分布式计算框架--Ray
原创

开源地址:https://github.com/ray-project/ray
Ray是一个高性能的分布式计算框架,在AI和大模型领域得到了广泛应用,OpenAI的训练底层框架就是Ray。Ray提供了统一的分布式计算抽象,可以像在本机上执行python函数或类的实例,而不用关注该函数或实例在哪些机器上执行。
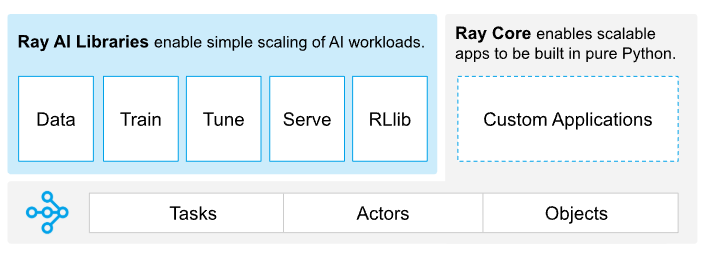
Ray框架图
使用方法
安装Ray:
pip install ray主节点启动:
ray start --head --num-gpus=1
# num-gpus用于指定使用主节点上几张卡启动后看输出日志,记录下来主节点的ip和port,从节点连接的时候需要。
从节点启动:
ray start --address='主节点ip:主节点端口' --num-gpus=1
# num-gpus用于指定使用从节点上几张卡可以随意启动多个从节点
在集群内任意节点都可以查看集群状态,命令`ray status`
分布式任务执行:
在主节点上运行python程序,Ray会自动把任务分到多台机器上执行。下面是我自己写的,一个简单的三机三卡分布式python例子。
# pipeline_actor.py
import ray
from transformers import AutoModelForCausalLM
@ray.remote(num_gpus=1) # 每个Actor分配1块GPU
class PipelineStage:
def __init__(self, model_path: int, max_length: int):
self.device = "cuda:0"
# 加载模型
self.model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype="auto", device_map="auto")
self.max_length = max_length
def forward(self, inputs: dict):
# 将输入数据移动到当前设备
inputs = {
"input_ids": inputs["input_ids"].to(self.device),
"attention_mask": inputs["attention_mask"].to(self.device)
}
# 执行当前阶段计算
generated_ids = self.model.generate(**inputs, max_length=self.max_length)
return generated_ids# test_ray.py
import ray
import torch
from example.ray_dist.pipeline_actor import PipelineStage
from transformers import AutoTokenizer
master_node = "master_ip"
slave_node1 = "slave1_ip"
slave_node2 = "slave2_ip"
prompt = "Explain the theory of relativity in simple terms."
model_path = "./Llama-3.2-3B-Instruct/"
def main():
# 初始化Ray集群
ray.init(
address="auto",
runtime_env={"env_vars": {"RAY_ENABLE_WINDOWS_OR_OSX_CLUSTER": "1"}},
_node_ip_address=master_node
)
# 在3台机器上各启动一个Actor
stage1 = PipelineStage.options(
resources={f"node:{master_node}": 0.01}, # 绑定到master node
num_gpus=1
).remote(model_path=model_path, max_length=20)
stage2 = PipelineStage.options(
resources={f"node:{slave_node1}": 0.01}, # 绑定到slave node
num_gpus=1
).remote(model_path=model_path, max_length=30)
stage3 = PipelineStage.options(
resources={f"node:{slave_node2}": 0.01}, # 绑定到slave node
num_gpus=1
).remote(model_path=model_path, max_length=40)
# 准备输入数据
tokenizer = AutoTokenizer.from_pretrained(model_path)
inputs = tokenizer(prompt, return_tensors="pt")
# 执行pipeline推理
generated_ids_1 = ray.get(stage1.forward.remote(inputs))
inputs = {
"input_ids": generated_ids_1,
"attention_mask": torch.ones_like(generated_ids_1)
}
generated_ids_2 = ray.get(stage2.forward.remote(inputs))
inputs = {
"input_ids": generated_ids_2,
"attention_mask": torch.ones_like(generated_ids_2)
}
generated_ids_3 = ray.get(stage3.forward.remote(inputs))
# 解码输出
print(tokenizer.batch_decode(generated_ids_1, skip_special_tokens=True))
print(tokenizer.batch_decode(generated_ids_2, skip_special_tokens=True))
print(tokenizer.batch_decode(generated_ids_3, skip_special_tokens=True))
ray.shutdown()
if __name__ == "__main__":
main()
核心原理
组件
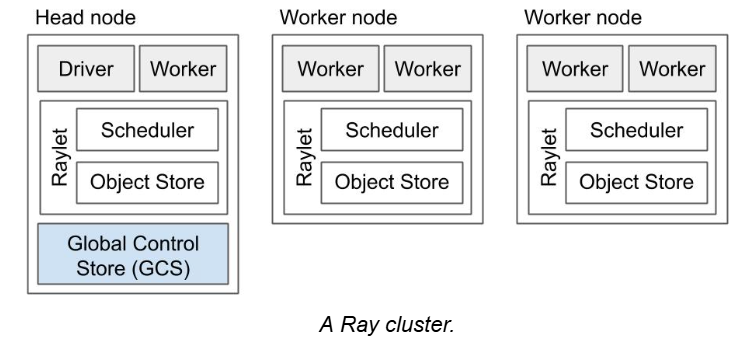
Ray集群由一个或多个worker节点构成,每一个worker节点构成如下:
1、一个或多个worker进程,负责任务提交和执行。每一个worker进程负责处理一个具体的函数或类的实例,初始化的workers数量等于CPU数量。
2、raylet负责管理一个节点上的资源,主要由一个调度器和对象存储构成。调度器负责动态资源管理、任务分配,对象存储负责存储、转换大的对象。
其中一个worker节点会被指定为head节点,head节点除了具备上述worker节点的功能外,还有以下功能:
1、Global Control Services:是一个管理集群级别原数据的服务器,例如:以键值对形式缓存实例的位置、集群成员管理(成员新增、删除、健康检测)、actor管理(创建、销毁、重建)、资源管理、任务的调度和执行。总之,GCS管理的原数据访问频率较低,但会被集群中的大多数worker使用。在Ray 2.0中,GCS也可以运行在head节点外。代码位置:ray/src/ray/gcs at master · ray-project/ray
2、驱动进程:是一个特殊的工作进程,为了执行python main函数。可以提交任务,但不会执行。值得注意的是,驱动进程能够运行在任何节点,但通常默认在主节点。
内存模型
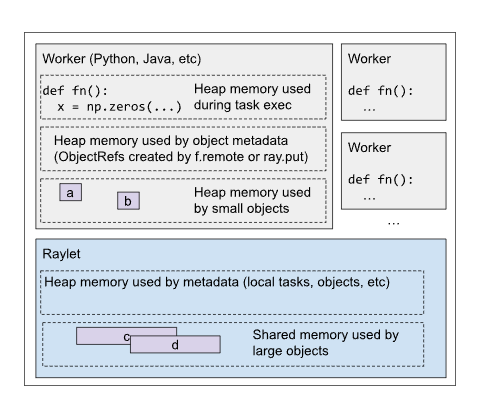
1、Ray worker在task或actor执行期间使用堆内存
2、大型Ray对象使用的共享内存(由‘ Ray .put() ’创建或由Ray任务返回的值),当worker调用‘ Ray.put() ’或从task返回时,它会将提供的值复制到Ray的共享内存对象存储中,然后Ray将使这些对象在整个集群中可用。
3、小Ray对象使用的堆内存(由Ray task返回),如果对象足够小(默认100KB), Ray将直接将值存储在所有者的“内存中”对象存储中,而不是Raylet共享内存对象存储中。任何读取该对象的worker(例如,通过‘ ray.get ’)都会将该值直接复制到自己的堆内存中。
4、Ray元数据使用的堆内存,这是Ray分配的内存,用于管理应用程序的元数据。
语言运行时
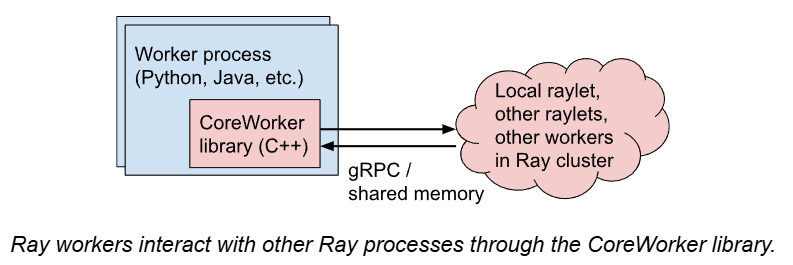
所有Ray核心组件都是用c++实现的,Ray通过一个称为“core worker”的通用c++库支持Python、Java和(实验性的)c++前端。这个库实现了所有权表、进程内存储,并管理gRPC与其他worker和raylet之间的通信。由于该库是用c++实现的,所以所有语言运行时都共享一个Ray worker协议的通用高性能实现。
Ray Compiled Graph
相对于.remote()的立即执行,dag在执行前,先把整个计算图的结构和执行计划定义好。这种模型下,计算图就可以先编译,在编译阶段就可以进行各种分析和优化,从而为后续执行做好充分准备。采用静态执行模型,dag可以提升20%的训练吞吐量。在官方给的例子中,编译后性能提升了10倍。
DAG的关键特性:
Lazy Computation Graphs: 懒计算模式,即可以等所有task/actor定义完之后再执行,方便做图优化
Custom Input Node: 支持数据变但计算图不变,避免重复建图
Multiple Output Node: 计算图不变,但支持多输出
DAG的优点:
1.预分配资源:通过预分配资源,Ray Compiled Graph 可以提前规划和准备所需的计算资源,如 CPU、GPU、内存等。这有助于减少在任务执行过程中动态分配资源带来的系统开销,提高资源利用效率,使系统能够更专注于实际的计算任务,从而提升整体性能。
2.NCCL 通信器准备与调度:在分布式计算中,NCCL(NVIDIA Collective Communications Library)用于 GPU 之间的高效通信。Ray Compiled Graph 可以提前准备 NCCL 通信器,并通过合理的调度方式避免死锁问题。这确保了在多 GPU 或多节点环境下,GPU 之间的通信能够稳定、高效地进行,避免因死锁导致的任务失败或性能瓶颈。
3.自动重叠 GPU 计算与通信:在 GPU 计算过程中,计算和数据传输(通信)通常是两个重要的环节。Ray Compiled Graph 能够自动优化计算和通信的顺序,使 GPU 在进行计算的同时,可以并行地进行数据传输,从而充分利用 GPU 的资源,减少整体的执行时间,提高 GPU 的利用率和计算效率。
4.提升多节点性能:在多节点的分布式计算环境中,Ray Compiled Graph 的静态执行模型可以对跨节点的任务调度和数据传输进行优化。通过预分配资源、合理安排通信等方式,减少节点间的通信延迟和资源竞争,提高多节点环境下的整体性能,使系统能够更有效地处理大规模分布式计算任务。
参考文档:
https://www.zhihu.com/people/jim-li-618/posts
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号