TreeMap工作原理-Java快速进阶教程

TreeMap工作原理-Java快速进阶教程

jack.yang
发布于 2025-04-05 11:13:40
发布于 2025-04-05 11:13:40
TreeMap 继承AbstractMap实现 Serializable、Cloneable、NavigableMap和SortedMap接口。 TreeMap 不使用哈希方法来存储键,这点与 HashMap ,LinkedHashMap 使用哈希计算来存储键不同。HashMap 和 LinkedHashMap 底层使用数组数据结构来存储节点,但 TreeMap 使用称为红黑树的数据结构。此外TreeMap 中的所有元素都按键排序。默认情况下,TreeMap 对其键按自然顺序执行排序,但它允许您使用 Comparator 来实现自定义排序。我们可以在创建TreeMap 时提供Comparator ,具体取决于使用哪个构造函数。让我们来看看它的构造函数:
- TreeMap():此默认构造函数构造一个空的TreeMap,该TreeMap将使用其键的自然顺序进行排序。
- TreeMap(Comparator comp): 这是一个参数构造函数,它需要 Comparator 对象来构造一个空的TreeMap。它将使用比较器组合进行排序。
- TreeMap(Map map): 它使用Map 中的条目创建一个TreeMap,该TreeMap将使用键的自然顺序进行排序。
- TreeMap(SortedMap sortedMap):它使用 sortedMap 中的条目初始化TreeMap,该TreeMap将按与 sortedMap 相同的顺序排序。
正如我们所看到的TreeMap的各种重载构造函数。让我们看看TreeMap的性能因素如下:
TreeMap的性能
如果与HashMap和LinkedHashMap相比,TreeMap的性能较慢。TreeMap为containsKey()、get()、put()和remove()等方法提供了log(n)的时间复杂度保证。
此外,TreeMap本质上追求提供相对快速处理的数据结构,这意味着它不是同步的,这就是为什么它不是线程安全的。你可以让它在多线程环境下是线程安全的,如下所示:
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));让我们讨论TreeMap的内部结构。
TreeMap的内部树结构
K key; //键
V value; //值
Entry<K,V> left; //左子节点对象
Entry<K,V> right;//右子节点对象
Entry<K,V> parent; //父节点对象
boolean color; //节点颜色
顾名思义,TreeMap基于树数据结构。众所周知,在树中每个节点都有6个元素,其中最重要的3个元素分别是其父元素、右元素和左元素。让我们看下图:
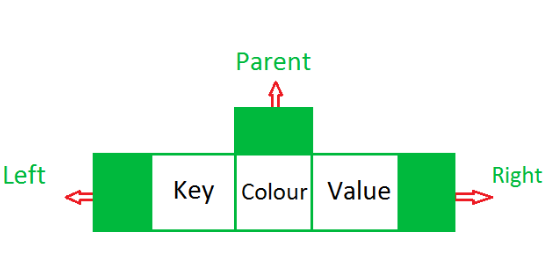
如上图所示,节点中有三个引用,比如父元素、右元素和左元素,它们具有以下属性关系:
- 左元素在逻辑上将始终小于父元素。
- 右元素在逻辑上将始终大于或等于父元素
- 对象的逻辑比较是通过自然顺序完成的,或者基于那些实现可比较接口并覆盖compareTo(Object obj)方法的对象的返回值来确定结果。
让我们看看 compareTo() 方法的以下用法:
- 如果 obj1.compareTo(obj2) 返回一个负数,则 obj1 在逻辑上小于 obj2。
- 如果 obj1.compareTo(obj2) 返回正数,则 obj1 在逻辑上大于 obj2
- 如果 obj1.compareTo(obj2) 返回零,则 obj1 等于 obj2。
正如我们所讨论的,TreeMap基于红黑树工作。
红黑树
红黑树是一种自平衡二叉搜索树,其中每个节点都有一个额外的位,该位通常被解释为红色或黑色。这些颜色用于确保树在插入和删除过程中保持平衡。虽然树的平衡并不完美,但它足以减少搜索时间并将其保持在 O(log n) 时间左右,其中 n 是树中元素的总数。必须注意的是,由于每个节点只需要 1 位空间来存储颜色信息,因此这些类型的树显示出与传统(无色)二叉搜索树相同的内存占用。
在本文中,我不打算详细解释红黑算法,让我们看看红黑算法的伪代码,以便理解内部实现,如下所示:
- 正如算法的名称所暗示的那样,树中每个节点的颜色要么是红色,要么是黑色。
- 根节点必须为黑色。
- 红色节点不能有红色邻居节点。
- 从根节点到 null 的所有路径都应包含相同数量的黑色节点。
- 所有的叶子都是黑色的。

Java 中TreeMap的内部工作原理
现在,我们将讨论一个示例,看看TreeMap在内部是如何工作的。
/**
*
*/
package com.jack.map;
import java.util.Map;
import java.util.TreeMap;
/**
* @author Jack.Yang
*
*/
public class TreeMapTest {
/**
* @param args
*/
public static void main(String[] args) {
Map<Key, String> treemap = new TreeMap<>();
treemap.put(new Key("H"), "中国");
treemap.put(new Key("D"), "广东");
treemap.put(new Key("B"), "深圳");
treemap.put(new Key("F"), "广州"); treemap.put(new Key("P"), "北京");} }让我们一步一步地了解。
第 1 步:最初,当我们创建一个TreeMap 对象时
Map<Key, String> treemap = new TreeMap<>();里面没有元素。让我们在其上添加第一个元素。
步骤 2:将第一个元素添加到TreeMap
treemap.put("H", "中国");在上面的代码中,“H”是键,“中国”是值。此数据将成为TreeMap的根节点,其余数据将附加到该节点,具体取决于其键的值是小于还是大于根。
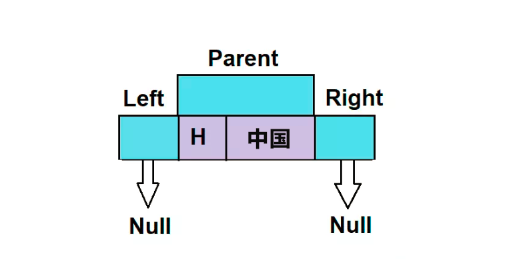
步骤 3:将第二个元素添加到TreeMap
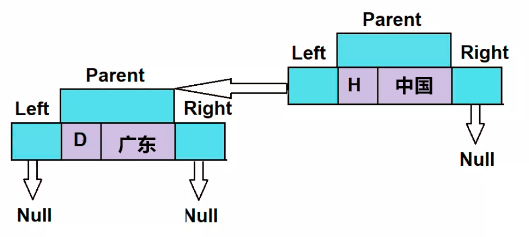
treemap.put("D", "广东");现在,“D”在逻辑上小于“H”,因此根据我们的规则,
- “广东” 将放置在 “中国” 的左侧。
- “中国”将是 “广东” 的父级。
插入此元素后,TreeMap的结构将如下所示。
步骤 4:将第三个元素添加到TreeMap
就像前两个元素一样,我们将使用 put 方法在TreeMap中添加第三个元素,并将其键值与根的键值进行比较以确定其位置。如果它的键值大于根的值,那么它将位于其右侧,但如果它的值小于根的值,那么我们必须遵循与第一个元素相同的过程,将其视为根元素。
treemap.put("B", "深圳");
根据我们的规则,B 小于 D,这反过来又使其小于 H,因此它被放置在元素的左侧,键为“D”。这是因为在这种情况下,第一个元素被视为树的其余部分的根元素。
所以 “B” 为键,"深圳"为值插入此对象后,TreeMap的结构如下所示。
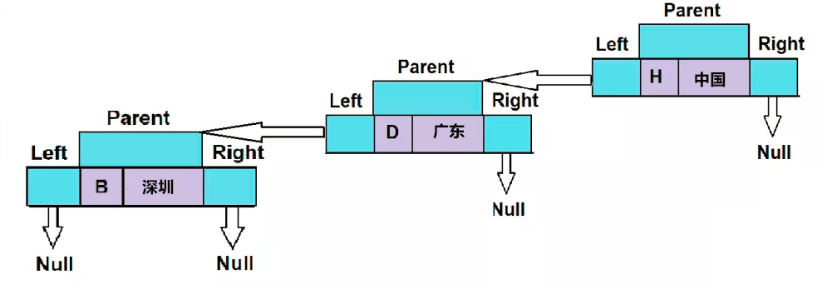
如上图所示,此元素 {“中国”} 是树的根节点。正如我们上面讨论的红黑树的属性和规则,红黑树实现将为我们提供从左到右的排序顺序。所以根据图,一棵树的元素变得如下。
- {“广东”} 将在 {“中国”} 的左侧
- {“深圳”} 将位于 {“广东”} 的左侧
步骤 5:将第四个元素添加到TreeMap
与前三个元素一样,我们在此TreeMap中添加第四个元素,只需检查其键值即可。
treemap.put("F", "广州");第四个元素的键值是“F”,它大于“D”但小于“H”。因此,它将放置在 H 的左侧,但位于 D 的右侧。添加此元素后,TreeMap的结构将如下所示。
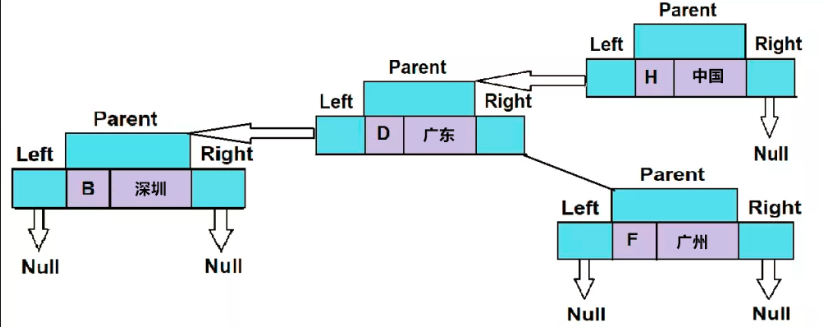
步骤 6:将第5个元素添加到TreeMap
treemap.put("P", "北京");同样,第五个元素将添加到根元素“H”的右侧,因为“P”按字母顺序大于“H”。添加此元素后,TreeMap的结构将如下所示。
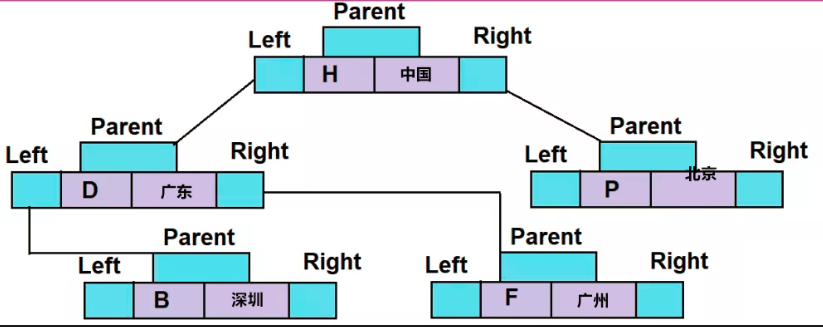
在TreeMap中插入所有元素后,它将看起来像这样子的:
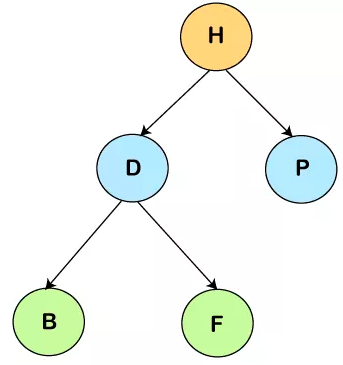
在本文中,我们了解到 TreeMap 和 HashMap 一样也是 map 接口的一部分,以键值对的形式存储数据,但以自平衡二叉搜索树的形式存储——红黑树。
它是不同步的,并且按照数字或字母的升序自然地对数据进行排序,具体取决于我们用于声明键的数据类型的类型,因为它根据其键对数据进行排序和存储。我们还可以在初始化TreeMap 时使用比较器进行一些自定义排序。就像其他排序的Map一样,TreeMap 还允许我们使用其内置方法执行一些操作,例如添加、删除、替换等。
由于其对数据进行排序的自然方式,这些操作的时间复杂度为 log n,这使得它在访问数据时速度方面比 HashMap 慢,但在大量存储方面,它比 HashMap 更易于扩展,因为 HashMap 以连续顺序存储数据(它将数据存储在数组中),而 TreeMap 将数据存储在自平衡二叉搜索树中,可以在其中存放大量数据,因为它只需要存储数据所需的空间量。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2008-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号