医图论文 ACM MM'24 | PASSION:用于不均衡缺失率下有效不完全多模态医学图像分割的方法

医图论文 ACM MM'24 | PASSION:用于不均衡缺失率下有效不完全多模态医学图像分割的方法

小白学视觉
发布于 2025-03-28 15:09:30
发布于 2025-03-28 15:09:30
论文信息
题目:PASSION: Towards Effective Incomplete Multi-Modal Medical Image Segmentation with Imbalanced Missing Rates
PASSION:用于不均衡缺失率下有效不完全多模态医学图像分割的方法
作者:Junjie Shi, Caozhi Shang, Zhaobin Sun, Li Yu, Xin Yang, Zengqiang Yan
源码:https://github.com/Jun-Jie-Shi/PASSION
论文创新点
- 提出新任务:首次提出并阐述了具有不均衡缺失率的不完全多模态医学图像分割这一更现实、更具挑战性的任务,打破以往研究中假设模态缺失率相同的局限,关注临床实际场景中模态缺失率的不均衡问题。
- 设计新方法:提出偏好感知自蒸馏(PASSION)方法,通过构建像素级和语义级自蒸馏,在统一框架中平衡各模态的优化目标;定义相对偏好评估模态主导地位,设计任务级和梯度级正则化,平衡不同模态的收敛速度。
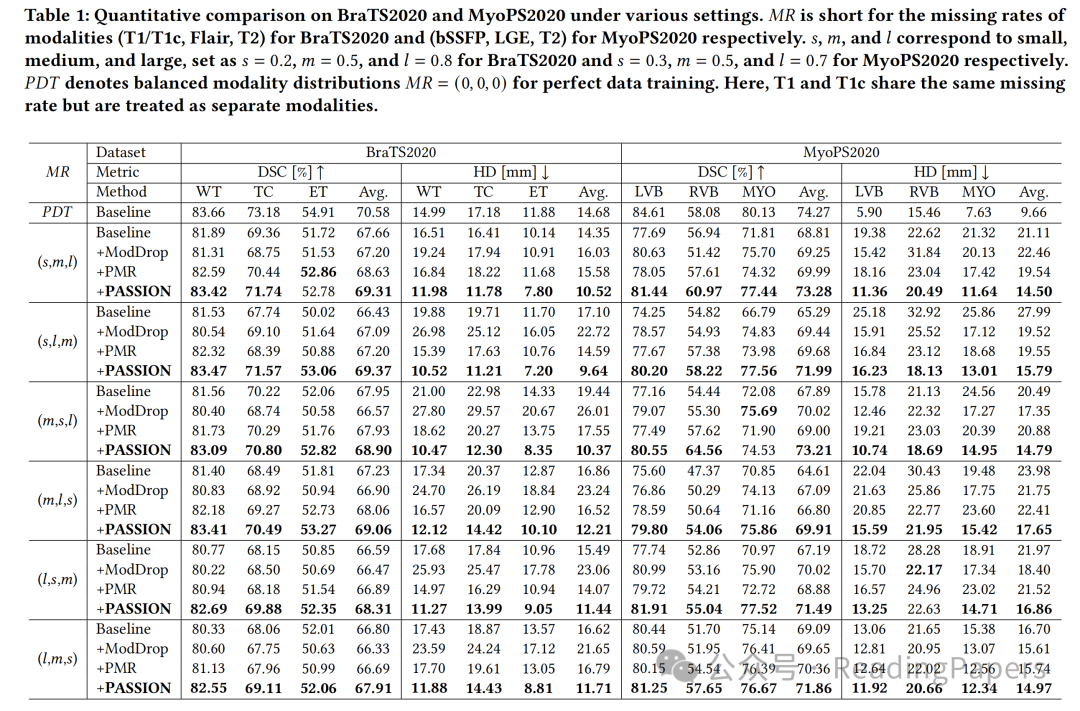
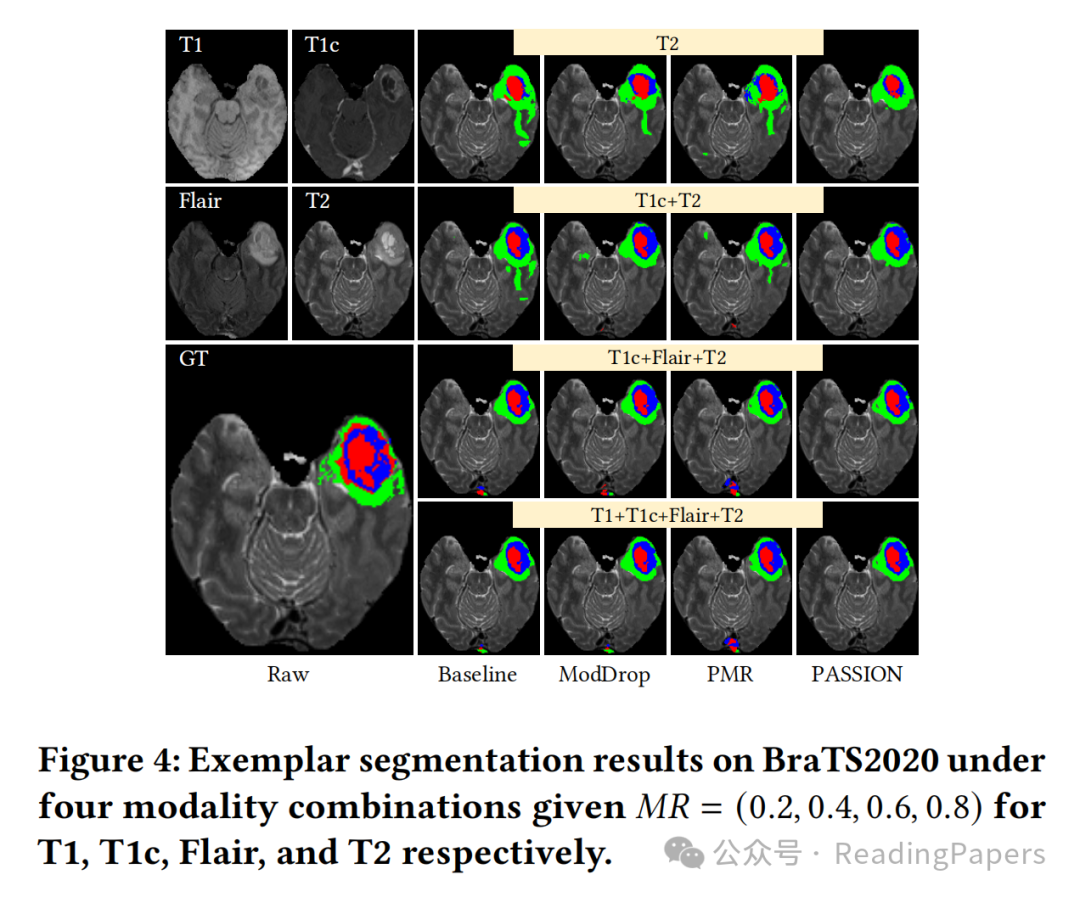
- 性能更优越:在BraTS2020和MyoPS2020两个公开多模态数据集上进行实验,结果表明PASSION在模态平衡方面优于现有方法,能有效减少分割时的误报,在不同模态组合下性能更稳定。
- 即插即用特性:PASSION可作为即插即用模块集成到不同骨干网络中。实验验证,在多种骨干网络上引入PASSION后,在各种模态缺失率下均能实现性能提升,甚至在部分任务上超过完美数据训练(PDT)的效果,证明其具有良好的鲁棒性和灵活性 。
摘要
不完全多模态图像分割是医学成像中的一项基础任务,旨在仅部分模态可用时提高部署效率。然而,模型训练期间能获取完整模态数据这一常见做法与现实相差甚远,因为在临床场景中,各模态的缺失率可能不均衡。在本文中,作者首次阐述了这一具有挑战性的场景,并提出了偏好感知自蒸馏(PASSION)方法,用于在不均衡缺失率下进行不完全多模态医学图像分割。具体而言,作者首先构建了像素级和语义级自蒸馏,以平衡各模态的优化目标。然后,定义相对偏好来评估训练过程中各模态的主导地位,并据此设计任务级和梯度级正则化,以平衡不同模态的收敛速度。在两个公开的多模态数据集上的实验结果表明,PASSION在模态平衡方面优于现有方法。更重要的是,PASSION被验证可作为即插即用模块,在不同骨干网络上持续提升性能。
3. 方法
3.1 问题定义

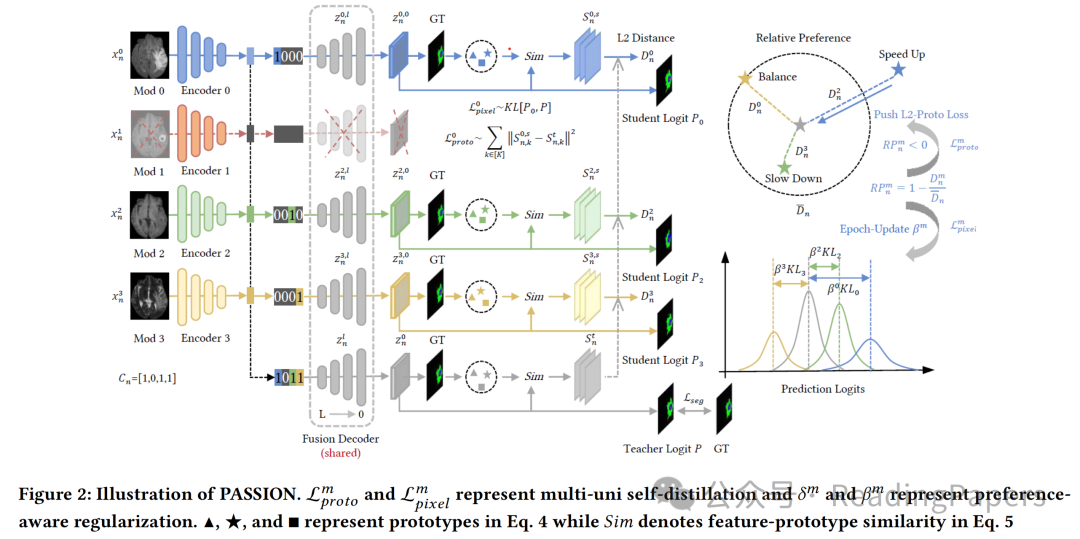
3.2 多-单自蒸馏
受知识蒸馏(KD)的启发,其旨在通过软标签将教师的 “暗知识” 转移给学生,作者将多模态知识视为每个可用单模态的共同目标,以平衡模态间的学习。由于多模态知识是通过所有模态学习得到的,它可能会被某些缺失率较低的模态主导。通过KD进行惩罚时,这些模态会因为更接近多模态知识(即软标签)而被较少强调。这样,就有望在IDT中重新平衡模态。与以往基于KD的工作不同,那些工作依赖于基于PDT的单独完整多模态教师模型,作者更倾向于使用统一网络将多模态知识转移到单模态,称为多-单自蒸馏。一方面,这降低了在IDT下训练一个足够强大的教师模型的难度;另一方面,在统一框架中,多模态知识对于单模态来说是固有的,但尚未得到充分利用。具体来说,多-单自蒸馏由以下描述的像素级和语义级自蒸馏组成。
像素级自蒸馏。由于分割可以被表述为一个像素级分类任务,作者提出对齐多模态和单模态之间每个像素的预测。通过实验验证发现,特征级对齐通常会导致多模态性能下降,而在深度监督中进行logit对齐对于不均衡学习是一个更稳健的选择。因此,每个单模态的像素级多-单自蒸馏公式为:
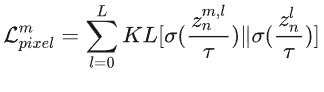
其中表示Kullback-Leibler散度,是温度超参数,是softmax函数,和分别表示样本第层的多模态和模态的特征。
语义级自蒸馏。通过从不同模态学习更多信息,多模态教师模型能够捕捉到更稳健的类内和类间表示。因此,不仅要将局部像素级知识,还要将全局类级知识转移到单模态。通过使用原型来表示一个类的通用特征,作者希望构建多模态和单模态原型,以实现全局知识转移。这里,每个样本的原型是单独计算的,因为在分割中每个样本包含足够的像素。

3.3 偏好感知正则化
如前所述,多-单自蒸馏将知识平等地转移到可用的单模态,以平衡模态间的学习。然而,这可能仍然会使那些缺失率较高的模态难以跟上其他模态。这是因为出现频率较高的单模态在优化过程中往往比其他模态更具优势。因此,在IDT中动态评估每个单模态相对于其他模态的强弱,并平衡它们的学习速度至关重要。

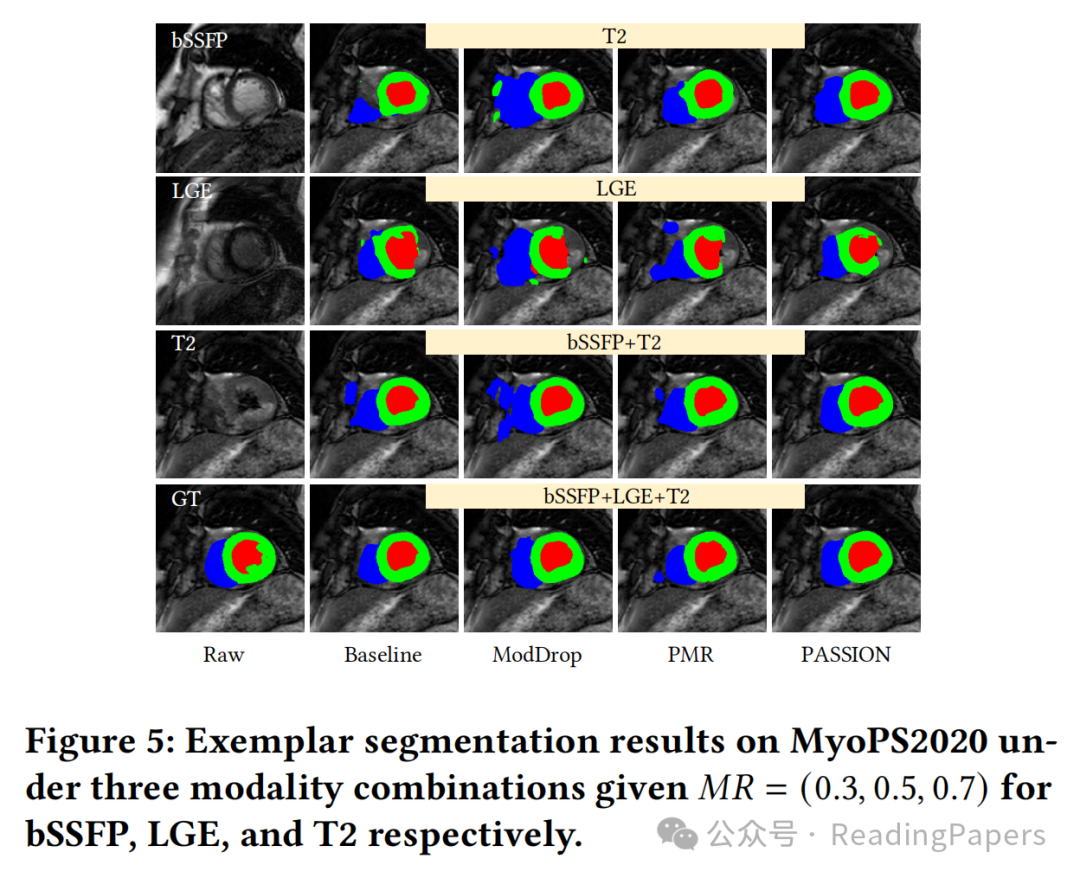
4. 实验
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与作者联系,作者将在第一时间回复并处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号