4875倍性能飞跃!智能 SQL 优化工具 PawSQL 如何将EXISTS子查询"秒拆"为JOIN连接

4875倍性能飞跃!智能 SQL 优化工具 PawSQL 如何将EXISTS子查询"秒拆"为JOIN连接

PawSQL
发布于 2025-04-09 15:08:04
发布于 2025-04-09 15:08:04
在数据库性能调优中,子查询优化是提升查询效率的关键点之一。今天,我们将分享一个使用 PawSQL 对EXISTS子查询进行重写优化的案例,展示如何通过合理的SQL重写与索引设计,实现超过487516.45%的性能提升!
一、案例分析:EXISTS子查询的性能困境
这个查询的目的是找出所有关联零件名称为 'indian navy coral pink deep' 的订单项。
select *
from lineitem as l
where exists (
select *
from part as p
where p.p_partkey = l.l_partkey
and p.p_name = 'indian navy coral pink deep'
)这种写法虽然逻辑清晰,但在大数据量情况下,子查询可能会对性能造成较大压力。
通过分析其执行计划,我们发现其执行瓶颈:
- 对600,572行的lineitem表进行全表扫描
- 嵌套循环中60万次主键查找part表
- 每次循环都需要执行字符串过滤条件判断
- 总执行时间达到1219ms
二、PawSQL智能优化策略:查询重写与索引推荐
2.1 语义等价转换:EXISTS到INNER JOIN
PawSQL 自动应用了 Exists2JoinRewrite 重写优化算法,转换后的查询取消了子查询嵌套,直接通过JOIN条件完成数据关联,使得查询计划可以更直接地利用索引优化,提高查询效率。
select l.*
from lineitem as l, part as p
where p.p_partkey = l.l_partkey
and p.p_name = 'indian navy coral pink deep'技术原理:
- EXISTS子查询通常会导致嵌套循环执行计划,可能效率较低
- 转换为显式连接后,优化器有更多选择执行路径的自由
- 在大多数现代数据库中,显式连接比子查询有更好的优化支持
适用条件:
这一重写规则并非适用于所有EXISTS子查询,它需要满足以下严格条件:
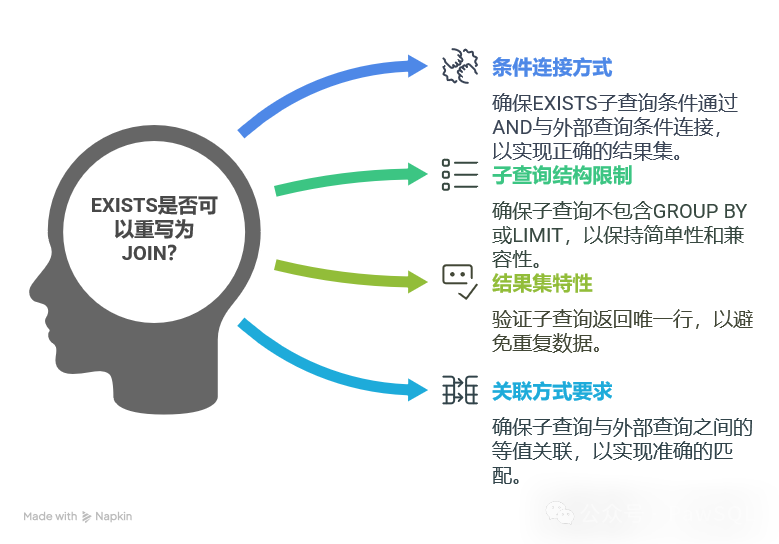
这些条件确保了重写转换在保证语义等价的同时,能够带来实质性的性能提升。
2.2 智能索引推荐
PawSQL识别到现有索引不足以支持高效查询,推荐创建新索引:
CREATE INDEX PAWSQL_IDX1103600139 ON lineitem(l_partkey);
CREATE INDEX PAWSQL_IDX2050589888 ON part(p_name, p_partkey);索引推荐策略
索引名称 | 作用维度 | 覆盖场景 | 优势特性 |
|---|---|---|---|
PAWSQL_IDX1103600139 | 被驱动表(lineitem) | 加速l_partkey关联查询 | 减少全表扫描 |
PAWSQL_IDX2050589888 | 驱动表(part) | 同时覆盖过滤(p_name)和关联(p_partkey) | 覆盖索引避免回表 |
三、性能优化效果
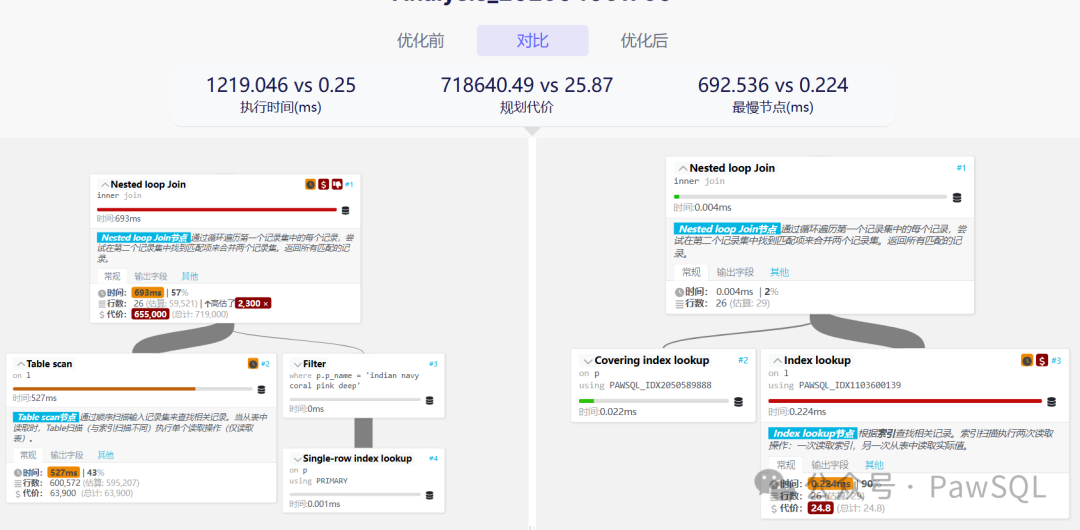
3.1 量化提升指标
指标维度 | 优化前 | 优化后 | 提升倍数 |
|---|---|---|---|
执行成本(cost) | 718,640.49 | 25.87 | 27,777x |
实际执行时间 | 1219ms | 0.25ms | 4,876x |
逻辑读次数 | 600,572 | 1 | 600,572x |
3.2 关键改进点
- 数据访问方式:全表扫描 → 索引范围扫描
- 驱动表顺序:大表驱动 → 小结果集驱动
- 过滤时机:后置过滤 → 查询前置过滤
四、总结
通过本案例,我们不仅看到了一个SQL优化的完整过程,更展示了智能 SQL 优化工具 PawSQL 的强大能力:
- 查询重写引擎:智能转换SQL语义
- 索引推荐系统:精准推荐缺失索引
- 执行计划分析:深度解析性能瓶颈
- 规则检查体系:全面识别潜在问题
PawSQL通过智能算法,将数据库专家的经验转化为自动化算法,让每个开发者都能轻松实现专业级的SQL优化。
🌐 关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持包括MySQL/PostgreSQL/Oracle/openGauss/TDSQL/Oceanbase/达梦DM/金仓等各种主流商用和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号