微服务数据一致性技术解析:从单体到微服务的数据困局

微服务数据一致性技术解析:从单体到微服务的数据困局

TechVision大咖圈
发布于 2025-06-25 08:31:33
发布于 2025-06-25 08:31:33
关键词: 微服务数据一致性, 企业应用, 技术架构, 最佳实践
本文基于多位资深架构师在大型互联网公司的实战经验总结,希望能为正在进行微服务改造的团队提供有价值的参考。如果您在实践中遇到问题,欢迎交流讨论!
一、引言:从单体到微服务的数据困局
还记得那个"美好"的单体应用时代吗?一个数据库,一个事务,天下太平。但当我们拆分成微服务后,突然发现数据一致性成了"头号敌人"。
想象一下,用户下单买了一台手机,库存服务减了1,订单服务创建了记录,但支付服务突然挂了。这时候问题来了:钱没扣,但库存没了,订单还在那儿"孤零零"地等着。这就是微服务架构中数据一致性的经典困局。
传统单体 vs 微服务数据处理
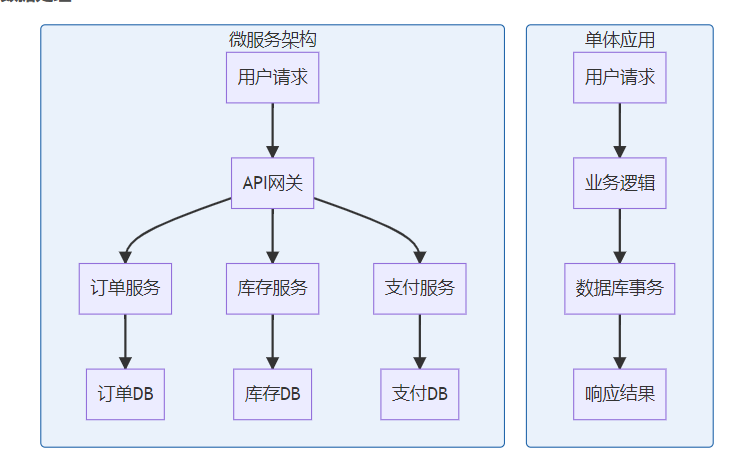
二、数据一致性的核心原理
2.1 CAP理论:不可能的三角
在分布式系统中,CAP理论告诉我们一个残酷的现实:一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance) 三者不可兼得。
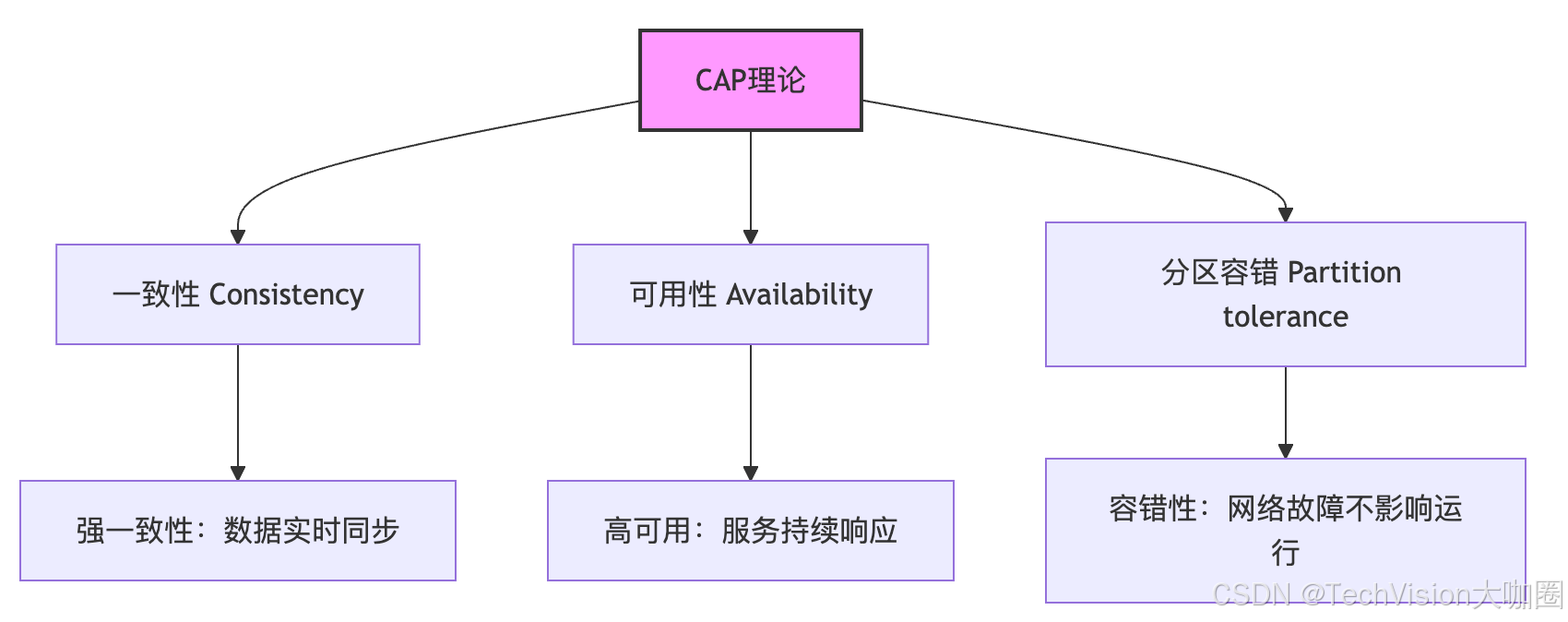
2.2 一致性的分类
根据一致性要求的强弱,我们可以将其分为:
强一致性:所有节点在同一时间看到的数据完全一致
- 适用场景:金融交易、账户余额
- 代价:性能较低,可用性受影响
最终一致性:系统保证在没有新的更新后,最终所有节点都会达到一致状态
- 适用场景:用户信息同步、商品信息更新
- 优势:性能好,可用性高
弱一致性:系统不保证何时能达到一致,但会尽力而为
- 适用场景:缓存数据、统计信息
- 特点:性能最优,但数据可能不准确
三、常见的一致性解决方案
3.1 分布式事务:2PC与3PC
**两阶段提交(2PC)**是最经典的分布式事务解决方案,但也是最"臭名昭著"的。
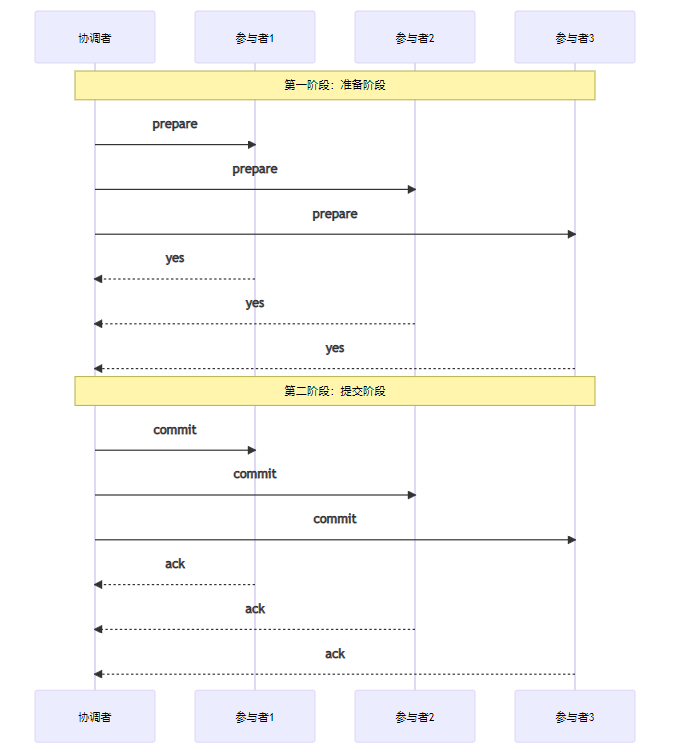
2PC的问题:
- 同步阻塞:所有参与者都要等待
- 单点故障:协调者挂了就全完了
- 数据不一致:网络分区时可能导致脑裂
3.2 Saga模式:化整为零的艺术
Saga模式将长事务拆分为多个短事务,每个短事务都有对应的补偿操作。这就像是"后悔药",出错了可以逐步回滚。
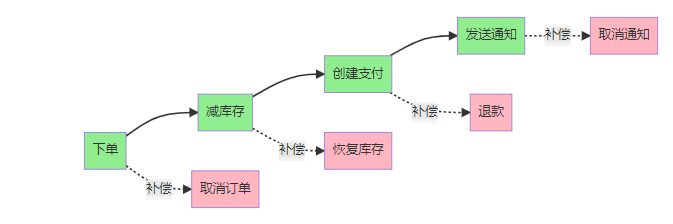
3.3 事件驱动架构:异步的魅力
通过事件总线实现服务间的松耦合通信,天然支持最终一致性。
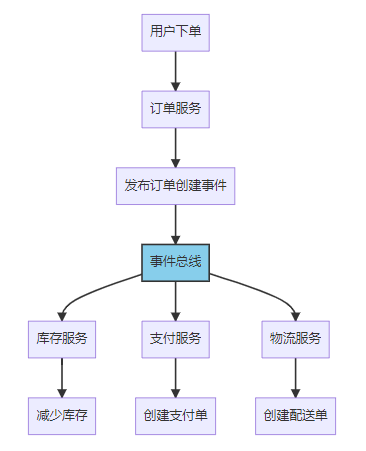
四、实战案例:电商系统的数据一致性实践
4.1 业务场景分析
让我们以一个典型的电商下单流程为例,看看在真实项目中是如何处理数据一致性的。
核心业务流程:
- 用户提交订单
- 检查商品库存
- 创建订单记录
- 扣减库存
- 创建支付单
- 发送确认通知
4.2 架构设计
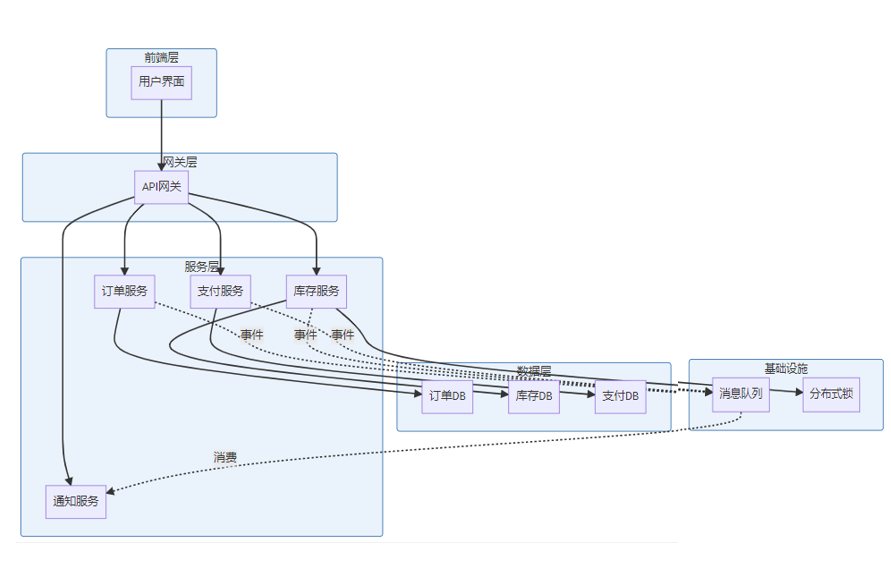
4.3 具体实现策略
第一步:引入分布式锁
// 伪代码示例
function processOrder(orderId, productId, quantity) {
// 获取分布式锁,防止超卖
lock = distributedLock.acquire("product:" + productId);
try {
// 检查库存
if (inventory.check(productId) >= quantity) {
// 预占库存
inventory.reserve(productId, quantity);
// 发布库存预占事件
eventBus.publish("InventoryReserved", {orderId, productId, quantity});
} else {
throw new InsufficientInventoryException();
}
} finally {
lock.release();
}
}第二步:使用Saga模式
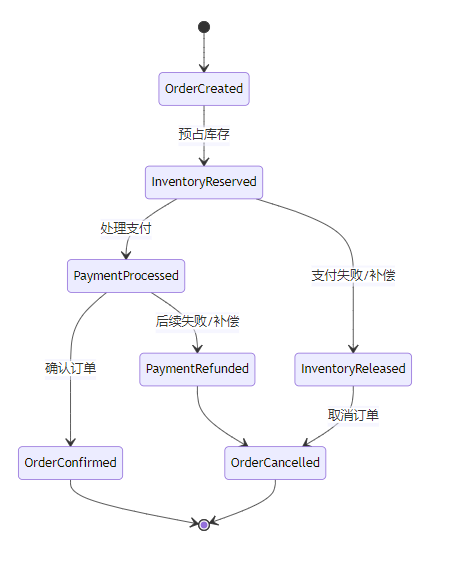
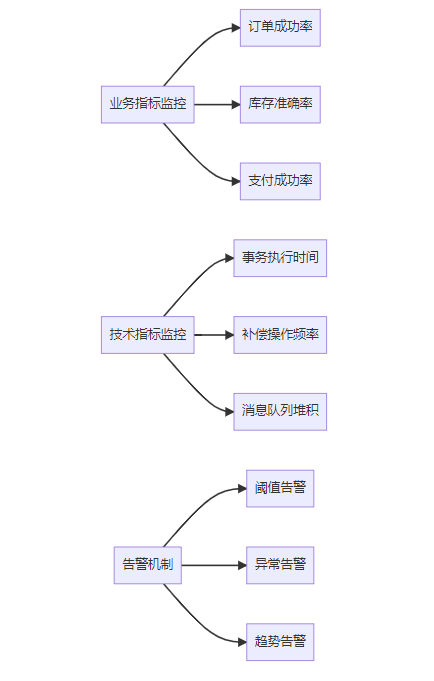
4.4 监控与告警
数据一致性问题往往是"静悄悄"的,所以监控至关重要:
五、技术选型与最佳实践
5.1 技术选型指南
选择合适的数据一致性方案需要考虑多个维度:
方案 | 适用场景 | 优势 | 劣势 | 推荐指数 |
|---|---|---|---|---|
2PC/XA事务 | 强一致性要求高的场景 | 保证强一致性 | 性能差,可用性低 | ⭐⭐ |
Saga模式 | 业务流程复杂的场景 | 性能好,容错强 | 实现复杂,需要补偿逻辑 | ⭐⭐⭐⭐ |
事件驱动 | 高并发,最终一致性 | 高性能,松耦合 | 调试困难,数据延迟 | ⭐⭐⭐⭐⭐ |
TCC模式 | 对性能和一致性都有要求 | 性能较好,一致性强 | 实现复杂度高 | ⭐⭐⭐ |
5.2 最佳实践总结
1. 业务设计原则
- 优先考虑业务幂等性设计
- 合理设计补偿操作
- 建立完善的监控体系
2. 技术实现建议
- 使用消息队列实现异步处理
- 引入分布式锁避免并发问题
- 设计熔断和降级机制
3. 运维管理要点
- 建立数据一致性检查机制
- 设计数据修复工具
- 制定应急处理预案
5.3 常见坑点避免指南
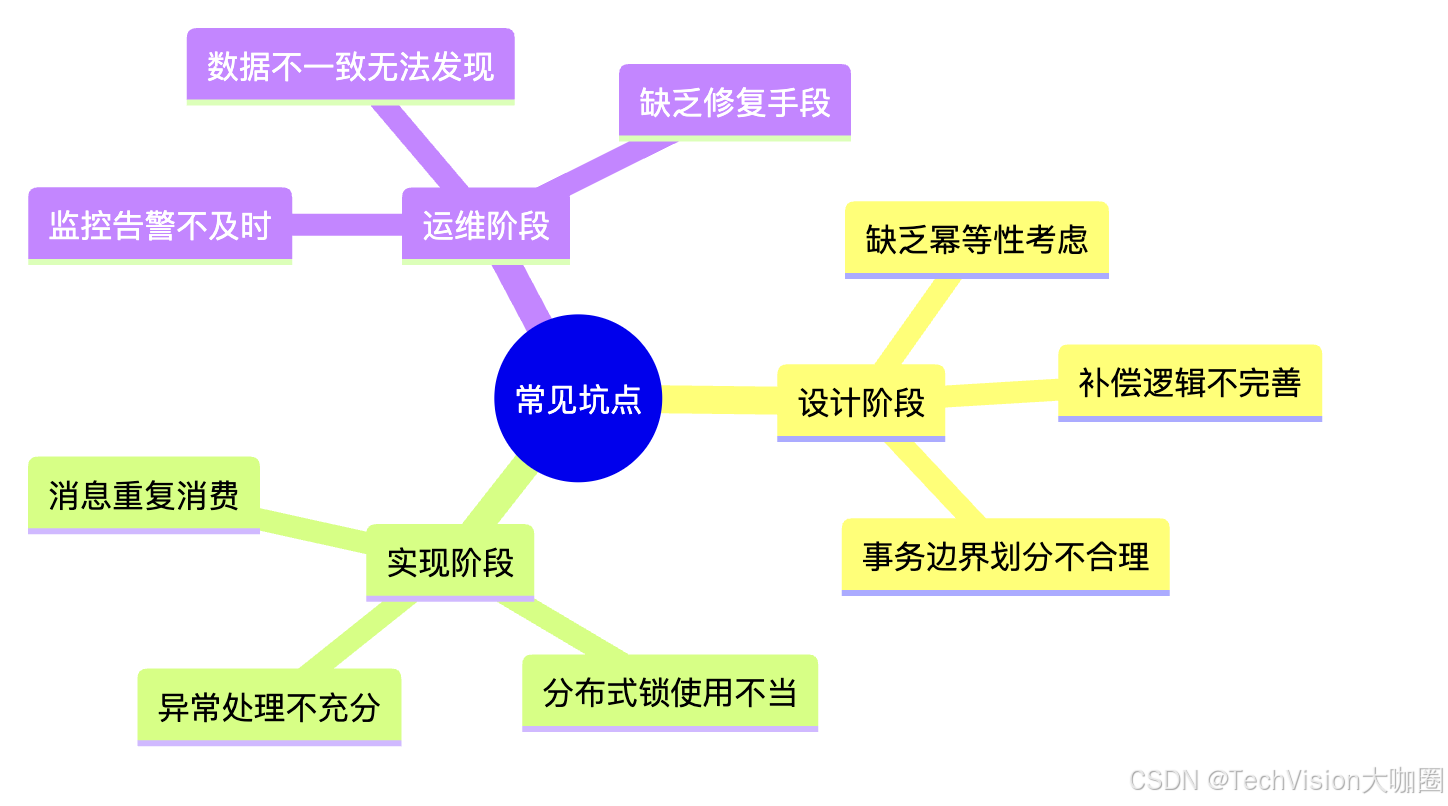
六、总结与展望
数据一致性在微服务架构中确实是个"硬骨头",但掌握了正确的方法和工具,这个问题就不再那么可怕了。
核心要点回顾:
- 没有银弹:根据业务场景选择合适的方案
- 监控先行:问题发现比问题解决更重要
- 渐进改进:从简单方案开始,逐步优化
- 团队共识:确保团队对数据一致性有统一认知
未来发展趋势:
- 更智能的自动化补偿机制
- 基于AI的异常检测和修复
- 更完善的可观测性工具链
微服务的数据一致性之路虽然充满挑战,但正是这些挑战让我们的系统变得更加健壮和优雅。记住,最好的架构不是没有问题的架构,而是能够优雅处理问题的架构。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号