IBM Deep Archive:磁带存储的云归档

IBM Deep Archive:磁带存储的云归档

数据存储前沿技术
发布于 2025-04-09 13:31:18
发布于 2025-04-09 13:31:18
全文概览
非结构化数据(如图片、视频、日志等)以每年55-65%的速度激增,占据数据总量的80-90%。然而,传统存储方案面临成本飙升、基础设施压力和安全风险的三重挑战。例如,43%的IT决策者担忧现有系统无法支撑未来数据需求,而勒索软件攻击导致的数据恢复成本更是雪上加霜。
在此背景下,IBM推出Deep Archive,通过磁带存储与云技术的深度融合,重新定义低成本、高安全的长期数据归档方案。其兼容S3 Glacier接口的架构,不仅降低冷数据存储成本达85%,更通过物理隔离(Air Gap)和弹性设计,为合规性、灾难恢复和可持续性提供创新解决方案。
阅读收获
- 技术洞察:掌握磁带存储在云时代的成本优势与物理隔离安全机制。
- 架构设计:理解IBM混合云存储层级的分层策略与S3协议适配逻辑。
- 成本决策:通过27 PB十年成本对比,量化磁带存储的经济性。

IBM Deep Archive-Fig.webp
IBM Deep Archive-Fig-1.webp
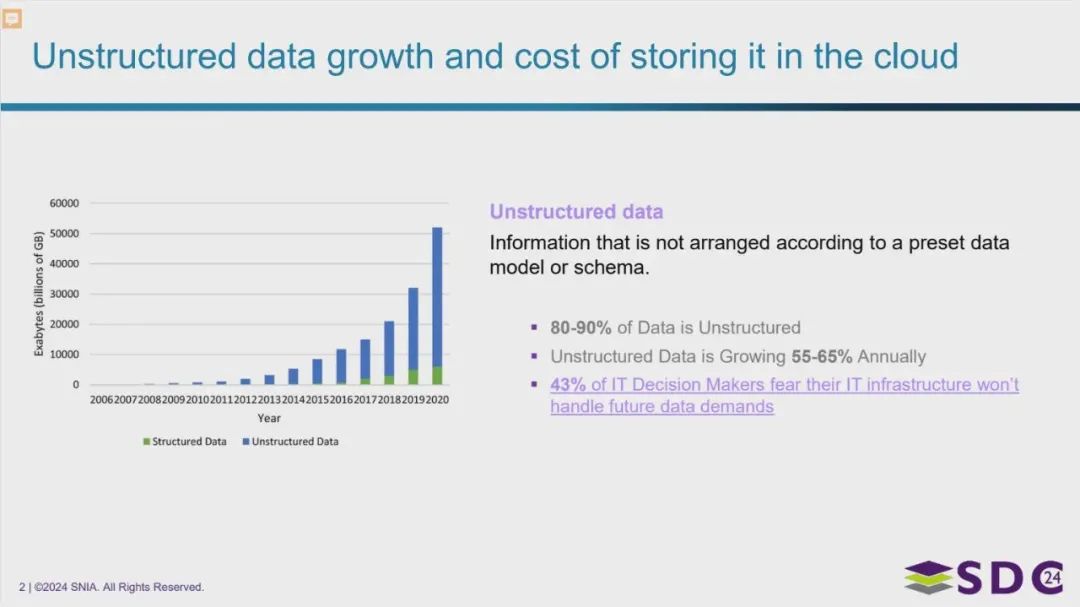
非结构化数据增长以及在云中存储的成本
图片主要展示了非结构化数据在过去十几年中的快速增长趋势,以及其在数据总量中的高占比。图片强调了非结构化数据增长带来的挑战,包括存储成本的增加以及IT基础设施可能无法满足未来需求的担忧。结构化数据虽然也在增长,但增速远不及非结构化数据。
===
- 80-90%的数据是非结构化的。
- 非结构化数据每年增长55-65%。
- 43%的IT决策者担心他们的IT基础设施无法应对未来的数据需求。
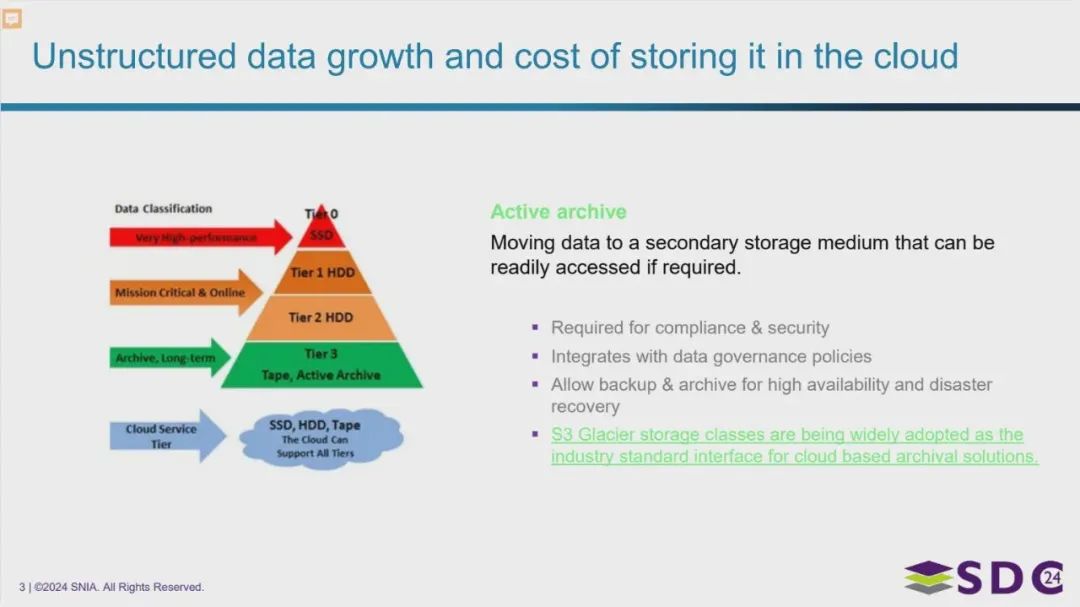
IBM Deep Archive-Fig-2.webp
介绍了数据存储的分类层级,根据性能和成本需求将数据分为不同的层级,从高性能的固态硬盘到低成本的磁带存储。同时,图片也强调了“活动归档”的重要性,它是一种将数据移动到辅助存储但仍能快速访问的策略,对于合规性、安全性、备份和灾难恢复至关重要。最后,图片指出云计算可以支持所有这些存储层级,并且像S3 Glacier(AWS 深度归档 对象存储服务)这样的云存储服务正成为归档解决方案的行业标准。
图片的主要内容是一个数据分类的层级结构,从上到下分为四个层级:
- Tier 0: 最高性能,使用固态硬盘 (SSD)。
- Tier 1 HDD: 用于关键任务和在线数据。
- Tier 2 HDD: 用于归档和长期存储。
- Tier 3: 使用磁带和活动归档。

IBM Deep Archive-Fig-3.webp
图片展示了当前组织在云存储方面的采用情况和面临的挑战。
绝大多数组织都在积极拥抱云计算,并且许多组织计划采用混合云模式。然而,安全性仍然是他们最主要的担忧。此外,超过半数的组织经历过网络攻击。在面临勒索软件攻击时,数据恢复是首要任务。尽管云被认为是数字战略的关键,但不断上升的云存储成本和难以预测的费用(如数据出口费)以及管理云支出是IT决策者面临的主要挑战。

IBM Deep Archive-Fig-4.webp
图片中列出了人们对活动归档的七个主要期望:
- 集成性 (Integration): 标准的、兼容S3的接口,可以轻松集成到现有的基础设施和软件中。
- 成本 (Cost): 具有成本效益,确保价格稳定且没有意外费用。
- 易用性 (Ease of use): 系统不需要高级的磁带知识即可运行,并且可以由S3管理员配置和操作。
- 黑盒 (Black box): 一个包含所有必需组件的自包含解决方案,具有简单的选项设置。
- 弹性 (Resiliency): 数据弹性,确保数据的保护优先于数据访问。
- 安全性 (Security): 从一开始就实施的安全设计,包括加密、监控和物理隔离的访问控制。
- 可持续性 (Sustainability): 必须有助于降低能源消耗、碳足迹和冷却需求。

IBM Deep Archive-Fig-5.webp
IBM Deep Archive 磁带存储解决方案
图片介绍了IBM Deep Archive,这是一个为需要长期、低成本数据存储的组织设计的集成解决方案。它利用磁带存储的优势,提供高容量和吞吐量,同时保持易用性和易集成性。该方案与S3 Glacier兼容,可以显著降低冷数据的存储成本,并且不收取数据出口费用。
IBM Deep Archive:磁带存储的云归档-Fig-1.png
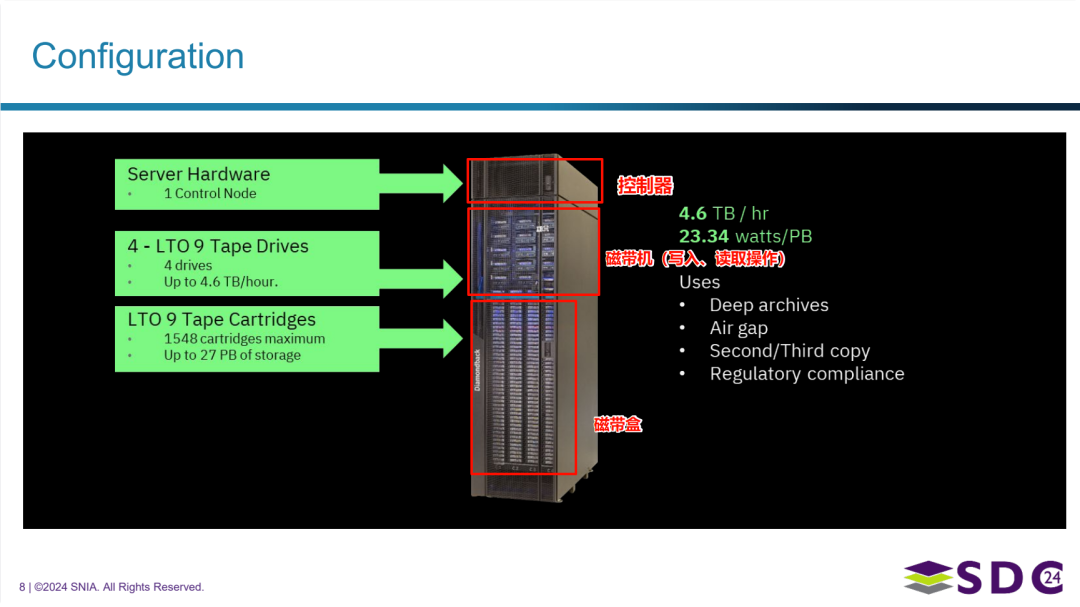
配置
图片展示了IBM Deep Archive的配置信息:
- 服务器硬件 (Server Hardware):
- 1 个控制节点 (1 Control Node)
- LTO 9 磁带机 (LTO 9 Tape Drives):
- 4 个磁带机 (4 drives)
- 高达每小时 4.6 TB 的吞吐量 (Up to 4.6 TB / hour)
- LTO 9 磁带盒 (LTO 9 Tape Cartridges):
- 最多 1548 个磁带盒 (1548 cartridges maximum)
- 高达 27 PB 的存储容量 (Up to 27 PB of storage)
图片右侧列出了一些关键指标和用途:
- 4.6 TB / hr (每小时 4.6 TB 的吞吐量)
- 23.34 watts / PB (每PB 23.34 瓦的功耗)
- 用途 (Uses):
- 深度归档 (Deep archives)
- 物理隔离 (Air gap)
- 第二/第三副本 (Second / Third copy)
- 法规遵从 (Regulatory compliance)
为什么磁带存储将磁带机和磁带盒分离?
磁带存储分离设计的原因:
- 成本效益: 磁带盒(存储介质)的成本相对较低,而磁带机(读写设备)的成本较高。分离设计允许用户购买较少的磁带机,但可以拥有大量的磁带盒用于长期归档。只有在需要读写特定磁带盒上的数据时,才需要使用磁带机。这样可以显著降低长期存储的总成本。
- 可扩展性和容量: 分离的磁带盒可以实现近乎无限的离线存储。当一个磁带盒存满后,可以将其移除并存储在其他地方,然后将新的空白磁带盒放入磁带机中继续使用。这为需要存储大量数据的场景提供了极高的可扩展性。
- 物理安全和便携性: 分离的磁带盒可以轻松地移除并异地安全存储,这为数据提供了更好的物理安全保障,防止灾难或网络攻击(形成物理隔离)。此外,磁带盒也便于携带,在网络带宽有限或不可用的情况下,可以通过物理方式传输数据。
- 磨损和寿命: 磁带机是机械设备,包含许多移动部件,会随着时间的推移而磨损。将存储介质(磁带盒)与驱动器分离意味着更昂贵和复杂的驱动器可以用于多个不同的磁带盒,从而延长其使用寿命并降低每单位存储数据的成本。
- 标准化和互换性: 分离的设计有利于磁带格式的标准化(例如LTO)。用户可以在兼容的磁带机上使用不同品牌的磁带盒。
IBM Deep Archive-Fig-7.webp
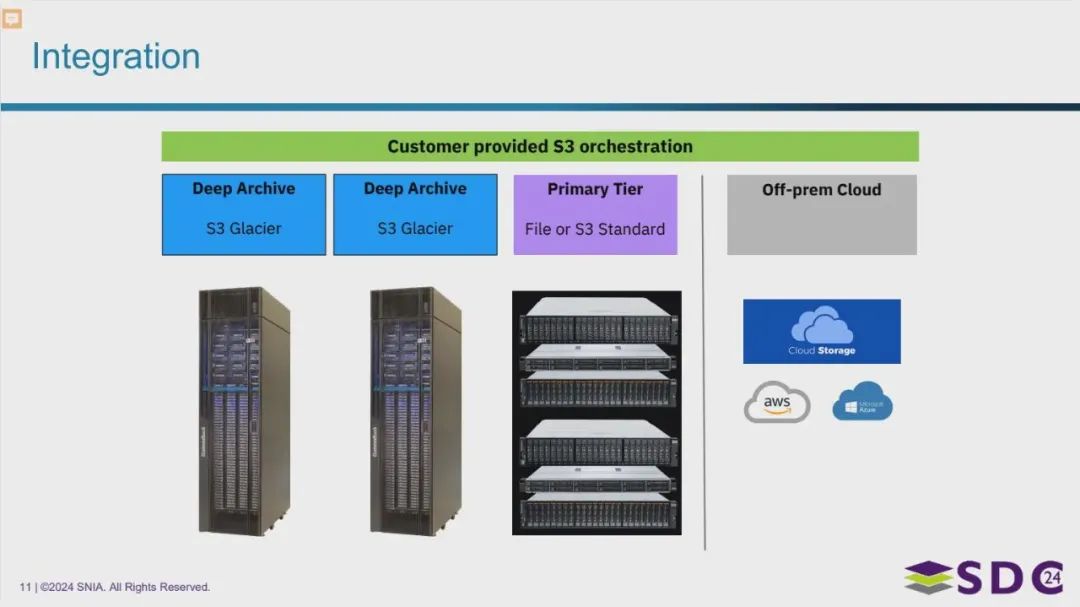
混合云集成能力
图片展示了IBM Hyperswap的集成架构。它描述了一个混合云存储环境,其中客户通过S3接口管理数据。数据可以存储在本地的IBM Deep Archive(作为S3 Glacier的后端)、本地的主存储层(可以是文件存储或S3标准存储),以及异地的公共云存储(如AWS或Azure)。
这个架构旨在提供灵活的数据存储选项,可以根据数据的访问频率和成本需求将数据存储在不同的层级。IBM Deep Archive在此架构中扮演着低成本、长期归档的角色,并与S3 Glacier兼容。
为什么主流磁带存储库要适配S3存储协议?
- 云计算的普及和标准化: Amazon S3已经成为云对象存储的事实标准。越来越多的企业采用混合云或多云策略,希望能够以统一的方式管理和访问不同存储介质上的数据。适配S3协议使得磁带存储库能够无缝地融入云存储生态系统。
- 简化集成和互操作性: S3协议简单易用,拥有广泛的工具和SDK支持。通过适配S3,磁带存储库可以更容易地与各种云服务、应用程序和数据管理平台集成,降低了集成的复杂性和成本。
- 对象存储的优势: 对象存储非常适合存储海量的非结构化数据,而这正是磁带存储的主要应用场景——长期归档和备份。S3协议提供的元数据管理、可扩展性和成本效益等特性,与磁带存储的需求高度契合。
- 统一的数据管理体验: 无论是云端的对象存储还是本地的磁带存储,都通过S3协议进行访问,可以为用户提供统一的数据管理和访问体验,简化操作和管理流程。
- 支持新兴应用场景: 随着大数据、人工智能等新兴技术的兴起,对海量数据的长期存储和低成本访问需求日益增长。S3协议的广泛应用使得磁带存储能够更好地服务于这些新兴的应用场景。
IBM Deep Archive-Fig-8.webp
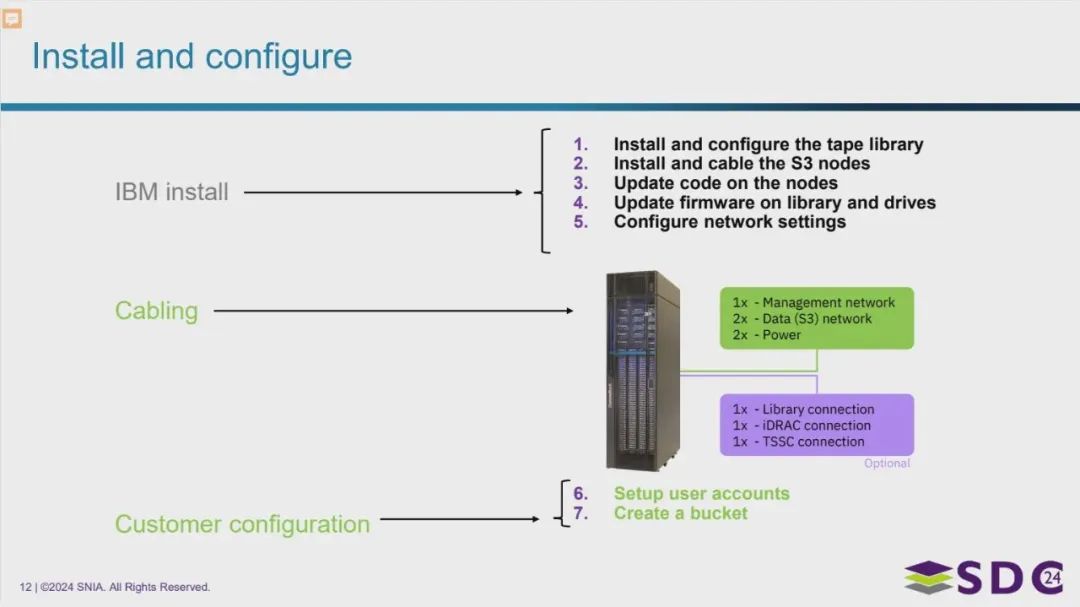
磁带存储系统的安装与配置
图片概述了安装和配置IBM Deep Archive的步骤。安装过程包括物理安装磁带库和S3节点、连接必要的线缆(包括管理网络、数据网络、电源和库连接等)、更新软件和固件,以及配置网络设置。在客户配置阶段,需要设置用户账户并创建一个存储桶才能开始使用。
===
IBM 安装 (IBM install):
- 安装和配置磁带库 (Install and configure the tape library)
- 安装S3节点并连接线缆 (Install and cable the S3 nodes)
- 更新节点上的代码 (Update code on the nodes)
- 更新库和驱动器的固件 (Update firmware on library and drives)
- 配置网络设置 (Configure network settings)
- 设置用户账户 (Setup user accounts)
- 创建存储桶 (Create a bucket)

IBM Deep Archive-Fig-9.webp
灵活检索存储(Flexible Retrieval)
右侧图片介绍了Amazon S3 Glacier Retrieval存储类别,区分3类。
- Amazon S3 Glacier Instant Retrieval storage class (即时检索存储类别): 毫秒级数据检索,属于低成本归档存储类别。
- Amazon S3 Glacier Flexible Retrieval storage class (灵活检索存储类别): 数据检索时间为分钟到12小时,属于成本更低的归档存储类别。
- Amazon S3 Glacier Deep Archive storage class (深度归档存储类别): 数据检索时间为12-48小时,属于成本最低的归档存储类别。
使用IBM Deep Archive,S3应用程序需要使用这个存储类别进行读写操作。
- 数据写入时会先暂存在TapeCloud节点,然后自动迁移到磁带库。
- 恢复数据需要发起RestoreObject请求,并且恢复时间受到磁带盒挂载和寻道时间的影响。
图片还列出了一些关于对象大小、账户和存储桶数量的限制,并对比了S3 Glacier的不同存储类别,强调Flexible Retrieval是成本和检索速度之间的一个平衡选项。

IBM Deep Archive-Fig-10.webp
磁带云管理功能
图片展示了IBM Deep Archive的管理工具TapeCloud Manager的界面和功能。该管理平台提供了全面的监控功能,包括系统健康、容量、吞吐量、节点和磁带库的状态等。
功能类别 (Feature Category) | 功能 (Feature) |
|---|---|
监控 (Monitoring) | 系统健康 (System health) |
事件通知 (Event notifications) | |
容量指标 (Capacity metrics) | |
吞吐量指标 (Throughput metrics) | |
TapeCloud 节点 (TapeCloud nodes) | |
磁带库 (Tape libraries) | |
磁带机 (Tape drives) | |
数据磁带盒 (Data cartridges) | |
清洁磁带盒 (Cleaning cartridges) | |
节点硬件 (Node hardware) | |
管理 (Management) | 系统更新 (System updates) |
库/驱动器固件 (Library / drive firmware) | |
证书 (Certificates) | |
用户账户 (User accounts) | |
库用户账户 (Library user accounts) | |
存储桶 (Buckets) | |
软件日志 (Software logs) | |
库/驱动器日志 (Library / drive logs) | |
节点日志 (Node logs) | |
加密设置 (Encryption settings) | |
NTP / 时间设置 (NTP / time settings) | |
网络设置 (Network settings) | |
服务操作 (Service actions) | 启动/停止/重启节点 (Start / stop / restart nodes) |
关闭/重启节点电源 (Power off / reboot nodes) | |
重新扫描库 (Rescan library) | |
禁用/启用驱动器 (Disable / enable drives) | |
更换数据磁带盒 (Replace data cartridges) | |
更换清洁磁带盒 (Replace cleaning cartridges) | |
验证磁带盒 (Validate cartridges) |
IBM Deep Archive-Fig-11.webp
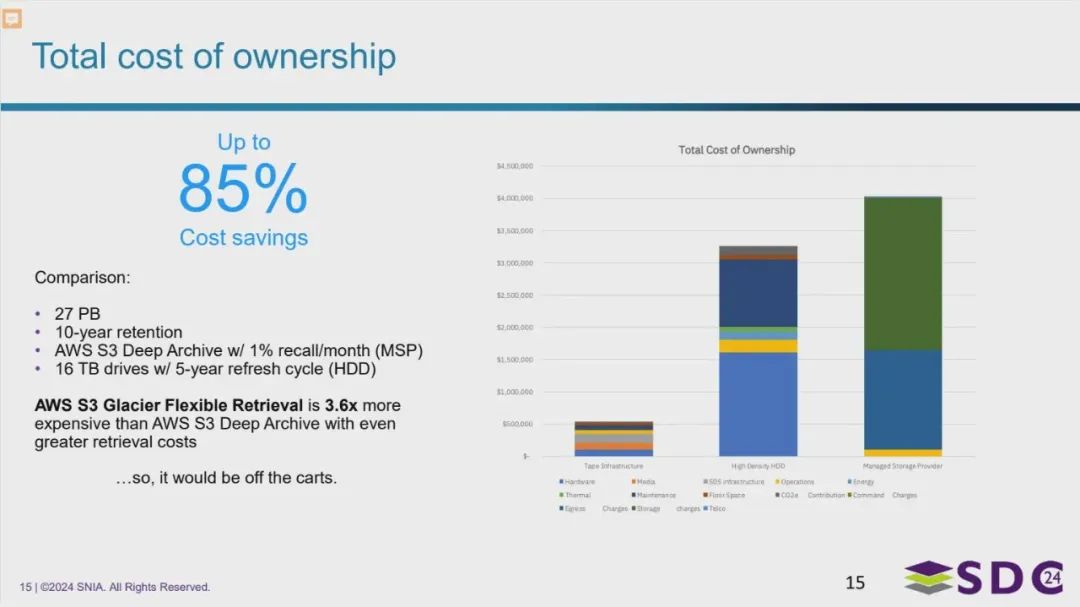
使用成本分析
图片对比了IBM Deep Archive和传统的HDD存储在十年保留27 PB数据时的总拥有成本。
结果显示,与使用16 TB硬盘驱动器并每五年更新一次相比,使用IBM Deep Archive可以节省高达85%的成本。
此外,图片还指出,AWS S3 Glacier Flexible Retrieval的成本远高于AWS S3 Deep Archive,并且取回成本也更高。这强调了AWS S3 Deep Archive作为长期数据存储解决方案的成本效益。

IBM Deep Archive-Fig-12.webp
IBM 存储产品定位
定义了两种产品族,
Deep Archive (深层归档):
- 适用于不常访问的活动归档
- 仅支持S3 Glacier存储类别
- 用户/应用程序可访问的数据归档
- 低成本,高容量
- 最小容量3 PB,最佳容量9+ PB
IBM Storage Scale + CES:
- 适用于AI和数据分析的事务性存储
- 支持文件和对象存储(S3标准存储类别)
- 为用户对象/文件频繁访问提供分层存储
- 全功能的信息生命周期管理平台
- 全自动的数据持久性平台
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 技术平衡:在AI训练等高频访问场景中,磁带存储能否替代SSD或HDD?
- 生态挑战:磁带存储的物理隔离特性如何应对云原生架构的实时数据需求?
- 可持续性:磁带存储的低能耗特性是否能成为“绿色数据中心”的核心解决方案?
原文标题:IBM Deep Archive-Revolutionizing Data Archiving
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号