复杂多样本10X单细胞数据整理及读取流程(Python)
原创

其实,如果数据很少的话可以选择手动整理。
既往整理过R语言版本的读取流程:常见不同单细胞数据类型的读取及Seurat对象创建方法整理(单多样本/10X/h5/txt/csv/tsv),https://mp.weixin.qq.com/s/p32aRJcBdyoBi1kooYO2LA
此外也整理过简单的多样本10X单细胞数据整理及读取流程:Seurat和h5ad数据相互转化以及10X多样本数据整理和读取(Python),https://mp.weixin.qq.com/s/kz_J2C5Eg0sV8affQrU7Fg
选择了GSE259229数据集~
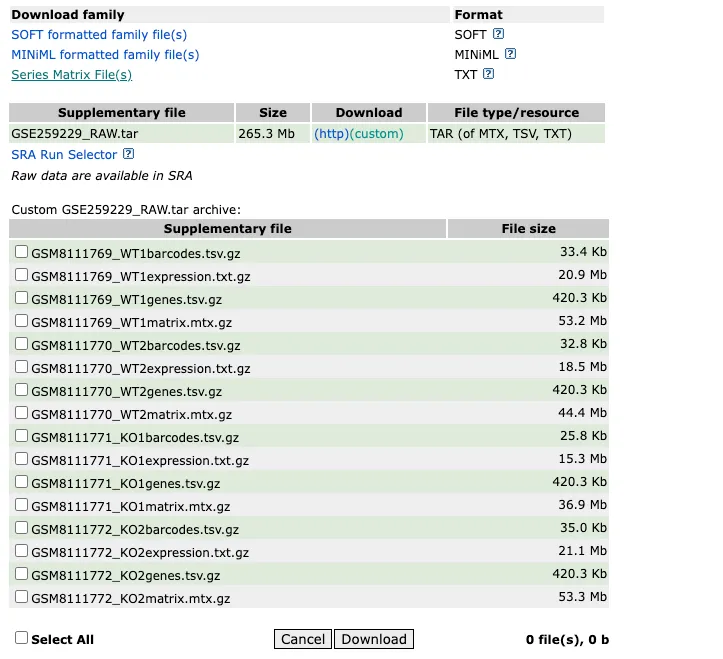
整理及读取流程
1.导入
import os
import scanpy as sc
import pandas as pd
import tarfile # 解压缩文件的库2.获取当前文件路径
path = os.getcwd()
path3.解压缩
# 解压缩
tar_path = "GSE259229_RAW.tar"
exreact_path = "GSE259229_RAW"
# 解压缩
with tarfile.open(tar_path,"r") as tar:
tar.extractall(path = extract_path) # extractall(...): 表示将 .tar 文件中的所有内容全部解压出来
# 查看解压后的文件列表
files = os.listdir(exreact_path)
print(files)4.提取样本名称,并重新创建新的数据文件夹
folder = "GSE259229_RAW"
filenames = [f for f in os.listdir(folder) if not f.startswith(".")]
# 提取下划线 _ 前的样本名,并去重
samples = list({f.split("_")[0] for f in filenames})
print(samples)
# 3. 创建对应的文件夹
base_dir = "0_GSE259229"
for sample in samples:
dir_path = os.path.join(base_dir, sample)
os.makedirs(dir_path, exist_ok=True)
# 查看创建好的子文件夹
print(os.listdir(base_dir))5.获取文件并移动位置
import shutil
# 1.获取每个文件的路径
folder = "GSE259229_RAW"
base_dir = "0_GSE259229"
fs = [os.path.join(folder, f) for f in os.listdir(folder)]
print(fs)
# 2. 提取原始文件夹中的文件名称,按照自己的文件要求提取样本名称
filenames = [f for f in os.listdir(folder) if not f.startswith(".")]
samples = list({f.split("_")[0] for f in filenames})
# 3.然后把文件夹中构成每个样本的文件移动到对应的文件夹中去
for file_path in fs: # 第一层循环:遍历所有文件的完整路径
for sample in samples: # 第二层循环:遍历每个样本名
if sample in file_path: # 判断这个样本名是否出现在文件路径中
dest_dir = os.path.join(base_dir, sample) # 拼接出目标目录路径
os.makedirs(dest_dir, exist_ok=True) # 如果目标目录不存在就创建
shutil.copy(file_path, dest_dir) # 复制文件到目标目录
break # 一旦匹配成功就跳出内层循环,防止重复复制
# 查看某个样本文件夹的文件
print(os.listdir(base_dir))
6.文件重命名
import re
# 获取base_dir路径下所有文件的名称
base_dir = "0_GSE259229"
for root, dirs, files in os.walk(base_dir):
for f in files:
if f.startswith("."):
continue # 跳过隐藏文件
old_path = os.path.join(root, f)
# 正则说明:
# ^GSM\d+_ 匹配开头 GSM+数字+下划线
# [A-Z]{2}\d+ 匹配WT1、KO2、WT2等(两个大写字母+数字)
# 替换成空字符串,即去除这部分
new_fname = re.sub(r'^GSM\d+_[A-Z]{2}\d+', '', f)
# 去掉可能多余的下划线
new_fname = new_fname.lstrip('_')
new_path = os.path.join(root, new_fname)
print(f"Renaming:\n {old_path}\n→ {new_path}\n")
os.rename(old_path, new_path)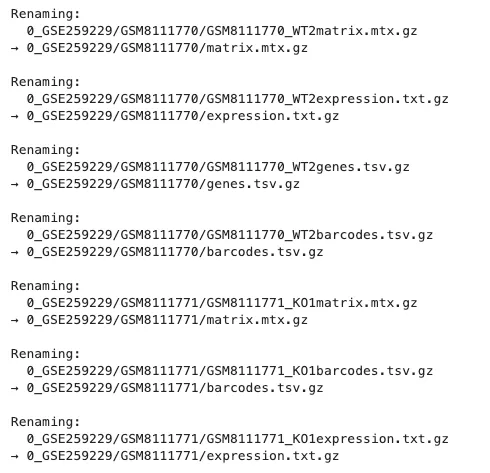
7.对多余文件进行处理
# 把只有包含expression的文件进行额外处理
import os
import shutil
base_dir = "0_GSE259229"
base_dir_abs = os.path.abspath(base_dir) # 获取绝对路径
parent_dir = os.path.dirname(base_dir_abs) # 获取上游路径
new_dir = os.path.join(parent_dir, "expression_GSE259229") # 创建新的文件夹
if not os.path.exists(new_dir):
os.makedirs(new_dir)
# os.walk()是递归遍历工具。在每一层目录中产生一个三元组:
#root 当前正在遍历的目录的路径
#dirs 当前目录下的所有子目录名(列表)
#files 当前目录下的所有文件名(列表)
for root, dirs, files in os.walk(base_dir):
for f in files:
if f == "expression.txt.gz": #对expression.txt.gz文件额外处理
old_path = os.path.join(root, f)
# 从路径里拿到GSM号,假设GSM号就是当前目录名
gsm_id = os.path.basename(root) # os.path.basename用于获取路径中的最后一部分
new_fname = f"{gsm_id}_{f}"
new_path = os.path.join(new_dir, new_fname)
print(f"Moving and renaming:\n {old_path}\n→ {new_path}\n")
shutil.move(old_path, new_path)
8.再次解压缩文件
import gzip
# 解压缩
base_dir = "0_GSE259229"
for root, dirs, files in os.walk(base_dir):
for f in files:
if f.endswith(".gz"):
gz_path = os.path.join(root, f)
out_path = os.path.join(root, f[:-3]) # 去掉 .gz 后缀
print(f"解压 {gz_path} 到 {out_path}")
with gzip.open(gz_path, 'rb') as f_in:
with open(out_path, 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)9.提取样本名称
dir_path = "0_GSE259229"
samples = [s for s in os.listdir(dir_path) if not s.startswith('.')]
print(samples)10.读取样本
sce_list = []
for sample in samples:
sample_path = os.path.join(dir_path, sample)
# 读取10X格式数据
adata = sc.read_10x_mtx(sample_path, var_names='gene_symbols', cache=True)
# 过滤:至少5个细胞的基因,至少500个基因的细胞 (对应min.cells和min.features)
sc.pp.filter_genes(adata, min_cells=5)
sc.pp.filter_cells(adata, min_genes=500)
# 给AnnData添加项目名称
adata.obs['sample'] = sample
# 给细胞名加前缀,防止重复
#adata.obs_names = [f"{sample}_{cell}" for cell in adata.obs_names]
sce_list.append(adata)sce_list
adata = sc.concat(sce_list) #,label='sampleid',index_unique='_')
adata.obs_names_make_unique()
adataadata.obs
11.保存样本
adata.write('./0_GSE259229/GSE259229.h5ad')注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多相关内容可关注公众号:生信方舟 。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号