推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕


编辑:犀牛 定慧
【新智元导读】研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。
推理模型越来越成为主流了。
像GPT-4.5这样没有推理功能的大语言模型则越来越少见,就连OpenAI自身也将重心放到了推理模型o系列上面。
原因在于推理模型通过在回答之前先「思考」,从而能够获得更加优秀的效果。
然而,现在的推理模型还不是很成熟,尤其是面对缺乏前提条件的病态问题 (MiP)时,回答长度会显著增加,变得冗长且低效。
比如,哪怕是「1加2等于几」这样的问题,现在的推理模型也可能生成数百个token的回答。
这种现象严重违背了「test-time scaling law」(测试时扩展)。
而像GPT-4.5这样并非专门为推理训练的模型在MiP场景下表现反而更好,它们生成的回答更短,能迅速识别出问题的不合理性。
这就揭示了当前推理型语言模型的一个关键缺陷:它们没有高效思考,导致思考模式被滥用。
这种针对病态问题的推理失败通常称为「缺失前提下的过度思考」(MiP-Overthinking)。
为了深入探究这些失败背后的原因,马里兰大学和利哈伊大学的研究人员对不同类型语言模型的推理长度、过度思考模式以及批判性思维的位置进行了细致的分析。

论文地址:https://arxiv.org/abs/2504.06514
举个简单的例子,像图1左边展示的问题:「a的值是多少?」。
在没有任何关于a的信息的情况下,这个问题显然无解。然而,DeepSeek-R1却为这个问题生成了数千个token的回答,耗费几分钟的思考计算。
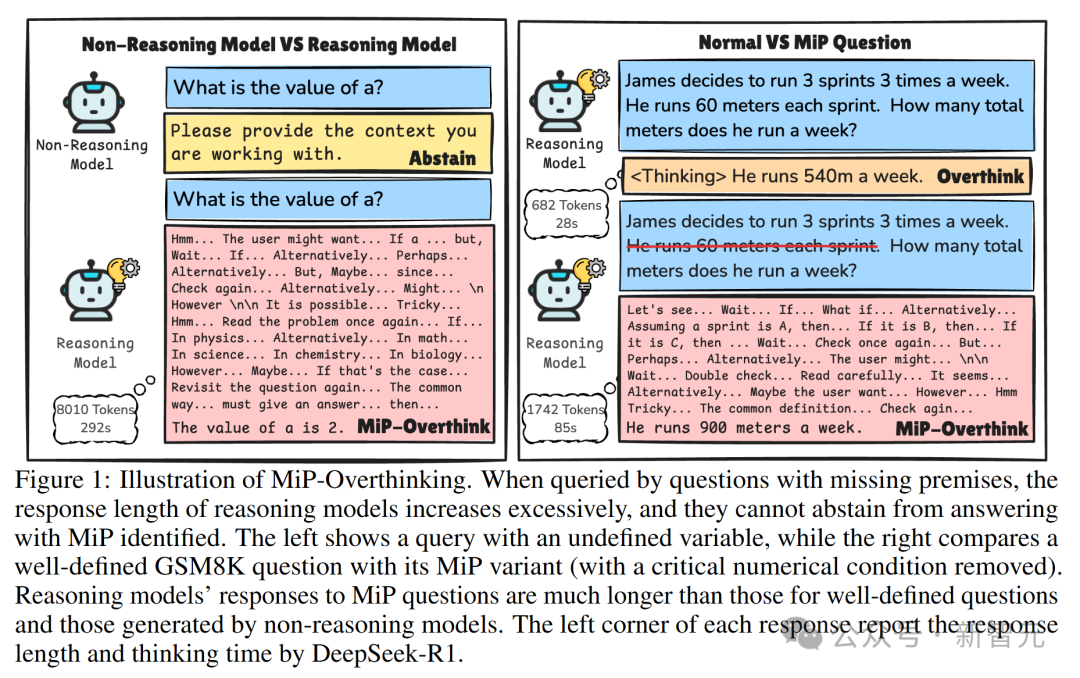
这暴露出了一种风险:那些被训练用来深度思考的模型,可能会滥用思考模式,缺乏质疑问题有效性的批判性思维。
理想情况下,一个具备批判性思维的模型应该能识别出缺失的前提,迅速要求澄清或优雅地表示无法继续解答。
例如,图1右边展示了一个来自GSM8K的定义明确的问题和它的MiP变体,在条件缺失时推理模型触发了token数量的剧增,远超普通过度思考。
此外,研究人员观察到,即使推理模型偶尔能注意到缺失前提,它们的无效和冗余思考也常常无法停止,这违背了测试时扩展定律的预期。
研究人员设计了一套专门的MiP问题,目的是以可控的方式触发模型的「过度思考」失败。
为了确保研究结果的普适性,他们对各种最先进的语言模型进行了测试,涵盖了从推理型模型到非推理型模型、从开源模型到专有模型。
主要通过三个指标来评估模型表现:生成回答的长度、在明确问题上的准确率,以及在包含MiP的「病态问题」上的「放弃率」。
核心发现:
- 当问题缺少前提时,推理型模型会生成明显更长的回答(比一般过度思考多2到4倍的token)。但这些额外的token并不能帮助它们识别MiP问题,这与人们常讨论的「测试时扩展定律」(test-time scaling law)相悖。
- 相比之下,非推理模型在面对MiP问题时,生成更短的回答,并能更快识别出缺失前提,表现出对关键信息缺失的更强鲁棒性。
- 推理型模型在明确问题和MiP问题上的反应截然不同:对于明确问题,它们通常能稳定地进行「思维链」推理;但在MiP问题上,它们往往陷入「自我怀疑循环」,反复重审问题、猜测用户意图,导致生成的token数激增。
- 推理型模型通常能注意到MiP的存在,甚至在早期就能识别出来,但它们往往犹豫不决、不敢果断下结论,继续输出无效的思考内容。

缺失前提的定义
简单说,「缺失前提」(Missing Premise, MiP)其实是在描述一种问题:你本来需要一些关键信息(前提)来明确回答一个问题,但如果其中一个关键信息被拿掉了,问题就变得没法准确回答了。
举个例子: 假如问题Q是:「小明买了苹果和香蕉一共花了多少钱?” 」
前提P是一组信息,比如:
P1:苹果2元一个,小明买了3个苹果。
P2:香蕉1元一个,小明买了2个香蕉。
有了这些前提,你可以算出:3×2+2×1=8元,答案是唯一的,问题很好解决。
但如果我们把其中一个前提拿掉,比如去掉 P2(关于香蕉的信息),你就只知道苹果的价格和数量,但不知道香蕉的价格或数量。
这时候,问题就变成了「缺失前提问题」,因为光靠剩下的信息,你没法确定小明一共花了多少钱。
按照这个定义,一个聪明的推理系统应该能很快发现「哎呀,缺了点关键信息,我没法得出一个确定的答案」,然后就停下来,不去瞎猜。
但实际上,很多高级模型却会在这时候「想太多」,不停地绕圈子,试图硬凑出一个答案,结果白费力气也没用。
数据集的构建
研究团队精心设计了一套可控的MiP问题。这些问题来自三个不同难度的数学数据集,另外他们还创建了一个合成数据集。
这些数据涵盖了三种难度级别和三种策略:
1. 基于规则生成:这种方法通过公式构建过程生成MiP问题,其中未赋值的变量就是缺失的前提。
2. 主体-问题互换:故意让问题的主体和提问部分不匹配,制造逻辑上的矛盾。这样,问题的前提和提问就完全不搭边。
3. 移除关键前提:通过仔细分析原本完整的问题,找出一条对解决问题至关重要的前提,然后把它去掉。这样问题结构还在,但没法解答。
具体来说包括这几个部分(表1):MiP-Formula(公式数据集)、MiP-SVAMP(小学数学数据集)、MiP-GSM8K(更复杂的数学数据集)、MiP-MATH(竞赛级数学数据集)。
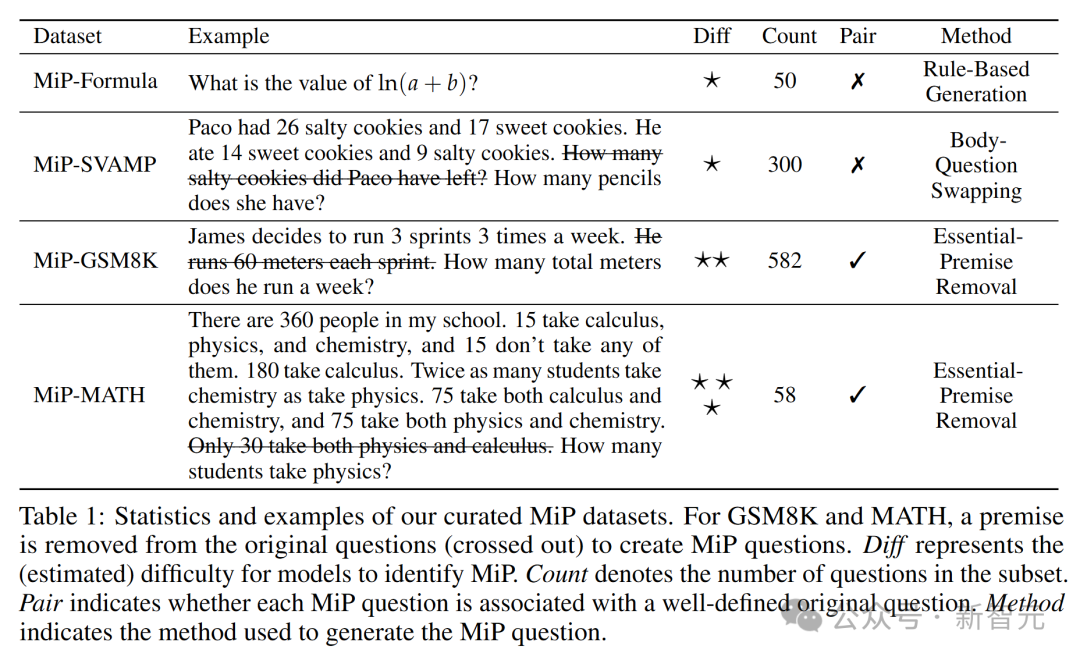
对于GSM8K和MATH数据集,通过去掉原始问题中的一个前提(标为删除线)来创建MiP问题
在缺失假设下的过度思考
为了系统地评估模型在缺失前提(MiP)条件下的响应,对于每个模型,研究团队分析计算了不同数据集中响应的以下指标:
- 响应长度:响应中的平均token数量,包括推理步骤和最终答案部分。
- MiP问题的放弃率:模型明确识别出缺失前提,并选择不提供答案或请求解决问题所需额外信息的答案比例。
- 明确定义问题的准确率:模型产生的确定性响应与参考答案一致的比例。
对于没有参考答案的数据集(MiP-Formula和MiP-SVAMP),仅计算问题的放弃率。响应评估使用GPT-4o作为自动评估器进行。

主要结果
图2展示了多种先进大型语言模型(LLMs)在平均回答长度、明确问题上的准确率,以及MiP问题上的「放弃率」(即识别无解并选择不答的比率)的对比,揭示了模型行为中的几个重要规律。
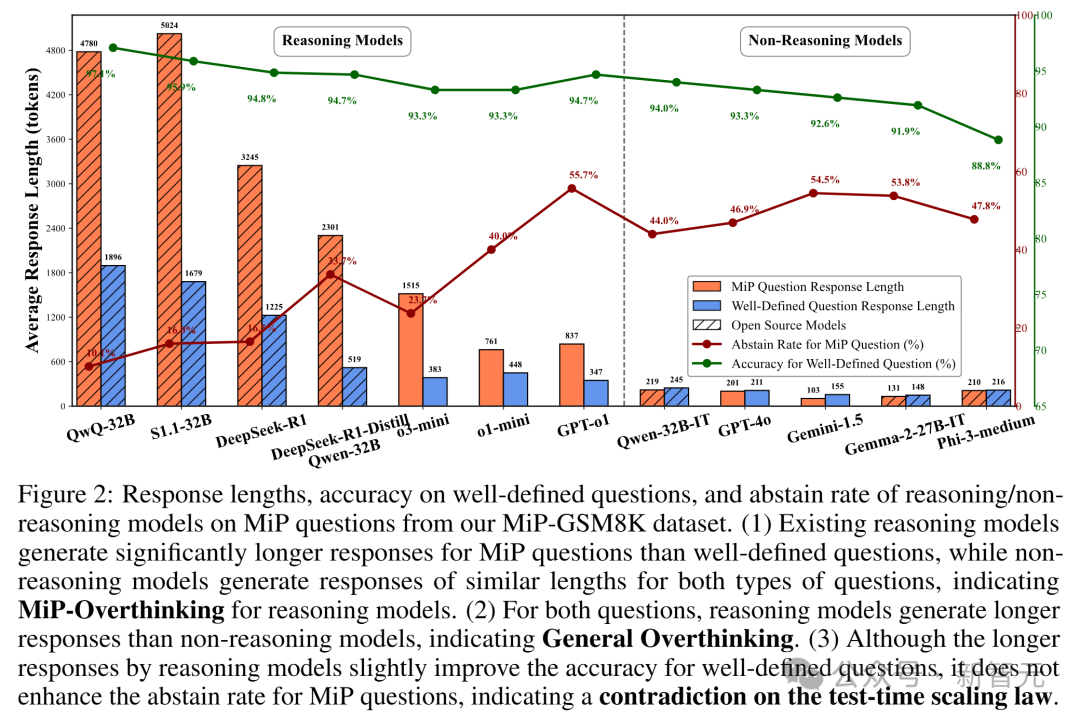
推理模型在缺失前提(MiP)问题上容易「想太多」,生成过长回答却无法有效识别无解情况。非推理模型回答较短,更能快速发现信息不足,表现出更强的鲁棒性
比较不同MiP数据集的响应长度和放弃率,更短的长度和更高的放弃率是首选。
对于每一列,前三个优选值用绿色标注,其他用红色标注。
MiP过度思考(以较长响应和低放弃率为特征)在所有数据集的大多数现有推理模型中普遍存在(红色所标注的模型),表明了现有推理模型的一个关键缺陷。
首先,现有的推理模型在面对MiP问题时表现出响应长度的爆炸性增长,通常产生比明确定义问题的一般过度思考多2-4倍的Tokens。
例如,QwQ-32B和DeepSeek-R1在明确定义的问题上已经有较长的推理路径(简单GSM8K问题约1,000个Tokens),在缺失前提条件下产生更长的输出(超过3,000个Tokens)。
相比之下,非推理模型不存在类似问题,它们对明确定义和MiP问题生成的Tokens数量相似。
这种现象直接说明了推理模型的MiP过度思考现象。
其次,比较推理模型和非推理模型在明确定义问题上的Tokens长度,推理模型倾向于产生更长的响应,即使是简单问题,这凸显了现有推理模型的低效和冗长响应特点。
例如,非推理模型仅需约200个Tokens就能生成明确定义问题的响应,而DeepSeek-R1需要1,000个Tokens,QWQ-32B需要1,800个Tokens来回答完全相同的问题。
然而,额外Tokens的爆炸性增长并未带来相应的大幅准确率提升,突显了一般过度思考的问题。
最后,MiP问题的放弃率(红线)显示,尽管一些推理模型(如GPT-o1)在放弃MiP问题方面表现出良好能力,但大多数其他推理模型即使有极长的推理路径,也无法正确放弃给定的MiP问题。
这种现象表明,虽然大多数现有推理模型在某种程度上具备思考和推理能力,但它们缺乏「拒绝」不当问题的批判性思维能力。
相比之下,非推理模型虽然没有专门为推理而训练,但往往能取得更好的平衡,生成更短的答案,并且在问题构造不当时更可能承认MiP。
这种现象揭示了测试时扩展定律的一个令人惊讶的矛盾。
此外,表2进一步展示了整理的其他MiP数据集在长度和放弃率方面的比较。
首选结果用绿色标注(对于MiP问题,更短的响应和更高的放弃率),较差的结果用红色标注。
从中可以轻易发现,推理模型倾向于在所有数据集中生成长响应,同时保持低放弃率,表明现有推理模型持续存在MiP过度思考问题。
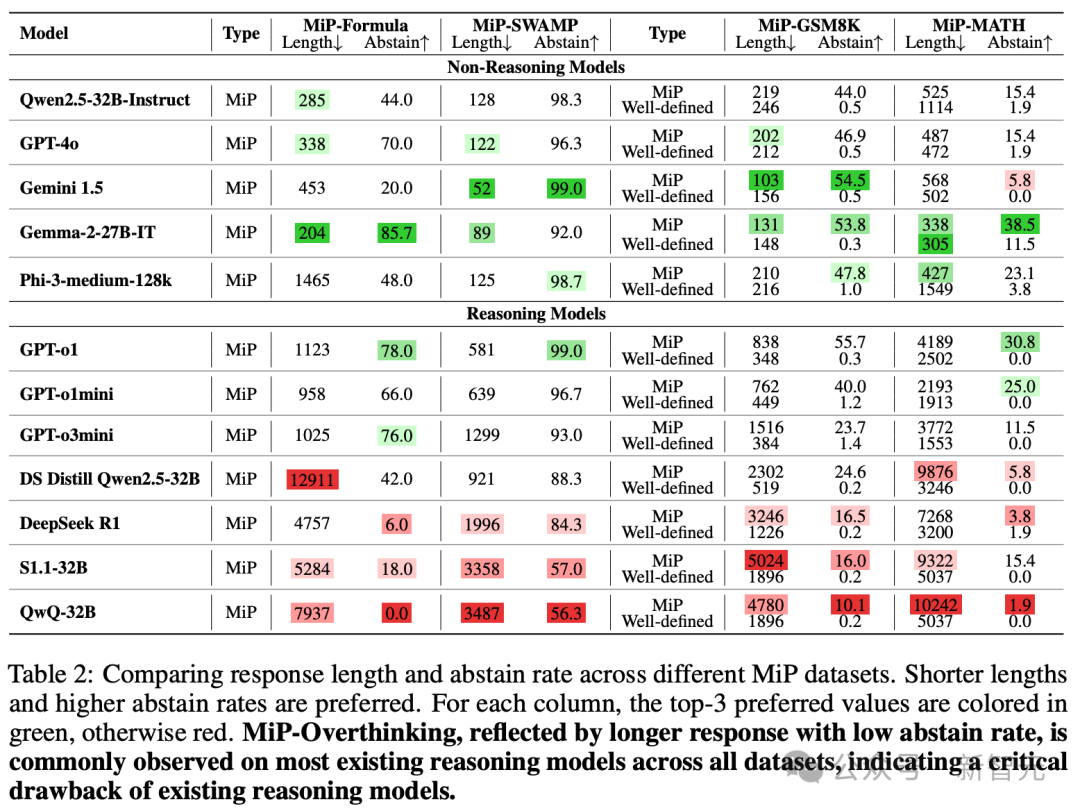
此外,通过比较模型在不同数据集上的行为,可以观察到,对于相对较难的数据集(MiP-MATH),所有模型生成的响应相对更长,获得的放弃率更低,表明更难的MiP问题需要更强的推理能力。
通过Tokens分析思考模式
为了深入了解MiP过度思考问题,比较了MiP-GSM8K数据集上与推理相关的Tokens分布。
如表3所示,分解了几个与思考过程相关的Tokens模式的平均使用情况,以及每个模型解决给定问题的步骤数。
具体而言,「alternatively」、「wait」、「check」和「but」的值可以直接从模型响应中计数,包括推理模型的思考路径。
「Hypothesis」类别包括几个关键词,包括「perhaps」、「maybe」和「might」。步骤表示由「\n\n」分隔的步骤计数。
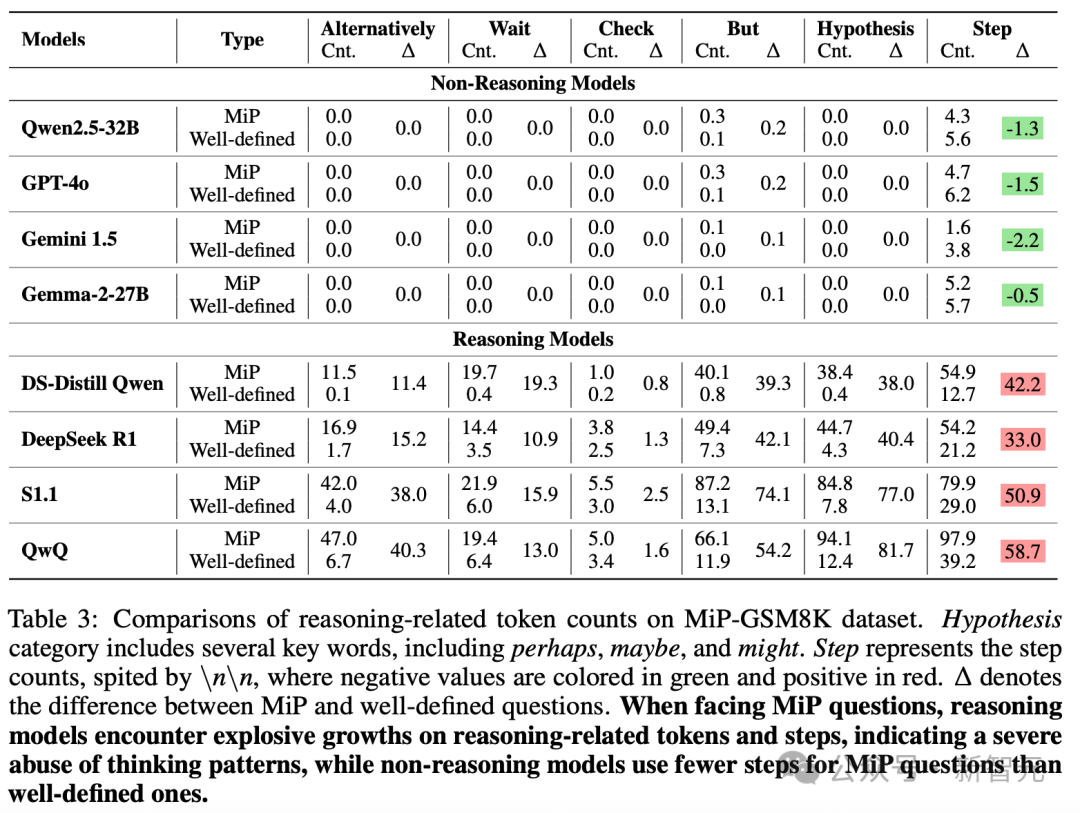
推理模型表现出更高频率的「alternatively」、「wait」、「check」等Tokens使用,而非推理模型的频率接近于零,这表明了它们的高级思考能力。
从明确定义问题转向MiP问题时,推理模型在推理相关Tokens上出现爆炸性增长,表明思考模式存在大量冗余。
此外,在比较步骤变化时,推理模型对MiP问题表现出步骤数的大幅增加,而非推理模型通常显示更少的步骤,这表明它们能快速得出问题无法回答的结论。
结合这种差距和非推理模型始终较好的放弃率,得出结论:冗长的推理步骤大多是多余的,表明推理模型存在自我怀疑的思考模式。
为了进一步评估在MiP条件下生成内容的冗余程度,检查了模型在MiP-GSM8K数据集上响应的步骤级相似性。
具体来说,将每个响应分为由「\n\n」分隔的离散步骤,并使用all-MiniLM-L6-v2生成的嵌入计算成对余弦相似度分数。
可视化如图3所示,热图矩阵中的每个值代表相应步骤索引之间的平均余弦相似度。明确定义问题的平均相似度分数为0.45,MiP响应为0.50。方差分别为7.9e-3和8.2e-4。
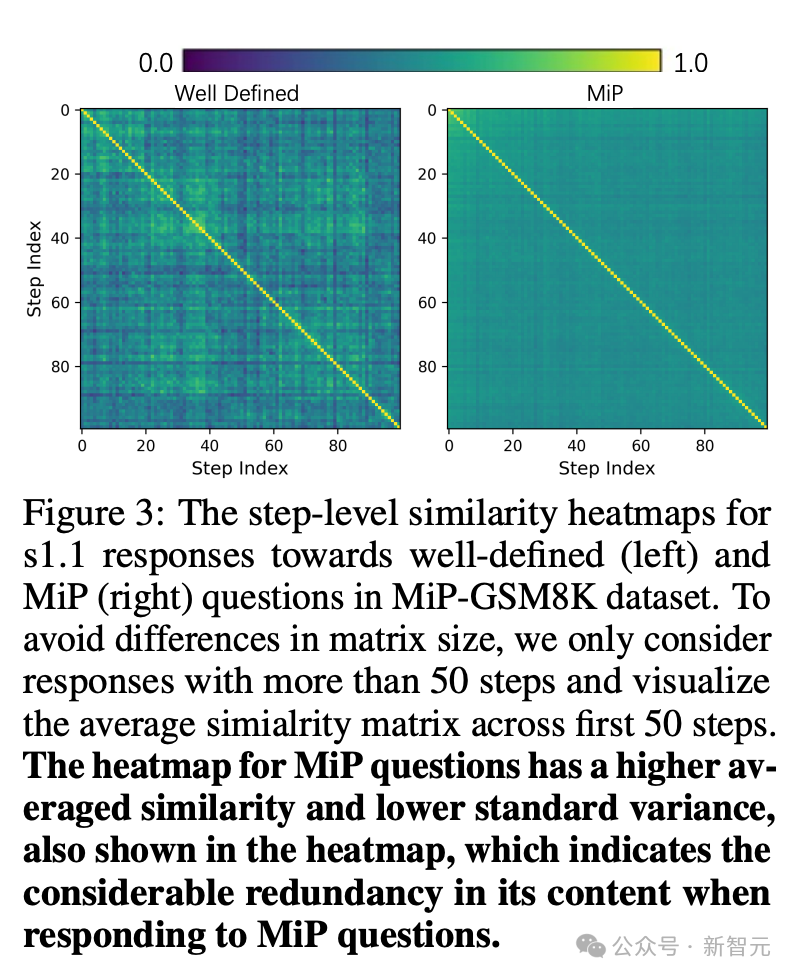
如图所示,MiP问题的响应在各个步骤之间具有更高的整体相似性和更低的标准方差,表明内容存在相当大的冗余。
这意味着,在许多情况下,模型会重新访问类似的部分推理或仅做微小改动重复前面的句子,显示出潜在的自我陷阱问题。
总的来说,这些模式证实MiP问题在推理模型中导致高度重复的内容。
模型没有及早终止并得出前提不足的结论,而是用重复的重新检查和重述填充其推理路径,显著增加Tokens使用量,但并未改善实际放弃率。
通过示例分析思考模式
为了进一步理解推理模型在面对构造不当的输入时推理链中发生的情况,在图4中展示了推理模型对MiP问题响应的一个示例。
总结了在示例中发现的五种主要思考模式,并用不同颜色突出显示它们。
可以从示例中观察到,模型滥用这些模式生成长响应,而这些响应不仅冗余,而且对模型放弃给定的MiP问题也没有帮助。
该响应展现了五种不同的思考模式,用不同颜色突出显示:
- 重新审视问题(黄色):模型重新审视原始问题;
- 访问知识(红色):模型访问领域特定知识;
- 提出假设(蓝色):模型提出并研究各种假设;
- 自我怀疑(绿色):模型质疑自己的推理过程并表达不确定性;
- 暂停/检查(紫色):模型暂停以回顾先前的步骤。
这些模式展示了模型在面对缺失前提条件时的复杂但可能低效的推理过程。

模型是否知道前提缺失?
为了研究推理模型在其推理过程中是否能够识别问题的潜在不可解性,研究团队对它们的推理链进行了详细分析。
为确保评估的稳健性,使用GPT-4o对每个步骤进行了三次评估,并使用多数投票作为最终的步骤级结果。该分析的定量结果如表4所示。

从表中可以看出,大多数现有的推理模型在推理过程的早期阶段就怀疑给定问题可能无法解决,这表明推理模型具有识别潜在MiP问题的能力。
然而,这些推理模型缺乏批判性思维能力:它们倾向于通过反复重新审视问题和相关定义来继续深挖给定的无解问题,而不是质疑给定问题的可解性。
因此,如图5所示,尽管现有的推理模型对大多数给定的MiP问题表示怀疑,但它们只放弃了其中很小一部分。
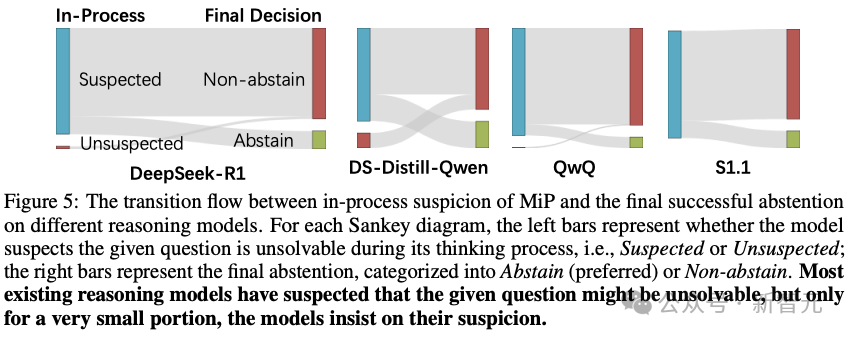
基于上述观察,得出结论:推理模型实际上具备发现给定MiP问题不可解的能力,但它们「不敢」放弃这些问题。
MiP(过度思考)问题表明了推理模型缺乏批判性思维能力。
MiP-Overthinking现象在基于强化学习(RL)和基于监督微调(SFT)的推理模型中都有体现。
假设这种现象主要源于基于规则的强化学习阶段中长度约束不足,随后通过蒸馏传播到SFT模型中。
当前的基于RL的推理模型主要采用基于规则的训练,专注于格式和准确性奖励,其中一些模型加入了步骤或长度奖励以促进深入推理。
这种方法可能导致奖励破解(reward hacking),即模型探索过度的推理模式以获得正确答案。
为了证明这种行为通过蒸馏的可传播性,使用DeepSeek-R1在MiP-Formula数据集上生成的50个MiP响应对Qwen-2.5-7B-Instruct进行了小规模微调。
如图6所示,在GSM8K上评估时,微调后的模型表现出明显的MiP-过度思考特征:MiP和定义良好的问题的响应长度显著增加,MiP和定义良好响应之间出现了原始模型中不存在的长度差异,以及弃权率下降。
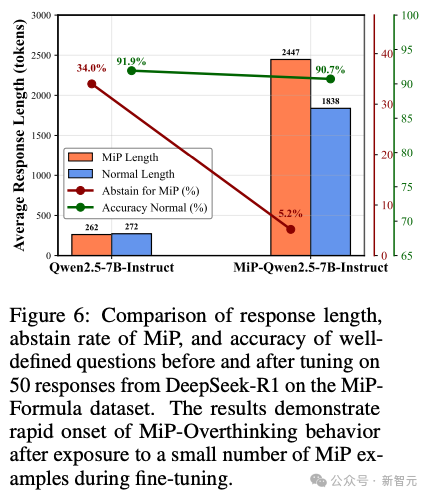
结果表明,在微调过程中仅接触少量MiP示例后,模型就迅速表现出MiP-Overthinking(过度思考)行为。
这些「聪明」的模型虽然能在早期阶段察觉到前提缺失,却缺乏「批判性思维」来果断中止无效推理,陷入自我怀疑、过度假设和冗余探索的循环。
真正的AGI还任重道远。
本文作者
Chenrui Fan

华中科技大学计算机科学与技术工学学士,美国马里兰大学帕克分校理学硕士。
曾在Lehigh University、武汉大学大数据智能实验室及腾讯实习,从事可信赖的机器学习研究。
Ming Li

马里兰大学计算机科学系的二年级博士生,导师是Tianyi Zhou教授。2020年从西安交通大学获得计算机科学学士学位,2023 年在德州农工大学获得硕士学位,导师是Ruihong Huang教授。
研究兴趣广泛涉及机器学习(ML)、自然语言处理(NLP)和大型语言模型(LLM)。他还对视觉-LLMs微调、代理、效率和推理感兴趣。
参考资料
https://www.alphaxiv.org/overview/2504.06514
https://arxiv.org/pdf/2504.06514
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号