大模型SFT数据筛选的艺术:探索IFD、Supperfiltering、MoDS、CaR、Nuggets与LESS的核心价值

大模型SFT数据筛选的艺术:探索IFD、Supperfiltering、MoDS、CaR、Nuggets与LESS的核心价值

汀丶人工智能
发布于 2025-04-26 19:47:02
发布于 2025-04-26 19:47:02
1.数据处理场景优化
场景1:业务数据精简
随着业务发展,某些子任务的数据量可能过大,影响其他任务的模型泛化。定期检查并精简这些“冗余”数据,确保数据集高效且均衡。
场景2:开源数据筛选
面对新业务需求而无特定SFT训练数据时,需从开源数据中筛选有助于提升该场景表现的数据,以填补数据缺口,增强模型适应性。
场景3:识别关键数据
分析现有训练集,找出对特定业务场景增益最大的数据,优化数据资源配置,提高模型性能和效率。
2.常见方法
本文将探索两种类型的数据精选方法
- 一种是针对庞大训练数据集进行筛选,没有单一的优化场景,更适合面向 To-c 的模型,这里我把这类方法称为 Non-Target Method。
- 另一种是基于已有验证集,也可以理解成基于一个任务提出的具体任务场景,从数据集中挑选对这个具体场景有增益的数据,这类方法更贴近实际业务场景,这里我把这类方法称为 Target Method。
本文将聚焦于这些方法的核心逻辑和理论,而非论文中的测试结果。实际上,很多测试结果并不具备实际业务参考价值,关键在于理解并运用其中的思想。
Non-Target Method 1:IFD

在这里插入图片描述
- 项目地址:https://github.com/tianyi-lab/Cherry_LLM
- 论文链接:https://arxiv.org/pdf/2308.12032
核心思想:
论文的核心理念围绕三个关键指标,其中最核心的是 Instruction-Following Difficulty (IFD) metric。
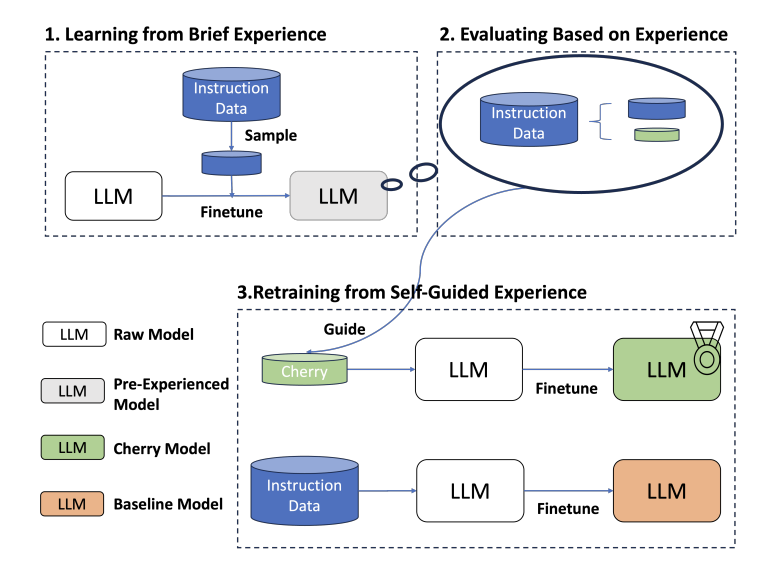
- Conditioned Answer Score (CA): 这一指标衡量模型在给定指令下生成正确答案的能力。它反映了模型遵循这个指令生成正确答案的难度。
- Direct Answer Score (DA): 这一指标衡量的是模型单独生成答案的难易程度。 目标是考察这个答案是不是天生对于模型来说就是难以生成的。
- Instruction-Folowing Difficulty (IFD): CA 与 DA 的比值。 通常,提供提示(prompt)作为上下文会降低模型生成输出的难度。IFD 值超过 1 的数据被视为异常,并在研究中被排除。高但不超过 1 的 IFD 值意味着提示对模型生成答案有所帮助,但帮助并不显著,这类样本被视为 “difficulty” 样本。而低 IFD 值表明提示极大地简化了答案的生成,这类属于 “easy” 样本。为了构建高质量的训练集,研究选择了 IFD 值最高的前 10% 样本。

具体例子:
左上角的正例 1: DA 和 CA 都很高, 显示出该输出对原始模型而言就颇具挑战性,同时,即便在给定提示(prompt)作为上下文时,模型生成输出的难度并未显著降低。这类就是 “difficulty” 样本。
左下角的正例 2: DA 和 CA 都相对低, 意味着该输出对模型而言容易生成,但加入提示后,并未给模型带来显著的生成难度下降。这类也是值得训练的样本。
右上角的负例 1: DA 高而 CA 低。 这种情况通常出现在短文本中,由于平均损失较高导致 DA 值大。然而,给定提示后 CA 显著降低,说明在上下文的帮助下,生成这个简短的输出变得轻而易举。属于 “easy” 样本。
右边中间的负例 2: DA 和 CA 都相对低。 这个例子中,答案引自 LLM 预训练学过的一本书,因此作为已有知识,LLM 很容易复述出这句话。但是,如果加上一个指令,CA 分数就会变得更低,这表明 LLM 在遵循这个指令方面已经获得了相当好的能力。属于 “easy” 样本
右下角的负例 3: 最常见的情况,即教学难度不够。同样属于 “easy” 样本。
优点:
- 整个过程不依赖于外部模型,而是由待训练的模型自身来计算 IFD 分数,确保了一致性和内在性。
- 提出的 IFD 指标既直观又具备理论支撑,能够有效地反映出模型在不同条件下生成答案的难度。
缺点:
- 虽然 IFD 指标在理论上很有吸引力,但在实际操作中,高 IFD 的样本未必真正代表困难样本。实际上,它们可能包括一些答非所问的错误样本,这些样本由于提示(prompt)与答案之间的不相关性,自然导致 IFD 分数偏高。因此,在开源数据上直接应用此方法可能会引入很多错误的数据。
- 使用 IFD 指标进行样本选择时,可能容易偏向于挑选出某一类特定任务的样本,从而忽视了数据的多样性。
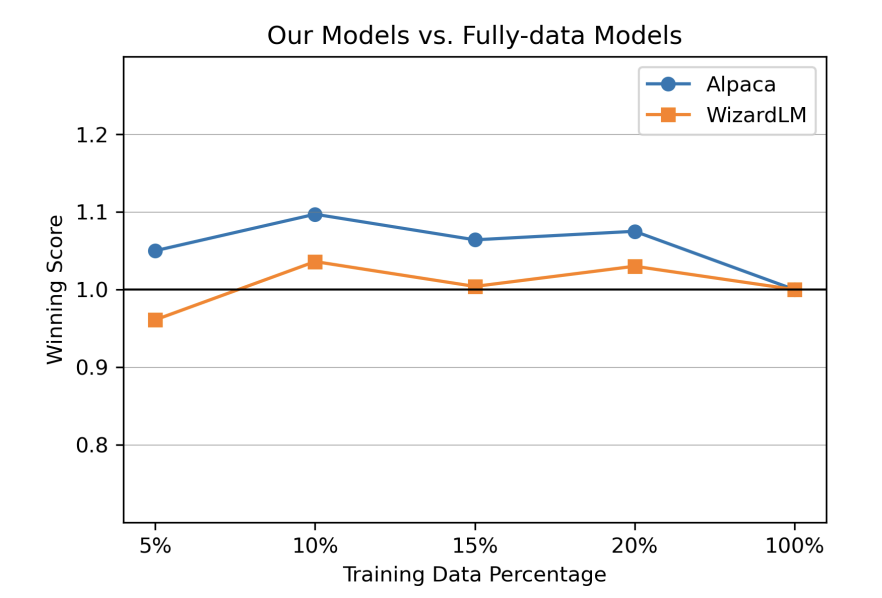
- 实验结果
在 Alpaca和 WizardLM上进行了实验,大约 5%-10% 的数据即可超过原来的模型。如下图:
进一步探究了不同的数据筛选方法对模型的影响,如下图:
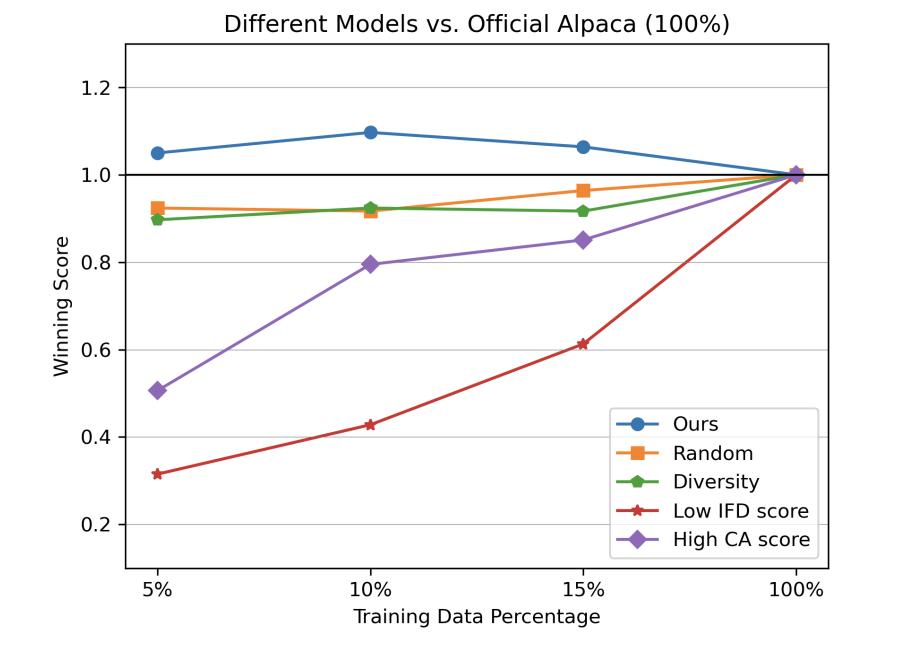
值得注意的是,Low IFD score 有着极低的 performance,这进一步证明了我们方法的有效性,即高 IFD 的 sample 是更有效的,而低 IFD 的 sample 反而是对训练有负面影响的。
- 后续相关工作
- ACL2024《Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning》
论文链接:https://arxiv.org/abs/2402.00530
Github 链接:https://github.com/tianyi-lab/Superfiltering
这篇文章揭示了较强和较弱的模型在感知数据难度上的一致性,提出只要在很小的模型上,如 GPT2(124M),使用 IFD score,就可以很好的选出较好的指令数据。这篇文章是第一个成功使用 GPT2-level 的小模型完成对 GPT4 生成的数据进行筛选的工作。
链接:ACL2024《Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning》论文解读
- ACL2024《Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning》
论文链接:https://arxiv.org/abs/2402.10110
Github 链接:https://github.com/tianyi-lab/Reflection_Tuning
这篇文章提出了老师学生互动模式(teacher-student collaboration pipeline)来提升数据质量,其中使用了 IFD 来评估新生成的 instruction 的难度,同时提出了逆过程的 IFD(reversed-IFD)来评估新生成 response 和 instruction 之间的 alignment。
Non-Target Method 2:Superfiltering

这篇文章是 IFD 工作的进一步发展,由同一批作者撰写,主要解决了 IFD 效率问题。
核心思想:
设想一个场景,若你计划训练一个 72B 的庞大模型,在百万级别的 SFT 数据上使用 IFD 进行数据筛选可能会非常耗时费力。那么,我们是否能用一个规模较小的 13B 模型来代替这一步的数据挑选工作呢?问题的关键在于这两个不同大小的模型在计算 IFD 指标时能否保持顺序一致性。
论文中证明了,尽管大模型和小模型在内在能力上存在显著差异,例如,大型模型在同一数据上通常会有更低的困惑度,但不同大小的模型在感知教学难度方面可能具有相似性。
具体来说,如果某条候选训练数据在大 size 的模型中计算的 IFD 分数位列前 5%,那么用小模型计算的话,这条数据也有很大可能性排在前 5%。简而言之,不同 size 的模型在识别困难数据时,不同数据的相对排名往往相似。这对我们来说已经足够,因为在应用 IFD 方法时,我们更关注数据的相对排名,而不是具体得分。例如,通常选取 IFD 排名前 10% 的数据作为训练集。
优点和缺点
这种方法与标准的 IFD 相比,优点在于提高了时效性,使数据处理更加迅速。然而,它也存在一个缺点,即相较于原始的 IFD 方法,其效果略有降低。
Non-Target Method 3:MoDS

在这里插入图片描述
项目:https://github.com/CASIA-LM/MoDS
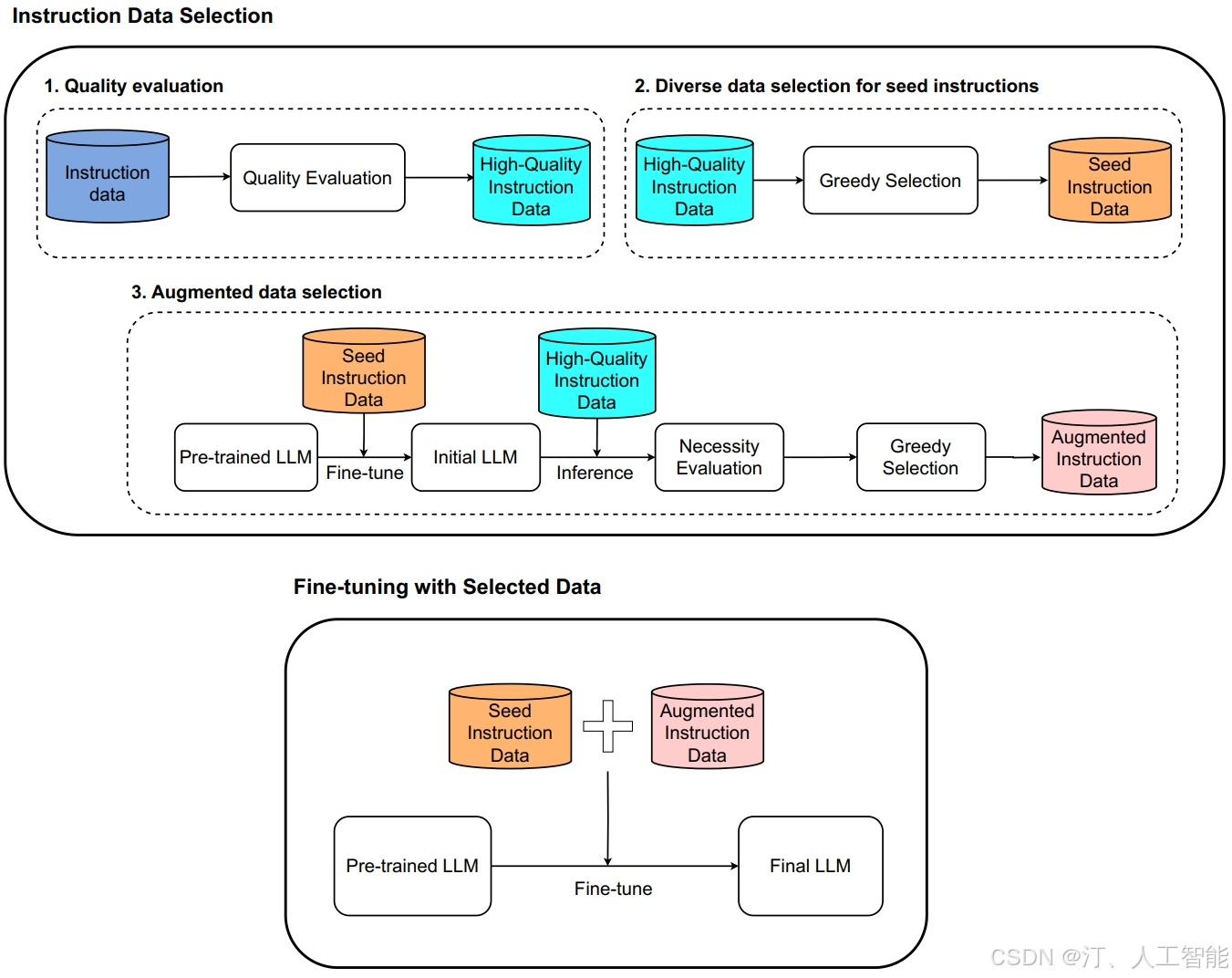
在这里插入图片描述
核心思想:
围绕三个点 quality (质量), coverage (覆盖面) 和 necessity (必要性)。
方法步骤:
- Step 1: 使用 reward-model-deberta-v3-large-v2这一评分模型从海量候选数据中筛选出高质量数据, 被筛选出来的数据就是上图的 High-Quality Instruction Data,这步关注的是 quality。
- Step 2: 使用 k-center greddy algorithm 聚类算法, 以从第一步筛选出的高质量数据中挑选出多样性的数据,即 Seed Instruction Data。这步关注的是 coverage。
- Step 3: 用第二步筛选出来的 Seed Instruction Data 训练基础模型, 用训练后的模型对第一步的所有 High-Quality Instruction Data 进行 loss 计算, loss 大的认为是当前模型不能很好地遵旨的问答对, 论文中认为这些是 necessity 的数据, 这些数据被称为 Augmented Instruction Data。 这步关注的是 necessity。
- Step 4: 最后,将 High-Quality Instruction Data 和 Augmented Instruction Data 混合,对基础模型进行进一步训练。
优点:
- 考虑的比较全面, 改方面考虑了 SFT 数据的质量,多样性和必要性。
缺点:
- 需要依赖一个外部的评分模型,只要是引入外部模型,都是有偏的,很难确保评分模型筛选出来的数据就是难的样本。
- 整体流程相对复杂,涉及多个步骤和算法。
Non-Target Method 4:CaR ☆

项目:https://github.com/IronBeliever/CaR
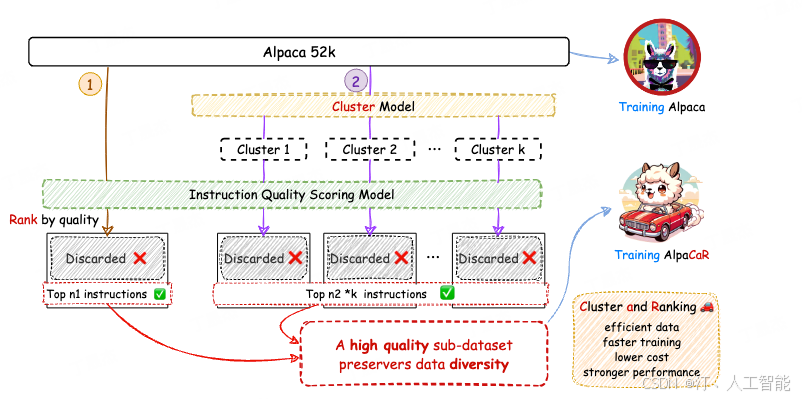
核心思想:
同 MoDs 的方法十分相似,但流程更为简洁。
该方法融合了质量和多样性两个关键要素。首先,它使用评分模型对数据进行质量评估,筛选出高质量数据作为训练集的一部分。为了保持数据的多样性,还采用 k-means 聚类,并从每个簇中选取高质量数据,作为训练数据的另外一部分。最终筛选出来的数据同时兼顾质量和多样性。
不同点在于该论文中用了较长的篇幅去讨论怎么得到一个更符合人类喜好的评分模型,论文中谈到很多的评分模型其实是倾向于 GPT 偏好的,而不是人类偏好。
优点:
- 兼顾了数据的质量和多样性
- 操作流程相对 MoDS 更为简化
缺点:
- 需要依赖一个外部的评分模型,虽然论文给到了建立这个评分模型的很多经验和 skills,但只要涉及一个 llm 外的外部模型,就是有偏的。 不能确保一致性和内在性。
- 相对于 MoDS, 没考虑数据的 necessity。
Target Method 1:Nuggets

- 项目: https://github.com/pldlgb/nuggets
- 论文链接:https://arxiv.org/pdf/2312.10302
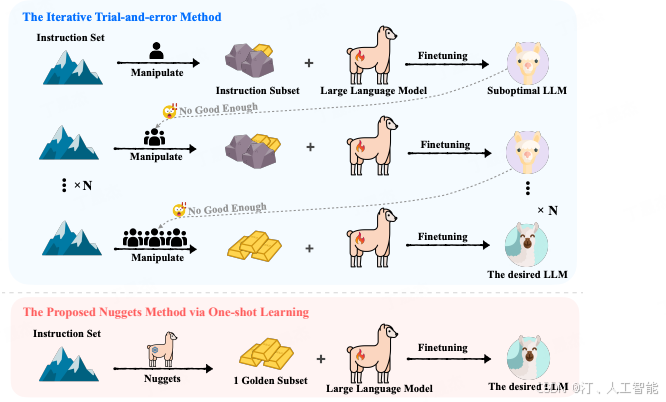
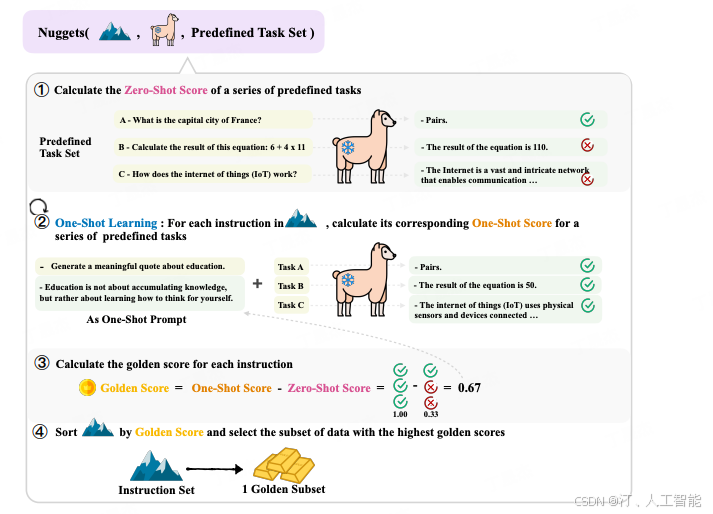
核心思想:
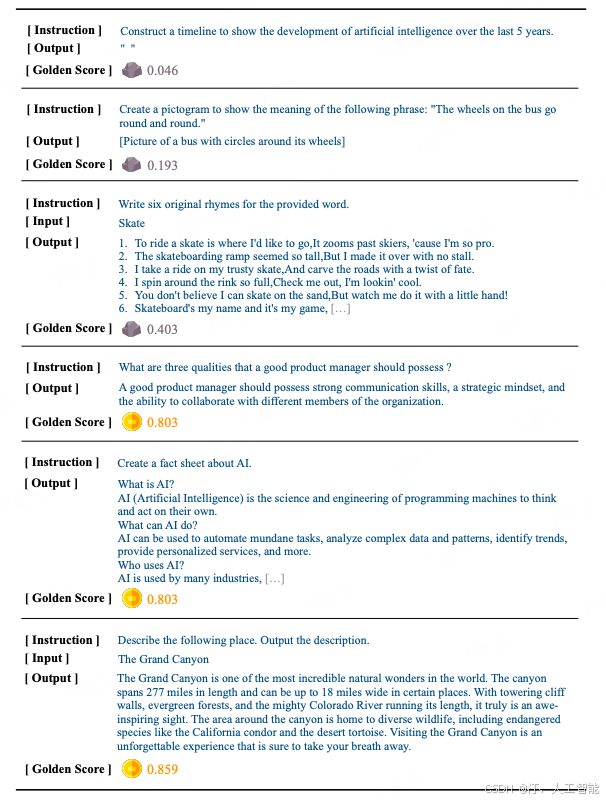
假设,现在我们有 5 个不同的任务场景需要优化,每个任务配有 4 条测试数据,共计 20 条测试数据。目前,我们还拥有 1000 条训练数据。为了评估这些数据对测试集的增益效果,我们将每条训练数据逐一作为 one-shot example,观察加入其后对每条测试数据输出的影响。若加入某条训练数据能降低测试数据的损失(loss),则视为有增益效果,可能值得加入到最终的训练集中。
每条训练数据将根据其对 20 条测试数据中多少条有增益效果来获得一个得分,例如,若一条训练数据能让 16 条测试数据得到增益,则其得分为 0。8(即 16/20)。我们将根据这一得分机制,选择得分高的数据组成精选训练集。下图展示了得分低和得分高的数据示例。可以看到这里得分低的例子,如输出为空,或没有真正输出一张图片。
优点:
- 方法直观, 直觉上让人觉得有效。
- 实施难度低。
缺点:
- 计算复杂度高, 因为需要对每条训练数据与每条测试数据进行配对计算 loss 影响。
- 测试集的质量对最终结果有显著影响,因此需要精心准备能够覆盖不同任务边界场景的测试集。
Target Method 2:LESS ☆

- 项目: https://github.com/princeton-nlp/LESS
- 论文:https://arxiv.org/abs/2402.04333

核心思想:
同 Nuggets, 一样要首先得到你需要优化场景的诺干测试集,不同于 Nuggets 的是, Nuggets 是考察训练集作为 one-shot 对测试集的提升, LESS 更直接, 考察的是训练集给模型梯度优化方向对测试集 loss 的下降, 选择那些对测试集 loss 下降最大的那些训练集作为 gold train dataset。 实质上, 论文中考虑得更全面,如为了更精细得到损失的影响,设置了 warmup 的环境,为了空间的友好型,使用了 Lora搭配降维等等各种探究, 这篇论文有陈丹琪的挂名,值得深度!
LESS 方法的核心思想同 Nuggets 类似,都是基于一个明确的场景测试集挑选数据,考虑候选训练数据对这个测试集的提升作用。与 Nuggets 不同的是,LESS 不依赖于训练集作为 one-shot example 对测试集的提升,而是直接考察假如模型对这条候选训练数据进行训练时,模型梯度优化方向对测试集损失的降低。通过选择那些能最大程度降低测试集损失的训练数据,我们得到了所谓的 “target gold train datset”。这种方法考虑得非常周全,例如通过 warm up 来更精确地衡量损失的影响,同时使用 Lora 搭配降维等技术以优化空间效率。这篇论文还有陈丹琪的参与,论文写作十分完备,值得深入研究。
具体例子:
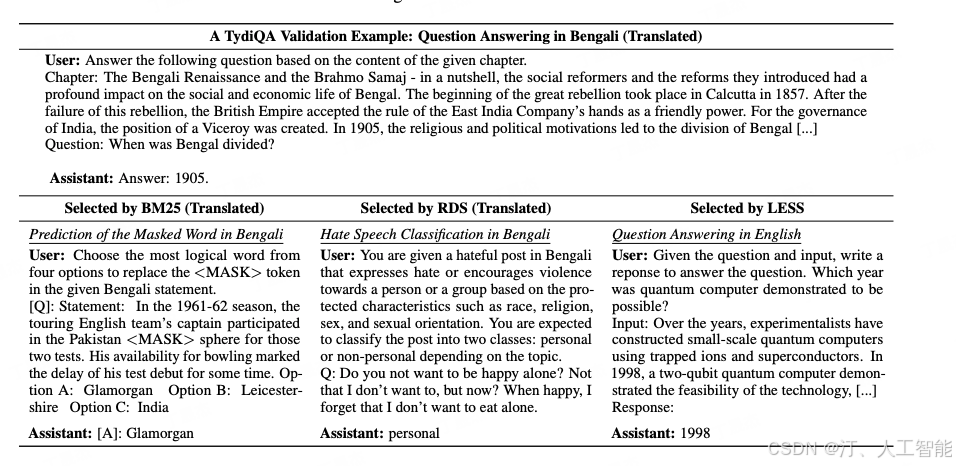
该论文中的一个有趣例子展示了 LESS 方法的有效性。在这个例子中,红框内是一条孟加拉语的测试集,而下方三个例子则是通过不同方法找到的对这条验证集最有贡献的训练集。可以看到,基于字符表面的方法如 BM25 只能召回相同语种和词汇的例子,而 RDS 使用嵌入式的召回方法。令人印象深刻的是,LESS 方法找回了一个英文例子,且改例子其难度与验证集相似。这证明了 LESS 能从更深层次筛选数据,并揭示了大型语言模型对不同语种的内在对齐能力。

优点:
- 方法简单, 直觉上让人觉得有效。
- 对训练集进行统计,就可以轻松地将其迁移到不同的测试集上。
缺点:
- 同 Nuggets 类似
小结
- 确保回复的质量、多样性和有效性
- 质量优先:在挑选用于模型学习的数据时,首先要确保这些数据能够生成高质量的回答。这意味着避免出现答非所问、格式混乱或回答过于简略的问题。
- 强调多样性:为了提升模型的泛化能力,所选数据应具有足够的多样性。这有助于模型在面对各种问题时都能给出准确且丰富的答案。
- 评估数据的有效性:每一条被选中的数据都应该经过严格评估,以确定其对提升模型性能的实际价值。
- 根据应用场景选择最适合的方法
- Target Method 更适合工业应用:这种方法更适合于具体的业务场景,因为它通常涉及与产品经理讨论特定的应用案例,而不是宽泛的场景描述。因此,在实际部署中更为实用和高效。
- Non-Target Method 更适合消费者领域:当应用场景不明确时,这种策略可能更加合适。然而,在这类情况下,直接采用已调优的开源模型(如 qwen-chat 或 yi-chat)可能是更佳的选择。
- 综合运用多种筛选方法提高鲁棒性
- 建议将大约70%的数据来源定为目标导向型方法(例如LESS),而剩余30%则来自非目标导向型方法(如CaR)。这样的组合不仅有助于增强模型的准确性,还能增加其应对不同情况的能力,从而提升整体的鲁棒性。
- 注意数据叠加效应中的潜在问题
- 在使用专注于目标优化但忽略多样性的方法(比如Nuggets和LESS)时,需要注意数据叠加可能导致的非线性增益问题。例如,即使单独看来两条训练数据各自能带来10分的改进,但它们共同作用时未必能得到20分的总增益,有时甚至会低于预期。这是因为某些数据之间可能存在冗余甚至冲突,导致效果不如预期。因此,在使用这些方法时需特别注意这一点。
参考链接:大模型SFT数据精选方法
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-04-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号