技术译文 | 没有好的数据,人工智能就毫无用处


作者:Scott Stroz,MySQL Developer Advocate
原文:https://blogs.oracle.com/mysql/post/without-good-data-ai-is-useless,May 12, 2025
截图:Oracle MySQL Blog、YouTube
爱可生开源社区翻译,本文约 2800 字,预计阅读需要 10 分钟。

上周,我们发布了 MySQL Shorts 第 89 集[1],重点介绍了 HeatWave[2] 中的一些机器学习[3] 功能 。在本文中,我将讨论在为本集视频训练 AI 模型时,关于好数据和坏数据的一些体会。

Episode-089 - Performing Predictive Analysis with HeatWave AutoML
YouTube:Episode-089 - Performing Predictive Analysis with HeatWave AutoML
I. 准备
在训练第 89 集的模型时,我使用了一个由 高尔夫联赛管理数据 生成的数据集。该数据集包含高尔夫球手的信息、他们的成绩以及他们所打的球场。一些数据集还包含天气状况信息。这些数据甚至可以追溯到 2013 年。
高尔夫联赛数据集
训练数据:高尔夫联赛数据集
这些数据被用来训练一个模型,该模型可以根据高尔夫球手之前的成绩和他们当时所处的球场来预测他们的成绩。我对数据集进行了多次迭代,使模型训练到能够产生良好结果的程度。由于高尔夫运动的不可预测性 —— 同一位高尔夫球手在同一天、同一个球场、相同的天气条件下打出的成绩可能会大相径庭(我认为将实际成绩控制在 5 杆以内就是一个很好的结果)。数据科学家可能不同意…… 但我不是数据科学家。我是一名开发人员,正在尝试学习如何使用人工智能解决问题。
在本文中,我将展示使用五个不同数据集训练的五个不同模型的结果。这些数据集由相同的源数据生成,但为了获得最佳结果,我们添加或删除了一些数据。
II. 数据
每次迭代使用的数据被分成 3 个不同的表。这 3 个表分别是:
- golf_train:此表包含用于训练模型的数据。每次迭代的列略有不同。所有迭代都有一个共同的列,即
score,其中包含高尔夫球手在特定一轮高尔夫比赛中的得分。每次迭代包含 11,465 行数据。 - golf_test:此表包含用于测试模型的数据。该表的列与
golf_train表中的列相同,但数据不同,并且score列的值为 null。每次迭代包含 4,914 行数据。 - golf_scores:该表包含用于评估模型的数据。它包含了
golf_test表中高尔夫球手的实际得分。
III. 步骤
在训练模型、运行预测和评估结果时,我对这五个数据集都使用了相同的步骤。步骤如下:
- 使用
sys.ml_train()存储过程利用golf_train中的数据训练模型。 - 使用
sys.ml_model_load()存储过程加载新创建的模型。 - 使用
sys.ml_predict_table()存储过程对golf_test表中的数据运行预测,该存储过程将数据导出到名为golf_predict的新表中。 - 运行以下查询来评估预测结果:
select
distinct abs(round(gp.prediction,0)-gs.score) diff,
count(*) count
from golf_predict gp
join golf_scores gs on gp.id = gs.id
group by diff
order by diff;
此查询返回预测分数和实际分数之间的唯一差异以及这些差异发生的次数。
IV. 迭代
A. 第一次迭代
起初,我的第一个数据集似乎取得了成功,因为结果非常准确。以下是测试查询的结果:
+------+-------+
| diff | count |
+------+-------+
| 0 | 4910 |
| 1 | 3 |
| 2 | 1 |
+------+-------+
这个模型正确预测了 4,914 个杆数中的 4,910 个。它预测的杆数与实际杆数的误差在 5 杆以内,准确率高达 100% 。我欣喜若狂!我以为我找到了高尔夫预测的圣杯。
但当我把结果分享给小儿子时,我的热情很快就消退了。他指出,该模型似乎找到了一种模式或“公式”来预测分数,并且该模型“过度拟合”了数据。
事实证明他是对的。让我们检查一下 golf_train 表中的列,看看究竟是怎么回事。
+-----------------+---------------+
| Field | Type |
+-----------------+---------------+
| id | int |
| golfer_name | varchar(100) |
| match_date | date |
| scheduled_date | varchar(10) |
| score | int |
| net_score | int |
| handicap | int |
| course_name | varchar(75) |
| hole_group_name | varchar(75) |
| slope | decimal(10,2) |
| rating | decimal(10,2) |
| team_name | varchar(50) |
| week_name | varchar(75) |
| division_name | varchar(50) |
| season_name | varchar(50) |
| league_name | varchar(50) |
+-----------------+---------------+
如果您是一名高尔夫球手,您可能已经弄清楚了这个数据集的问题所在。
golf_train 表的这次迭代包含了 score 、 net_score 和高尔夫球手的 handicap 。将 net_score 和 handicap 相加,就得到了 score 。因此,该模型可以通过将 net_score 和 handicap 相加来预测分数。
这不是一个好的模型。
B. 第二次迭代
在第二次迭代中,我从 golf_train 表中删除了 net_score 和 handicap 列,并使用了这个新的配置来训练模型。以下是我在 golf_train 的这次迭代中使用的列:
+-----------------+---------------+
| Field | Type |
+-----------------+---------------+
| id | int |
| golfer_name | varchar(100) |
| match_date | date |
| scheduled_date | varchar(10) |
| score | int |
| course_name | varchar(75) |
| hole_group_name | varchar(75) |
| slope | decimal(10,2) |
| rating | decimal(10,2) |
| team_name | varchar(50) |
| week_name | varchar(75) |
| division_name | varchar(50) |
| season_name | varchar(50) |
| league_name | varchar(50) |
+-----------------+---------------+
以下是上述测试查询的结果:
+------+-------+
| diff | count |
+------+-------+
| 0 | 446 |
| 1 | 931 |
| 2 | 817 |
| 3 | 769 |
| 4 | 598 |
| 5 | 457 |
| 6 | 324 |
| 7 | 214 |
| 8 | 126 |
| 9 | 92 |
| 10 | 62 |
| 11 | 30 |
| 12 | 21 |
| 13 | 11 |
| 14 | 3 |
| 15 | 2 |
| 16 | 5 |
| 17 | 3 |
| 18 | 1 |
| 19 | 1 |
| 20 | 1 |
+------+-------+
我们可以看到,结果差异更大。该模型正确预测了 4,914 个成绩中的 446 个,并预测了 4,018 个(82%)与实际成绩的误差在 5 杆以内的成绩。这是一个更好的模型。但它是否理想呢?
此时,我决定深入研究该模型。为了更好地理解模型的工作原理,我运行了 sys.ml_explain_table() 存储过程,以更好地理解模型的预测过程。在 ml_explain_table() 生成的表中,我注意到 team_name 列中的数据经常被用来进行预测。这让我警觉起来,因为我所在的高尔夫联赛的球队都是由两名球员组成的。通过使用 team_name ,模型可能会根据一名队友的历史得分来预测另一名队友的得分。
尽管结果更符合我的预期,但这可能不是一个好的模型。
C. 第三次迭代
在第三次迭代中,我从 golf_train 表中删除了 team_name 列,并使用了这个新配置来训练模型。以下是我在 golf_train 本次迭代中使用的列:
+-----------------+---------------+
| Field | Type |
+-----------------+---------------+
| id | int |
| golfer_name | varchar(100) |
| match_date | date |
| scheduled_date | varchar(10) |
| score | int |
| course_name | varchar(75) |
| hole_group_name | varchar(75) |
| slope | decimal(10,2) |
| rating | decimal(10,2) |
| week_name | varchar(75) |
| division_name | varchar(50) |
| season_name | varchar(50) |
| league_name | varchar(50) |
+-----------------+---------------+
以下是上述测试查询的结果:
+------+-------+
| diff | count |
+------+-------+
| 0 | 325 |
| 1 | 612 |
| 2 | 581 |
| 3 | 577 |
| 4 | 550 |
| 5 | 473 |
| 6 | 454 |
| 7 | 370 |
| 8 | 312 |
| 9 | 233 |
| 10 | 152 |
| 11 | 118 |
| 12 | 69 |
| 13 | 41 |
| 14 | 23 |
| 15 | 13 |
| 16 | 6 |
| 17 | 2 |
| 18 | 3 |
+------+-------+
该模型正确预测了 4,914 个分数中的 325 个,并预测了 3,118 个(63%)与实际分数的误差在 5 杆以内的分数。鉴于该模型的准确率低于之前的互动,我不确定这个模型是否更好。
根据我将在下面讨论的其他迭代,该模型不如前一个模型好。
D. 第四次迭代
天气是影响高尔夫球手在球场上表现的因素之一。因此,在第四次迭代中,我在 golf_train 表中添加了一些包含天气数据的列。我添加了 temperature 、 conditions (晴、多云、下雨等)、 wind_speed 和 humidity 。以下是我在 golf_train 的本次迭代中使用的列:
+-----------------+---------------+
| Field | Type |
+-----------------+---------------+
| id | int |
| golfer_name | varchar(100) |
| match_date | date |
| scheduled_date | varchar(10) |
| score | int |
| course_name | varchar(75) |
| hole_group_name | varchar(75) |
| slope | decimal(10,2) |
| rating | decimal(10,2) |
| week_name | varchar(75) |
| division_name | varchar(50) |
| season_name | varchar(50) |
| league_name | varchar(50) |
| temperature | int |
| conditions | varchar(50) |
| wind_speed | int |
| humidity | int |
+-----------------+---------------+
以下是测试查询的结果:
+------+-------+
| diff | count |
+------+-------+
| 0 | 325 |
| 1 | 610 |
| 2 | 589 |
| 3 | 573 |
| 4 | 556 |
| 5 | 464 |
| 6 | 458 |
| 7 | 369 |
| 8 | 313 |
| 9 | 230 |
| 10 | 154 |
| 11 | 116 |
| 12 | 69 |
| 13 | 41 |
| 14 | 23 |
| 15 | 13 |
| 16 | 6 |
| 17 | 2 |
| 18 | 3 |
+------+-------+
让我震惊的是,即使加入了天气条件,模型的准确率不仅没有提升,甚至没有任何变化,准确率依然是 63%。
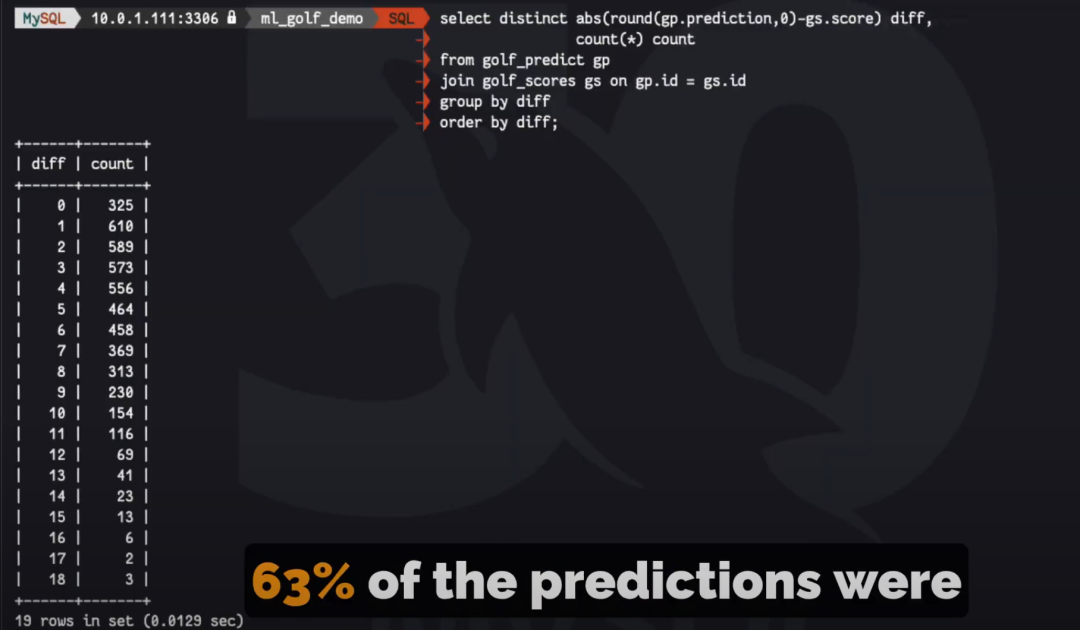
第四次迭代模型的准确率
第四次迭代模型的准确率
在对这篇博文进行分析时,我意识到这个模型仍然不是理想的,即使它是我在第 89 集的演示中使用的模型。
E. 第五次迭代
我开始对找到比第二次迭代更理想的模型失去希望,因为第二次迭代可能一直在使用一位高尔夫球手的数据来预测另一位高尔夫球手的成绩。后来我意识到,我使用的数据中没有任何数据能够表明这位高尔夫球手的能力。一位高尔夫球手可能会随着时间的推移而进步或退步,而模型没有数据可以用来判断这一点。幸运的是,我用来生成数据集的源数据确实有一些我们可以使用的数据 —— 高尔夫球手在打一轮高尔夫球时的差点。
有些人可能不知道,高尔夫球手的差点衡量了他们的能力。差点越低,高尔夫球手的水平就越高。因此,我在 golf_train 表中添加了一列,其中包含高尔夫球手在打高尔夫球时的差点。在本例中,我决定保留天气信息。以下是我在 golf_train 的这次迭代中使用的列:
+-----------------+---------------+
| Field | Type |
+-----------------+---------------+
| id | int |
| golfer_name | varchar(100) |
| match_date | date |
| scheduled_date | varchar(10) |
| score | int |
| handicap | int |
| course_name | varchar(75) |
| hole_group_name | varchar(75) |
| slope | decimal(10,2) |
| rating | decimal(10,2) |
| week_name | varchar(75) |
| division_name | varchar(50) |
| season_name | varchar(50) |
| league_name | varchar(50) |
| temperature | int |
| conditions | varchar(50) |
| wind_speed | int |
| humidity | int |
+-----------------+---------------+
以下是测试查询的结果:
该模型正确预测了 4,914 个分数中的 531 个,并预测了 4,118 个(84%)与实际分数相差 5 杆以内的分数。唯一差异的数量与第四次迭代相同,但本次迭代中出现较大差异的次数较少。
本次迭代的准确率高于第二次迭代,是一个更理想的模型。
V. 总结
这是一次令人愉快的练习。思考哪些数据能帮助模型做出更好的预测,哪些数据无助于预测,这很有挑战性。我也学到了很多关于如何使用 HeatWave 的机器学习功能。
我认为数据科学家可以创建更好的数据集来训练模型。但是,正如我上面提到的,我是一名开发人员,正在尝试学习如何使用人工智能解决问题,而不是数据科学家。
你应该从这篇文章中学到的一点是,使用优质数据训练模型至关重要。正如我在工作中经常听到的那样,“垃圾进,垃圾出”。你需要使用优质数据才能从模型中获得最佳结果。
哦,另外,如果结果看起来好得令人难以置信,我也会质疑。
参考资料
[1]
MySQL Shorts Episode-089: https://www.youtube.com/watch?v=MCunWV6EWoA&list=PLWx5a9Tn2EvG4C90YFJ9eU61IpALeE0SN&index=90
[2]
HeatWave: https://www.oracle.com/heatwave/
[3]
机器学习: https://www.oracle.com/heatwave/features/#automl
本文关键字:#MySQL #人工智能 #机器学习 #大语言模型 #翻译
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号