单细胞数据的纵向、横向和比例条形图(柱状图)绘制(Python)
原创
单细胞数据的纵向、横向和比例条形图(柱状图)绘制(Python)
原创
凑齐六个字吧
发布于 2025-06-10 20:37:16
发布于 2025-06-10 20:37:16
在R语言中有个强大的R包ggplot2,它能够帮助我们完成很多绘图工作,方便又好用。Python环境中用于绘图可能会比较常用mamatplotlib,seaborn,plotly以及ggplot(Python),本次就用mamatplotlib和seaborn来进行横向和比例条形图的绘制。
R语言版本的横向和比例条形图也在既往的推文中出现过:https://mp.weixin.qq.com/s/nuFHE4AyUMsBvbGbEhDxBg
绘制流程
1.导入
# 可以选择延续scanpy中创建的环境也就是sc
# 激活环境
conda activate sc# 服务器就自己登陆
# 自己的电脑就去终端上输入
jupyter lab加载库(顺手都加载了),其实绘制柱状图的核心是matplotlib.pyplot和pandas库
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import scanpy as sc
import numpy as np
import anndata as ad
import pooch
import os# 确定位置,自己修改
os.getcwd()2.读取位置
# 路径要结合实际情况
adata = sc.read_h5ad('~/scRNA_V5.h5ad')adata.obs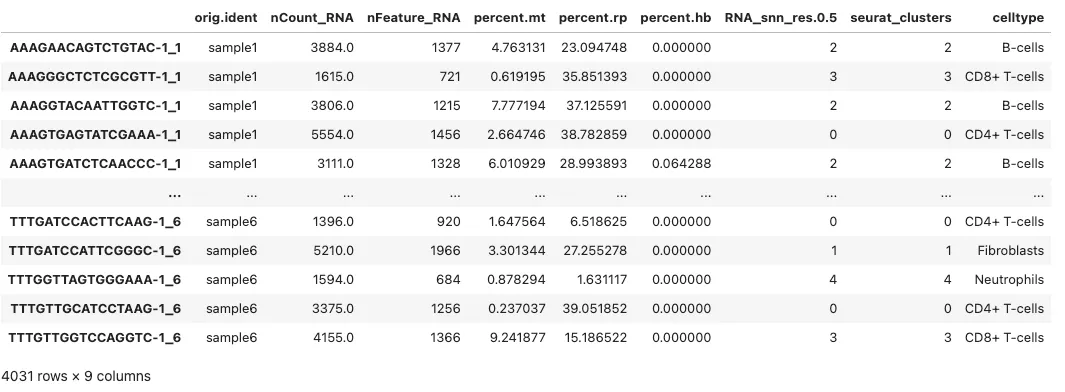
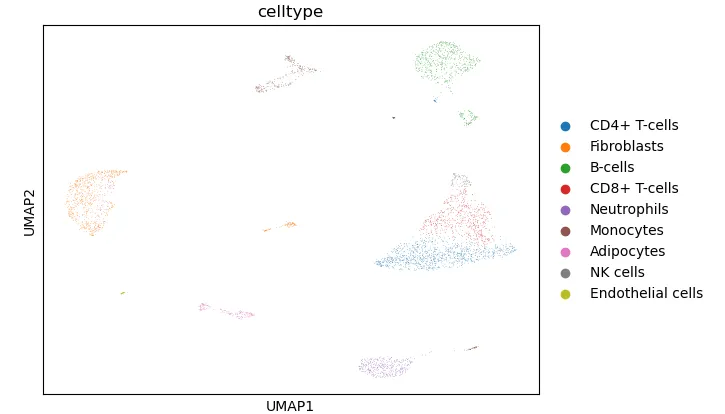
检查一下“老演员”。
sc.pl.umap(
adata, # AnnData 对象
color="celltype", # 按 celltype 分组上色
size=0.8, # 点大小,类似 pt.size
legend_loc='right margin', # 在图上显示标签,等价于 label = TRUE
ncols=2, # 控制子图排列列数
title=None, # 可选:不显示默认标题
show =False
)
3.数据预处理
提取数据
# 统计celltype数量
dat = adata.obs["celltype"].value_counts().reset_index()
dat.columns = ['Celltypes', 'Cell_num']
dat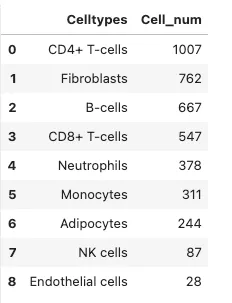
# 使用pd.Categorical进行排序并增加label列
dat['Celltypes'] = pd.Categorical(dat['Celltypes'],
categories=['CD4+ T-cells',
"Fibroblasts",
"B-cells",
"CD8+ T-cells",
"Neutrophils",
"Monocytes",
"Adipocytes",
"NK cells",
"Endothelial cells"], # 可以对每个细胞进行排序,也可以直接写celltype
ordered=True)
# dat.rename(columens={old_index1: new_index1, old_index2: new_index2}, inplace=True) 还有这种直接映射的
dat["label"] = dat["Celltypes"].astype(str)+":"+ dat["Cell_num"].astype(str)
dat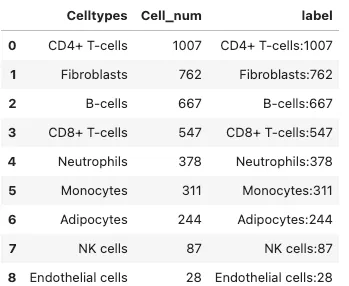
4.纵向条形(柱状)图绘制
# 自定义颜色(使用tab20调色板)
mycolors = sns.color_palette('tab20', len(dat))
# 创建图形(调整尺寸适应纵向图)
plt.figure(figsize=(10, 6)) # 宽度>高度更适合纵向图
# 绘制纵向柱状图(交换x/y轴即可)
barplot = sns.barplot(
data=dat,
x='Celltypes', # 现在x轴是类别
y='Cell_num', # y轴是数值
palette=mycolors
)
# 在每个柱子上方显示细胞数
for i, value in enumerate(dat['Cell_num']):
barplot.text(
x=i, # x坐标对应柱子索引
y=value + 0.01 * max(dat['Cell_num']), # y坐标在柱子顶部稍上方
s=str(value), # 显示细胞数值
ha='center', # 水平居中
va='bottom', # 垂直底部对齐
fontsize=10
)
# 美化样式
plt.xticks(
rotation=45, # 旋转45度防止文字重叠
ha='right', # 旋转后右对齐更美观
fontsize=12
)
plt.xlabel('') # 隐藏x轴标签
plt.ylabel('Cell Number', fontsize=12) # 显示y轴标签
plt.title("Cell Type Distribution", pad=20) # 添加标题(pad增加间距)
# 调整布局并保存
plt.tight_layout()
plt.savefig('vertical_cell_num.pdf', bbox_inches='tight', dpi=300)
plt.show()
5.横向条形(柱状)图绘制
其实横向和纵向的变化关键在于sns.barplot中的x,y中输入了什么数据。
# 自定义颜色(可以根据R里mycolors换成想用的颜色)
mycolors = sns.color_palette('tab20', len(dat)) # len函数可以返回多少行数
# 画横向柱状图
plt.figure(figsize=(7, 8))
barplot = sns.barplot(
data=dat, # 用的数据来源是DataFrame dat
y='Celltypes', # y轴对应的列是 dat 中的 'Celltypes',作为分类变量(类别标签)
x='Cell_num', # x轴对应的列是 dat 中的 'Cell_num',作为数值大小(柱子长度)
palette=mycolors # 使用自定义颜色列表 mycolors 给不同的类别上色
)
# 在条形左侧显示标签
for i, (value, label) in enumerate(zip(dat['Cell_num'], dat['label'])):
barplot.text(
x=0, # 文字的横坐标位置,放在x=0,也就是条形的起点位置
y=i, # 文字的纵坐标位置,对应第i个条形(条形在y轴的第i个位置)
s=label, # 要显示的文字内容,来自dat['label'],比如 "Bcell:50"
va='center', # 文字垂直方向居中对齐
ha='left', # 文字水平方向左对齐
fontsize=12, # 文字大小
color='black' # 文字颜色
)
# 美化样式
plt.xlabel('')
plt.ylabel('')
plt.title("Celltypes")
plt.xticks(rotation=45, fontsize=10, color='black')
plt.yticks([])
plt.tight_layout()
plt.savefig('column_cell_num.pdf',bbox_inches='tight',dpi=300)
plt.show()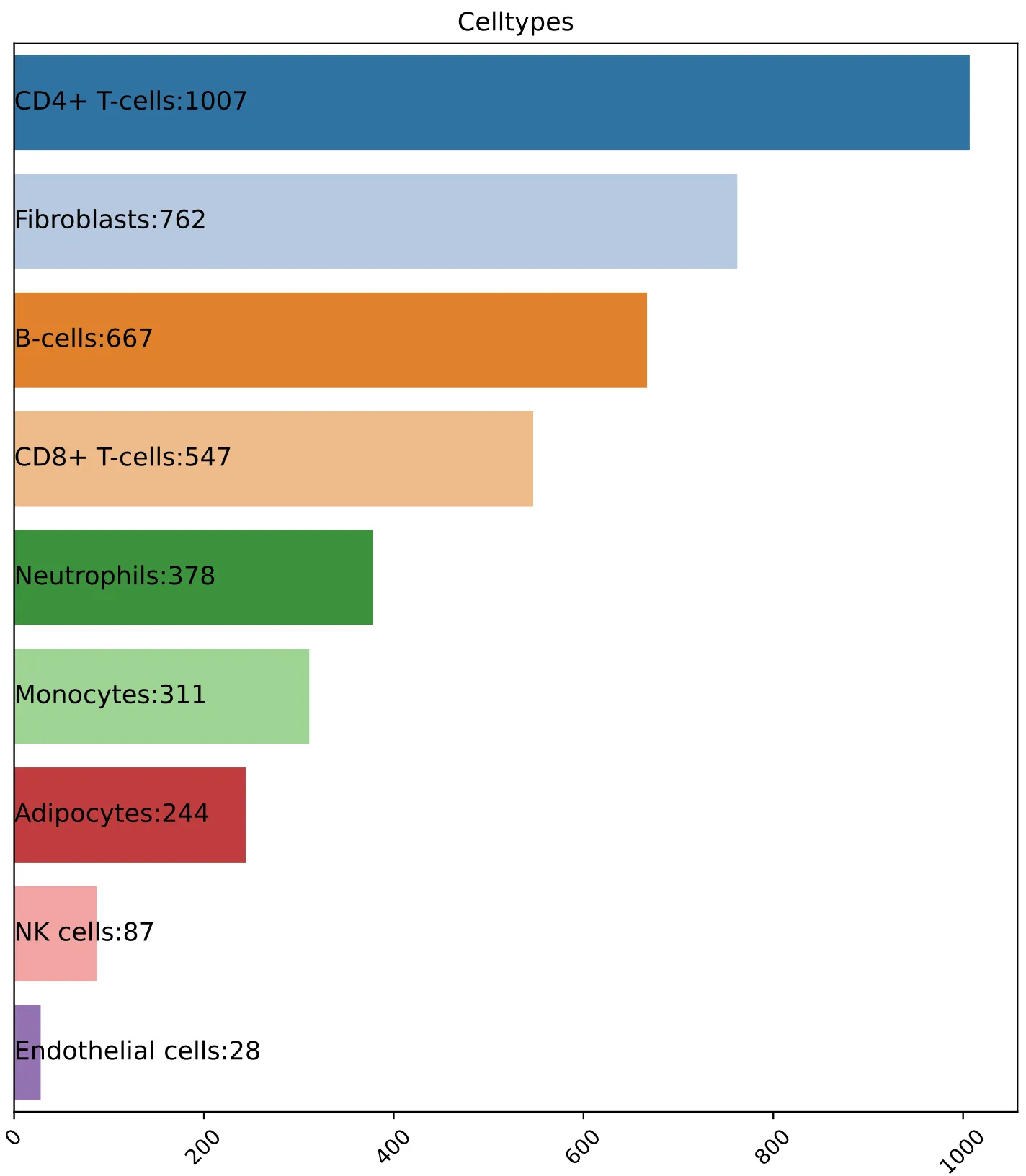
这里可以用大模型对里面的一句代码进行解释:for i, (value, label) in enumerate(zip(dat['Cell_num'], dat['label']))
# 假设数据如下
dat = {
'Cell_num': [1007, 762, 667],
'label': ['CD4+ T-cells', 'Fibroblasts', 'B-cells']
}
# zip 后的效果
list(zip(dat['Cell_num'], dat['label']))
# 结果:
# [(1007, 'CD4+ T-cells'),
# (762, 'Fibroblasts'),
# (667, 'B-cells')]# enumerate 添加索引后
list(enumerate(zip(dat['Cell_num'], dat['label'])))
# 结果:
# [
# (0, (1007, 'CD4+ T-cells')),
# (1, (762, 'Fibroblasts')),
# (2, (667, 'B-cells'))
# ]也就是通过zip和enumerate的组合拳形式构建了每个细胞的细胞数和需要展示的文字内容。
6.细胞比例条形图
# 想把所有样本和细胞类型相同的归为一组,groupby(["orig.ident", "celltype"]):按照 orig.ident 和 celltype 两列对细胞进行分组。
# size每个分组的 总行数(无论有没有 NaN),而conut每个分组中 每一列的非 NaN 数量
count_df = adata.obs.groupby(["orig.ident","celltype"]).size().reset_index(name = "count")
# 计算比例 lambda x: x / x.sum() * 100,计算当前组内各项的百分比
count_df["Proportion"] = count_df.groupby(["orig.ident"])["count"].transform(lambda x:x/x.sum()*100)
# 长数据改成宽数据格式
pivot_df = count_df.pivot(index="orig.ident", columns="celltype", values="Proportion").fillna(0)
pivot_df.to_csv("pivot_df.csv")
pivot_df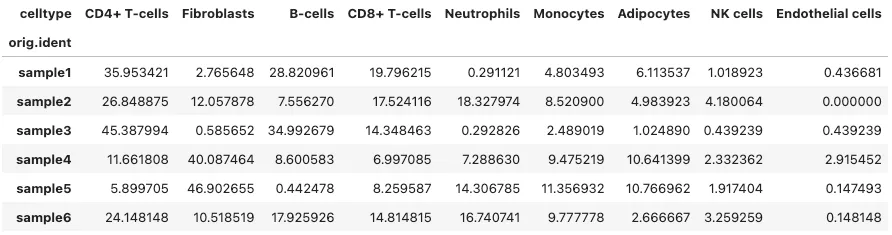
# 自定义颜色,替换为你自己的颜色字典,key是celltype名称
mycolors = {
'CD4+ T-cells':"#326795",
"Fibroblasts":"#aec0db",
"B-cells":"#da7a31",
"CD8+ T-cells":"#e9b581",
"Neutrophils":"#318736",
"Monocytes":"#94ce8c",
"Adipocytes": "#b63b3a",
"NK cells":"#ef9d9a",
"Endothelial cells":"#8a66a7",
}
# 开始画图
plt.figure(figsize=(7, 8)) # 单位为英寸
bottom = pd.Series([0] * len(pivot_df), index=pivot_df.index)
x = pivot_df.index # 样本名,x轴坐标
for celltype, color in mycolors.items():
if celltype in pivot_df.columns:
plt.bar(x, pivot_df[celltype],
bottom=bottom,
label=celltype,
color=color,
alpha=0.9)
bottom += pivot_df[celltype]
plt.title('Celltype Proportion per types', fontsize=14)
plt.xlabel('Types', fontsize=12)
plt.ylabel('Proportion (%)', fontsize=12)
plt.xticks(rotation=45, ha='right', fontsize=10)
plt.yticks(fontsize=10)
plt.legend(title='Celltypes', bbox_to_anchor=(1.05, 1), loc='upper left', fontsize=10)
plt.tight_layout()
plt.savefig("stacked_bar_celltypes_vertical.pdf", dpi=300, bbox_inches='tight')
plt.show()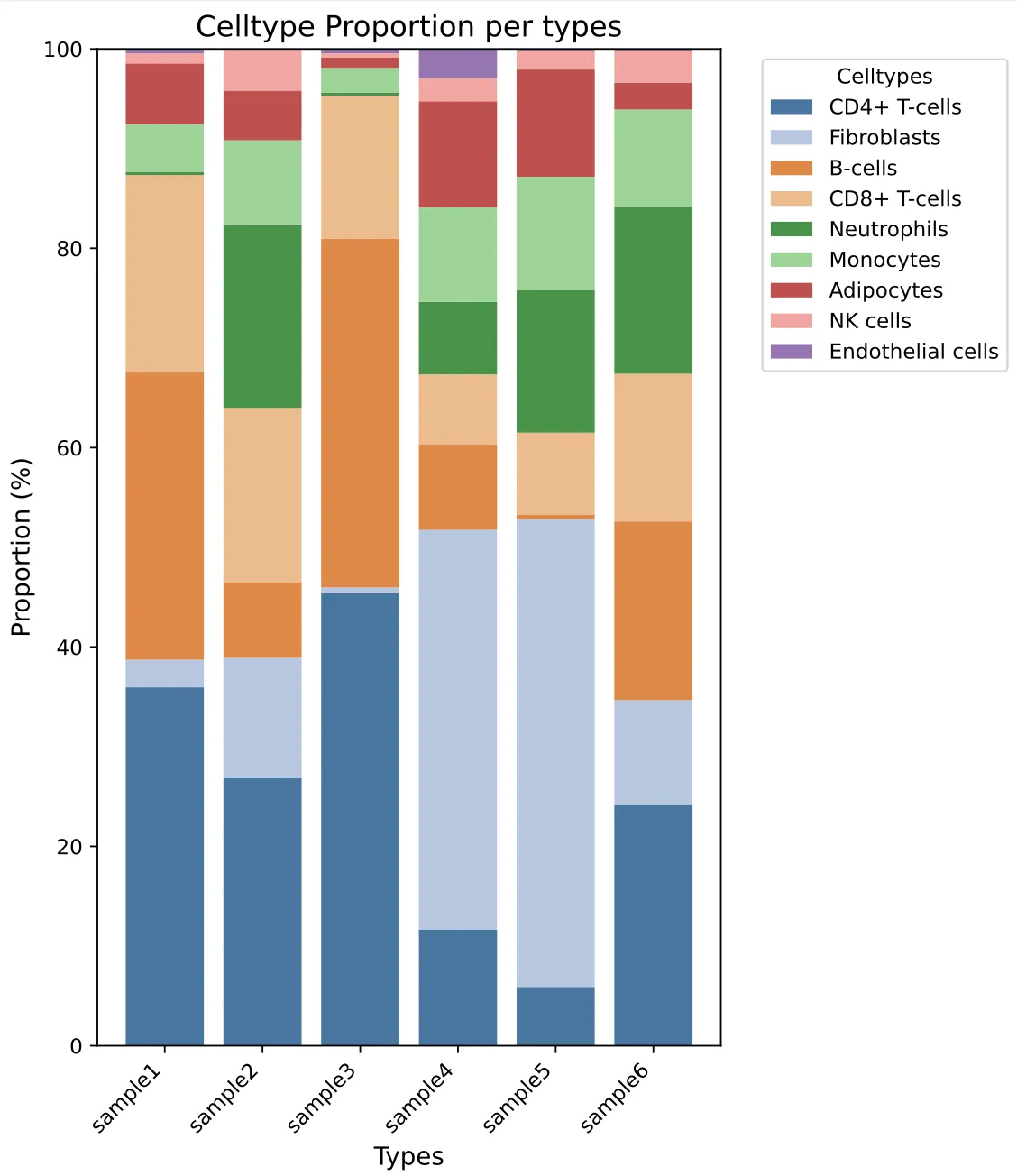
参考资料
- pandas:https://pandas.pydata.org/
- matplotlib.pyplot:https://matplotlib.org/3.5.3/api/_as_gen/matplotlib.pyplot.html
注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多相关内容可关注公众号:生信方舟 。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号