Debezium 实战:几行代码,实现 MySQL CDC 数据采集
原创
Debezium 实战:几行代码,实现 MySQL CDC 数据采集
原创
叫我阿柒啊
发布于 2025-07-16 16:24:17
发布于 2025-07-16 16:24:17
前言
在上一篇零帧起手,Debezium 实现 MySQL CDC 有多简单 文章中,我通过 debezium 的官方文档学习了如何配置一个 engine 和 MySQL connector,来实现一个最简单的 cdc 采集程序,那本篇文章主要是理论实践,从代码实现入手,完成本地 MySQL 采集的流程开发。
采集实现
首先在 MySQL 中创建一个数据库和一个 test 表,并在表中插入数据,sql 如下:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS debezium CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
-- 使用数据库
USE debezium;
-- 创建表 test
CREATE TABLE IF NOT EXISTS test (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
age INT,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- 插入初始数据
INSERT INTO test (name, age) VALUES
('Alice', 25),
('Bob', 30),
('Charlie', 22);这样,我们就创建了 debezium 数据库、test 表,然后插入了三条数据。

程序开发
我们在 debezium 的配置中监听这个表的变化。
public class MySQLDebezium {
public static void main(String[] args) {
final Properties props = new Properties();
props.setProperty("name", "engine");
props.setProperty("connector.class", "io.debezium.connector.mysql.MySqlConnector");
props.setProperty("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");
props.setProperty("offset.storage.file.filename", "offsets.dat");
props.setProperty("offset.flush.interval.ms", "60000");
/* begin connector properties */
props.setProperty("database.hostname", "192.168.1.1.1");
props.setProperty("database.port", "3306");
props.setProperty("database.user", "root");
props.setProperty("database.password", "123456");
props.setProperty("database.server.id", "85744");
// props.setProperty("database.include.list", "debezium");
props.setProperty("table.include.list", "debezium.test");
props.setProperty("topic.prefix", "aqi");
props.setProperty("schema.history.internal", "io.debezium.storage.file.history.FileSchemaHistory");
props.setProperty("schema.history.internal.file.filename", "schemahistory.dat");
props.setProperty("converter.schemas.enable", "false");
try (DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine.create(Json.class)
.using(props)
.notifying(record -> {
System.out.println(record);
}).build()
) {
// Run the engine asynchronously ...
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);
for (;;) {}
} catch (IOException e) {
throw new RuntimeException(e);
}
// Do something else or wait for a signal or an event
}
}上面代码就是我按照官网做了一些修改,配置部分都是通用的,我们只需要关注的是 notifying 部分,这里实现了 debezium 采集的 MySQL 变更数据的逻辑。在代码的最后我增加了 for (;;) 自旋,不让 try 代码块结束,因为在 java17 中的 try 新写法,会在代码块执行完成之后自动关闭 engine,这样程序就会报错。
全量采集
在启动了程序之后,debezium 就采集了 test 表的全量快照,并在控制台打印出来了。

这里就不得不提 snapshot.mode 这个参数了,这个参数没有程序员中定义,因为它的默认值 initial,会先实现 test 表的全量快照,然后再我们定义的 offset.dat 文件中做好记录,然后再次启动的时候就会只采集新变更的数据。如果想要每次启动都是全量快照,则需要手动指定为 always。
所以上面采集到的就是我们上面的 sql 建表、插入数据的变更数据,同时打印的 record 是文本,如果我们需要三方 json 类去格式化,同时也可以在 notifying 中定义 KafkaProducer 将变更数据写入 kafka。
增量采集
同时在我们的项目目录下,也生成了两个文件:offset.dat 和 schemahistory.dat。当我们关闭程序再次启动的时候,就会发现控制台就不会打印变更数据了,因为 debezium 会从 offset.dat 中记录的位置开始消费,但 test 表中没有增量数据生成。
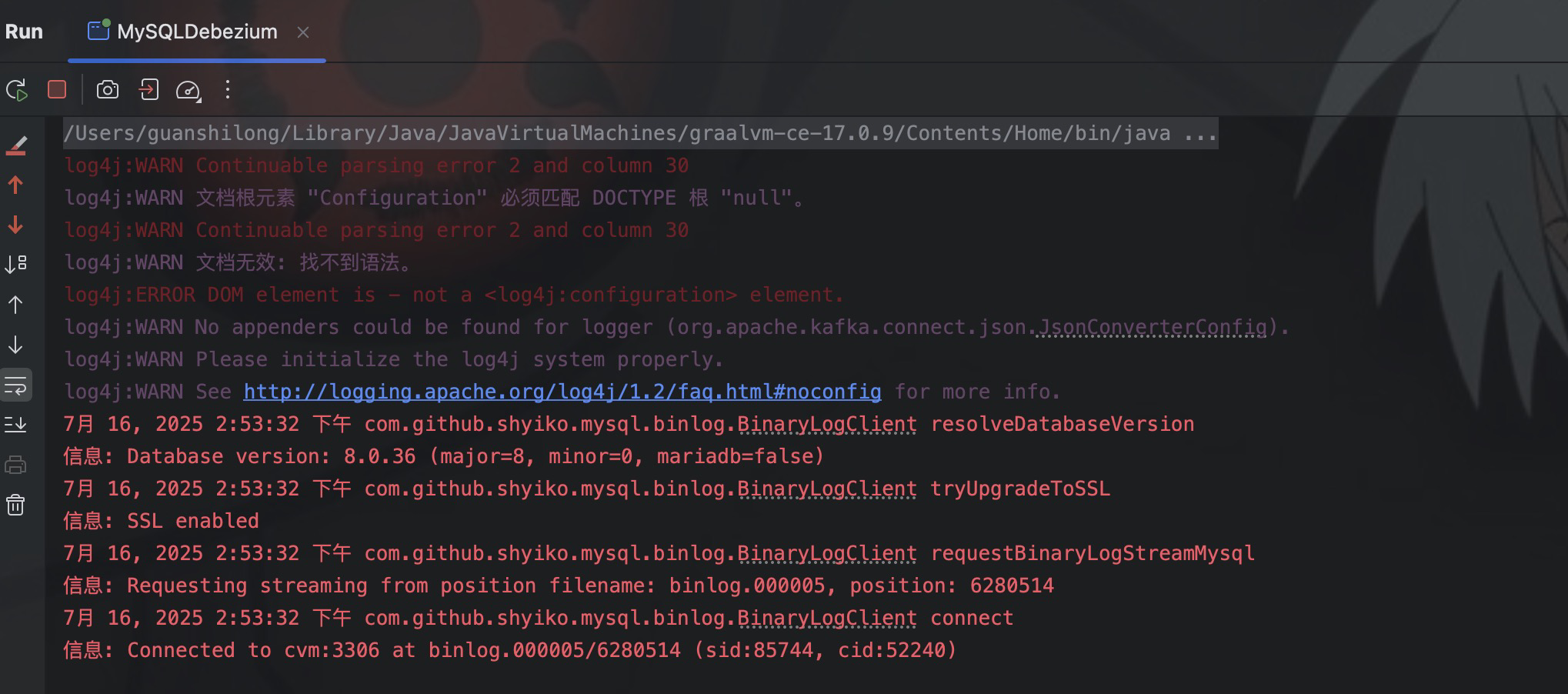
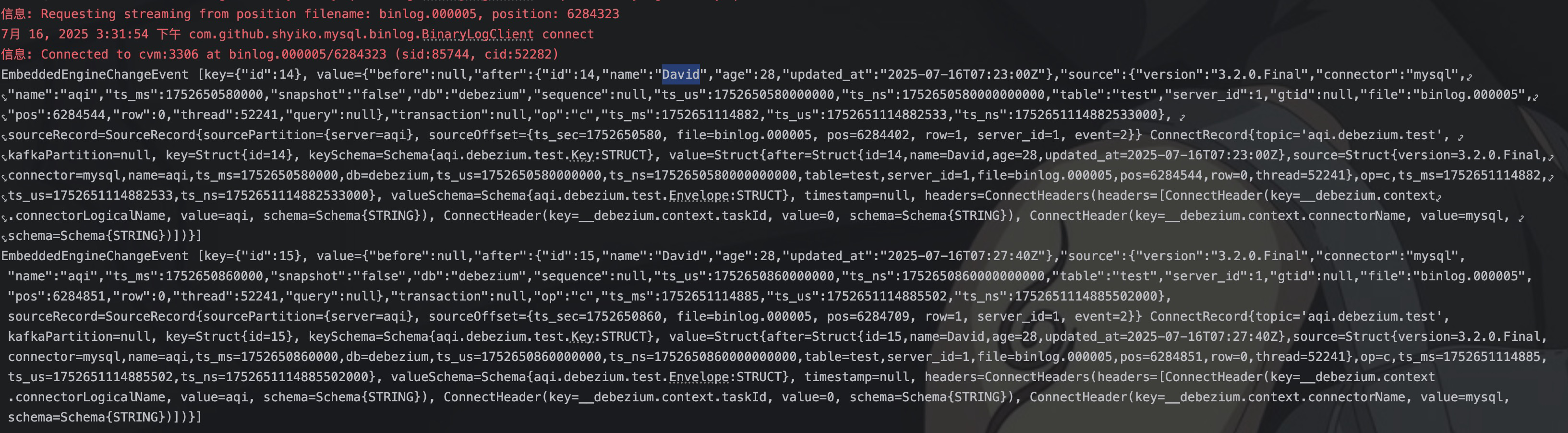
如果想要再次全量采集,可以将指定目录下的 offset.dat 删除之后重新启动即可。我们在 test 表中插入两条数据。

然后在控制台就捕获到了插入的变更数据。
结语
本篇文章主要从官方给出的样例,采集到了 MySQL 表中的数据,并打印到了控制台。在采集的过程中也遇到了很多问题,在下一篇文章中会详细列举遇到的问题、解决思路以及解决方案,同时在后面的文章中,也会对采集到的数据进行格式化处理以及写入 Kafka。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号