石头剪刀布:Apache Hudi中的可插拔表格式

石头剪刀布:Apache Hudi中的可插拔表格式

ApacheHudi
发布于 2025-05-22 11:21:53
发布于 2025-05-22 11:21:53
作者:Balaji Varadarajan,Apache Hudi PMC成员,开源贡献者和湖仓(Lakehouse)爱好者
我是Apache Hudi的PMC成员,并且在过去15年中一直为开源软件做贡献。我不销售或推广任何特定的数据系统供应商。我只是一名普通工程师,喜欢构建开源数据湖仓技术,并在工作场所使用它们来帮助提高效率并保持数据系统的开放性和灵活性。
在这篇博客中,我想分享:
- 1. 提出Hudi中可插拔表格式层的原因,这是一个重大变更,允许Hudi的存储引擎也能够写入其他表格式规范,如Apache Iceberg、Delta Lake或Lance。
- 2. 这项工作如何有潜力超越Apache XTable (Incubating)[1]或Delta Lake Uniform[2]提供的**"读取兼容性",朝着Hudi写入器、表服务和外部表格式写入器(例如,Snowflake写入Iceberg表)之间的完全写入兼容性**方向发展。
- 3. Hudi如何能够发展以支持多种存储/表格式——其高性能原生格式,以及其他流行的外部表格式——就像大多数数据库一样。
- 4. 我还想作为一个开源爱好者坦率地解释这项工作的技术和生态系统原因。我还将讨论供应商的一些行为如何使开源创新变得困难。
为什么我提出RFC-93
如今,开放表格式或数据湖仓空间正在快速增长。围绕Apache Hudi、Apache Iceberg、Delta Lake以及更新的努力(如Uniform或Apache XTable)有很多活动。作为从早期阶段就开始从事这项技术的人,看到行业范围内的采用非常令人兴奋。
我开始研究RFC-93[3](Hudi中可插拔的Iceberg和Delta支持)的最初原因来自我工作过的公司中的实际问题。我们需要使Hudi表的元数据访问速度比S3允许的更快。所以我开始思考——如果我们可以使Hudi表元数据(如文件列表、统计信息等)更具可组合性并将其存储在云管理的服务中会怎样?我受到Snowflake如何将其所有元数据保存在FoundationDB中以获得快速访问[4]的启发——甚至对于托管的Iceberg表[5]也是如此。在进一步探索这个设计后,我意识到这种模块化设计也可以启用一个可插拔的TableFormat接口,使Hudi平台能够支持其他表格式的元数据。
开源与供应商
有一段时间,我听到关于"为什么不使用Iceberg?"的问题,其驱动因素是"像Snowflake和Databricks这样的大供应商正在推动它"。首先,我认为Databricks是在开发Delta Lake,而不是Iceberg...这些表格式的托管产品有明显不同的性能特征。
这次对话让我意识到了一个重要的事情。今天的数据生态系统变得非常嘈杂。声音太多了。如果两个工程师真正了解湖仓内部原理,现在有200个其他人在撰写博客和社交媒体文章,其中许多人在技术事实上出错。这种混乱使工程团队更难做出清晰、明智的决定,或者基于技术考虑的表面价值进行理性对话。最近,由于供应商在生态系统中的"棋步[6]",这种情况在Apache Hudi周围表现得尤为明显。这也给Hudi用户推卸了一个毫无根据的"举证责任",要通过某种流行度测试。不幸的是,复杂的系统软件不是这样运作的。
一项最近的调查[7]结果给了我强烈的动力,确保我们庞大的OSS Hudi社区——在过去7年中愉快地建立起来——不受任何供应商战争的影响。这个社区应该继续成长并为湖仓世界构建创新。事实上,许多供应商已经从Hudi中受益——通过使用其创意或通过销售托管Hudi解决方案。
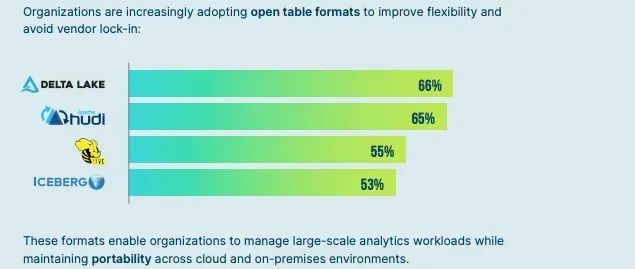
将此转化为帮助OSS用户的机会:OSS社区没有理由发动战争。跨社区工作是像我这样的用户避免(并帮助公司避免)向供应商不必要支付费用的方式。作为Hudi PMC和长期社区成员,我意识到我可能需要做更多工作来使Hudi适应/发展到当前的生态系统,并为OSS用户解锁好处。支持可插拔格式使Hudi能够在更深层次上与生态系统集成,让用户可以选择最佳的组件。这种可组合性符合现代数据系统的发展方式——远离整体架构,朝着模块化、可互操作的构建块方向发展。
让我们在下一节中从技术角度更详细地解析这一点。
它如何改变Hudi堆栈
从本质上讲,Apache Hudi诞生[8]是为了解决一个关键需求——使数据湖更易管理、性能更高且增量式。多年来,Hudi已经发展成为一个全面的湖仓平台,涵盖现代数据基础设施堆栈的多个层次:
- • 摄取层:通过Hudi DeltaStreamer(Spark/Flink)的流式或批处理数据摄取
- • 转换层:对写入/读取的SQL支持,用于处理高速数据的流式API。
- • 管理层:表优化服务,如压缩、聚类,簿记服务如清理,和归档。目录同步服务,将数据暴露给更广泛的生态系统。
- • 存储层:不同的基础/日志文件格式,部分更新,合并读取(MOR),写时复制(COW)存储模式。
- • 表格式层:关于表中文件的元数据,不同的快照和提交日志。
下面的堆栈所指的存储和管理层的组合就是"存储引擎"(与数据库系统处理此功能的方式一致),并提供了用户已经习惯喜爱Hudi的大部分功能。
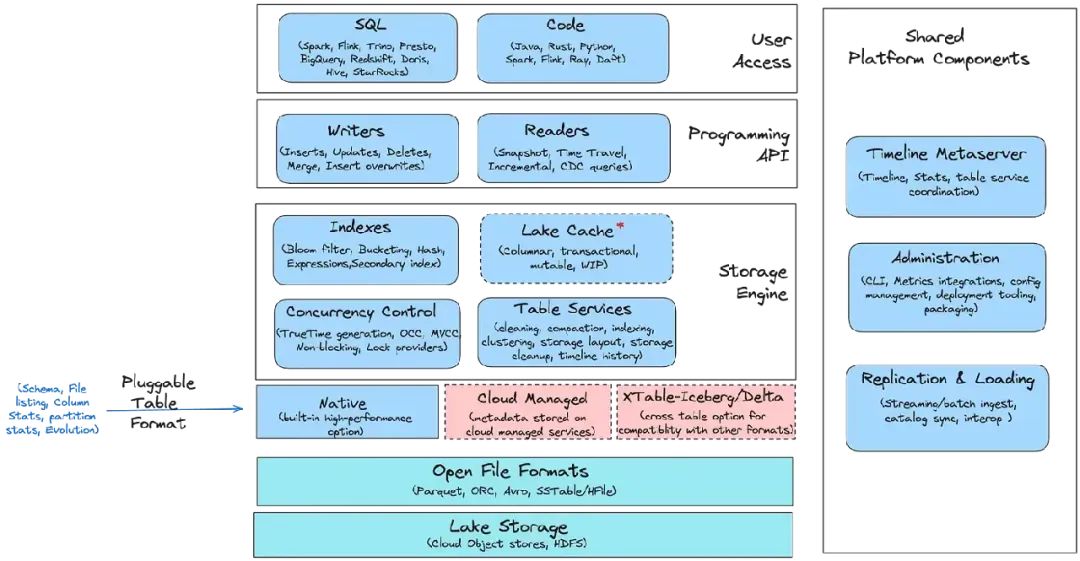
历史上,Hudi的原生表格式,结合其写入路径和元数据服务,一直是其性能和功能的核心。但随着湖仓生态系统的成熟,我们可以开放这一层,以其他方式提供具有不同权衡的相同元数据。事实上,即使在Hudi内部,我最近也在研究支持当前代码库中0.x和1.x表格式的抽象。所以,从技术上讲,这似乎是一个相对简单的事情,Hudi可以继续支持**"外部"表格式(Iceberg、Delta、自定义...),同时支持不同版本的"本地"表格式**。
各格式之间一直存在并将继续存在长期的、明显的并发控制和性能差异。然而,这些可以留给用户自行决定,而在表格式层上提供更多选择,而不改变SQL查询或数据管道,可以为OSS数据湖仓用户带来极大的好处。
工作原理:TableFormat接口
我已经提出了一个PR[9](我希望它会进入即将发布的Hudi 1.1版本),向Hudi引入新的可插拔表格式接口。这个RFC的核心是TableFormat接口,它抽象了通常只在Hudi的本机格式上执行的元数据和时间线操作(即当前使用的格式)。这个接口有关键的回调和接口,用于将插件与Apache Hudi写入器集成。
- • getName() — 表格式插件的名称。这个标识插件,使写入器可以动态加载类,就像Apache Spark数据源名称用于动态实例化源实现一样。
- • commit(..) — 这个回调将允许外部表格式完成写操作,包括产生数据文件的表服务,如压缩或聚类。
- • archive(..), clean(..), rollback(..), restore(..) — 对于那些不熟悉Hudi的人,该项目提供了在调度表服务方面的极大灵活性(内联,异步),基于常见策略,如基于时间或版本清理旧文件,或压缩最多写入的文件组等。Hudi写入器或项目内的单独工具可以执行它们,同时与其他写入器重试和协调。这些回调允许外部表格式对Apache Hudi的表服务操作做出反应,同时充分利用Hudi的"表服务"运行时。
- • getTimelineFactory() — 时间线是一个事件日志,充当表更改的事实来源。此方法返回外部表格式的时间线实现,可以在Hudi的写入器和服务中执行相同的必需的时间线读取/写入。
- • getMetadataFactory() — 此方法返回由外部表格式支持的元数据实现,同时允许使用Apache Hudi的读取器利用外部表格式维护的元数据。
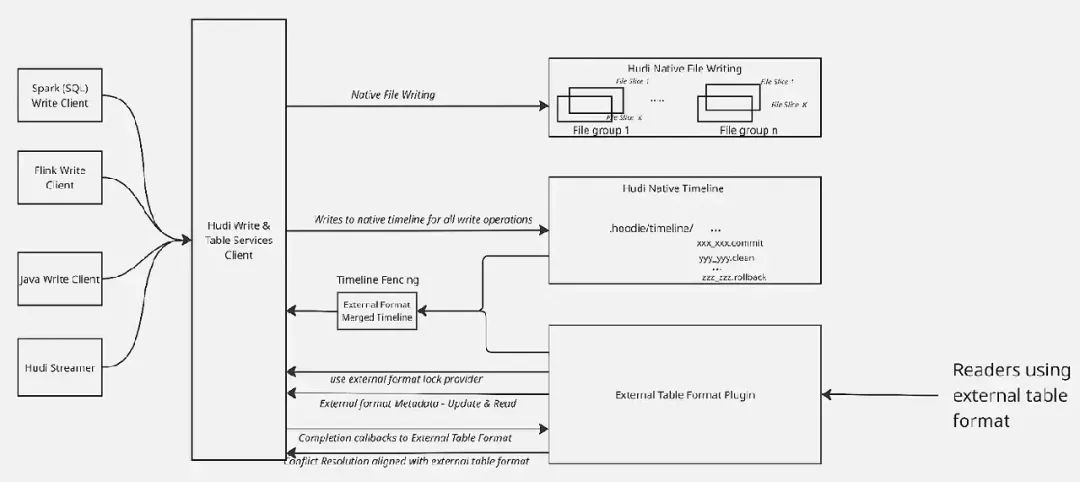
这些API的主要目的是提供Apache Hudi更高层软件堆栈(Hudi写入器、表服务、实用程序、工具)与外部表格式之间的关注点分离,其中:
- • Apache Hudi 像往常一样写入数据文件,使用其优化的布局(因此自动文件大小调整等功能继续使用户受益)
- • 外部插件(例如Apache Iceberg插件)被调用来写入版本化元数据(例如清单文件),在提交期间。
- • 插件的时间线实现的方式使得真相来源是外部表格式(因此与任何写入外部表格式的写入器兼容)
- • 插件的元数据被馈送到Hudi写入器的不同部分,增强了Hudi服务(如Timeline服务器,它优化了元数据的服务)的好处
- • Hudi写入器和表服务继续在*.hoodie*文件夹中的内部时间线中记录事件,以促进在外部表格式上的表服务(清理、压缩、回滚)的调度/执行。
这确保了快照隔离和一致的提交语义,无论表格式如何。
设计草图:在Hudi下插入Iceberg
为了理解这在实际中如何工作,让我们勾勒一下有人如何在这些抽象下为Iceberg实现可插拔表格式。
首先,你在表创建期间使用以下方式配置表格式插件(例如):
hudi.table.format.plugin=iceberg
并在应用程序的类路径中提供包含TableFormat实现的jar。
从概念上讲,实现将执行以下操作:
- • getName():这将是字符串"iceberg"。
- • commit(..):通常的提交元数据(HoodieCommitMetadata)被传递给提交回调中的插件。这包含在每个存储路径创建/更新的文件列表。有了这个,iceberg实现将能够生成其快照创建所需的清单文件。首先将提交写入内部Hudi时间线,然后生成Iceberg快照,必要时与"并发安全"的目录进行通信。数据仅在两个元数据部分都写入,特别是外部表格式(即Iceberg快照)时才提交。
- • archive, clean, rollback, restore:类似地,对于每个表服务操作,记录相应操作的相关元数据被传递给插件。对于iceberg支持的操作,插件实现将有上下文来生成新的清单文件和快照。
- • getTimelineFactory:Iceberg的tableFormat插件可以实现一个复合时间线,该时间线只有在提交到Iceberg时才认为操作"完成"。它将使用其最新清单来跟踪已提交的事务(hudi的提交实例),并为Hudi的操作提供真相来源时间线。例如,我们可以重用所有现有的Hudi清理计划/调度,并将其应用于iceberg快照。
- • getMetadataFactory:Iceberg tableFormat插件将使用此API来查询文件列表、分区和列统计,用于使用Apache Hudi的读取器/写入器/表服务。
该功能可在RFC-93[10]中获得,第一个外部插件实现可能在Apache XTable (Incubating)[11]项目下开发。
在其初始范围内:我们只支持Spark的写时复制表。其他引擎(如Flink)或表格式(如Delta Lake)或表类型(如合并读取)可以根据社区的兴趣得到支持。在当前实现中,表必须只由Hudi写入器和服务更改。可以扩展以支持外部写入器,只需根据外部写入计算内部时间线的更新。
好处
开放表格式层为湖仓用户带来了几个优势。
- 1. 高性能元数据需求:Hudi的时间线和元数据服务对于启用ACID事务、多写入器并发和回滚至关重要。通过使这些可插拔,你现在可以用低延迟存储(如DynamoDB)支持它们,为大规模表实现显著的速度提升。这是我正在积极追求的用例。
- 2. 减少与供应商的摩擦:面对现实吧。我们对供应商路线图没有太多控制。但是,他们似乎都已经接受了Iceberg,例如,至少是读取支持。这对开源数据生态系统来说是一件好事,看到完全封闭的仓库现在正在读取开放格式。表格式的可插拔性现在可以帮助供应商在这一演变中采取下一步措施,超越诸如"市场正在选择格式x、y或z"之类的模糊声明,向我们技术上证明为什么他们不能支持某些东西,或者他们的建议如何是最佳技术选择。
- 3. 扩展Hudi的写入超能力:Hudi写入速度快——非常快,它的设计更好地平衡[12]了写入速度和查询效率。通过使其能够与外部格式一起使用,用户可以受益于Hudi的聚集文件布局、索引和写入优化的代码路径,同时仍将其表作为Iceberg/Delta暴露给下游工具。
- 4. 系统设计中的标准实践:从MySQL(InnoDB、MyISAM、MyRocks)到Presto(连接器),存储层的可扩展性是系统设计中经过验证的模式。鉴于当前生态系统的成熟度,所有主要OSS和商业引擎都支持开放表格式,现在是Hudi扩大其范围的好时机。
- 5. 自动化表服务而无需向供应商付费:Hudi自带内置表服务,可自动处理压缩、聚类和清理,确保最佳性能,无需外部编排。例如,Apache Iceberg生态系统现在可以最终获得开箱即用的文件大小调整和表管理,而无需购买封闭的表维护解决方案或自己完成所有工作。你可以民主化跨格式的元数据管理,即使你不使用Hudi格式。
- 6. 统一湖仓摄取:Hudi流式处理工具为许多大规模数据湖仓提供动力,内置支持约半打关键CDC、流和文件数据源。想象一下使用Hudi的DeltaStreamer运行你的摄取管道,并发出可以作为其他表格式读取的表——无需额外处理。
可能还有更多。但是,希望这已经给你一个很好的坚实列表。使用Hudi摄取一次,然后使用其他格式兼容的引擎进行查询。使用DynamoDB或你选择的目录管理元数据。使用可插拔格式,界限变得模糊——这对OSS用户来说是件好事。
结论
通过可插拔表格式,Hudi变得更加像一个平台;正如我们多年来一直重申的那样,它从来不仅仅是一种格式。遗憾的是,围绕湖仓的对话被营销战和供应商叙事所主导。但那些在开源中的我们知道,真正推动进展的是可组合系统、可靠抽象和以用户为先的设计。常规OSS贡献者是Hudi的关键部分,我们一起构建,因为我们相信技术价值、开放性和社区。我们很少对供应商战争感兴趣。
湖仓不是产品或标志——它是一种设计模式,一套原则,以及对如何大规模管理数据的愿景。让我们保持湖仓开放、灵活和社区驱动。🚀 我们正在积极寻找合作者和反馈。加入Slack[13]上的对话,尝试一下,或提交问题以帮助塑造项目的下一阶段。
引用链接
[1] Apache XTable (Incubating):https://xtable.apache.org/
[2]Delta Lake Uniform:https://docs.delta.io/latest/delta-uniform.html
[3]RFC-93:https://github.com/apache/hudi/pull/12998
[4]FoundationDB中以获得快速访问:https://www.snowflake.com/en/blog/how-foundationdb-powers-snowflake-metadata-forward/
[5]甚至对于托管的Iceberg表:https://www.youtube.com/watch?v=lfN4zGGAvv8&t=729s
[6]棋步:https://siliconangle.com/2024/06/22/decoding-chess-moves-snowflake-databricks/
[7]调查:https://hello.dremio.com/rs/321-ODX-117/images/State-of-Data-Unification-Survey.pdf
[8]诞生:https://www.uber.com/blog/hoodie/
[9]PR:https://github.com/apache/hudi/pull/13216
[10]RFC-93:https://github.com/apache/hudi/blob/master/rfc/rfc-93/rfc-93.md
[11]Apache XTable (Incubating):https://github.com/apache/incubator-xtable
[12]平衡:https://substack.com/home/post/p-159031300
[13]Slack:https://join.slack.com/t/apache-hudi/shared_invite/zt-33fabmxb7-Q7QSUtNOHYCwUdYM8LbauA
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号