真实场景文档理解:字节发布的WildDoc基准数据集向OCR提出了什么挑战?
原创
真实场景文档理解:字节发布的WildDoc基准数据集向OCR提出了什么挑战?
原创
合合技术团队
发布于 2025-06-11 11:19:54
发布于 2025-06-11 11:19:54
最近,字节跳动团队联合华中科技大学发布的基准数据集 WildDoc 引起了对 OCR 能力的再衡量。WildDoc是首个专为评估自然环境中文档理解能力而设计的基准,它融合了一系列反映真实世界条件的人工捕获的文档图像,选取了 3 个常用的具有代表性的文档场景作为基准(Document/Chart/Table), 包含超过 12,000 张手动拍摄的图片,覆盖了环境、光照、视角、扭曲和拍摄效果等五个影响真实世界文档理解效果的因素。
根据字节团队的介绍,WildDoc 的采集开发主要针对文档理解领域现有的两个问题:
- 脱离真实场景:现实中文档多为手机 / 相机拍摄的纸质文件或屏幕截图,面临光照不均、物理扭曲(褶皱 / 弯曲)、拍摄视角多变、模糊 / 阴影、对焦不准等复杂干扰;
- 无法评估鲁棒性:现有基准未模拟真实环境的复杂性和多样性,导致模型在实际应用中表现存疑。
我们可以看一下 WildDoc 数据集中的样本示例:

为了全面评估现有模型,WildDoc 构建了一个新的鲁棒性指标:Consistency Score,用来评估模型是否能够始终如一地处理现实世界中的各种情况。研究团队对众多具有代表性的 MLLMs 进行了测试,实验发现主流 MLLMs 在 WildDoc 上性能显著下降,例如,GPT-4o 平均准确率下降 35.3%,揭示了现有模型在真实场景文档理解的性能瓶颈。
研究结果提出了几点发现:
- 物理扭曲最具挑战性:皱纹、褶皱、弯曲等物理变形导致模型性能下降最显著,远超光照或视角变化的影响。
- 非正面视角与图像质量:非正面拍摄(如倾斜视角)因文本形变和模糊导致性能下降,但屏幕捕获图像因数据增强算法成熟,性能下降较小。
- 语言模型规模影响有限:大参数量模型在 WildDoc 上表现略优,但未完全克服真实场景挑战,表明模型架构需针对性优化。
为什么要关注自然场景文档解析?
在 AI 时代,文档解析技术已经广泛应用于扫描文档的文本识别。然而,当用户用手机拍摄真实环境中的文档时,往往会受到环境光照不均、视角倾斜、扭曲变形或拍摄抖动等因素的干扰,导致传统解析方法失效。WildDoc 所提出的也正是这个问题:对于这些“不完美”的输入,要怎么提升识别的准确性和鲁棒性?
解析技术在这一领域的进步,能显著提高日常效率,减少手动输入错误,并推动 AI 助手等智能应用。在移动设备普及的今天,自然场景下的扫描解析需求量仍在持续增加。
以学习场景为例,在线下课堂上,学生用手机能够快速拍摄老师的板书或讲义,用于课后复习或共享,但现实情况下,教室光线不足、角度倾斜或手写潦草会导致图像模糊或扭曲,传统 OCR 难以识别。如果解析技术能克服这些因素,学生就能一键提取文本,生成可编辑笔记,提升学习效率。
工作办公时,这类情况也十分常见:大家在会议中拍摄白板或投屏上的草图或手写笔记,方便后续整理和协作。但环境因素如反光、视角偏移、摩尔纹或文档弯曲常使图像失真。高效的自然场景解析能自动校正并提取内容,取代手动整理,节省机械性劳动时间。
这些场景涉及了数十亿级的普通用户,关注自然场景文档解析不仅是技术演进的需求,更是让 AI 工具更贴近生活,释放更大的实用价值。
文档解析产品给出了什么样的答案?
面对自然环境图片可能会出现的页面弯曲、阴影遮挡、摩尔纹、图片模糊、字迹不清晰等等问题,当前文档解析工具主要采用图片预处理的方式,通过图像处理算法,最大程度上排除干扰状况,还原文字与版面信息。

图像预处理流程示例
以 TextIn xParse 为例,我们选取了 WildDoc 数据集中的部分有代表性的样本进行测试,来看一下识别结果:

样本原图

预处理矫正结果与解析输出
如图样本有明显折叠干扰,图片预处理对其进行切边矫正,通过算法实现“展平”的效果,进一步完成正确解析。

样本原图

预处理矫正结果与解析输出
上图为弯曲样本,同时光线较暗,解析结果需要正确识别文本与标题。

样本原图
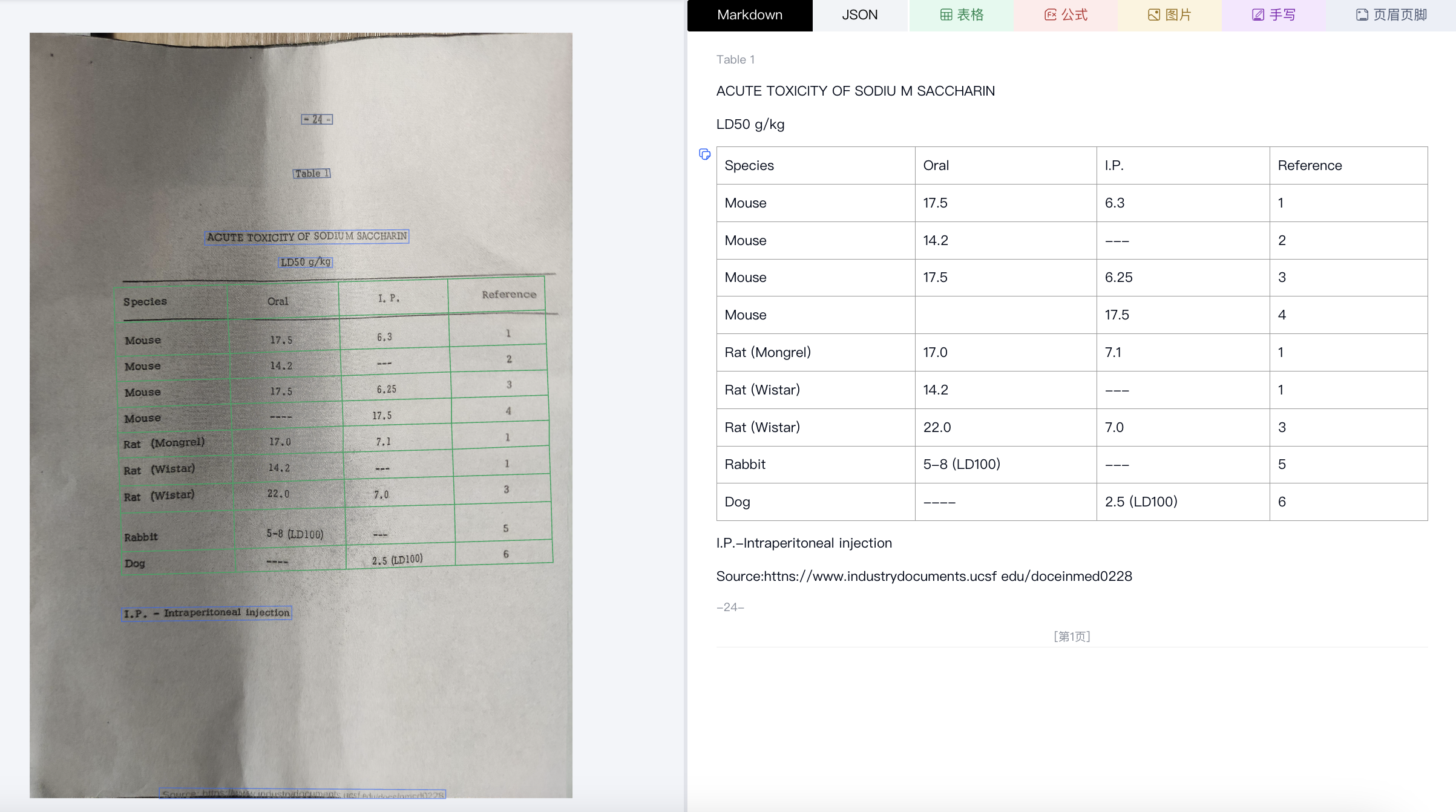
预处理矫正结果与解析输出
另一个典型的向内弯曲样本,且为表格信息,弯曲畸变易对表格识别与行列位置信息还原造成干扰,在经过图像处理算法矫正后,我们可以看到正确的表格还原。
使用说明:
1 在线使用

在 TextIn xParse 参数配置栏勾选【切边矫正】,提升拍摄角度不正或歪曲变形的照片的识别效果。
目前该功能已全面上线,限时免费开放使用。
2 API调用
步骤一:登录 TextIn 官网 TextIn - API 中心,获取 app-id 和 secret-code。
步骤二:调用官方示例代码。
步骤三:将下列切边矫正增强功能的参数集成到代码中,一键替代源代码中的 48-62 列。
resp = textin.recognize_pdf2md(image, {
'crop_enhance':1, # 切边矫正增强功能的控制参数
})
result = json.loads(resp.text)
filepath = 'pdf2md_remove_watermark.md'
with open(filepath, 'w', encoding='utf-8') as f:
f.write(result['result']['markdown'])步骤四:运行最终替换好的代码并得到切边矫正后识别更精准的解析文件。
欢迎后台私信小助手,开通免费试用,来交流群与我们共同探讨技术发展与 AI 应用的可能性。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号