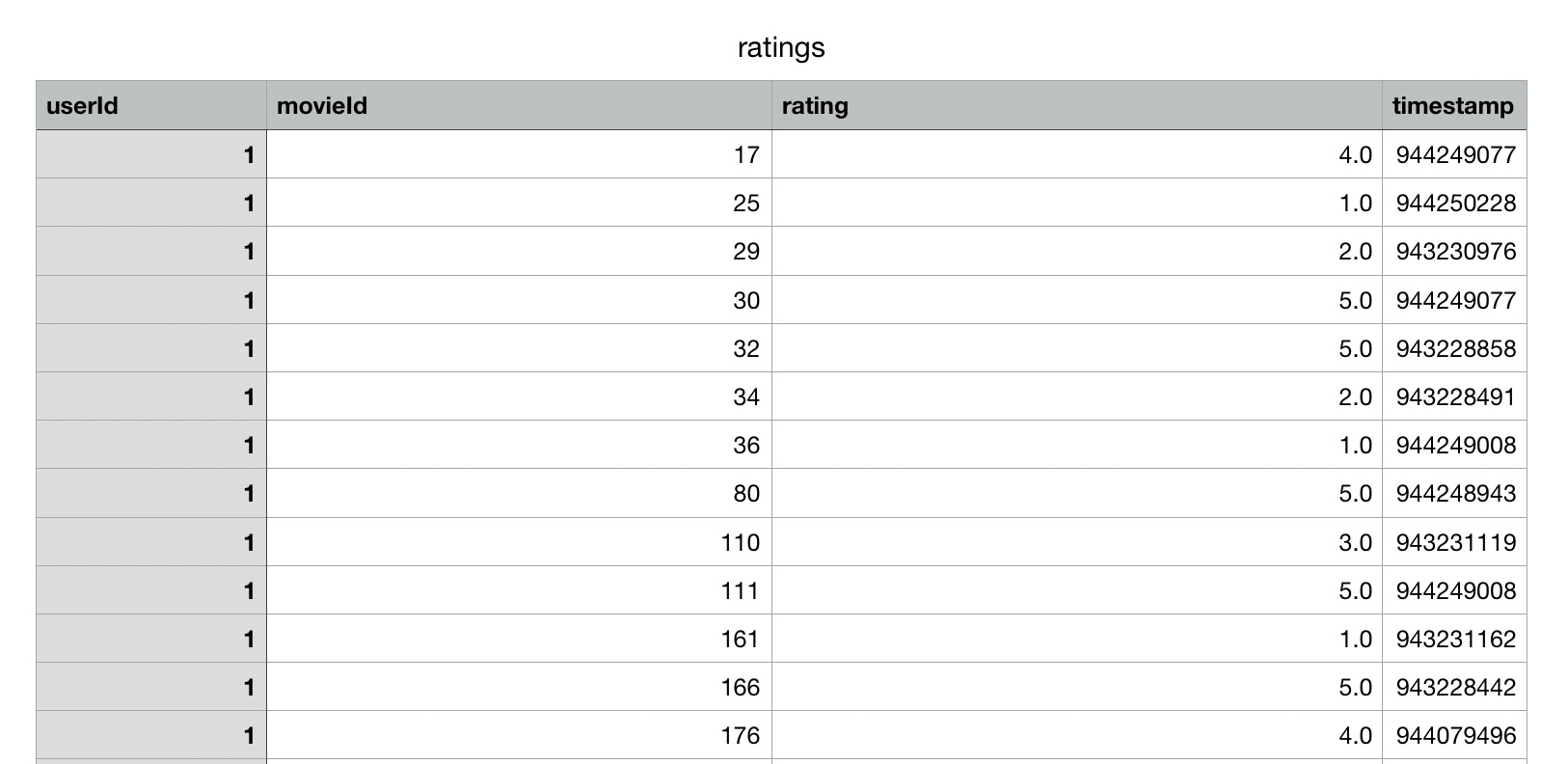
在tags文件中共四列数据,分别是:userId、movieId、tag、timestap。
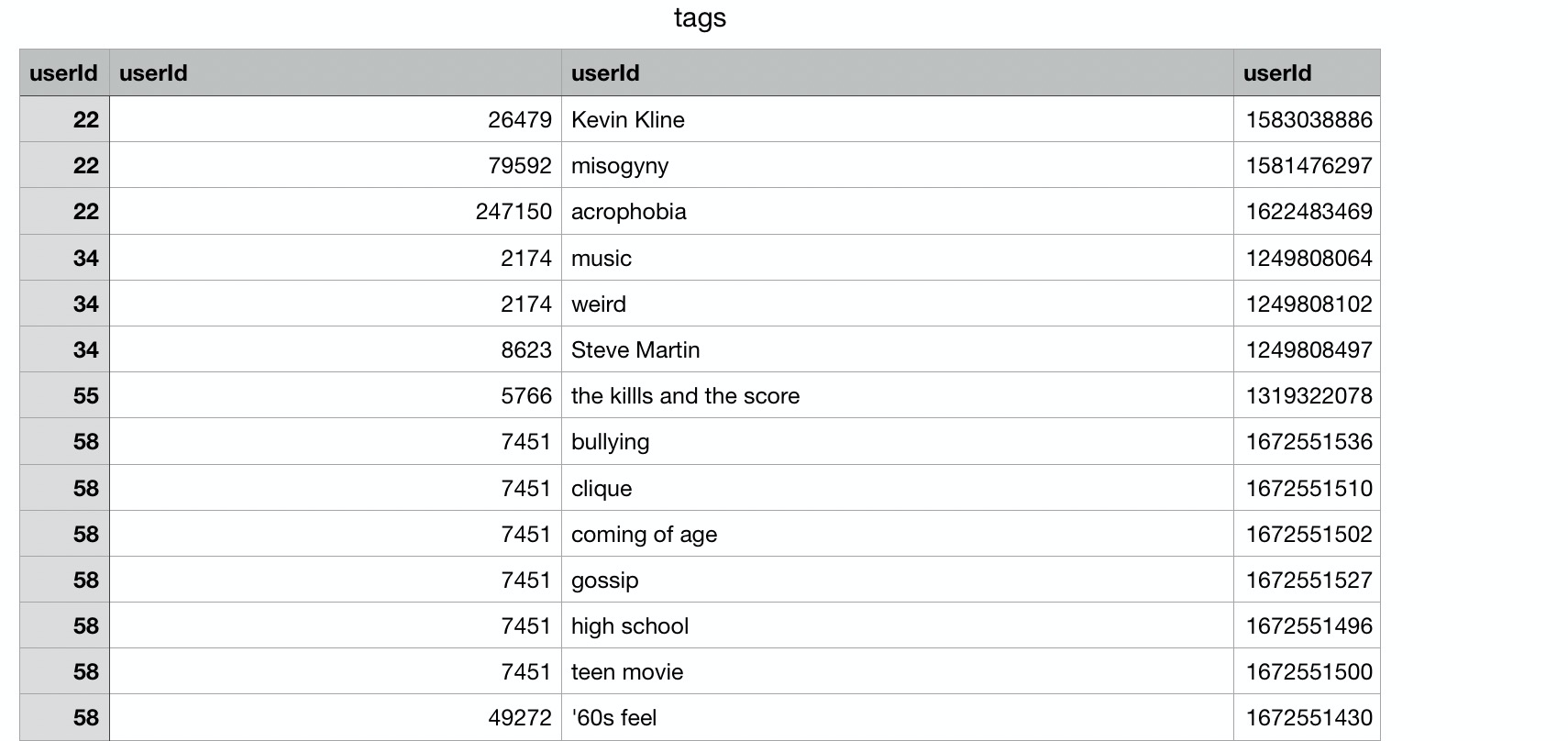
而links文件对于我这个电影推荐系统来说没有什么意义,里面数据就是movieId对应各种数据库中的ID。其中,IMDB是互联网电影资料库(亚马逊公司旗下网站),TMDB 是一个用户贡献的电影数据库。

上面就是MovieLens包含的四种数据,其中ratings直接使用spark的ALS训练生成电影推荐模型,movies和tags文件就存入数据库中。其中movies主要是用来在前台展示。
数据处理
在上面四个文件中,我们将 movies 和 tags 这两部分数据存储在 MySQL 中,那为什么要存储这两部分数据呢?
ALS生成的推荐模型数据是这样的:用户1喜欢电影2,用户2喜欢电影3。那么电影2和3到底是哪部电影呢,这时候从moveis表里根据2、3这个ID就能获取到电影名称,展示在前台页面页面上。
而tags表主要是用来表示用户和电影类型偏好的关系,通过userId和movieId与ratings关联,可以帮助分析出来电影的特征和用户的偏好。这些标签可以用于电影推荐准确性验证、用户偏好分析,以及改进电影分类和搜索功能。
建表
所以就在数据库中创建movies和tags两个表:
create table movies(
id int(8) not null primary key,
title varchar(200) not null,
genres text
);
create table tags(
userId varchar(8) default '',
movieId varchar(8) default '',
tag text,
timestamp varchar(16) default ''
);数据加载
然后开发一个 sql 脚本,将 movies.txt 和 tags.txt 中的数据load到数据表中。
LOAD DATA INFILE '/var/lib/mysql-files/ml-32m/movies.csv'
INTO TABLE movies
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS
(id, title, genres);
LOAD DATA INFILE '/var/lib/mysql-files/ml-32m/tags.csv'
INTO TABLE tags
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS
(userId, movieId, tag, timestamp);其中选项含义:
- FIELDS TERMINATED BY ',':指定字段之间的分隔符为逗号
- ENCLOSED BY '"':指定字段值被引号包围(如果你的数据中包含了逗号)
- LINES TERMINATED BY '\n':指定行结束符为换行符
- IGNORE 1 ROWS:忽略CSV文件的第一行(通常是表头)
执行上面的sql将数据加载到 MySQL。
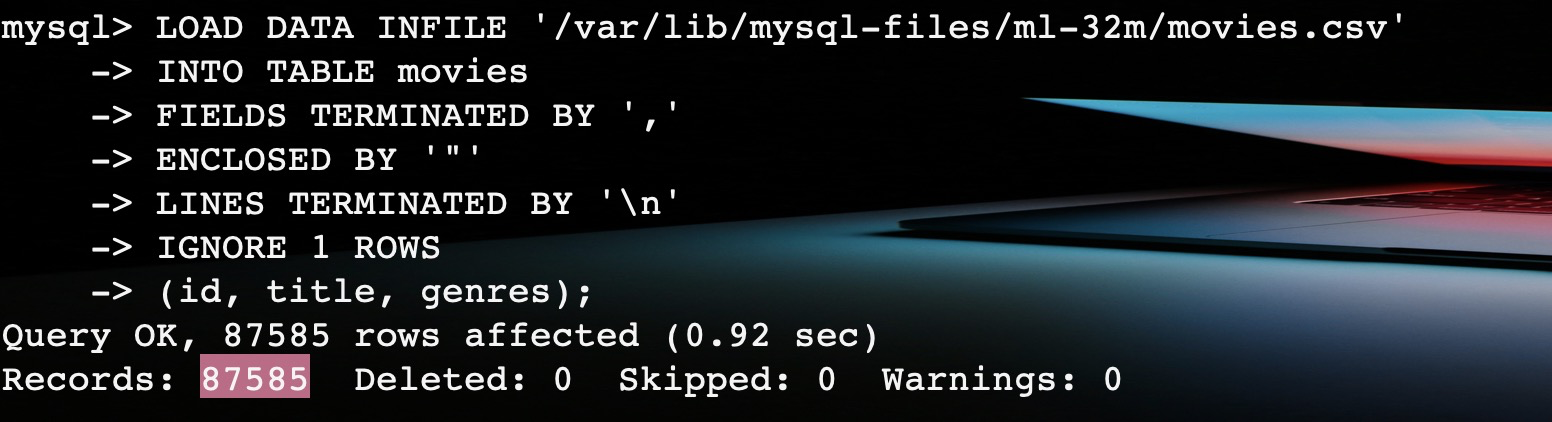
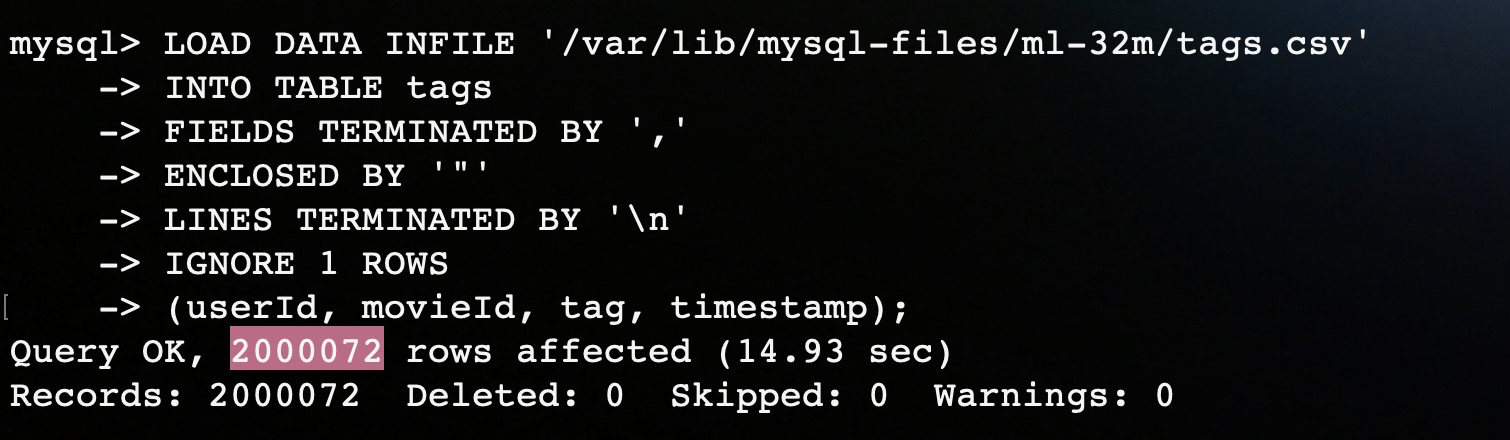
在成功加载之后,查询两个表的数数据。
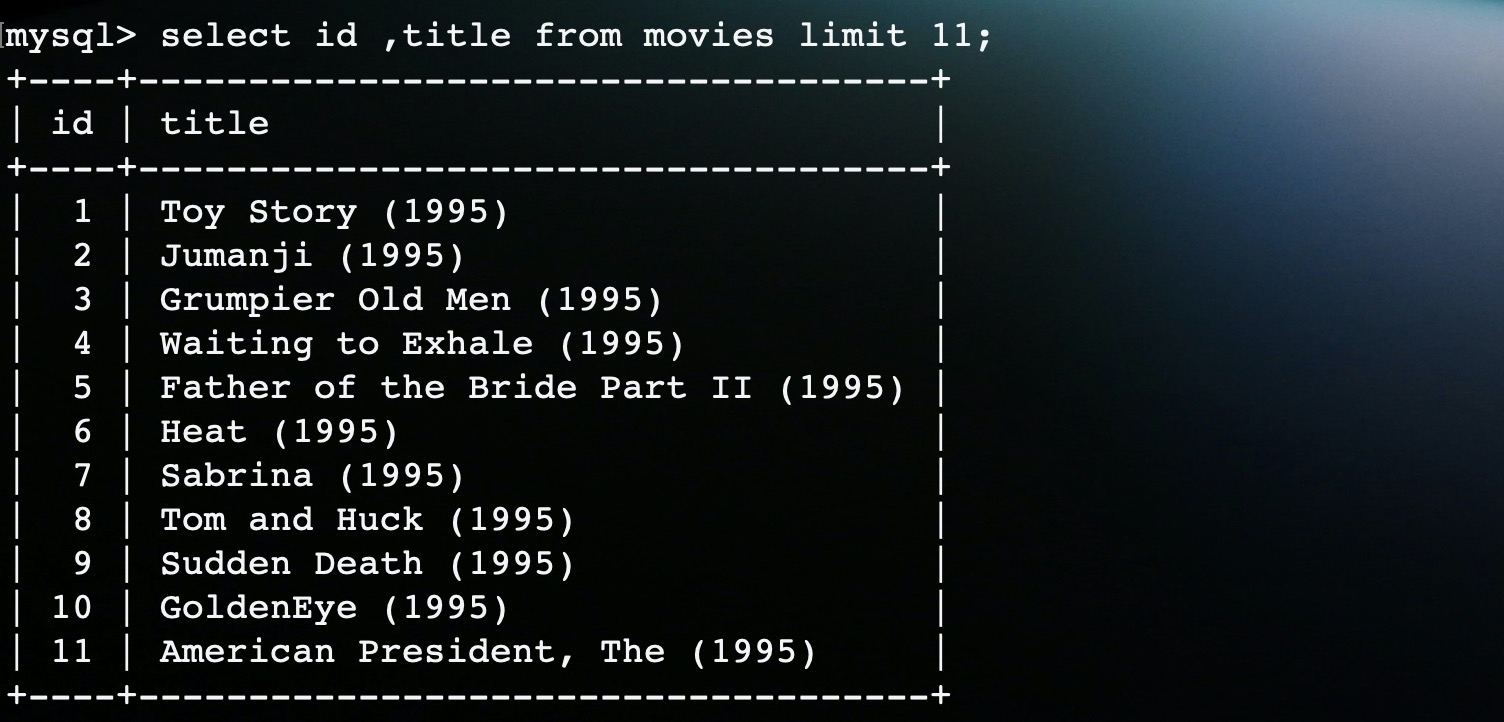
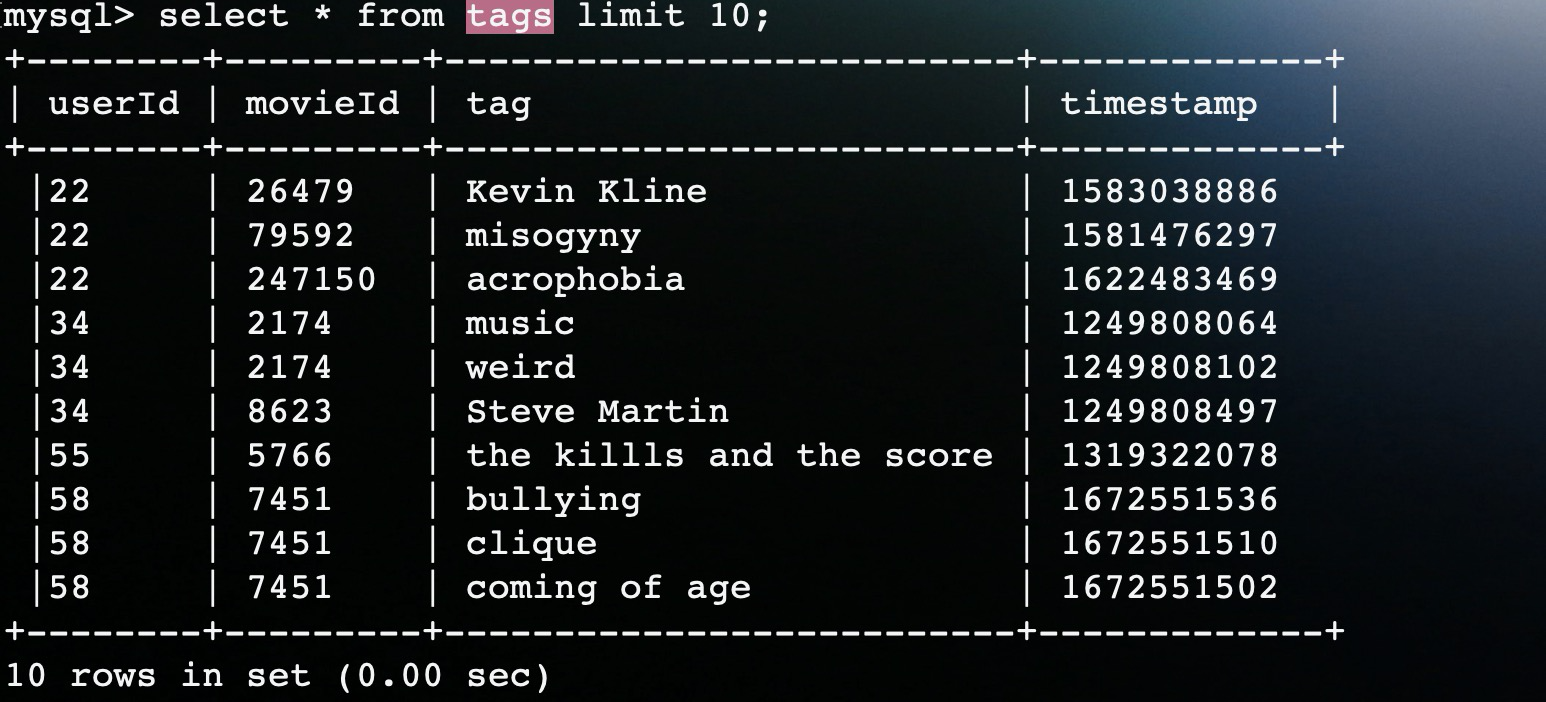
这样,就完成数据的加载工作。
推荐算法
然后就是使用上篇文章分析的spark ALS代码,读取ratings中的数据生成推荐模型。因为有3000w的数据,可以放在HDFS上提高并发能力,如果本地的话就考虑增加线程数来提高效率。这个一个很好的点,从这里就可以将Hadoop、HDFS等这些大数据技术组件,引入到这个推荐系统中。
首先使用sed命令将ratings评分数据文件的表头删除,否则在spark程序读取ratings数据进行处理的时候就会报错。
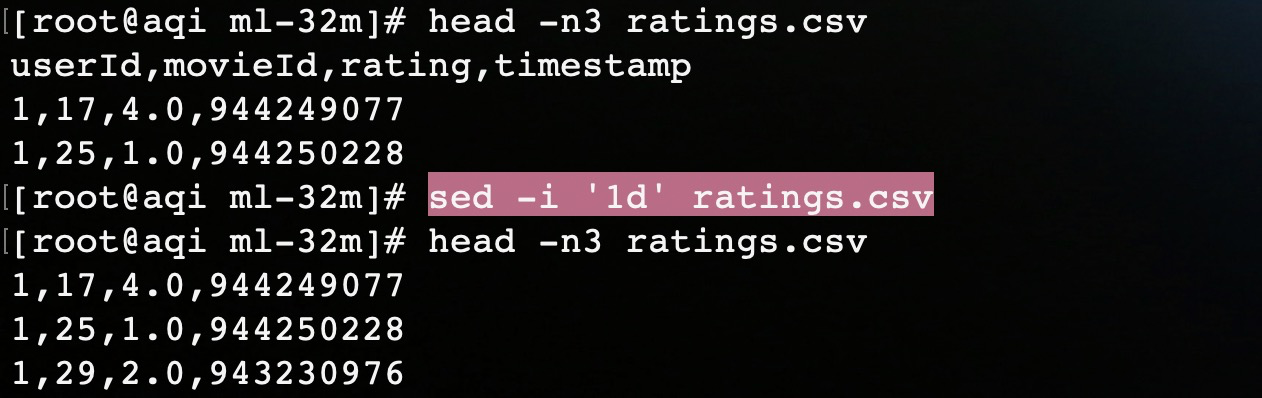
在处理完数据之后,就在spark的ALS代码中,读取ratings数据文件,根据之前的推荐算法进行推荐。代码主要分为三个部分:
1. 解析评分文件
首先我们根据 rating 评分文件中的字段,构造一个 case 类作为映射实体。然后定义 parseRating 函数处理文件数并映射成 Rating 对象。
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split(",")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}上面这些都是准备工作。
2. ALS 推荐算法
接下来就是使用 spark mlib 提供的 ALS 算法,开发一个 Spark 程序开始将数据加载到程序中进行推荐。这一块都是根据官方提供的程序进行稍微改造即可。
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("ALSExample")
.master("local[4]")
.getOrCreate()
import spark.implicits._
// 读取评分数据
val ratings = spark.read.textFile("path/ml-32m/ratings.csv")
.map(parseRating)
.toDF()
// 划分训练集和测试集
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
// 构建 ALS 模型
val als = new ALS()
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
// 模型训练
val model = als.fit(training)
// 模型评估
model.setColdStartStrategy("drop")
val predictions = model.transform(test)
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println(s"Root-mean-square error = $rmse")
// 获取每个用户 top10 推荐
val userRecs = model.recommendForAllUsers(10)
}通过读取评分文件、构建 ALS 模型、模型训练、评估之后,就可以获取到用户的电影推荐数据,这时候我们在控制台打印,输出结果如下:
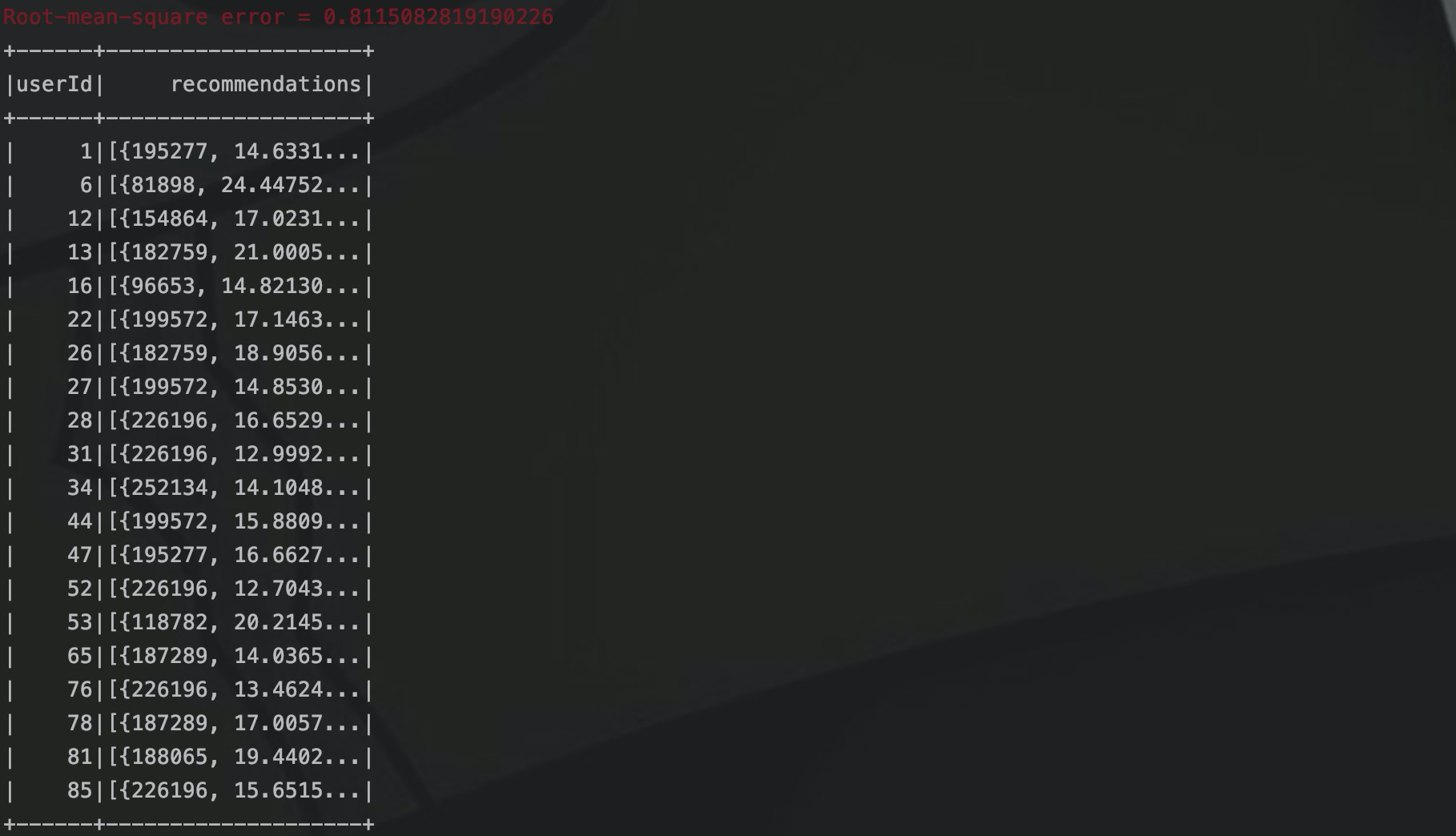
可以看到这里的均方根误差只有0.8,相对于之前样例数据计算的1.7,可以说是精度提高了不少,这里输出的结果只有TOP 10,我们在spark代码中连接数据库,将推荐的数据存放到数据库中。
3. 存储推荐数据
我这里用的MySQL,但是如果是大数据的数据存储和查询,为了提高存储和查询的效率和时效性,推荐的方案是 redis 或者 HBASE。这个就纳入到后面的优化工作中去。
这里创建一个电影推荐的结果表 user_movie_recommendations。
CREATE TABLE user_movie_recommendations (
user_id INT NOT NULL,
movie_id INT NOT NULL,
prediction FLOAT,
recommend_time DATETIME DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (user_id, movie_id)
);然后就是在推荐程序中,使用 spark sql 模块,将推荐结果数据处理后,写入到 MySQL 中去,代码如下:
val explodedRecs = userRecs
.withColumn("recommendation", F.explode(F.col("recommendations")))
.select(
F.col("userId").as("user_id"),
F.col("recommendation.movieId").as("movie_id"),
F.col("recommendation.rating").as("prediction"),
F.current_timestamp().as("recommend_time")
)
// MySQL JDBC 配置
val mysqlUrl = "jdbc:mysql://127.0.0.1:3306/movies"
val mysqlProperties = new java.util.Properties()
mysqlProperties.setProperty("user", "root")
mysqlProperties.setProperty("password", "123456")
mysqlProperties.setProperty("driver", "com.mysql.cj.jdbc.Driver")
// 写入 MySQL,14 分区并发写,每批 2000 条,提升性能
explodedRecs
.repartition(14)
.write
.mode("append")
.option("batchsize", "2000")
.option("isolationLevel", "NONE")
.jdbc(mysqlUrl, "user_movie_recommendations", mysqlProperties)
spark.stop()在写入的过程中为了提高并发和效率,这里通过 repartition 进行了重分区,并且将 batchsize 设置为 2000,并禁用了部分事务。
在代码执行完毕之后,我们查询电影推荐的结果表 user_movie_recommendations,可以看到数据已经写入。
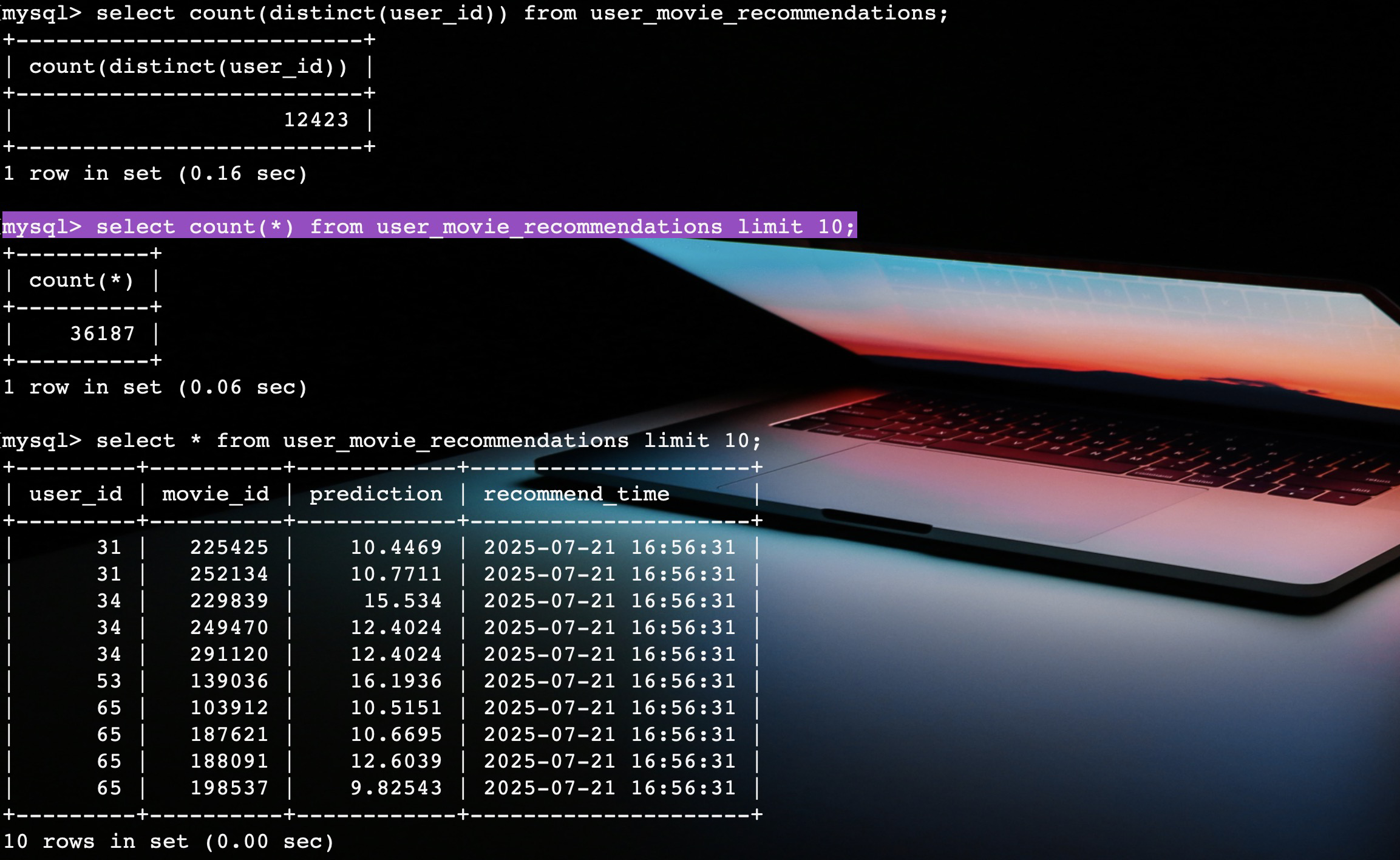
这样就完成了电影推荐的算法部分,这一块可以使用 spark,也可以使用 python 去实现。
电影推荐系统
就在前几天有一个同学私信我,如何在图书管理系统中加入算法,我看到之后就反问:“是推荐算法吗”。在得到他肯定回答之后,我告诉他 推荐程序和管理系统之间都是独立解耦的 。
在系统中收集到用户的行为数据,经过清洗格式化之后,放入到推荐程序中生成推荐结果数据放入数据库,然后管理系统通过接口调用,将推荐结果数据展示到前端上,例如轮播图展示、首页展示或者个性推荐等。
我们之前已经有了 movies、ratings、tags 文件,以及电影推荐的结果表 user_movie_recommendations。我简单得做了一个电影推荐系统,看看上面那些数据是如何和推荐系统关联起来的。
电影展示
在电影推荐系统中我们设计了 movie 表,如下图所示,核心字段和我们上面数据集中的 movies 文件是相同的。
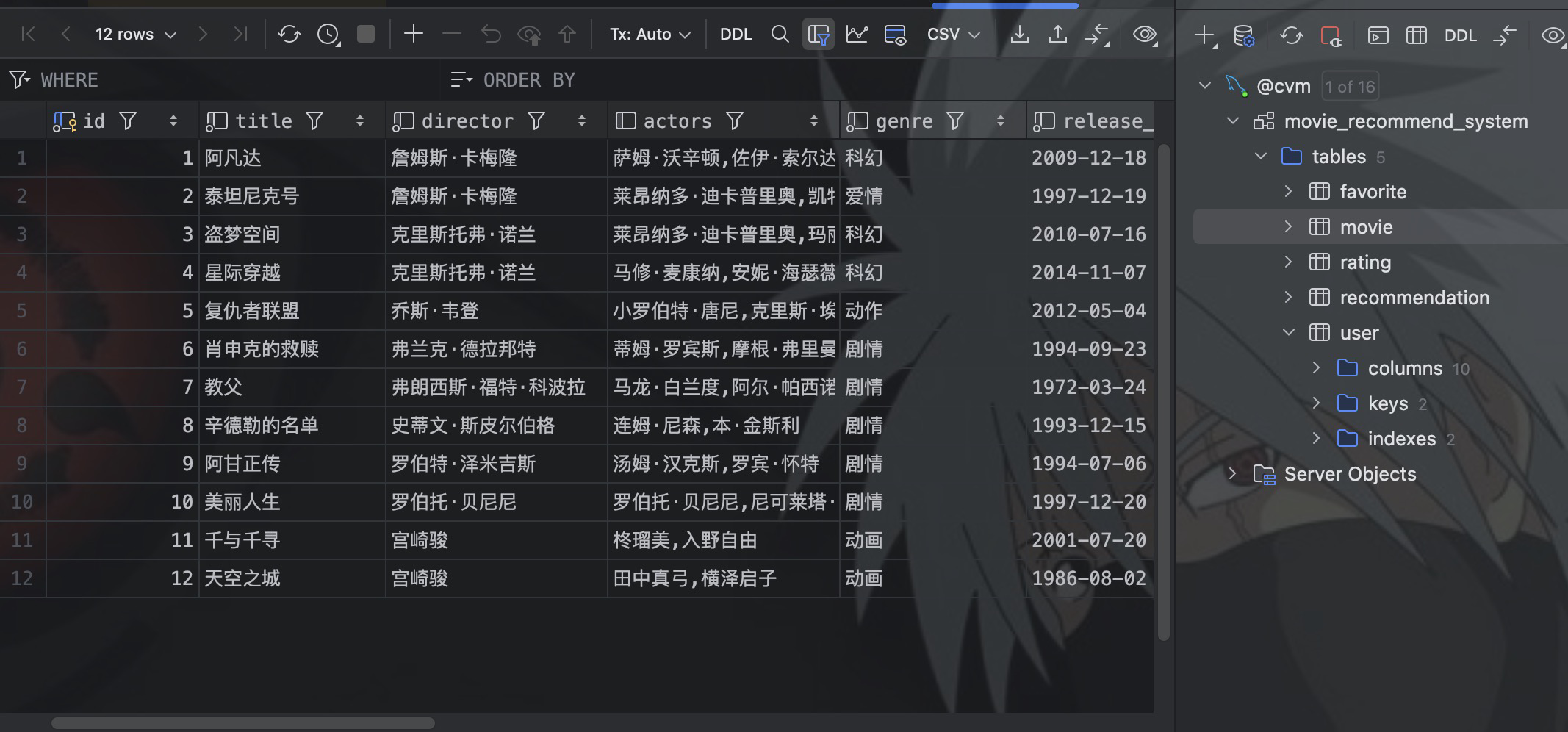
细心的你会发现,在电影推荐系统 movie 表中的 genre 字段,就是数据集中的 tags 文件中的内容,用于标识电影的类型,只不过在电影推荐系统中,直接放在了一张表中。我们通过在 Mapper 中定义查询函数。
// 根据ID查询电影
@Select("SELECT * FROM movie WHERE id = #{id}")
Movie findById(Long id);
// 根据类型查询电影
@Select("SELECT * FROM movie WHERE genre = #{genre} AND status = 1")
List<Movie> findByGenre(String genre);然后在 Controller 中通过调用 Service 层方法,最终将 movie 数据通过接口返回给用户。
// 获取电影列表
@PostMapping("/list")
public Result getMovieList(@RequestHeader("Authorization") String token) {
try {
if (token != null && token.startsWith("Bearer ")) {
token = token.substring(7);
if (!JwtUtil.validateToken(token)) {
return Result.error("Invalid token");
}
}
logger.info("User getting movie list");
List<Movie> movies = movieService.findAll();
return Result.success(movies);
} catch (Exception e) {
logger.error("Failed to get movie list: {}", e.getMessage());
return Result.error(e.getMessage());
}
}
// 获取电影详情
@PostMapping("/detail")
public Result getMovieDetail(@RequestHeader("Authorization") String token, @RequestBody Map<String, Long> request) {
try {
Long movieId = request.get("id");
logger.info("User getting movie detail for id: {}", movieId);
Movie movie = movieService.findById(movieId);
if (movie != null) {
return Result.success(movie);
} else {
return Result.error("Movie not found");
}
} catch (Exception e) {
return Result.error(e.getMessage());
}
}最终由前端电影页面展示。
所以,我们在电影推荐系统中展示使用的 movie 表,和我们在上面讲 Spark 推荐算法数据集中的 电影数据是一样,所以我才在推荐算法那一节,将数据集中的 movies 存入到了 MySQL。
用户评分
movie 展示在系统中,用户对电影进行评分、收藏等操作。
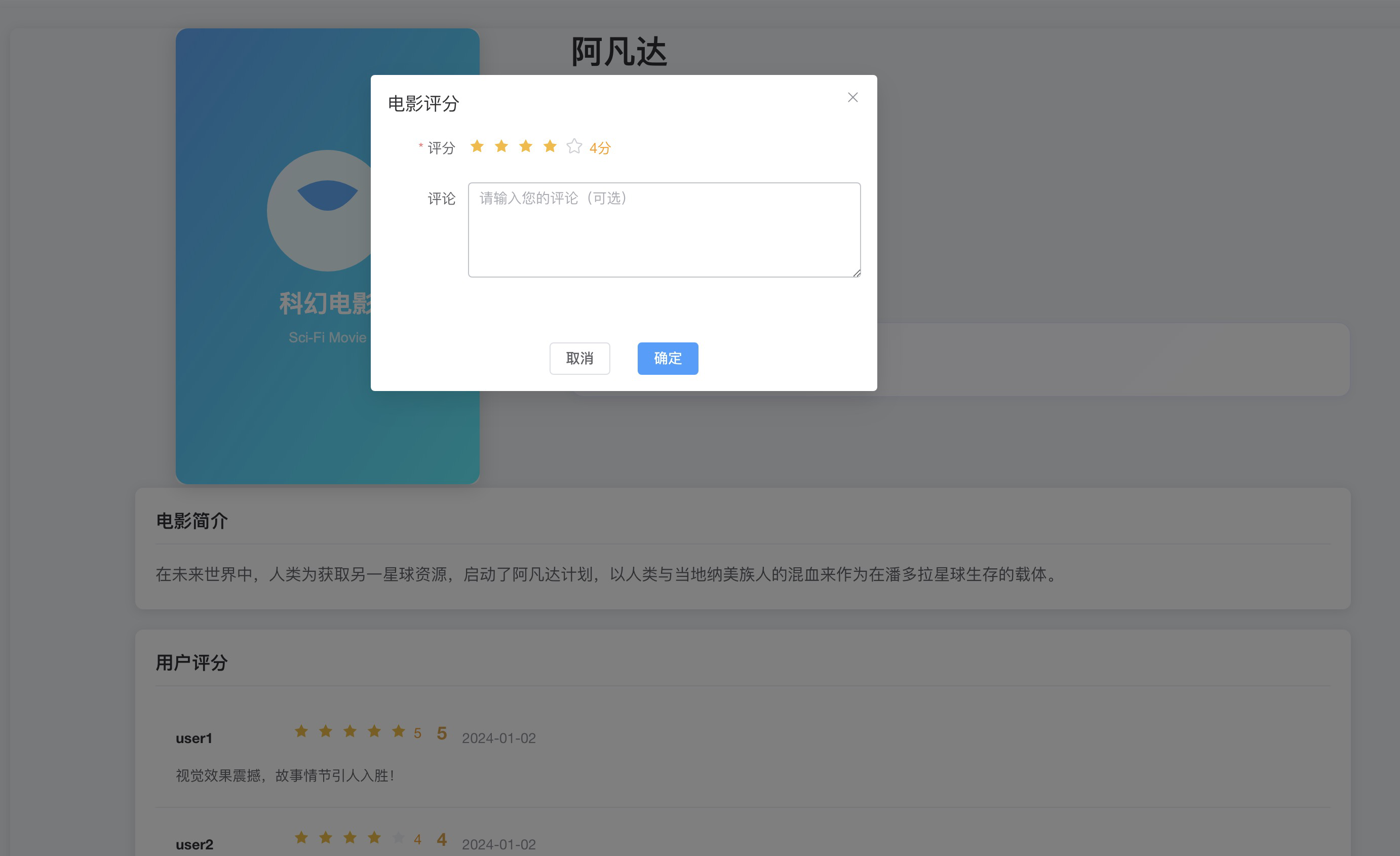
然后调用电影推荐系统中的 controller 接口来收集用户的的评分数据。
// 添加评分
@PostMapping("/add")
public Result addRating(@RequestHeader("Authorization") String token, @RequestBody Map<String, Object> request) {
try {
if (token != null && token.startsWith("Bearer ")) {
token = token.substring(7);
if (!JwtUtil.validateToken(token)) {
return Result.error("Invalid token");
}
Long userId = JwtUtil.getUserIdFromToken(token);
Long movieId = Long.valueOf(request.get("movieId").toString());
Integer rating = Integer.valueOf(request.get("rating").toString());
String comment = (String) request.get("comment");
logger.info("User {} adding rating {} for movie {} with comment: {}", userId, rating, movieId, comment);
Rating savedRating = ratingService.addRating(userId, movieId, rating, comment);
return Result.success(savedRating);
}
return Result.error("Invalid token");
} catch (Exception e) {
logger.error("Failed to add rating: {}", e.getMessage(), e);
return Result.error(e.getMessage());
}
}然后通过 Service 层调用 mapper 层,将用户数据插入到数据库中。
/ 插入新评分
@Insert("INSERT INTO rating(user_id, movie_id, rating, comment, create_time, update_time) " +
"VALUES(#{userId}, #{movieId}, #{rating}, #{comment}, #{createTime}, #{updateTime})")
@Options(useGeneratedKeys = true, keyProperty = "id")
int insert(Rating rating);最终就形成了 rating 表。
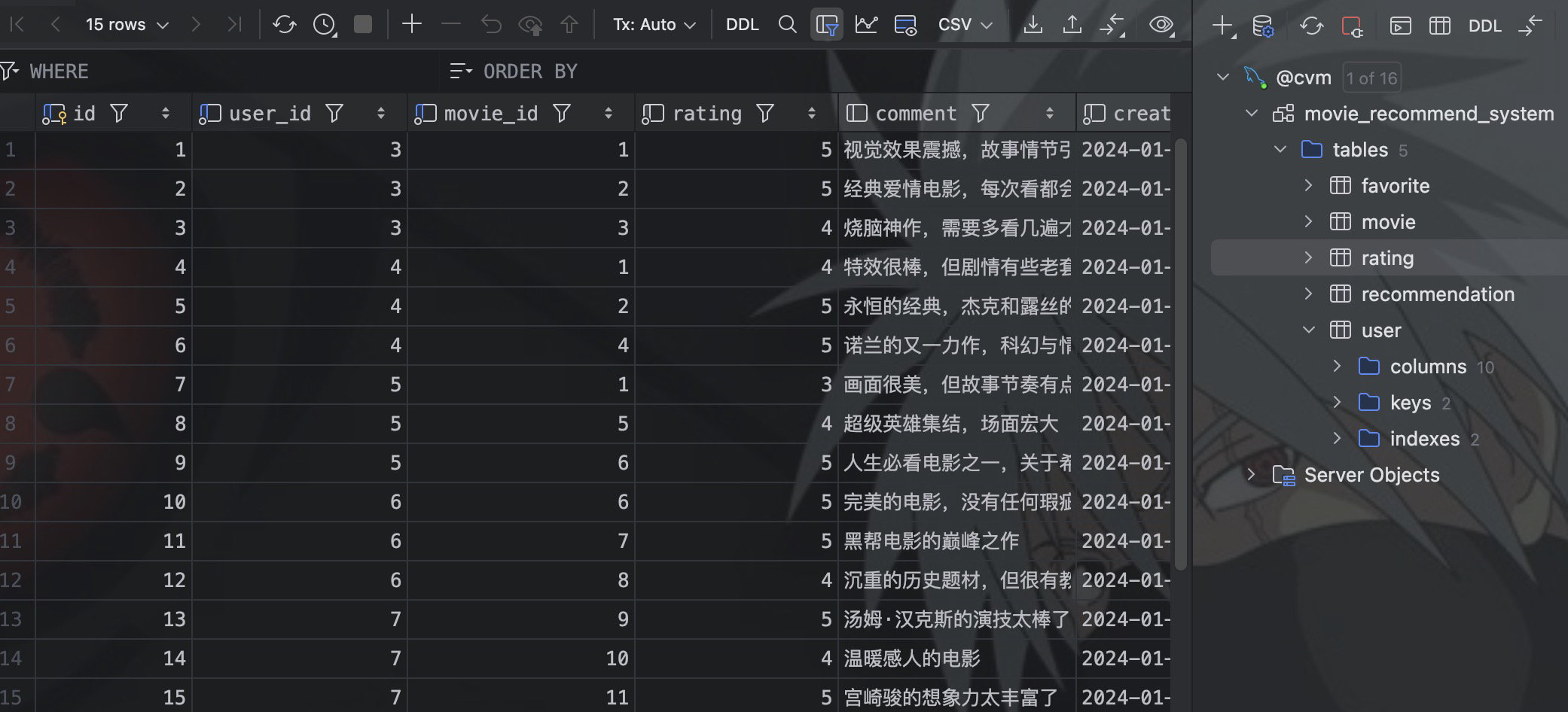
评分数据除了用于推荐算法,同时也要展示在电影推荐系统中。定义查询接口,在电影页面中展示每个用户对于该电影的评分信息。
// 根据ID查询评分(包含用户名和电影标题)
@Select("SELECT r.*, u.username, m.title as movieTitle FROM rating r " +
"LEFT JOIN user u ON r.user_id = u.id " +
"LEFT JOIN movie m ON r.movie_id = m.id " +
"WHERE r.id = #{id}")
Rating findById(Long id);
// 查询用户的所有评分
@Select("SELECT r.*, u.username, m.title as movieTitle FROM rating r " +
"LEFT JOIN user u ON r.user_id = u.id " +
"LEFT JOIN movie m ON r.movie_id = m.id " +
"WHERE r.user_id = #{userId} ORDER BY r.create_time DESC")
List<Rating> findByUserId(Long userId);
// 查询电影的所有评分
@Select("SELECT r.*, u.username, m.title as movieTitle FROM rating r " +
"LEFT JOIN user u ON r.user_id = u.id " +
"LEFT JOIN movie m ON r.movie_id = m.id " +
"WHERE r.movie_id = #{movieId} ORDER BY r.create_time DESC")
List<Rating> findByMovieId(Long movieId);电影推荐
rating 中的评分数据,也就是我们在 ALS 推荐算法中用到的数据。在电影推荐系统的 admin 账户下,可以启动电影推荐程序,加载上面的评分数据进行推荐。

这里可以通过一些脚本调度,启动我们上面开发的 spark 电影推荐程序,这样就实现了电影推荐系统和电影推荐算法程序之间的解耦。
推荐展示
电影推荐程序执行过后,生成电影推荐结果数据表 recommendation:
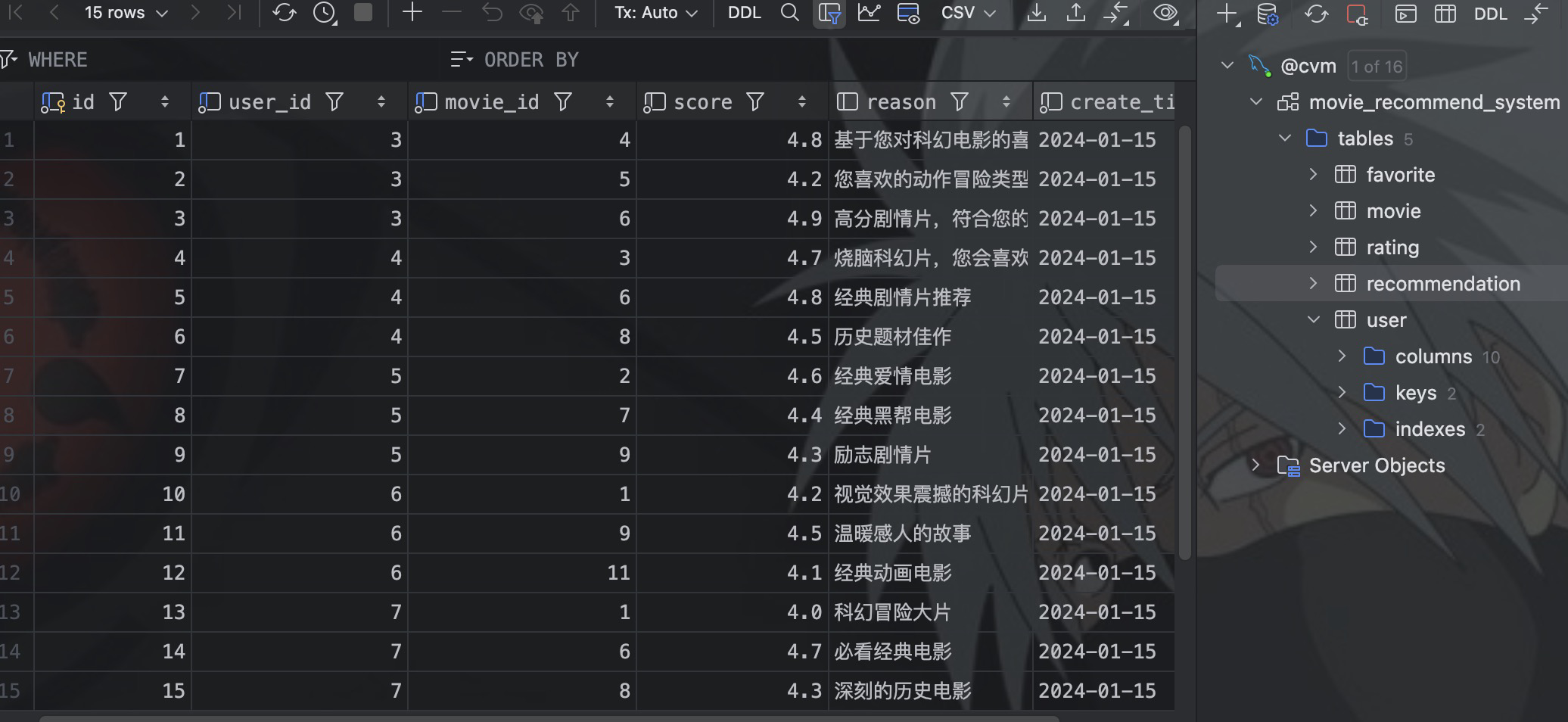
然后定义查询 recommendation 的 mapper:
// 查询用户的所有推荐
@Select("SELECT r.*, u.username, m.title as movie_title, m.poster_url FROM recommendation r " +
"LEFT JOIN user u ON r.user_id = u.id " +
"LEFT JOIN movie m ON r.movie_id = m.id " +
"WHERE r.user_id = #{userId} ORDER BY r.score DESC")
List<Recommendation> findByUserId(Long userId);这里的参数是 userId,当用户登录推荐系统进入推荐页面之后,在 Controller 中会通过 token 获取用户的 userId,然后通过 Service 传入 userId 到上面的 Mapper 方法中,查询用户的电影推荐。
// 获取用户的推荐列表
@PostMapping("/my-list")
public Result getMyRecommendationList(@RequestHeader("Authorization") String token) {
try {
if (token != null && token.startsWith("Bearer ")) {
token = token.substring(7);
if (!JwtUtil.validateToken(token)) {
return Result.error("Invalid token");
}
Long userId = JwtUtil.getUserIdFromToken(token);
List<Recommendation> recommendations = recommendationService.findByUserId(userId);
return Result.success(recommendations);
}
return Result.error("Invalid token");
} catch (Exception e) {
logger.error("Failed to get user recommendation list: {}", e.getMessage());
return Result.error(e.getMessage());
}
}然后接口返回数据,展示在用户的推荐页面。
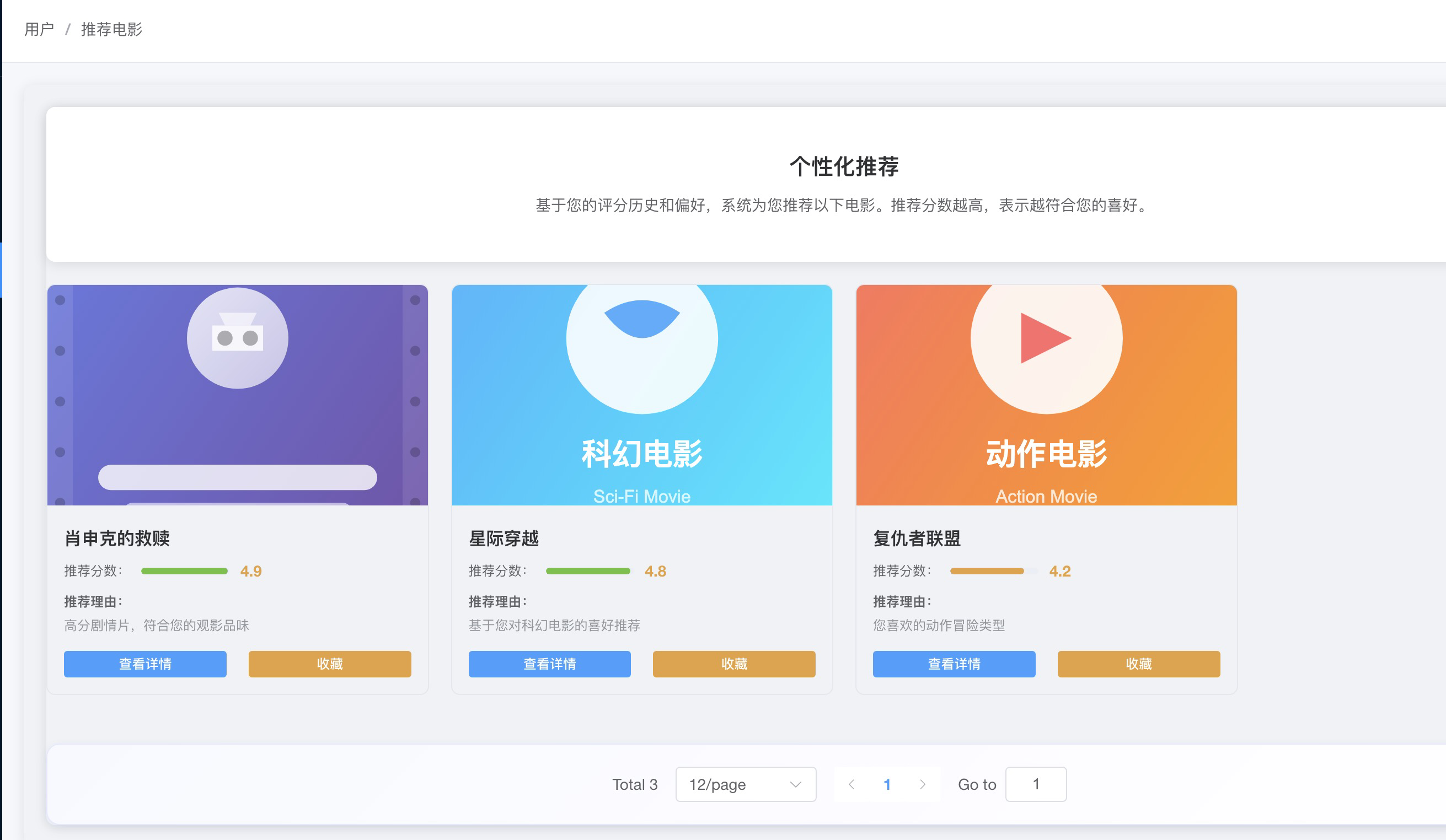
这样我们就实现了电影推荐系统和 Spark ALS 算法生成电影推荐结果数据的互通。
结语
本篇文章从之前的 Spark 推荐算法开始,涉及了数据准备、数据样例解释等前置步骤,也完成了算法推荐生成推荐数据的入库工作。在电影推荐系统中,我们通过部分代码阅读,将推荐算法和推荐系统串联起来,让大家更好的理解两者之间的关系。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号