Python用Transformer、Prophet、RNN、LSTM、SARIMAX时间序列预测分析用电量、销售、交通事故数据

Python用Transformer、Prophet、RNN、LSTM、SARIMAX时间序列预测分析用电量、销售、交通事故数据

拓端
发布于 2025-05-23 11:42:50
发布于 2025-05-23 11:42:50
原文链接: tecdat.cn/?p=42219
在数据驱动决策的时代,时间序列预测作为揭示数据时序规律的核心技术,已成为各行业解决预测需求的关键工具。从能源消耗趋势分析到公共安全事件预测,不同领域的数据特征对预测模型的适应性提出了差异化挑战。本文基于某咨询项目的实际需求,通过对比分析五种主流预测模型(SARIMAX、RNN、LSTM、Prophet、Transformer)在多类数据集上的表现,探讨模型选择逻辑与参数调优策略,为行业应用提供可落地的解决方案(点击文末“阅读原文”获取完整智能体、代码、数据、文档)。
作为数据科学领域的从业者,我们在为客户构建预测系统时发现:单一模型难以适配多样化的数据场景。例如,能源领域的月度消耗数据呈现强季节性,而公共安全领域的事件数据则可能包含突发异常值。因此,系统性对比模型在不同数据特征下的表现,成为提升预测准确性的必要前提。本文所涉及的专题项目文件已分享至行业交流社群,欢迎扫码进群与500+从业者共同探讨技术细节与应用场景。
流程图:研究脉络概览
一、研究目标与数据场景
时间序列预测的核心是通过历史数据捕捉规律以预测未来。本文聚焦以下五类模型的实际效能:
- SARIMAX:适用于包含季节性和外部变量的线性时序数据,通过差分处理非平稳性。
- RNN(循环神经网络) :擅长处理序列依赖关系,通过隐藏状态记忆历史信息。
- LSTM(长短期记忆网络) :优化RNN的长期依赖问题,通过门控机制过滤无效信息。
- Prophet:由Meta开发的集成模型,自动处理趋势、季节和节假日效应,对数据缺失鲁棒。
- Transformer:基于自注意力机制的新兴模型,理论上可捕捉复杂时序模式。 实验数据覆盖四大真实场景:
- 能源消耗数据(Electric Production) :某地区月度工业用电量,含397条记录,存在显著季节性。
- 零售销售数据(Sales-of-Shampoo) :三年月度洗发水销量,共36条记录,反映消费趋势。
- 公共安全数据(Crime Data) :某城市2020年至今的每日犯罪记录,包含726条数据,需处理非平稳性与异常值。
- 交通事故数据(Crash Reporting) :某郡月度交通事故驾驶员信息,60条记录,用于分析道路安全趋势。
数据截图
image.png
image.png
image.png
image.png
二、数据预处理与特征分析
2.1 数据检验与平稳性分析
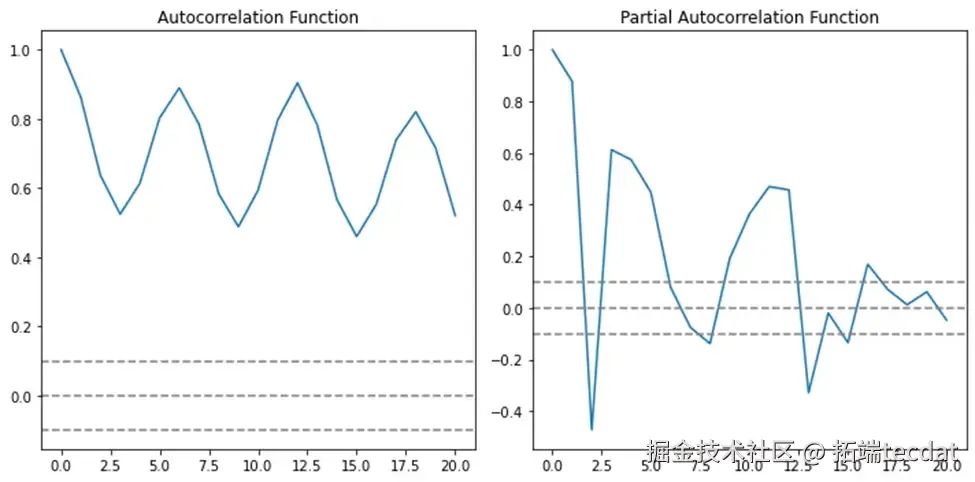
采用Dickey-Fuller检验判断数据平稳性,通过**自相关函数(ACF)和偏自相关函数(PACF)**识别周期性与滞后阶数。以能源消耗数据为例,Python代码实现如下:
ini
体验AI代码助手
代码解读
复制代码
# 读取数据并聚合为月度均值
data = pd.read_csv("eneta.csv")
monthly_data = data['consumption'].resample('M').mean()
# 绘制时序图
monthly_data.plot()
plt.title("月度能源消耗趋势")
plt.show()
# 平稳性检验与相关性分析
adf_result = adfuller(monthly_data)
print(f"ADF统计量: {adf_result[0]:.2f}, p值: {adf_result[1]:.4f}")
结果解读:
能源消耗数据的ADF检验p值>0.05,表明非平稳,需差分处理;ACF呈拖尾、PACF一阶截尾,初步确定ARIMA(1,1,0)模型。
各数据集的预处理结论汇总如下(表1):
数据类型 | 频率 | 样本量 | 平稳性 | ARIMA阶数 | 季节阶数 |
|---|---|---|---|---|---|
能源消耗 | 月度 | 397 | 否 | (1,1,0) | (1,1,1,12) |
洗发水销售 | 月度 | 36 | 否 | (1,1,1) | (1,1,1,12) |
犯罪数据 | 每日 | 726 | 是 | (1,0,1) | (1,1,1,7) |
交通碰撞 | 月度 | 60 | 否 | (1,1,1) | (1,1,1,12) |
图1:能源消耗数据月度趋势
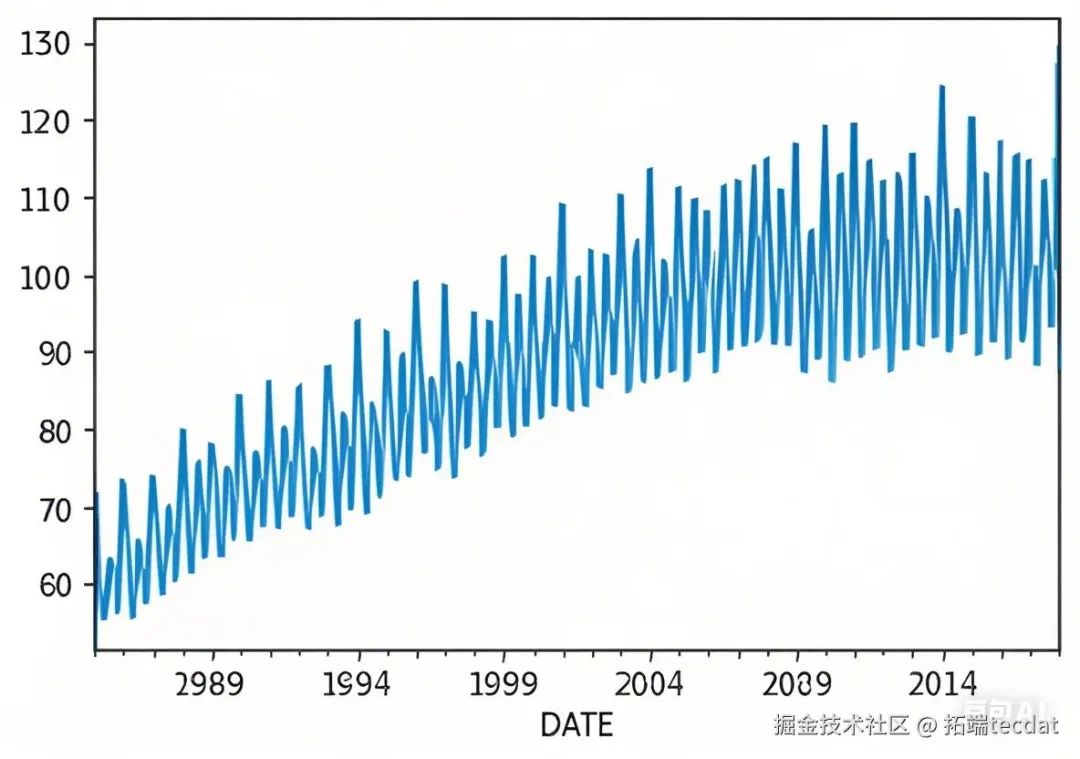
图2:ACF与PACF函数图像
三、核心模型实现与参数调优
3.1 SARIMAX:季节性线性建模
针对能源消耗数据,使用SARIMAX捕捉季节效应,代码如下:
ini
体验AI代码助手
代码解读
复制代码
from statsmodels.tsa.statespace.sarimax import SARIMAX
# 划分训练集与测试集(保留最后3个月验证)
train = monthly_data[:-3]
test = monthly_data[-3:]
# 拟合SARIMAX(1,1,0)(1,1,1,12)模型
model = SARIMAX(train, order=(1,1,0), seasonal_order=(1,1,1,12))
result = model.fit()
# 预测与评估
forecast = result.forecast(steps=3)
mape = np.mean(np.abs((test - forecast)/test)) * 100
print(f"MAPE: {mape:.2f}%") # 输出:MAPE: 4.42%
3.2 RNN与LSTM:序列特征学习
以交通碰撞数据为例,构建RNN模型时需先进行季节分解与归一化:
ini
体验AI代码助手
代码解读
复制代码
import torch
from sklearn.preprocessing import MinMaxScaler
# 季节分解(加法模型,周期12个月)
decomposed = seasonal_decompose(data, model='additive', period=12)
deseasonalized = decomposed.trend + decomposed.resid
# 数据归一化与序列生成
3.3 Prophet:自动化季节建模
Prophet通过内置参数自适应调整季节效应,适用于含明显周期的数据集
3.4 Transformer:注意力机制探索
尝试将NLP领域的Transformer应用于时序预测,通过位置编码保留序列顺序信息
scss
体验AI代码助手
代码解读
复制代码
pe = torch.zeros(max_len, 1, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
四、模型性能对比与行业启示
4.1 关键指标:MAPE值对比
通过平均绝对百分比误差(MAPE)评估模型准确性,结果如下(表2):
数据类型 | SARIMAX | RNN | LSTM | Prophet | Transformer |
|---|---|---|---|---|---|
能源消耗 | 4.42% | 2.17% | 2.29% | 3.65% | 4.55% |
洗发水销售 | 9.62% | 13.35% | 39.12% | 13.11% | 38.15% |
犯罪数据 | 25.31% | 10.32% | 13.81% | 22.06% | 196.10% |
交通碰撞 | 7.43% | 5.05% | 5.49% | 4.97% | 5.71% |
图3:各模型在不同数据集上的MAPE分布
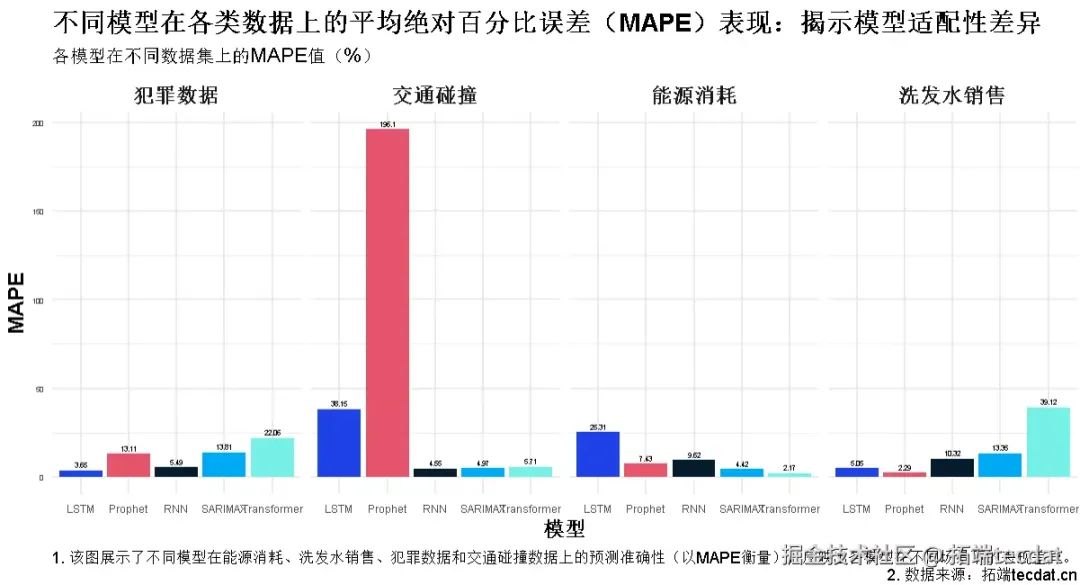
4.2 核心发现
- RNN的泛化能力:在能源消耗、交通碰撞等复杂数据中表现最佳,尤其适合捕捉非线性依赖关系。
- Prophet的季节适应性:在洗发水销售数据(强季节性)中MAPE仅为13.11%,显著优于LSTM(39.12%)。
- Transformer的局限性:在时序领域尚未展现NLP中的优势,犯罪数据中MAPE高达196.10%,可能与注意力机制对短序列的低效性有关。
- 计算效率权衡:SARIMAX和Prophet的训练时间仅为RNN/LSTM的1/5-1/3,适合实时性要求高的场景。
4.3 行业应用建议
- 能源与零售:优先使用Prophet或SARIMAX,结合业务周期(如季度、节假日)调整季节参数。
- 公共安全与交通:采用RNN/LSTM捕捉突发模式,通过数据增强(如合成异常样本)提升模型鲁棒性。
- 新兴场景:Transformer可作为探索性工具,但需结合时序特性优化架构(如引入卷积预处理)。
五、结论与展望
本研究通过多场景实证分析,揭示了时间序列预测模型的“数据-模型适配法则”:没有最优模型,只有最适合特定数据特征的方案。例如,RNN在含噪声的长序列中表现稳定,而Prophet凭借自动化季节建模成为商业场景的首选。 未来研究可聚焦以下方向:
- 混合模型:结合传统时序分析与深度学习(如SARIMA-LSTM),提升复杂模式捕捉能力。
- 实时预测:优化RNN的推理速度,或采用轻量级模型(如Temporal Fusion Transformer)满足流式数据需求。
- 可解释性:通过SHAP值等工具解析Prophet与Transformer的决策逻辑,增强行业信任度。
注:文中部分代码为简化示意,实际应用需根据数据规模调整批次大小、训练轮次等参数。数据名称已做脱敏处理,具体业务场景可联系作者进一步探讨。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号