大模型RAG:基于PgSql的向量检索
原创

一 RAG与向量检索
1.1 RAG概念
检索增强生成(Retrieval-augmented Generation),简称RAG。
RAG通常包括两个阶段:1、检索上下文相关信息;2、使用检索到的知识指导生成过程。简单来说,就像开卷考试,我们可以携带参考材料用来查找相关信息来回答问题。
1.2 RAG意义
目前对大模型的使用通常存在两个主要挑战:1、由于生成模型依赖于内在知识(权重),对于未覆盖到的知识领域可能会产生大量的幻觉,也就是“一本正经的胡说八道”;其次,由于大模型参数量巨大,重新训练或微调方法成本过高。
1.3 RAG应用框架
RAG应用框架如下图所示,包含文本向量化、检索向量数据库、获取上下文(相关知识/文档)、prompt构造、调用大模型执行文本生成等主要环节。

当然这里只是描述了一个主流程,实际应用还有对多轮/历史会话处理、多轮问题改写,意图识别与分发,结果聚合等等。
二 向量数据库
由于介绍RAG的文章已经很多,本篇主要打算介绍向量数据库部分,所以不再对RAG进行赘述。
2.1 向量数据库方案
目前已经有十几种可选的向量数据库技术方案,包括Milvus、MongoDB Atlas、Chroma、Weaviate等。从分类的角度说,包括:原生向量数据库(Chroma、LanceDB、Mivus等)、支持向量的全文检索数据库(Elastic、Lucene、OpenSearch和Solr)、支持向量的NoSQL数据库(Cassandra、Rockset、Azure Cosmos DB和MongoDB)、和支持向量的关系数据库(PostgreSQL、Clickhouse、SingleStoreDB等)。
主流向量数据库的部分指标对比如下:
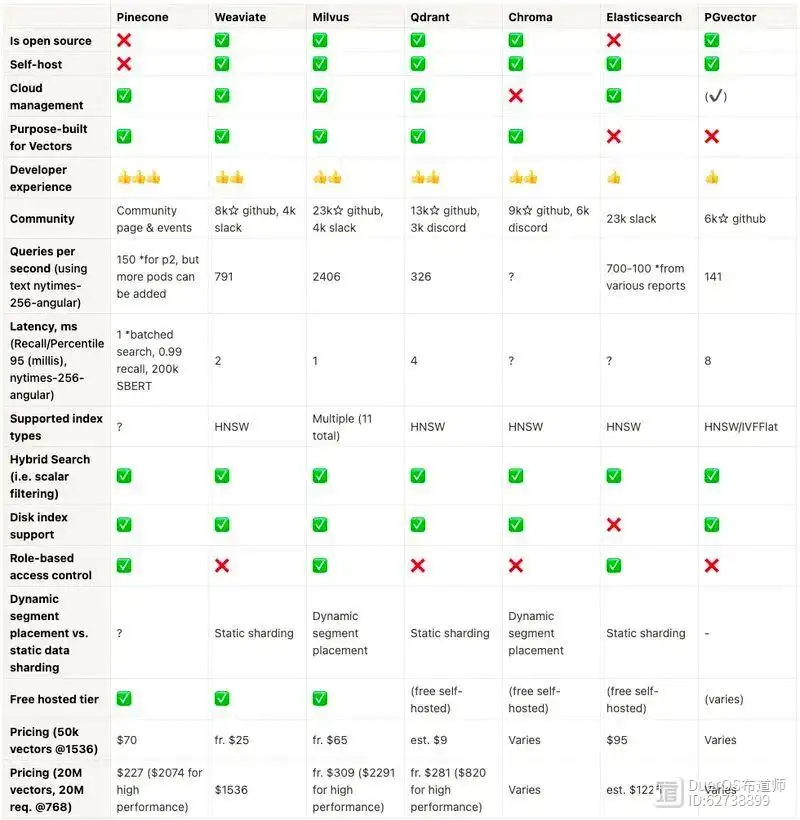
通常大模型应用场景,Milvus等原生向量数据库是最推荐的。但根据实际使用场景和习惯,在知识库数量并不是很大的场景(亿级以下),考虑到使用习惯和学习复杂度,也可以选择PgSQL等关系型数据库。
2.2 PgSql与PgVector
Postgres 通过 pg_vector 和 pg_embdding 两个插件来实现向量数据库,让PG数据库支持向量索引检索的能力。其索引算法使用的是基于Faiss的IVF Flat索引,提供了优异的召回率。
三 基于PgSql的向量检索示例
3.1 建立向量库
如下建表语句所示,向量库主要文档内容和embedding(文档向量化结果)。考虑到在实际应用场景可能涉及文档权限控制,或展示参考资料,我们还设计了文档名、文档id字段。
-- vector.knowledge_doc_vector definition
-- Drop table
-- DROP TABLE vector.knowledge_doc_vector;
CREATE TABLE vector.knowledge_doc_vector (
id bigserial NOT NULL,
doc_id bigserial NOT NULL,
embedding public.vector NULL,
doc_content text NULL,
doc_name varchar NULL,
doc_page varchar NULL,
CONSTRAINT knowledge_doc_vector_pkey PRIMARY KEY (id)
);示例数据如下:

3.2 Mybatis连接PgSql
除了mybatis-plus之外,引入pgsql和pgvector两个依赖:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.6.0</version>
</dependency>
<dependency>
<groupId>com.pgvector</groupId>
<artifactId>pgvector</artifactId>
<version>0.1.6</version>
</dependency>3.3 编写mapper
用于查找相似向量,按照余弦相似度计算
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.fawvw.pms.vector.domain.dto.KnowledgeDocVectorDTO;
import com.fawvw.pms.vector.domain.entity.KnowledgeDocVector;
import com.google.gson.Gson;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.SelectProvider;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
@Mapper
public interface VectorMapper extends BaseMapper<KnowledgeDocVector> {
@SelectProvider(type = SqlProvider.class, method = "findUsersWithSimilarVectors")
List<KnowledgeDocVectorDTO> findUsersWithSimilarVectors(double[] targetVector);
static class SqlProvider {
public String findUsersWithSimilarVectors(Map<String, Object> param) {
System.out.println("param keys:" + new Gson().toJson(param.keySet()));
double[] targetVector = (double[]) param.get("array");
String sql = "SELECT id, doc_id, embedding, doc_content, " +
"cosine_distance(embedding, '" + Arrays.toString(targetVector) + "') AS similarity " +
"FROM knowledge_doc_vector " +
"ORDER BY similarity DESC";
return sql;
}
}
}3.4 方法中调用,查询相似向量
下面示例代码使用的是阿里的灵积服务计算embedding,也可以采用其他方式计算。
public List findSimilarVector(String query) {
// query转为向量
TextEmbeddingResult embeddingResult = dashCodeHttpApi.textEmbedding(query);
List<Double> embeddings = embeddingResult.getOutput().getEmbeddings().get(0).getEmbedding();
double[] vector = new double[embeddings.size()];
for (int i = 0; i < embeddings.size(); i++) {
Double embedding = embeddings.get(i);
vector[i] = embedding;
}
log.info("vector:{}", vector);
List<KnowledgeDocVectorDTO> vectorDTOList = vectorMapper.findUsersWithSimilarVectors(vector);
log.info("vectorDTOList:{}", vectorDTOList);
// 过滤掉相似度低的向量检索结果 阈值:0.7
vectorDTOList = vectorDTOList.stream()
.filter(vectorDTO -> vectorDTO.getSimilarity() <= 0.7)
.collect(Collectors.toList());
return vectorDTOList;
}拿到与问题相关的文档知识之后,我们就可以封装prompt,并调用大模型API获取生成式回答了。
具体方法这里不再列举。
四 小结
本篇介绍了RAG的一些基础知识,以及向量库在其中的作用及选型。并基于PgSQL给出了一个向量库的使用示例。接下来的文章中,我们将深入探索如何实现可用的RAG应用。欢迎留言一起探讨。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号