【优选算法篇】前缀之序,后缀之章:于数列深处邂逅算法的光与影


C++ 前缀和详解:基础题解与思维分析
前言
前缀和是一种经典的算法技巧,用于高效地计算数组的某一区间内的元素和。它通过预处理一个前缀和数组,将区间求和的问题转化为常数时间的查询操作。本篇博客将详细讲解前缀和的原理,并结合题目解析,让大家掌握这一高效的算法方法。
第一章:前缀和基础应用
1.1 一维前缀和模板题
题目链接:【模板】一维前缀和
题目描述:
给定一个长度为 n 的整数数组 arr 和 q 个查询,每个查询由两个整数 l 和 r 组成,表示区间 [l, r]。请计算出每个区间内所有元素的和。
示例 1:
- 输入:
arr = [1, 2, 3, 4, 5],q = 2, 查询区间为[(1, 3), (2, 4)] - 输出:
[6, 9] - 解释:区间
[1, 3]的元素和为1 + 2 + 3 = 6,区间[2, 4]的元素和为2 + 3 + 4 = 9。
提示:
1 <= n, q <= 100000-10000 <= arr[i] <= 10000
解法(前缀和)
算法思路:
a. 预处理前缀和数组:
使用 dp[i] 表示从数组起始位置到第 i 个元素的累加和。
递推公式为:
dp[i] = dp[i - 1] + arr[i];通过一次遍历即可构建前缀和数组,时间复杂度为 O(n)。
b. 利用前缀和快速计算区间和:
使用前缀和数组,可以在 O(1) 的时间内计算出任意区间 [l, r] 的和:
sum(l, r) = dp[r] - dp[l - 1];这个公式的核心在于利用 dp[r] 存储了 [1, r] 区间的和,而 dp[l - 1] 则存储了 [1, l-1] 区间的和,二者相减即得 [l, r] 区间内的和。
图解分析
假设 arr = [1, 2, 3, 4, 5],查询区间为 [(1, 3), (2, 4)]:
- 前缀和数组构建:
dp[1] = arr[1] = 1dp[2] = dp[1] + arr[2] = 1 + 2 = 3dp[3] = dp[2] + arr[3] = 3 + 3 = 6dp[4] = dp[3] + arr[4] = 6 + 4 = 10dp[5] = dp[4] + arr[5] = 10 + 5 = 15
- 查询区间和计算:
- 对于区间
[1, 3]:sum(1, 3) = dp[3] - dp[0] = 6 - 对于区间
[2, 4]:sum(2, 4) = dp[4] - dp[1] = 9
- 对于区间
前缀和数组:
Index | arr[i] | dp[i] |
|---|---|---|
1 | 1 | 1 |
2 | 2 | 3 |
3 | 3 | 6 |
4 | 4 | 10 |
5 | 5 | 15 |
C++代码实现
#include <iostream>
#include <vector>
using namespace std;
const int N = 100010;
vector<long long> arr(N), dp(N); // 使用 vector 存储数组和前缀和
int n, q; // n 为数组大小,q 为查询次数
int main()
{
cin >> n >> q;
// 读取数组元素
for(int i = 1; i <= n; i++)
cin >> arr[i];
// 构建前缀和数组,dp[i] 表示从 arr[1] 到 arr[i] 的累加和
for(int i = 1; i <= n; i++)
dp[i] = dp[i - 1] + arr[i];
// 处理每个查询
while(q--)
{
int l, r;
cin >> l >> r;
// 输出区间和 [l, r]
cout << dp[r] - dp[l - 1] << endl;
}
return 0;
}易错点提示
- 前缀和数组的下标范围:
dp[i]表示从arr[1]到arr[i]的累加和,因此在构建前缀和数组时需要从i = 1开始,而非0。读取arr时也应从1开始。
- 边界条件处理:
- 当
l = 1时,dp[l - 1]为0。确保dp[0]初始化为0,以避免边界查询时产生错误。
- 当
- 数组长度与内存大小:
arr和dp的长度都最少需要定义为n+1以确保不会越界。尤其在大规模数据时,需要合理定义N以避免内存溢出。
代码解读
在这段代码中,我们首先通过输入构建了原数组 arr 和相应的前缀和数组 dp。然后通过预处理后的 dp 数组,能够快速计算出任意查询区间 [l, r] 的和。
整个过程只需要 O(n) 的时间构建前缀和数组,再通过 O(1) 的时间解决每个区间和查询,使得在多次查询场景下效率非常高。
题目解析总结
前缀和是一种非常常用的算法技巧,特别是在处理区间求和问题时,能够显著优化计算效率。通过一次遍历构建前缀和数组,我们可以在后续查询中轻松地利用前缀和的特性,实现对任意区间的快速求和。 这道题作为前缀和的模板题,帮助我们掌握了前缀和的核心思想与基本操作。通过它,我们能为后续更复杂的区间问题打下坚实的基础。
1.2 二维前缀和模板题
题目链接:【模板】二维前缀和
题目描述:
给定一个大小为 n × m 的矩阵 matrix 和 q 个查询,每个查询由四个整数 x1, y1, x2, y2 组成,表示一个子矩阵的左上角 (x1, y1) 和右下角 (x2, y2)。请计算出每个子矩阵内所有元素的和。
示例 1:
- 输入:
matrix = [[1, 2], [3, 4]],q = 1, 查询区间为[(1, 1, 2, 2)] - 输出:
[10] - 解释:子矩阵包含所有元素
1 + 2 + 3 + 4 = 10。
提示:
1 <= n, m <= 1000-10000 <= matrix[i][j] <= 10000
解法(二维前缀和)
算法思路:
类似于一维前缀和,我们可以预处理一个前缀和矩阵 sum,使得 sum[i][j] 表示从矩阵起点 (1, 1) 到位置 (i, j) 的所有元素的累加和。利用这个前缀和矩阵,可以在 O(1) 时间内求出任意子矩阵的和。
步骤分为两部分:
构建前缀和矩阵:
构建时,我们在矩阵的顶部和左侧添加一行和一列的 0,以简化边界处理。
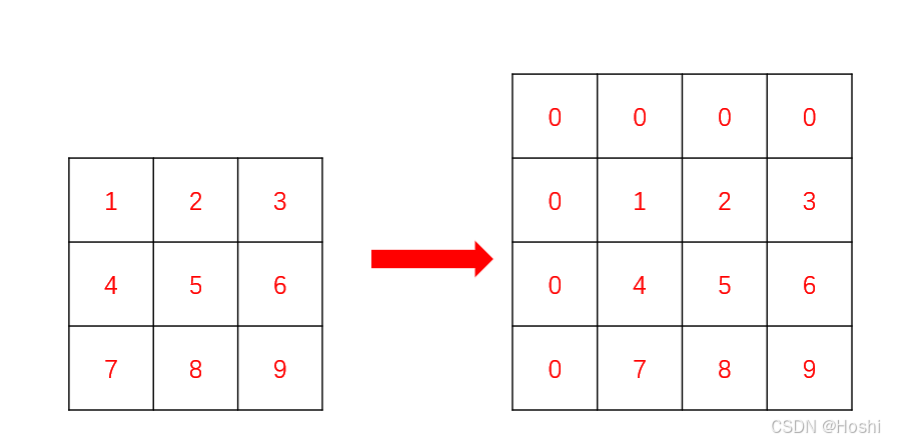
前缀和矩阵的递推公式为:
sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + matrix[i - 1][j - 1];利用前缀和矩阵计算子矩阵和:
对于左上角 (x1, y1) 和右下角 (x2, y2) 的查询,我们可以通过以下公式计算该子矩阵的和:
result = sum[x2][y2] - sum[x1 - 1][y2] - sum[x2][y1 - 1] + sum[x1 - 1][y1 - 1];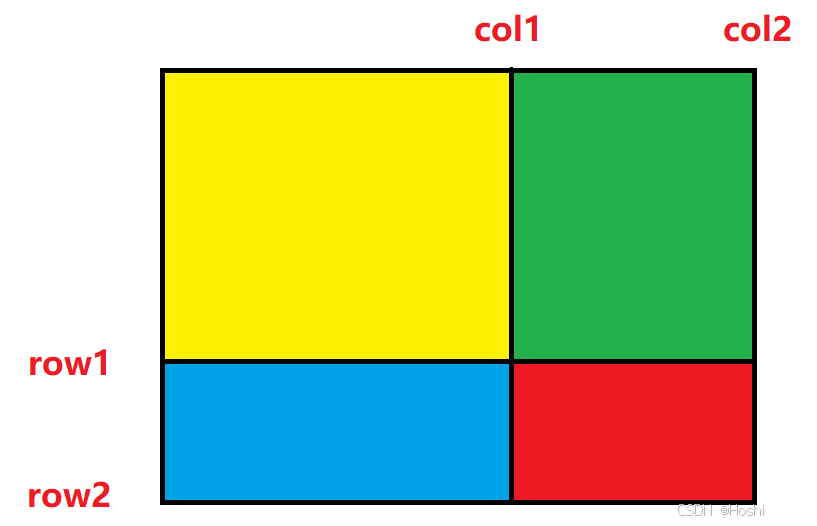
类比小学就学过的求面积
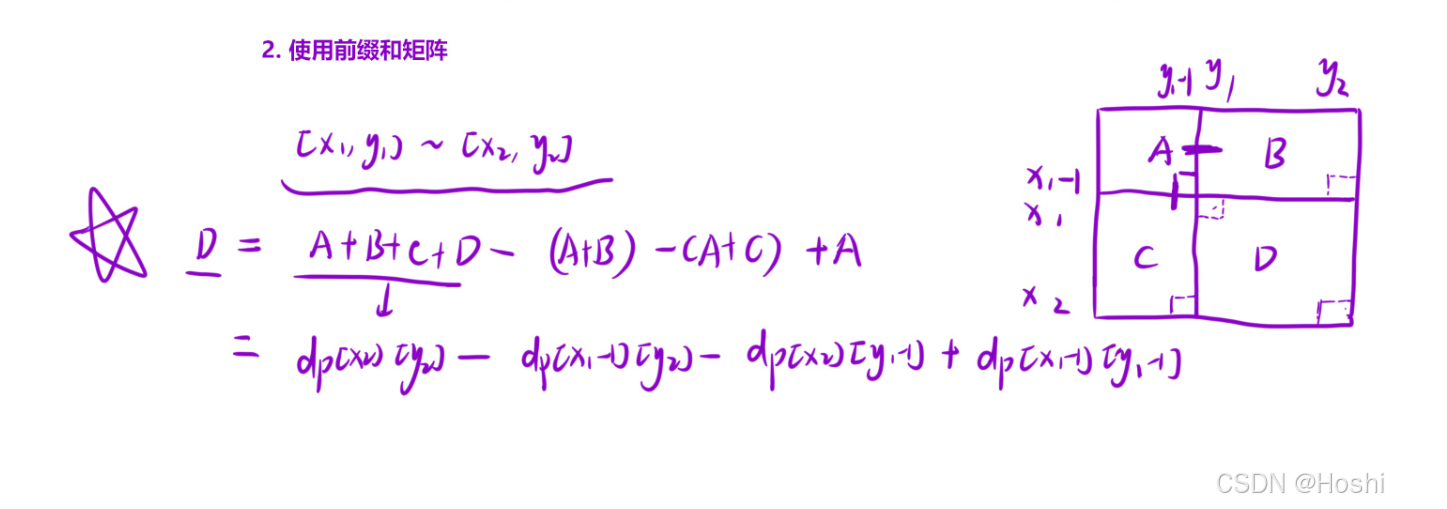
图解分析
假设 matrix = [[1, 2], [3, 4]],q = 1,查询区间为 [(1, 1, 2, 2)]:
构建前缀和矩阵:
原始矩阵:
1 2
3 4构建前缀和矩阵:
sum =
0 0 0
0 1 3
0 4 10查询子矩阵和:
对于 x1 = 1, y1 = 1, x2 = 2, y2 = 2:
result = sum[2][2] - sum[0][2] - sum[2][0] + sum[0][0] = 10 - 0 - 0 + 0 = 10C++代码实现
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int n, m, q;
cin >> n >> m >> q;
vector<vector<int>> matrix(n + 1, vector<int>(m + 1, 0));
vector<vector<long long>> sum(n + 1, vector<long long>(m + 1, 0));
// 读取矩阵数据
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
cin >> matrix[i][j];
}
}
// 构建前缀和矩阵
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + matrix[i][j];
}
}
// 处理查询
while(q--) {
int x1, y1, x2, y2;
cin >> x1 >> y1 >> x2 >> y2;
long long result = sum[x2][y2] - sum[x1 - 1][y2] - sum[x2][y1 - 1] + sum[x1 - 1][y1 - 1];
cout << result << endl;
}
return 0;
}易错点提示
- 矩阵下标的处理:
- 构建前缀和矩阵时,注意在
matrix的基础上偏移一行和一列,以简化边界处理。查询时也需调整下标。
- 构建前缀和矩阵时,注意在
- 前缀和公式理解:
- 在计算
sum[i][j]时,记得同时减去重复计算的sum[i - 1][j - 1]。
- 在计算
- 处理大规模输入:
- 对于
n, m较大的输入,使用long long类型存储累加和,以避免整数溢出。
- 对于
代码解读
- 时间复杂度:前缀和矩阵的构建时间为
O(n * m),每次查询时间为O(1),适用于大量查询场景。 - 空间复杂度:前缀和矩阵
sum需要O(n * m)的额外空间。
题目解析总结
二维前缀和是处理矩阵区域和问题的利器,通过一次性构建前缀和矩阵,可以高效地解决任意子矩阵的求和问题。相比于逐个元素累加的方法,前缀和能大幅减少计算次数,使得算法在面对多次查询时表现更佳。
1.3 寻找数组的中⼼下标(easy)
题目链接:724. 寻找数组的中⼼下标
题目描述:
给你⼀个整数数组 nums ,请计算数组的 中⼼下标 。
数组 中⼼下标 是数组的⼀个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中⼼下标位于数组最左端,那么左侧数之和视为 0,因为在下标的左侧不存在元素。这⼀点对中⼼下标位于数组最右端同样适⽤。
如果数组有多个中⼼下标,应该返回 最靠近左边 的那⼀个。如果数组不存在中⼼下标,返回 -1。
示例 1:
- 输入:
nums = [1, 7, 3, 6, 5, 6] - 输出:
3 - 解释:
- 中⼼下标是
3。 - 左侧数之和
sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11, - 右侧数之和
sum = nums[4] + nums[5] = 5 + 6 = 11,⼆者相等。
- 中⼼下标是
示例 2:
- 输入:
nums = [1, 2, 3] - 输出:
-1 - 解释:
- 数组中不存在满⾜此条件的中⼼下标。
示例 3:
- 输入:
nums = [2, 1, -1] - 输出:
0 - 解释:
- 中⼼下标是
0。 - 左侧数之和
sum = 0,(下标0左侧不存在元素), - 右侧数之和
sum = nums[1] + nums[2] = 1 + -1 = 0。
- 中⼼下标是
提示:
1 <= nums.length <= 10^4-1000 <= nums[i] <= 1000
解法(前缀和)
算法思路:
根据中⼼下标的定义,除了中⼼下标的元素外,该元素左边的「前缀和」等于该元素右边的「后缀和」。
因此,我们可以先预处理两个数组,一个表示前缀和,另一个表示后缀和。然后,通过遍历来找到满足条件的中⼼下标。
构建前缀和数组 lsum:
lsum[i] 表示 nums 从开始到位置 i - 1 的所有元素的和,即 [0, i - 1] 区间的累加和。
构建前缀和数组 lsum 的递推公式为:
lsum[i] = lsum[i - 1] + nums[i - 1];构建后缀和数组 rsum:
rsum[i] 表示 nums 从位置 i + 1 到最后一个元素的所有元素的和,即 [i + 1, n - 1] 区间的累加和。
构建后缀和数组 rsum 的递推公式为:
rsum[i] = rsum[i + 1] + nums[i + 1];枚举中⼼下标:
- 遍历数组,比较每个位置的前缀和
lsum[i]和后缀和rsum[i]是否相等。如果相等,说明该位置就是中⼼下标,直接返回。 - 若遍历完成仍无满足条件的下标,则返回
-1。
图解分析
假设 nums = [1, 7, 3, 6, 5, 6]:
- 前缀和数组构建:
lsum[0] = 0(表示nums的左侧没有元素)lsum[1] = lsum[0] + nums[0] = 0 + 1 = 1lsum[2] = lsum[1] + nums[1] = 1 + 7 = 8lsum[3] = lsum[2] + nums[2] = 8 + 3 = 11lsum[4] = lsum[3] + nums[3] = 11 + 6 = 17lsum[5] = lsum[4] + nums[4] = 17 + 5 = 22
- 后缀和数组构建:
rsum[5] = 0(表示nums的右侧没有元素)rsum[4] = rsum[5] + nums[5] = 0 + 6 = 6rsum[3] = rsum[4] + nums[4] = 6 + 5 = 11rsum[2] = rsum[3] + nums[3] = 11 + 6 = 17rsum[1] = rsum[2] + nums[2] = 17 + 3 = 20rsum[0] = rsum[1] + nums[1] = 20 + 7 = 27
- 查找中⼼下标:
- 遍历过程中,发现
lsum[3] == rsum[3],即下标3满足条件,因此输出3。
- 遍历过程中,发现
前缀和、后缀和数组:
Index | nums[i] | lsum[i] | rsum[i] |
|---|---|---|---|
0 | 1 | 0 | 27 |
1 | 7 | 1 | 20 |
2 | 3 | 8 | 17 |
3 | 6 | 11 | 11 |
4 | 5 | 17 | 6 |
5 | 6 | 22 | 0 |
C++代码实现
class Solution {
public:
int pivotIndex(vector<int>& nums) {
// lsum[i] 表示 [0, i - 1] 区间的累加和
// rsum[i] 表示 [i + 1, n - 1] 区间的累加和
int n = nums.size();
vector<int> lsum(n), rsum(n);
// 预处理前缀和数组
for(int i = 1; i < n; i++)
lsum[i] = lsum[i - 1] + nums[i - 1];
// 预处理后缀和数组
for(int i = n - 2; i >= 0; i--)
rsum[i] = rsum[i + 1] + nums[i + 1];
// 查找中⼼下标
for(int i = 0; i < n; i++) {
if(lsum[i] == rsum[i])
return i;
}
return -1;
}
};更简单的解法
该问题还可以通过更为简洁的解法实现,仅需一个变量记录累加的前缀和,节省空间。
优化思路:
遍历数组时,如果一个位置 i 满足 2 * 前缀和 + nums[i] == 总和,则它就是中心下标。其原理在于:
- 对于中心下标
i,数组的左侧和tmp与右侧和(总和 - tmp - nums[i])相等。 - 即满足条件
2 * tmp + nums[i] == 总和。
优化后的 C++代码实现
class Solution {
public:
int pivotIndex(vector<int>& nums) {
int totalSum = 0, tmp = 0;
// 计算总和
for(int num : nums) {
totalSum += num;
}
// 遍历数组,判断中心下标条件
for(int i = 0; i < nums.size(); i++) {
if(2 * tmp + nums[i] == totalSum) {
return i; // 找到中心下标
}
tmp += nums[i]; // 更新前缀和
}
return -1; // 没有找到中心下标
}
};易错点提示
- 前缀和和后缀和的下标范围:
lsum[i]表示[0, i - 1]区间累加和,而rsum[i]表示[i + 1, n - 1]区间累加和。因此,遍历中我们直接使用lsum[i] == rsum[i]即可判断条件。
- 边界处理:
- 若中心下标在数组最左端或最右端,需要确保对应的
lsum或rsum是0,这样才能保证正确的判断。
- 若中心下标在数组最左端或最右端,需要确保对应的
- 多种中心下标:
- 如果存在多个中心下标,返回最左边的那个,因此遍历时找到第一个满足条件的下标即返回。
代码解读
我们先通过遍历构建了 lsum 和 rsum 数组,然后再次遍历数组,找到第一个满足 lsum[i] == rsum[i] 的位置。
- 时间复杂度:
O(n),遍历数组的次数为常数次,适合于长度较大的数组。 - 空间复杂度:
O(n),额外的前缀和和后缀和数组lsum和rsum。
对于优化后的解法:
- 时间复杂度:
O(n),仅需一次遍历。 - 空间复杂度:
O(1),只使用一个临时变量记录前缀和,显著节省了空间。
28. 除⾃⾝以外数组的乘积(medium)
题目链接:238. 除⾃⾝以外数组的乘积
题目描述:
给你⼀个整数数组 nums,返回数组 answer,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积。
题⽬数据保证数组 nums 中任意元素的全部前缀元素和后缀的乘积都在 32 位整数范围内。
请不要使⽤除法,且在 O(n) 时间复杂度内完成此题。
示例 1:
- 输入:
nums = [1, 2, 3, 4] - 输出:
[24, 12, 8, 6]
示例 2:
- 输入:
nums = [-1, 1, 0, -3, 3] - 输出:
[0, 0, 9, 0, 0]
提示:
2 <= nums.length <= 10^5-30 <= nums[i] <= 30- 保证数组
nums中任意元素的全部前缀元素和后缀的乘积都在 32 位整数范围内。
进阶:你可以在 O(1) 的额外空间复杂度内完成这个题⽬吗?(出于对空间复杂度分析的⽬的,输出数组不被视为额外空间。)
解法(前缀积数组)
算法思路:
由于题目要求不能使用除法,同时要求
O(n)的时间复杂度,因此我们不能用求出整个数组的乘积然后除以单个元素的方式求解。
可以利用前缀和思想,使用两个数组来记录每个元素的前缀积和后缀积,然后将两者相乘得到每个元素除自身以外的乘积。
定义前缀积数组 lprod:
lprod[i] 表示 nums 从开始到 i - 1 的所有元素的乘积,即 [0, i - 1] 区间内所有元素的乘积。
构建前缀积数组 lprod 的递推公式为:
lprod[i] = lprod[i - 1] * nums[i - 1];定义后缀积数组 rprod:
rprod[i] 表示 nums 从 i + 1 到数组末尾的所有元素的乘积,即 [i + 1, n - 1] 区间内所有元素的乘积。
构建后缀积数组 rprod 的递推公式为:
rprod[i] = rprod[i + 1] * nums[i + 1];计算结果数组:
- 遍历
nums,计算每个位置i的结果ret[i]为lprod[i] * rprod[i]。 - 因为
lprod[i]包含的是nums[0]到nums[i - 1]的乘积,而rprod[i]包含的是nums[i + 1]到末尾的乘积,两者相乘即为除nums[i]外的所有元素乘积。
图解分析
假设 nums = [1, 2, 3, 4],期望的结果为 [24, 12, 8, 6]:
- 前缀积数组构建:
lprod[0] = 1(初始条件,表示没有元素的乘积)lprod[1] = lprod[0] * nums[0] = 1 * 1 = 1lprod[2] = lprod[1] * nums[1] = 1 * 2 = 2lprod[3] = lprod[2] * nums[2] = 2 * 3 = 6
- 后缀积数组构建:
rprod[3] = 1(初始条件,表示没有元素的乘积)rprod[2] = rprod[3] * nums[3] = 1 * 4 = 4rprod[1] = rprod[2] * nums[2] = 4 * 3 = 12rprod[0] = rprod[1] * nums[1] = 12 * 2 = 24
- 计算最终结果:
ret[0] = lprod[0] * rprod[0] = 1 * 24 = 24ret[1] = lprod[1] * rprod[1] = 1 * 12 = 12ret[2] = lprod[2] * rprod[2] = 2 * 4 = 8ret[3] = lprod[3] * rprod[3] = 6 * 1 = 6
前缀积、后缀积数组:
Index | nums[i] | lprod[i] | rprod[i] | ret[i] |
|---|---|---|---|---|
0 | 1 | 1 | 24 | 24 |
1 | 2 | 1 | 12 | 12 |
2 | 3 | 2 | 4 | 8 |
3 | 4 | 6 | 1 | 6 |
C++代码实现
class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
int n = nums.size();
vector<int> lprod(n, 1), rprod(n, 1), ret(n);
// 构建前缀积数组
for(int i = 1; i < n; i++) {
lprod[i] = lprod[i - 1] * nums[i - 1];
}
// 构建后缀积数组
for(int i = n - 2; i >= 0; i--) {
rprod[i] = rprod[i + 1] * nums[i + 1];
}
// 计算结果数组
for(int i = 0; i < n; i++) {
ret[i] = lprod[i] * rprod[i];
}
return ret;
}
};更简单的解法
优化思路:
我们可以进一步优化空间复杂度到 O(1)。通过仅使用一个 ret 数组来存储结果,并利用它保存前缀积,再遍历一次通过累积的后缀积来更新结果:
- 计算前缀积并保存到
ret中。 - 遍历并乘以后缀积:在遍历过程中同时更新后缀积的值,使每个位置的结果在不需要额外的
lprod和rprod数组的情况下得到。
优化后的 C++代码实现
class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
int n = nums.size();
vector<int> ret(n, 1);
// 计算前缀积
for(int i = 1; i < n; i++) {
ret[i] = ret[i - 1] * nums[i - 1];
}
// 计算后缀积并更新结果
int suffixProd = 1;
for(int i = n - 1; i >= 0; i--) {
ret[i] *= suffixProd;
suffixProd *= nums[i];
}
return ret;
}
};易错点提示
- 初始条件:
lprod[0]和rprod[n-1]都初始化为1,表示没有元素的乘积。
- 空间优化:
- 优化解法中只使用
ret数组存储前缀积,后续遍历时逐个乘以后缀积。
- 优化解法中只使用
- 避免溢出:
- 题目保证元素乘积在 32 位整数范围内,但实际操作时要避免大数溢出,注意数据类型的使用。
代码解读
在此解法中,我们通过构建前缀积和后缀积的方式实现了在 O(n) 时间复杂度下计算每个位置的乘积。在优化方案中,通过巧妙地在结果数组中存储前缀积并逐步累加后缀积,实现了空间复杂度的优化。
- 时间复杂度:
O(n),无论是初始计算前缀积和后缀积,还是单次遍历,时间复杂度都为O(n)。 - 空间复杂度:原方案为
O(n),优化方案达到O(1)的额外空间复杂度。
写在最后
在这片数列的流动之中,我们从前缀和的入门,渐次深入,直抵算法思想的核心。四道基础题如同桥梁,串联起前缀和与后缀积的巧妙应用,从区间求和的简明优雅到排除自身后的乘积演算,每一步都指向数据处理的无限可能。这是算法的序曲,数字的暗涌,如流水般轻盈而深邃。随着思维渐入佳境,我们将在下篇中进一步探索数列的复杂美,揭开更深层的优化思路,与算法之光同行。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-10-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号