YOLOv11改进目录一览 | 涉及卷积层、轻量化、注意力、损失函数、Backbone、SPPF、Neck、检测头等全方位改进
原创
YOLOv11改进目录一览 | 涉及卷积层、轻量化、注意力、损失函数、Backbone、SPPF、Neck、检测头等全方位改进
原创
Limiiiing
修改于 2025-03-11 15:42:13
修改于 2025-03-11 15:42:13
YOLOv11改进目录一览 | 涉及卷积层、轻量化、注意力、损失函数、Backbone、SPPF、Neck、检测头等全方位改进
YOLOv11的模型配置文件在ultralytics/cfg/models/11中,里面包含目标检测、实例分割、图像分类、关键点/姿态估计以及旋转目标检测,本文以目标检测模型文件为例(其他文件完全一致),详细介绍一下YOLOv11模型文件中各参数的含义。
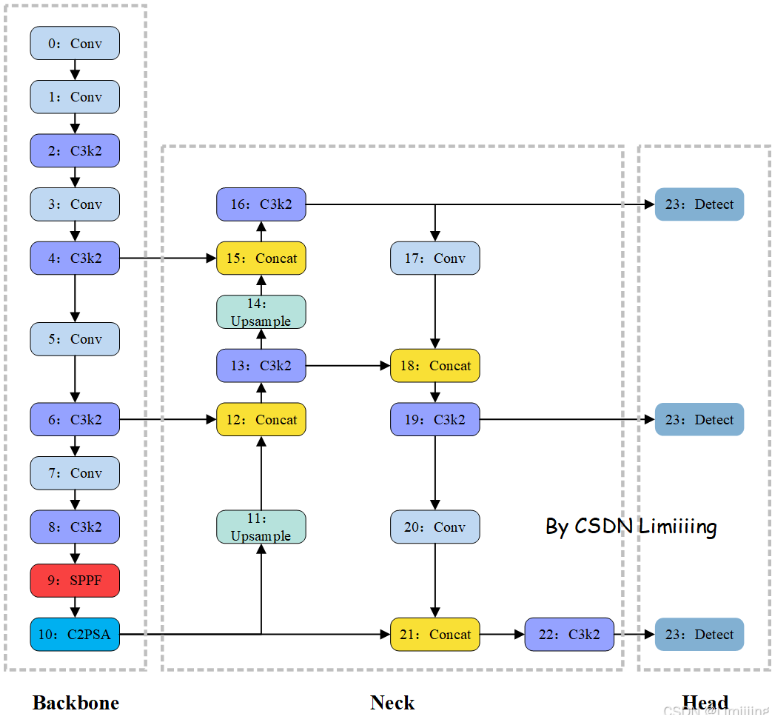
YOLOv11的目标检测文件yolo11.yaml中的内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)以下是对给定 YOLOv11 模型 YAML 文件的详细解释:
# Ultralytics YOLO 🚀, AGPL-3.0 license:这是一个注释,表明该模型是由 Ultralytics 开发的,遵循 AGPL-3.0 许可证。- YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect:注释说明这是使用
P3到P5的输出层 目标检测 的YOLOv11模型,并提供了使用示例的链接。 nc: 80:表示模型要检测的类别数量为 80。此处需要根据自己的数据集中的目标种类进行修改。scales:这部分定义了不同规模的模型参数。n: [0.50, 0.25, 1024]:代表YOLOv11n模型的参数。第一个值 0.50 表示深度系数,第二个值 0.25 表示宽度系数,第三个值 1024 表示最大通道数。同时在后面的注释中给出了该模型的一些统计信息,如层数、参数数量、梯度数量和计算量(GFLOPs)。s: [0.50, 0.50, 1024]等其他规模的模型也类似解释。
在模型调用时,只需将文件名命名为yolov11n,即可调用n模型。调用其他模型只需要修改命名即可
backbone:定义了模型的骨干网络。[from, repeats, module, args]:这是每个网络层的定义格式。from表示输入来自哪一层,repeats表示该模块重复的次数,module表示模块名称,args表示模块的参数。- [-1, 1, Conv, [64, 3, 2]]:表示输入来自上一层(-1),该卷积层(Conv)重复一次,参数为输入通道数 64、卷积核大小 3、步长为 2,参数来自Conv模块的定义。后面的注释0-P1/2分表表示第0层,P1特征图,2倍下采样。
- 其他层的解释类似,如
C3k2是新提出的模块,SPPF是空间金字塔池化快速(Spatial Pyramid Pooling - Fast)模块。 head:定义了模型的头部结构。- [-1, 1, nn.Upsample, [None, 2, "nearest"]]:表示使用最近邻插值上采样,参数分别为输入张量(None表示根据输入自动确定)、上采样因子 2 和插值方法为“nearest”。[[-1, 6], 1, Concat, [1]]:表示将当前层(-1)和第 6 层进行拼接(Concat),参数1表示在通道维度上进行拼接。- 后面的
C3k2、Conv和Detect等模块也类似解释,Detect模块最后接收类别数量nc,表示进行目标检测操作,接收P3、P4、P5三个不同尺度的特征图进行检测。
结构图的绘制主要通过模块所在的层数和层于层之间的连接而来。
YOLOv11模型结构🌟
YOLOv11改进目录一览(持续更新中ing📃)
🎓— 基础篇— 🎓
1、目标检测:YOLOv11训练自己的数据集(从代码下载到实例测试)
2、语义分割:YOLOv11的分割模型训练自己的数据集(从代码下载到实例测试)
3、使用AutoDL训练YOLO等计算机视觉网络模型(AutoDL+Xftp+VS Code),附详细操作步骤
4、YOLOv11目标检测模型性能评价指标详解,涉及混淆矩阵、F1-Score、IoU、mAP、参数量、计算量等,一文打尽所有评价指标
5、YOLOv11改进前必看 - YAML模型配置文件详细解读(再也不用担心通道数不匹配) 附网络结构图🌟
6、YOLOv11模型应用过程中的报错处理及疑问解答,涉及环境搭建、模型训练、模块改进、论文写作🌟
7、YOLOv11训练前的准备,将数据集划分成训练集、测试集验证集(附完整脚本及使用说明)🌟
8、YOLOv11改进入门篇 | 手把手讲解改进模块如何实现高效涨点,以SimAM注意力模块为例🌟
🎓论文写作 — 丰富工作量🎓
1、论文必备 - YOLOv11统计数据集中大、中、小目标数量,附完整代码和详细使用步骤🌟
2、论文必备 - 绘制YOLOv11模型在训练过程中,精准率,召回率,mAP_0.5,mAP_0.5:0.95,以及各种损失的变化曲线
3、论文必备 - YOLOv11输出模型每一层的耗时和GFLOPs,深入比较每一层模块的改进效果🌟
4、论文必备 - YOLOv11热力图可视化,支持指定模型,指定显示层,设置置信度,以及10种可视化实现方式🌟
5、论文必备 - YOLOv11训练前一键扩充数据集,支持9种扩充方法,支持图像和标签同步扩充🌟
6、论文必备 - YOLOv11计算COCO指标和TIDE指标,小目标检测必备,更全面的评估和指导模型性能,包含完整步骤和代码🌟
📈卷积层 — 发文常客📈
1、YOLOv11改进策略【卷积层】| CVPR-2023 部分卷积 PConv 轻量化卷积,降低内存占用
2、YOLOv11改进策略【卷积层】| CVPR-2024 PKI Module 获取多尺度纹理特征,适应尺度变化大的目标🌟
3、YOLOv11改进策略【卷积层】| CVPR-2023 SCConv 空间和通道重建卷积:即插即用,减少冗余计算并提升特征学习
4、YOLOv11改进策略【卷积层】| CGblock 内容引导网络 利用不同层次信息,提高多类别分类能力 (含二次创新)🌟
5、YOLOv11改进策略【卷积层】| ICCV-2023 LSK大核选择模块 包含二次独家创新🌟
6、YOLOv11改进策略【卷积层】| 利用MobileNetv4中的UIB、ExtraDW优化C3k2🌟
7、YOLOv11改进策略【卷积层】| ICCV-2023 引入Dynamic Snake Convolution动态蛇形卷积,改进C3k2🌟
8、YOLOv11改进策略【卷积层】| GnConv:一种通过门控卷积和递归设计来实现高效、可扩展、平移等变的高阶空间交互操作
9、YOLOv11改进策略【卷积层】| HWD,引入Haar小波变换到下采样模块中,减少信息丢失🌟
10、YOLOv11改进策略【卷积层】| SAConv 可切换的空洞卷积 二次创新C3k2
11、YOLOv11改进策略【卷积层】| ICCV-2023 SAFM 空间自适应特征调制模块 对C3k2进行二次创新🌟
12、YOLOv11改进策略【卷积层】| AKConv: 具有任意采样形状和任意参数数量的卷积核
13、YOLOv11改进策略【卷积层】| NeurIPS-2022 ParNet 即插即用模块 二次创新C3k2
14、YOLOv11改进策略【卷积层】| CVPR-2024 利用DynamicConv 动态卷积 结合C3k2进行二次创新,提高精度🌟
15、YOLOv11改进策略【卷积层】| 2023 引入注意力卷积模块RFAConv,关注感受野空间特征 助力yolov11精度提升🌟
16、YOLOv11改进策略【卷积层】| SPD-Conv 针对小目标和低分辨率图像的检测任务🌟
17、YOLOv11改进策略【卷积层】| 2023 RCS-OSA 通道混洗的重参数化卷积 二次创新C3k2🌟
18、YOLOv11改进策略【卷积层】| CVPR-2021 多样分支块DBB,替换传统下采样Conv 含二次创新C3k2
19、YOLOv11改进策略【卷积层】| ECCV-2024 小波卷积 增大感受野,降低参数量计算量,独家创新助力涨点🌟
20、YOLOv11改进策略【卷积层】| 2024最新轻量级自适应提取模块 LAE 即插即用 保留局部信息和全局信息🌟
21、YOLOv11改进策略【卷积层】| CVPR-2020 Strip Pooling 空间池化模块 处理不规则形状的对象 含二次创新
🍀Backbone/主干网络🍀
1、YOLOv11改进策略【Backbone/主干网络】| 2023 U-Net V2 替换骨干网络,加强细节特征的提取和融合🌟
2、YOLOv11改进策略【Backbone/主干网络】| 替换骨干网络为:Swin Transformer,提高多尺度特征提取能力
3、YOLOv11改进策略【Backbone/主干网络】| ICLR-2023 替换骨干网络为:RevCol 一种新型神经网络设计范式🌟
4、YOLOv11改进策略【Backbone/主干网络】| 2023-CVPR 替换骨干网络为 LSKNet (附网络详解和完整配置步骤)🌟
5、YOLOv11改进策略【Backbone/主干网络】| 2023-CVPR 替换骨干网络为 ConvNeXt V2 (附网络详解和完整配置步骤)🌟
6、YOLOv11改进策略【Backbone/主干网络】| CVPR-2024 替换骨干网络为 PKINet 获取多尺度纹理特征,适应尺度变化大的目标🌟
7、YOLOv11改进策略【Backbone/主干网络】| CVPR 2024 替换骨干网络为 RMT,增强空间信息的感知能力🌟
8、YOLOv11改进策略【Backbone/主干网络】| CVPR 2024 替换骨干网络为 UniRepLKNet,解决大核 ConvNets 难题🌟
🔥Conv和Transformer — 发文热点🔥
1、YOLOv11改进策略【Conv和Transformer】| CVPR-2023 BiFormer 稀疏自注意力,减少内存占用🌟
2、YOLOv11改进策略【Conv和Transformer】| 2024 AssemFormer 结合卷积与 Transformer 优势,弥补传统方法不足🌟
3、YOLOv11改进策略【Conv和Transformer】| CVPR-2021 Bottleneck Transformers 简单且高效的自注意力模块
4、YOLOv11改进策略【Conv和Transformer】| TPAMI-2024 Conv2Former 利用卷积调制和大核卷积简化自注意力机制🌟
5、YOLOv11改进策略【Conv和Transformer】| CVPR-2024 Single-Head Self-Attention 单头自注意力🌟
6、YOLOv11改进策略【Conv和Transformer】| ACmix 卷积和自注意力的结合,充分发挥两者优势
7、YOLOv11改进策略【Conv和Transformer】| 上下文转换器CoT 结合静态和动态上下文信息的注意力机制 (含二次创新C3k2)
8、YOLOv11改进策略【Conv和Transformer】| GRSL-2024 最新模块 卷积和自注意力融合模块 CAFM 减少图像中的噪声干扰🌟
9、YOLOv11改进策略【Conv和Transformer】| 2023 引入CloFormer中的双分支结构,融合高频低频信息(二次创新C2PSA)🌟
10、YOLOv11改进策略【Conv和Transformer】| CVPR-2022 Deformable Attention Transformer 可变形注意力 动态关注目标区域🌟
11、YOLOv11改进策略【Conv和Transformer】| ICCV-2023 iRMB 倒置残差移动块 轻量化的注意力模块
12、YOLOv11改进策略【Conv和Transformer】| ECCV-2024 Histogram Transformer 直方图自注意力 适用于噪声大,图像质量低的检测任务🌟
🔥YOLO和Mamba — 最新热点🔥
1、YOLOv11改进策略【YOLO和Mamba】| MLLA:Mamba-Like Linear Attention,融合Mamba设计优势的注意力机制🌟
2、YOLOv11改进策略【YOLO和Mamba】| 替换骨干 Mamba-YOLOv11-T !!! 最新的发文热点🌟
3、YOLOv11改进策略【YOLO和Mamba】| 替换骨干 Mamba-YOLOv11-B !!! 最新的发文热点🌟
4、YOLOv11改进策略【YOLO和Mamba】| 替换骨干 Mamba-YOLOv11-L !!! 最新的发文热点🌟
5、YOLOv11改进策略【YOLO和Mamba】| 2024 VM-UNet,高效的特征提取模块VSS block 二次创新提高精度🌟
🍀模型轻量化 — 加速推理🍀
1、YOLOv11改进策略【模型轻量化】| MoblieNet V4:2024 轻量化网络 移动生态系统的通用模型🌟
2、YOLOv11改进策略【模型轻量化】| MoblieNet V3:基于搜索技术和新颖架构设计的轻量型网络模型🌟
3、YOLOv11改进策略【模型轻量化】| ShuffleNet V1:一个用于移动设备的极其高效的卷积神经网络
4、YOLOv11改进策略【模型轻量化】| Shufflenet V2:通过通道划分构建高效网络,高效的CNN架构设计的实用指南🌟
5、YOLOv11改进策略【模型轻量化】| MoblieOne:改进的1毫秒移动主干网,引入结构重参数化,提高模型检测效率🌟
6、YOLOv11改进策略【模型轻量化】| MobileViT V1:高效的信息编码与融合模块,获取局部和全局信息
7、YOLOv11改进策略【模型轻量化】| GhostNet V1:基于 Ghost Module 和 Ghost Bottlenecks的轻量化网络结构
8、YOLOv11改进策略【模型轻量化】| GhostNet V2:NeurIPS-2022 Spotlight 利用远距离注意力增强廉价操作🌟
9、YOLOv11改进策略【模型轻量化】| RepViT:CVPR-2024 轻量级的Vision Transformers架构🌟
10、YOLOv11改进策略【模型轻量化】| FasterNet: CVPR-2023 高效快速的部分卷积块🌟
11、YOLOv11改进策略【模型轻量化】| VanillaNet:华为的极简主义骨干网络🌟
12、YOLOv11改进策略【模型轻量化】| EfficientViT:ICCV 2023 用于高分辨率密集预测的多尺度线性关注🌟
13、YOLOv11改进策略【模型轻量化】| StarNet:CVPR-2024 超级精简高效的轻量化模块🌟
14、YOLOv11改进策略【模型轻量化】| PP-LCNet:轻量级的CPU卷积神经网络
15、YOLOv11改进策略【模型轻量化】| EfficientNet v1 :高效的移动倒置瓶颈结构🌟
16、YOLOv11改进策略【模型轻量化】| EfficientNet v2:加速训练,快速收敛🌟
17、YOLOv11改进策略【模型轻量化】| MoblieNetV1:用于移动视觉应用的高效卷积神经网络🌟
18、YOLOv11改进策略【模型轻量化】| MoblieNetV2:线性瓶颈,倒置残差,含模型详解和完整配置步骤🌟
19、YOLOv11改进策略【模型轻量化】| 替换骨干网络为 GhostNet V3 2024华为的重参数轻量化模型🌟
20、YOLOv11改进策略【模型轻量化】| EMO:ICCV 2023,结构简洁的轻量化自注意力模型🌟
📈注意力机制篇 — 发文必备📈
1、YOLOv11改进策略【注意力机制篇】| 2024 PPA 并行补丁感知注意模块,提高小目标关注度🌟
2、YOLOv11改进策略【注意力机制篇】| 添加SE、CBAM、ECA、CA、Swin Transformer等注意力和多头注意力机制
3、YOLOv11改进策略【注意力机制篇】| ICML-2021 引入SimAM注意力模块(一个简单的,无参数的卷积神经网络注意模块)
4、YOLOv11改进策略【注意力机制篇】| GAM全局注意力机制: 保留信息以增强通道与空间的相互作用
5、YOLOv11改进策略【注意力机制篇】| 2023 MCAttention 多尺度交叉轴注意力 获取多尺度特征和全局上下文信息🌟
6、YOLOv11改进策略【注意力机制篇】| 2024 SCSA-CBAM 空间和通道的协同注意模块 二次创新C3k2🌟
7、YOLOv11改进策略【注意力机制篇】| 2024 SCI TOP FCAttention 即插即用注意力模块,增强局部和全局特征信息交互🌟
8、YOLOv11改进策略【注意力机制篇】| EMA 即插即用模块,提高远距离建模依赖
9、YOLOv11改进策略【注意力机制篇】| NAM 即插即用模块,重新优化通道和空间注意力
10、YOLOv11改进策略【注意力机制篇】| 2024 蒙特卡罗注意力(MCAttn)模块,提高小目标的关注度🌟
11、YOLOv11改进策略【注意力机制篇】| CVPR2024 CAA上下文锚点注意力机制🌟
12、YOLOv11改进策略【注意力机制篇】| 引入Shuffle Attention注意力模块,增强特征图的语义表示
13、YOLOv11改进策略【注意力机制篇】| Mixed Local Channel Attention (MLCA) 融合通道、空间、局部和全局信息的新型注意力
14、YOLOv11改进策略【注意力机制篇】| ICLR2023 高效计算与全局局部信息融合的 Sea_Attention 模块(含C2PSA二次创新🌟)
15、YOLOv11改进策略【注意力机制篇】| ICCV2023 聚焦线性注意力模块 Focused Linear Attention 聚焦能力与特征多样性双重提升🌟
16、YOLOv11改进策略【注意力机制篇】| WACV-2021 Triplet Attention 三重注意力模块 - 跨维度交互注意力机制优化
17、YOLOv11改进策略【注意力机制篇】| SENet V2 优化SE注意力机制,聚合通道和全局信息🌟
18、YOLOv11改进策略【注意力机制篇】| CVPRW-2024 分层互补注意力混合层 H-RAMi 针对低质量图像的特征提取模块🌟
19、YOLOv11改进策略【注意力机制篇】| CVPR-2023 FSAS 基于频域的自注意力求解器 结合频域计算和卷积操作 降低噪声影响🌟
20、YOLOv11改进策略【注意力机制篇】| Large Separable Kernel Attention (LSKA) 大核可分离卷积注意力 二次创新C2PSA、C3k2🌟
21、YOLOv11改进策略【注意力机制篇】| WACV-2024 D-LKA 可变形的大核注意 针对大尺度、不规则的目标图像🌟
22、YOLOv11改进策略【注意力机制篇】| 引入MobileNetv4中的Mobile MQA,轻量化注意力模块 提高模型效率🌟
🚀损失函数篇🚀
1、YOLOv11改进策略【损失函数篇】| 利用MPDIoU,加强边界框回归的准确性
2、YOLOv11改进策略【损失函数篇】| Slide Loss,解决简单样本和困难样本之间的不平衡问题🌟
3、YOLOv11改进策略【损失函数篇】| 替换激活函数为Mish、PReLU、Hardswish、LeakyReLU、ReLU6
5、YOLOv11改进策略【损失函数篇】| Shape-IoU:考虑边界框形状和尺度的更精确度量🌟
6、YOLOv11改进策略【损失函数篇】| 2024 引进Focaler-IoU损失函数 加强边界框回归🌟
7、YOLOv11改进策略【损失函数篇】| NWD损失函数,提高小目标检测精度🌟
8、YOLOv11改进策略【损失函数篇】| 引入Soft-NMS,提升密集遮挡场景检测精度,包括GIoU-NMS、DIoU-NMS、CIoU-NMS、SIoU-NMS、 EIou-NMS
9、YOLOv11改进策略【损失函数篇】| 将激活函数替换为带有注意力机制的激活函数 ARelu🌟
10、YOLOv11改进策略【损失函数篇】| WIoU v3:针对低质量样本的边界框回归损失函数🌟
🚀Neck — 加强特征融合🚀
1、YOLOv11改进策略【Neck】| ECCV-2024 RCM 矩形自校准模块 二次创新C3k2 改进颈部网络🌟
2、YOLOv11改进策略【Neck】| GSConv+Slim Neck:混合深度可分离卷积和标准卷积的轻量化网络设计🌟
3、YOLOv11改进策略【Neck】| BiFPN:双向特征金字塔网络-跨尺度连接和加权特征融合🌟
4、YOLOv11改进策略【Neck】| 使用CARAFE轻量级通用上采样算子
5、YOLOv11改进策略【Neck】| ASF-YOLO 注意力尺度序列融合模块改进颈部网络,提高小目标检测精度🌟
6、YOLOv11改进策略【Neck】| GFPN 超越BiFPN 通过跳层连接和跨尺度连接改进v11颈部网络🌟
7、YOLOv11改进策略【Neck】| 2023 显式视觉中心EVC 优化特征提取金字塔,对密集预测任务非常有效🌟
8、YOLOv11改进策略【Neck】| 有效且轻量的动态上采样算子:DySample
9、YOLOv11改进策略【Neck】| ArXiv 2023,基于U - Net v2中的的高效特征融合模块:SDI🌟
10、YOLOv11改进策略【Neck】| PRCV 2023,SBA:特征融合模块,描绘物体轮廓重新校准物体位置,解决边界模糊问题🌟
11、YOLOv11改进策略【Neck】| 替换RT-DETR中的CCFF跨尺度特征融合颈部结构,优化计算瓶颈与冗余问题🌟
12、YOLOv11改进策略【Neck】| HS-FPN:高级筛选特征融合金字塔,加强细微特征的检测🌟
13、YOLOv11改进策略【Neck】| TPAMI 2024 FreqFusion 频域感知特征融合模块 解决密集图像预测问题🌟
14、YOLOv11改进策略【Neck】| NeurIPS 2023 融合GOLD-YOLO颈部结构,强化小目标检测能力🌟
🚀Head/检测头🚀
1、YOLOv11改进策略【Head】| 引入RT-DETR中的RTDETRDecoder,替换检测头🌟
2、YOLOv11改进策略【Head】| 增加针对 大目标 的检测层 (四个检测头)🌟
3、YOLOv11改进策略【Head】| 结合CVPR-2024 中的DynamicConv 动态卷积 改进检测头, 优化模型(独家改进)🌟
4、YOLOv11改进策略【Head】| ASFF 自适应空间特征融合模块,改进检测头Detect_ASFF🌟
5、YOLOv11改进策略【Head】| AFPN渐进式自适应特征金字塔,增加针对小目标的检测头(附模块详解和完整配置步骤)🌟
6、YOLOv11改进策略【Head/分割头】| 结合CVPR-2024 中的DynamicConv 动态卷积 改进分割头, 优化模型(独家改进)🌟
7、YOLOv11改进策略【Head】| (独家改进)结合 ICME-2024 中的PPA注意力模块,自研带有注意力机制的小目标检测头🌟
8、YOLOv11改进策略【Head】| (独家改进)轻量化检测头:利用 EfficientNet 中的移动倒置瓶颈模块 MBConv 改进检测头🌟
9、YOLOv11改进策略【Head】| (独家改进)检测头添加Conv2Former 利用卷积调制操作和大核卷积简化自注意力机制,提高网络性能🌟
10、YOLOv11改进策略【Head】| 添加专用于小目标的检测层 附YOLOv1~YOLOv11的检测头变化详解🌟
🚀SPPF/空间金字塔池化🚀
1、YOLOv11改进策略【SPPF】| SimSPPF,简化设计,提高计算效率
2、YOLOv11改进策略【SPPF】| AIFI : 基于Transformer的尺度内特征交互,在降低计算成本的同时提高模型的性能
3、YOLOv11改进策略【SPPF】| NeuralPS-2022 Focal Modulation : 使用焦点调制模块优化空间金字塔池化SPPF🌟
4、YOLOv11改进策略【SPPF】| 将特征金字塔池化修改为:SPPELAN ,多尺度特征提取与高效特征融合🌟
5、YOLOv11改进策略【SPPF】| 将特征金字塔池化修改为:SPPCSPC,提升模型的特征提取能力和计算效率🌟
🚀特殊场景 — 小目标改进🚀
1、YOLOv11改进策略【小目标改进】| ASF-YOLO 注意力尺度序列融合模块改进颈部网络,提高小目标检测精度🌟
2、YOLOv11改进策略【小目标改进】| NWD损失函数,提高小目标检测精度🌟
3、YOLOv11改进策略【小目标改进】| 2024 蒙特卡罗注意力(MCAttn)模块,提高小目标的关注度🌟
4、YOLOv11改进策略【小目标改进】| 2024 PPA 并行补丁感知注意模块,提高小目标关注度🌟
5、YOLOv11改进策略【小目标改进】| SPD-Conv 针对小目标和低分辨率图像的检测任务🌟
6、YOLOv11改进策略【小目标改进】| 添加专用于小目标的检测层 附YOLOv1~YOLOv11的检测头变化详解🌟
7、YOLOv11改进策略【小目标改进】| 2024-TOP 自适应阈值焦点损失(ATFL)提升对小目标的检测能力🌟
8、YOLOv11改进策略【小目标改进】| Shape-NWD:融合改进,结合Shape-IoU和NWD 更好地适应小目标特性🌟
9、YOLOv11改进策略【小目标改进】| NeurIPS 2023 融合GOLD-YOLO颈部结构,强化小目标检测能力🌟
🎓独家融合改进 — 达到论文发表要求🎓
1、YOLOv11改进策略【独家融合改进】| MobileNetV4+BiFPN,轻松实现降参涨点,适用专栏内所有的骨干替换🌟
2、YOLOv11改进策略【独家融合改进】| AFPN渐进式自适应特征金字塔 + 注意力机制,适用专栏内所有的注意力模块🌟
3、YOLOv11改进策略【独家融合改进】| AssemFormer + HS-FPN 减少目标尺度变化影响,增加多尺度的学习能力🌟
4、YOLOv11改进策略【独家融合改进】| SPD-Conv+PPA 再次提升模型针对小目标的特征提取能力🌟
5、YOLOv11改进策略【独家融合改进】| Mamba-YOLO+SDI 增强长距离依赖,聚焦目标特征🌟
6、YOLOv11改进策略【独家融合改进】| RepVit+ASF-YOLO,轻量提点,适用专栏内所有的骨干替换🌟
7、YOLOv11改进策略【独家融合改进】| 模型轻量化二次改进:StarNet + FreqFusion,极限降参,适用专栏内所有轻量化模型🌟
8、YOLOv11改进策略【独家融合改进】| U-Net V2 + CCFF,加强跨尺度的上下文特征融合,提高模型特征提取能力🌟
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号