【深度学习优化算法】02:凸性


【作者主页】Francek Chen 【专栏介绍】
深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。 【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
凸性(convexity)在优化算法的设计中起到至关重要的作用,这主要是由于在这种情况下对算法进行分析和测试要容易。换言之,如果算法在凸性条件设定下的效果很差,那通常我们很难在其他条件下看到好的结果。此外,即使深度学习中的优化问题通常是非凸的,它们也经常在局部极小值附近表现出一些凸性。这可能会产生一些比较有意思的新优化变体。
%matplotlib inline
import numpy as np
import torch
from mpl_toolkits import mplot3d
from d2l import torch as d2l一、定义
在进行凸分析之前,我们需要定义凸集(convex sets)和凸函数(convex functions)。
(一)凸集
凸集(convex set)是凸性的基础。简单地说,如果对于任何
,连接
和
的线段也位于
中,则向量空间中的一个集合
是凸(convex)的。在数学术语上,这意味着对于所有
,我们得到
这听起来有点抽象,那我们来看一下图1里的例子。第一组存在不包含在集合内部的线段,所以该集合是非凸的,而另外两组则没有这样的问题。
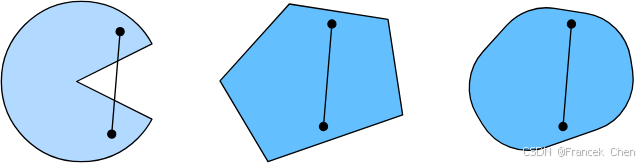
图1 第一组是非凸的,第二、第三组是凸的
接下来来看一下图2所示的交集。假设
和
是凸集,那么
也是凸集的。现在考虑任意
,因为
和
是凸集,所以连接
和
的线段包含在
和
中。鉴于此,它们也需要包含在
中,从而证明我们的定理。
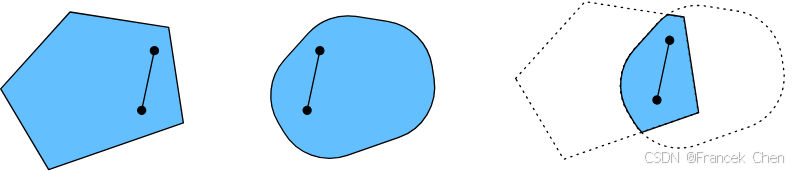
图2 两个凸集的交集是凸的
我们可以毫不费力地进一步得到这样的结果:给定凸集
,它们的交集
是凸的,但是反向是不正确的。
考虑两个不相交的集合
,取
和
。因为我们假设
,在图3中连接
和
的线段需要包含一部分既不在
也不在
中。因此线段也不在
中,因此证明了凸集的并集不一定是凸的,即非凸(nonconvex)的。
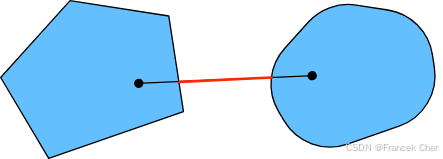
图3 两个凸集的并集不一定是凸的
通常,深度学习中的问题是在凸集上定义的。例如,
,即实数的
-维向量的集合是凸集(毕竟
中任意两点之间的线存在
)中。在某些情况下,我们使用有界长度的变量,例如球的半径定义为
。
(二)凸函数
现在我们有了凸集,我们可以引入凸函数(convex function)
。给定一个凸集
,如果对于所有
和所有
,函数
是凸的,我们可以得到
为了说明这一点,让我们绘制一些函数并检查哪些函数满足要求。下面我们定义一些函数,包括凸函数和非凸函数。
f = lambda x: 0.5 * x**2 # 凸函数
g = lambda x: torch.cos(np.pi * x) # 非凸函数
h = lambda x: torch.exp(0.5 * x) # 凸函数
x, segment = torch.arange(-2, 2, 0.01), torch.tensor([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3))
for ax, func in zip(axes, [f, g, h]):
d2l.plot([x, segment], [func(x), func(segment)], axes=ax)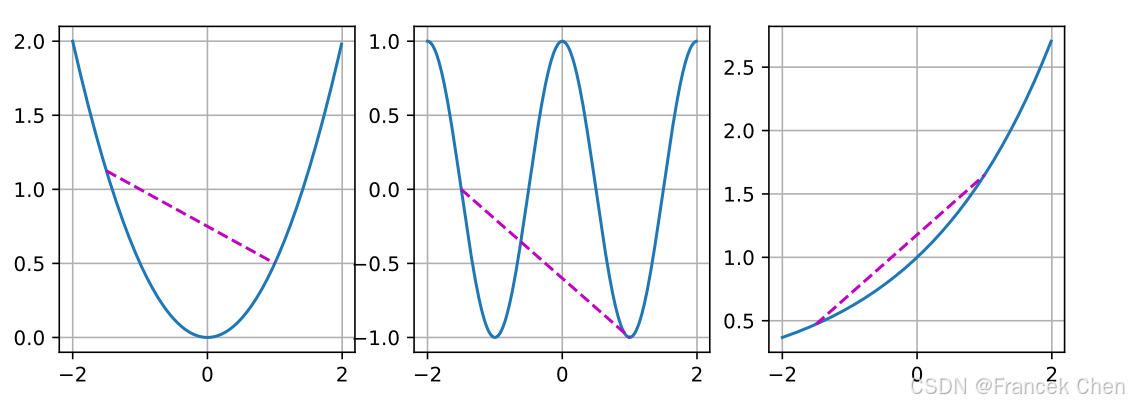
不出所料,余弦函数为非凸的,而抛物线函数和指数函数为凸的。请注意,为使该条件有意义,
是凸集的要求是必要的。否则可能无法很好地界定
的结果。
(三)詹森不等式
给定一个凸函数
,最有用的数学工具之一就是詹森不等式(Jensen’s inequality)。它是凸性定义的一种推广:
其中,
是满足
的非负实数,
是随机变量。换句话说,凸函数的期望不小于期望的凸函数,其中后者通常是一个更简单的表达式。为了证明第一个不等式,我们多次将凸性的定义应用于一次求和中的一项。
詹森不等式的一个常见应用:用一个较简单的表达式约束一个较复杂的表达式。例如,它可以应用于部分观察到的随机变量的对数似然。具体地说,由于
,所以
其中,
是典型的未观察到的随机变量,
是它可能如何分布的最佳猜测,
是将
积分后的分布。例如,在聚类中
可能是簇标签,而在应用簇标签时,
是生成模型。
二、性质
下面我们来看一下凸函数一些有趣的性质。
(一)局部极小值是全局极小值
首先凸函数的局部极小值也是全局极小值。下面我们用反证法给出证明。
假设
是一个局部最小值,则存在一个很小的正值
,使得当
满足
时,有
。
现在假设局部极小值
不是
的全局极小值:存在
使得
。则存在
,比如
,使得
。
然而,根据凸性的性质,有
这与
是局部最小值相矛盾。因此,不存在
满足
。
综上所述,局部最小值
也是全局最小值。
例如,对于凸函数
,有一个局部最小值
,它也是全局最小值。
f = lambda x: (x - 1) ** 2
d2l.set_figsize()
d2l.plot([x, segment], [f(x), f(segment)], 'x', 'f(x)')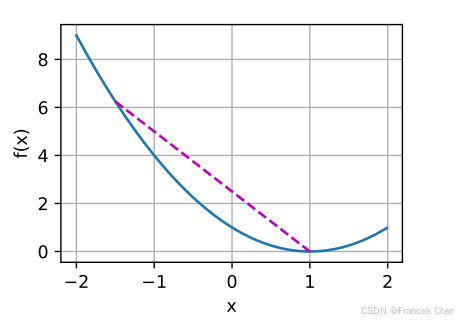
凸函数的局部极小值同时也是全局极小值这一性质是很方便的。这意味着如果我们最小化函数,我们就不会“卡住”。但是请注意,这并不意味着不能有多个全局最小值,或者可能不存在一个全局最小值。例如,函数
在
区间上都是最小值。相反,函数
在
上没有取得最小值。对于
,它趋近于
,但是没有
的
。
(二)凸函数的下水平集是凸的
我们可以方便地通过凸函数的下水平集(below sets)定义凸集。具体来说,给定一个定义在凸集
上的凸函数
,其任意一个下水平集
是凸的。
让我们快速证明一下。对于任何
,我们需要证明:当
时,
。因为
且
,所以
(三)凸性和二阶导数
当一个函数的二阶导数
存在时,我们很容易检查这个函数的凸性。我们需要做的就是检查
,即对于所有
,
。例如,函数
是凸的,因为
,即其导数是单位矩阵。
更正式地讲,
为凸函数,当且仅当任意二次可微一维函数
是凸的。对于任意二次可微多维函数
,它是凸的当且仅当它的黑塞矩阵
。
首先,我们来证明一下一维情况。为了证明凸函数的
,我们使用:
因为二阶导数是由有限差分的极限给出的,所以遵循
为了证明
可以推导
是凸的,我们使用这样一个事实:
意味着
是一个单调的非递减函数。假设
是
中的三个点,其中,
且
.根据中值定理,存在
,
,使得
由于单调性
,因此
由于
,所以
从而证明了凸性。
其次,我们需要一个引理证明多维情况:
是凸的当且仅当对于所有
,
是凸的。
为了证明
的凸性意味着
是凸的,我们可以证明,对于所有的
(这样有
),
为了证明这一点,我们可以证明对
中所有的
,
最后,利用上面的引理和一维情况的结果,我们可以证明多维情况:多维函数
是凸函数,当且仅当
是凸的,这里
,
。根据一维情况,此条成立的条件为,当且仅当对于所有
,
(
)。这相当于根据半正定矩阵的定义,
。
三、约束
凸优化的一个很好的特性是能够让我们有效地处理约束(constraints)。即它使我们能够解决以下形式的约束优化(constrained optimization)问题:
这里
是目标函数,
是约束函数。例如第一个约束
,则参数
被限制为单位球。如果第二个约束
,那么这对应于半空间上所有的
。同时满足这两个约束等于选择一个球的切片作为约束集。
(一)拉格朗日函数
通常,求解一个有约束的优化问题是困难的,解决这个问题的一种方法来自物理中相当简单的直觉。想象一个球在一个盒子里,球会滚到最低的地方,重力将与盒子两侧对球施加的力平衡。简而言之,目标函数(即重力)的梯度将被约束函数的梯度所抵消(由于墙壁的“推回”作用,需要保持在盒子内)。请注意,任何不起作用的约束(即球不接触壁)都将无法对球施加任何力。
这里我们简略拉格朗日函数
的推导,上述推理可以通过以下鞍点优化问题来表示:
这里的变量
(
)是所谓的拉格朗日乘数(Lagrange multipliers),它确保约束被正确地执行。选择它们的大小足以确保所有
的
。例如,对于
中任意
,我们最终会选择
。此外,这是一个鞍点(saddlepoint)优化问题。在这个问题中,我们想要使
相对于
最大化(maximize),同时使它相对于
最小化(minimize)。有大量的文献解释如何得出函数
。我们这里只需要知道
的鞍点是原始约束优化问题的最优解就足够了。
(二)惩罚
一种至少近似地满足约束优化问题的方法是采用拉格朗日函数
。除了满足
之外,我们只需将
添加到目标函数
。这样可以确保不会严重违反约束。
事实上,我们一直在使用这个技巧。比如权重衰减,在目标函数中加入
,以确保
不会增长太大。使用约束优化的观点,我们可以看到,对于若干半径
,这将确保
。通过调整
的值,我们可以改变
的大小。
通常,添加惩罚是确保近似满足约束的一种好方法。在实践中,这被证明比精确的满意度更可靠。此外,对于非凸问题,许多使精确方法在凸情况下的性质(例如,可求最优解)不再成立。
(三)投影
满足约束条件的另一种策略是投影(projections)。同样,我们之前也遇到过,例如在循环神经网络的从零开始实现中处理梯度截断时,我们通过
确保梯度的长度以
为界限。
这就是
在半径为
的球上的投影(projection)。更泛化地说,在凸集
上的投影被定义为
它是
中离
最近的点。
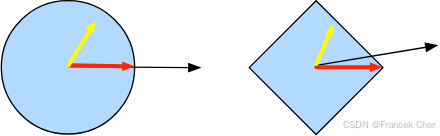
图4 凸投影
投影的数学定义听起来可能有点抽象,为了解释得更清楚一些,请看图4。图中有两个凸集,一个圆和一个菱形。两个集合内的点(黄色)在投影期间保持不变。两个集合(黑色)之外的点投影到集合中接近原始点(黑色)的点(红色)。虽然对
的球面来说,方向保持不变,但一般情况下不需要这样。
凸投影的一个用途是计算稀疏权重向量。在本例中,我们将权重向量投影到一个
的球上,这是图4中菱形例子的一个广义版本。
小结
在深度学习的背景下,凸函数的主要目的是帮助我们详细了解优化算法。我们由此得出梯度下降法和随机梯度下降法是如何相应推导出来的。
- 凸集的交点是凸的,并集不是。
- 根据詹森不等式,“一个多变量凸函数的总期望值”大于或等于“用每个变量的期望值计算这个函数的总值“。
- 一个二次可微函数是凸函数,当且仅当其Hessian(二阶导数矩阵)是半正定的。
- 凸约束可以通过拉格朗日函数来添加。在实践中,只需在目标函数中加上一个惩罚就可以了。
- 投影映射到凸集中最接近原始点的点。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号