【Linux】深入理解进程和文件及内存管理

【Linux】深入理解进程和文件及内存管理

s-little-monster
发布于 2025-03-18 12:54:39
发布于 2025-03-18 12:54:39
一、重谈Linux下一切皆文件
这个图画完之后截下来不太清楚,有需要的可以到我的Gitee中取:点击这里取图片~
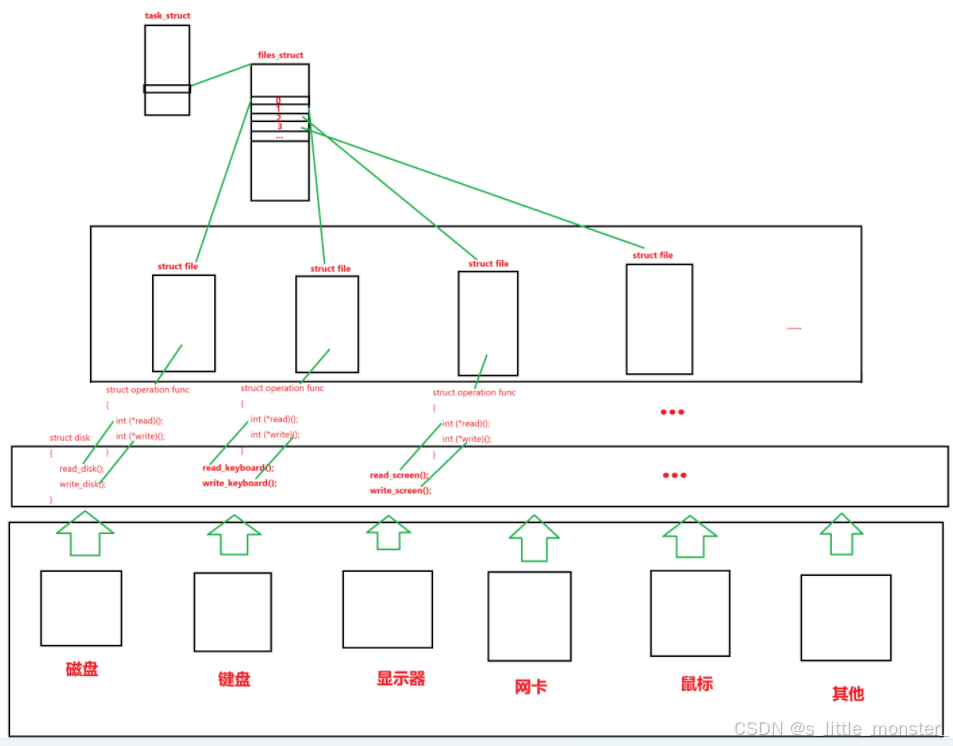
我们说了一切皆文件,对于操作系统来说,磁盘键盘显示屏等等一系列的外设都是文件,举一个访问外设的例子:进程运行,从进程PCB中找到指针指向文件管理结构体,然后在这个结构体中我们可以找到struct file*类型的指针指向一个个的文件管理结构体struct file,在这些结构体中都有着一个专门放读写函数的结构体,调用这些读写函数可以访问到外设存放读写函数的结构体,而虽然每个外设的读写方式不同,但它们仅把处理好的代码封装后将接口漏出,方便上方函数的统一调用,这样虽然每个外设不同,但是我们通过一种求同存异的方法,将它们统一协调调度起来 类似于键盘一类的只有读或者显示屏一类的只有写的外设,我们也有读或写的接口,只是接口不做处理,方便统一
二、操作系统对物理内存的管理
1、物理内存与磁盘的数据交互
在操作系统的运行机制里,物理内存和磁盘之间的数据交换起着关键作用,这种交换一般就是以页page为单位,常见的页大小为 4KB,在物理内存中,一个 4KB 大小的空间被称作页框,而从磁盘加载到这个页框里的4KB数据块则被叫做页
采用这种以页为单位进行数据交换的方式,具有显著的优势,一方面,能有效减少IO操作的次数,进而提升系统效率,举例来说,如果需要读取数据,一次读取 4KB 与分四次读取每次 1KB 相比,前者的效率要高得多,对于硬盘来说,一次读取 4KB 时,CPU 只需与磁盘进行一次交互,而分四次读取 1KB 时,CPU 要与磁盘进行四次交互,且这四次操作很可能不连续,这就意味着效率低下,另一方面,这种方式还遵循基于局部性原理的预加载机制,即便当前 CPU 仅需访问 100 字节的内容,操作系统和磁盘之间依旧会以 4KB 为单位将数据加载进来,这是因为根据经验,CPU 在访问当前磁盘中的代码和数据时,后续有较大概率会访问附近空间的代码和数据,还有一方面,就是对齐,磁盘中的最小写入单位是页,因为计算机硬件的设计往往遵循一定的对齐规则,这样可以提高数据访问的效率内存和磁盘控制器在设计时,通常会按照特定的字节边界来组织和传输数据,以页为单位进行数据交换可以保证数据在内存和磁盘之间的传输是按照硬件对齐要求进行的,减少硬件处理的复杂性
2、操作系统对物理内存的管理
操作系统具备感知物理内存的能力,其对物理内存的管理遵循先描述再组织的原则,在内核中,struct page 结构体承担着描述物理内存的重要职责,一个 struct page 对象对应着一个 4KB 的内存页框,该结构体中记录了当前页框的诸多属性信息,像页框的状态、引用计数等
操作系统会把物理内存划分成一个个的struct page对象,再用数组的形式将它们组织起来,数组的下标即为对应的页号,若要确定一个物理地址所在的页号,只需将该物理地址除以 4096 b(4KB = 4 * 1024 = 4096 b),或者将该地址按位与上 0xFFFFF000(以 32 位系统为例),把低 12 位清零,得到的结果就是该地址所在的页号
在进行内存申请操作时,系统会访问 page 数组,查看 struct page 里的 flags 属性,通过这个属性,系统能够判断当前页框的状态,确定其是否已被使用,若未被使用,系统就会修改 flags 以表明该页框已被申请,此外,flags 除了能表示页框的使用状态外,还能指示该页框是只读还是可读写等状态, 当然这里所介绍的只是操作系统对物理内存管理的一个基础模型,实际上真正的内存管理系统要复杂得多
三、文件页缓冲区
在操作系统内核中,struct file 是一个重要的数据结构,用于描述一个已打开的文件,而 inode 这一概念是在介绍磁盘时引入的,磁盘上的每个文件都对应着一个inode,它存储了该文件的属性信息,struct file 和 inode 之间存在着紧密的联系,struct file中仅记录了文件的少量属性,而struct inode结构体则专门用于记录一个文件的所有属性,在 struct file 中有一个指针字段,它指向该文件的struct inode对象
文件由内容和属性两部分构成,在磁盘上,文件的属性由 inode存储,文件的内容则由数据块存储,那么,在操作系统内核中,文件的内容(数据)是如何表示的呢?答案就是通过文件页缓冲区,
在 struct file 结构中有一个指向 struct address_space 结构体的指针,在 struct address_space 结构体中,有一个 struct radix_tree_root 结构体对象,它实际上是一种树状结构,即基数树(也叫字典树),树中的每个节点都是 struct radix_tree_node 类型,该类型中有一个名为 slots 的 void* 类型数组,数组中存储的其实就是 struct page 对象的地址,简单来说,在 struct file 结构体中有指向物理内存页框的指针,我们把这些物理内存区域称为文件页缓冲区
向文件写入数据的过程
当使用C/C++库函数向文件中写入数据时,整个过程分为几个阶段,首先,数据有可能会被写入到语言层面的用户缓冲区,然后,在合适的时机,这些数据会被从用户缓冲区写入到该文件对应的文件页缓冲区中,最后,还是在合适的时机,数据会从文件页缓冲区被写入到磁盘
将物理内存中的数据刷新到磁盘这一操作由IO子系统负责执行,进程通常无需关注具体的执行过程,在操作系统中,会存在大量的IO操作,可能有很多进程都需要将数据写入磁盘,为了有效管理这些操作,操作系统会按照先描述再组织的方式对所有的IO操作进行管理,内核中的struct request结构就是专门用来描述一个IO操作的
在Linux操作系统中,每个进程打开的每个文件都有自己的 struct inode 对象和对应的文件页缓冲区,也就是所谓的内核缓冲区,它们共同保障了文件操作的高效和稳定
四、动态库是如何被加载的
动态库在进程运行时要被加载到内存,一般我们常用的动态库是要被所有的可执行程序动态链接的,所以动态库在系统中加载完成后,会被所有的进程所共享
在操作系统的进程管理与库使用机制中,进程与动态库的交互有着独特的方式,一个进程在运行过程中,是可以同时链接多个动态库的,不过,当系统中存在多个进程时,不能简单地认为系统中必然存在多个不同的动态库,多个进程可能会依赖相同的动态库,操作系统对动态库采用“先描述,再组织”的策略进行管理,它会为每个动态库创建相应的数据结构来描述其属性、位置等信息,然后将这些描述信息组织起来,以便高效地进行查找、加载和管理,凭借这种管理方式,操作系统对系统中所有动态库的加载状态了如指掌
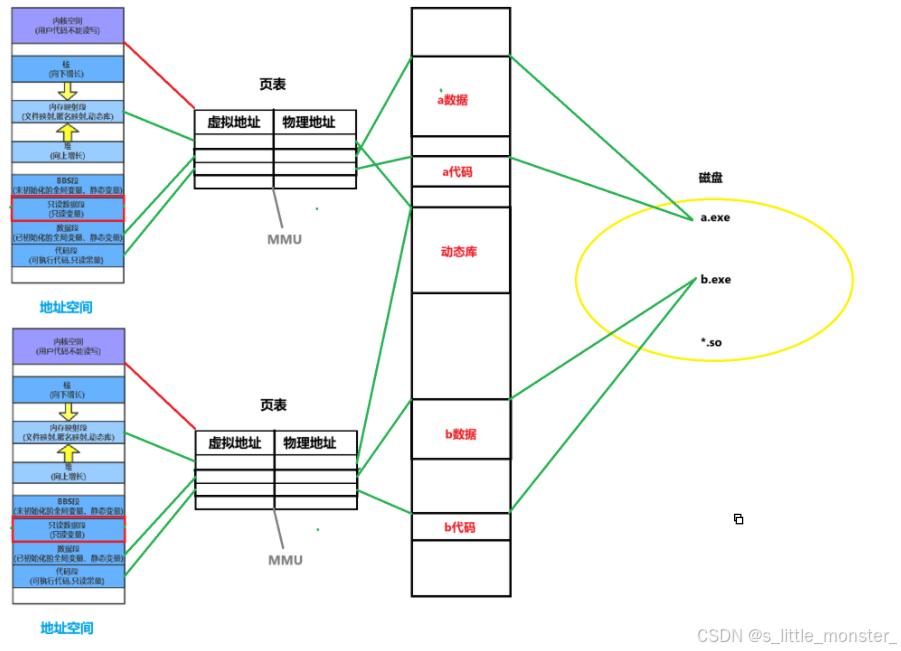
以 a.exe 为例,它在编译链接阶段选择使用动态库,当 a.exe 运行成为 a 进程后,CPU 会按照程序的指令顺序依次执行代码,假设在执行过程中遇到了一个库函数调用,此时,操作系统会检查该函数所在的动态库是否已经被加载到内存中,若尚未加载,操作系统会负责将该动态库加载到内存,这一加载过程本质上与文件加载一致,因为动态库本身也是以文件形式存在的,并且具有 inode 来标识其在文件系统中的元数据
动态库加载完成后,操作系统会在 a 进程的页表中建立该动态库与 a 进程地址空间中共享区的映射关系,这样,当 CPU 需要执行上述函数时,就可以从代码段跳转到共享区去执行动态库中该函数的代码,执行完毕后,CPU 会跳转回代码段,继续执行后续的程序指令
b.exe 同样在编译链接时采用动态库,之后被加载到内存成为 b 进程,当 CPU 执行 b 进程的代码并遇到上面函数调用时,因为在 a 进程已经将该所在的动态库加载到了内存,操作系统不会再次重复加载该动态库,而是直接在 b 进程的页表中建立该动态库与 b 进程共享区的映射关系,通过这种方式,同一个动态库可以被多个进程共享使用,所以动态库又被称为共享库
关于动态库中的全局变量
动态库确实可以被多个进程共享,但对于动态库中的全局变量(例如 errno),需要特殊的处理机制来保证各个进程之间的数据独立性,errno 是 C 语言标准库提供的一个全局变量,用于存储最近一次库函数调用失败时的错误码
如果简单地让所有进程共享 errno,会引发严重的问题,例如,当 a 进程调用库函数失败,errno 被设置为 1,此时如果 b 进程也使用这个共享的 errno,就会导致 b 进程错误地获取到 a 进程的错误码,这显然不符合逻辑
实际上,操作系统采用了写时拷贝技术来解决这个问题,当某个进程要修改 errno 时,操作系统会通过引用计数来判断该动态库是否被多个进程共享,如果该动态库被多个进程共享,操作系统会为该进程复制一份动态库中相关数据(包括 errno)的副本,而不是直接修改共享的数据,这样,每个进程都有自己独立的 errno 副本,从而保证了各个进程之间的错误码不会相互干扰,只有当进程对数据进行写操作时才会发生拷贝,而在只读的情况下,多个进程仍然可以共享同一份动态库数据,从而充分发挥了动态库共享的优势
五、深入理解地址
1、程序地址
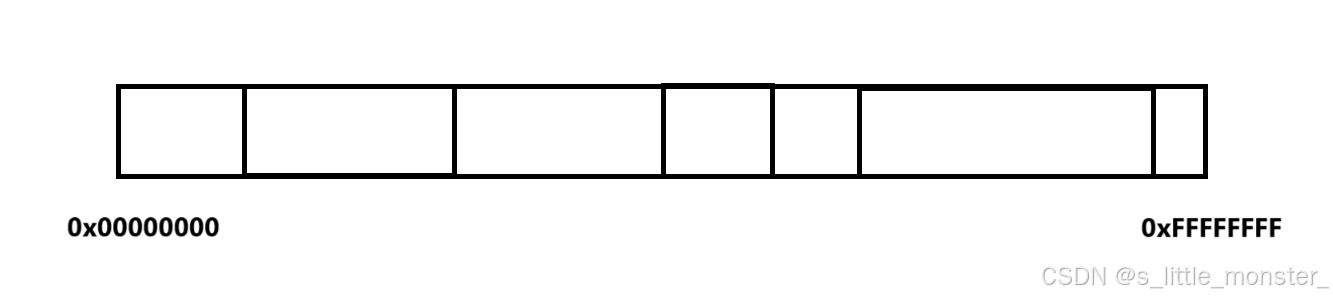
在一个程序编译好后形成了可执行文件,在它的内部是有地址的概念的,这里程序内部的地址我们称为逻辑地址,我们计算机一般采用的是平坦模式编址,平坦模式编址是一种简化的内存编址模型,在这种模式下,整个内存空间被视为一个连续的、线性的地址空间,程序可以直接访问这个连续地址空间内的任意内存位置,而不需要像分段模式那样进行复杂的段地址和偏移地址组合计算,在平坦模式中,内存地址是一个单一的、连续的数值,从 0 开始一直到系统所支持的最大内存地址
32位下的4GB内存地址
2、进程地址
我们知道,可执行程序内部采用的是逻辑地址(也叫虚拟地址)进行编址,物理内存本身有其固定的物理地址,无论可执行程序是否加载,物理内存的地址体系是一直存在的,当可执行程序被加载到内存后,程序中的每一条指令和数据都会对应一个物理地址,这是通过地址映射机制实现的
那么,CPU 是如何知道可执行程序的第一条指令位置呢?在编译生成可执行程序时,除了生成代码段、数据段等程序内容外,还会生成一个文件头,这个文件头包含了诸多重要信息,其中就有可执行程序的入口地址,此地址是逻辑地址(虚拟地址)
在 CPU 中有一个关键的寄存器,即程序计数器—PC 寄存器,它存储着接下来要执行指令的地址,实际上,在程序启动阶段,不会立刻把整个可执行程序加载到内存(可以想象我们打游戏的时候不是打开游戏就能玩的,需要等待加载)而是先将可执行文件的头部加载进来,操作系统读取文件头,从中获取可执行程序的入口地址,并将该地址设置到 PC 寄存器中
CPU 拿到这个虚拟地址后,会借助内存管理单元去查询页表,页表记录了虚拟地址和物理地址的映射关系,若查询发现该虚拟地址对应的页表项无效,也就是此页面尚未建立内存映射,操作系统会触发缺页中断,缺页中断发生后,操作系统暂停当前程序的执行,从磁盘把对应的程序页面加载到物理内存的空闲页框中,同时更新页表,建立起虚拟地址到物理地址的映射,之后,恢复程序执行,CPU 就能访问到物理内存中对应的指令了
CPU 凭借其内置的指令集,能够明确识别每条指令的长度,在正常运行状态下,CPU 按照 PC 寄存器所存储的地址顺序执行指令,每执行完一条指令,PC 寄存器会自动更新为下一条指令的地址,当程序执行过程中遇到函数调用指令或跳转指令时,PC 寄存器的值会被修改为新的虚拟地址,CPU 会依据这个新的虚拟地址再次查询页表,若发现页面未在内存中,将再次触发缺页中断
由此可见,CPU 正是通过将虚拟地址转换为物理地址的方式,来执行可执行程序中的指令以及访问可执行程序中的变量的,这种基于虚拟内存和地址映射的机制,为程序提供了独立的地址空间,增强了内存管理的灵活性和安全性
3、动态库地址
在计算机系统的程序执行机制中,可执行程序内部采用逻辑地址进行编址,CPU通过将虚拟地址转换为物理地址的方式来执行指令
静态库在编译链接过程中会被整合到可执行文件中,当可执行程序启动运行时,操作系统会将包含静态库代码的可执行文件加载到物理内存,之后 CPU 方可执行其中的指令,静态库中的函数采用绝对编址,这是因为它们已成为可执行文件的组成部分,其地址在编译链接阶段就已经确定下来
在可执行程序的编译阶段,对动态库内函数的引用表现为未解析的符号,当程序进入运行状态时,动态链接器承担起解析这些符号的任务,由于动态库在运行时能够被加载到虚拟内存共享区的任意位置,要将动态库加载到固定位置存在较大困难,这是由于一个可执行程序往往会同时使用多个动态库,各个动态库的大小不尽相同,并且每个动态库都采用独立的编址方式,不同动态库中可能出现相同的编址情况,为了实现动态库在虚拟内存共享区任意位置的加载,动态库内部采用相对编址的方法,对于动态库中的函数,仅需明确其在库中的偏移量即可,鉴于库中函数的偏移量是已知的(在编译动态库时,编译器会按照一定的规则对库中的代码和数据进行布局,编译器知道每个函数在代码段中的起始位置以及函数内部代码的长度),动态库便能够被加载到虚拟内存共享区的任意位置
在此机制下,操作系统只需记录每个动态库在虚拟内存中的起始地址,当需要执行某个动态库函数时,通过将该函数所在动态库的起始地址与该函数的偏移量相加,即可得到该函数在程序地址空间中的虚拟地址,随后,依据此虚拟地址查询页表,找到该函数在物理内存中的对应地址,进而执行该库函数,GCC 编译器中的 -fPIC 选项,其作用就是让编译器在生成动态库文件时,直接使用偏移量对库中的函数进行编址,从而实现代码的位置无关性
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号