TME髓系亚群细分“一本通”


2021年张泽民教授团队发布了髓系单细胞的泛癌图谱——
A pan-cancer single-cell transcriptional atlas of tumor infiltrating myeloid cells
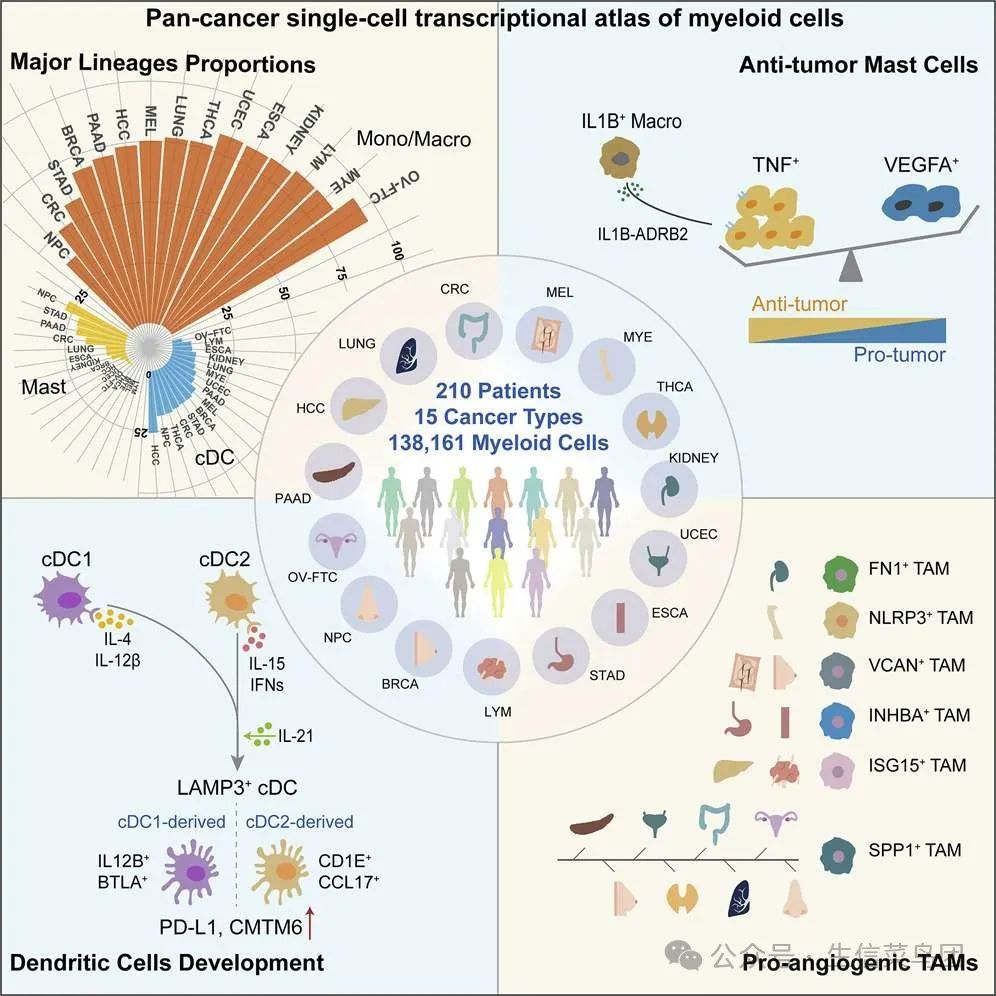
f1
f1
其中,对于髓系各亚群的marker是这样区分的:
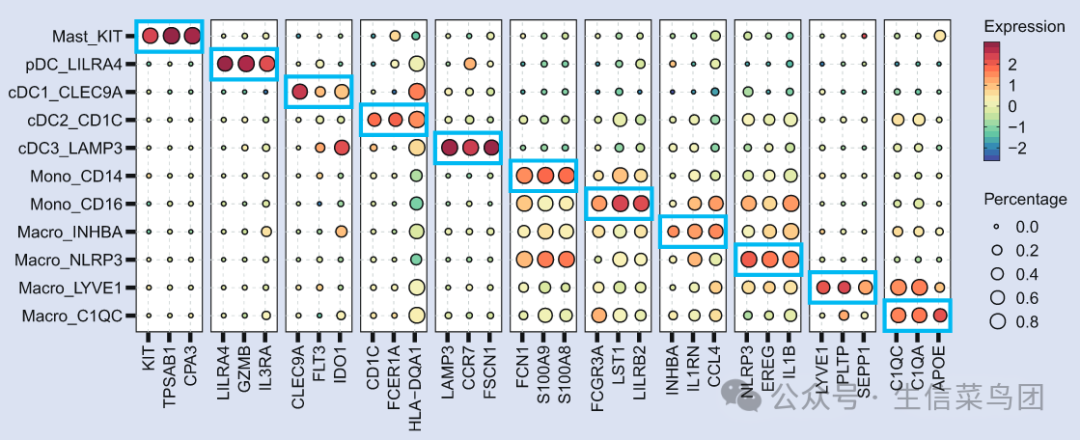
- Mast_KIT: KIT, TPSAB1, CPA3
- pDC_LILRA4: LILRA4, GZMB, IL3RA
- cDC1_CLEC9A: CLEC9A, FLT3, IDO1
- cDC2_CD1C: CD1C,, FICERIA, HLA-DOA1
- cDC3_LAMP3: LAMP3, CCRY, FSCN1
- Mono_CD14: FCN1, S100A9, S100A8
- Mono_CD16: FCOR3A, LST1, LILRB2
- Macro_INHBA: INHBA, IL1RN, CCL4
- Macro_NLRP3: NLRP3, , EREG, IL1B
- Macro_LYVE1: LYVE1, PLTP, SEPP1
- Macro_C1QC: C1QC, C1QA, APOE
另外在补充材料里,作者还提供了树突细胞和 M1, M2巨噬细胞的标志性基因。
cell type | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
M1 | IL23 | TNF | CXCL9 | CXCL10 | CXCL11 | CD86 | IL1A | IL1B | IL6 | CCL5 | IRF5 | IRF1 | CD40 | IDO1 | KYNU | CCR7 |
M2 | IL4R | CCL4 | CCL13 | CCL20 | CCL17 | CCL18 | CCL22 | CCL24 | LYVE1 | VEGFA | VEGFB | VEGFC | VEGFD | EGF | CTSA | CTSB |
Activated DC | FSCN1 | BIRC3 | LAMP3 | CCL19 | LAD1 | MARCKS | TNFAIP2 | CCR7 | CCL22 | MARCKSL1 | EBI3 | TNFRSF11B | NUB1 | INSM1 | RAB9A | LY75 |
Migratory DC | GAL3ST | NUDT17 | ITGB8 | ADCY6 | ENO2 | IL15RA | SOCS2 | IL15 | STAP2 | PHF24 | ANKRD33B | INSM1 | ANXA3 | ARHGAP28 | RNF115 | ADORA2A |
转眼间4年过去,2025年2月,这个团队又有新作——
Distinct cellular mechanisms underlie chemotherapies and PD-L1 blockade combinations in triple-negative breast cancer
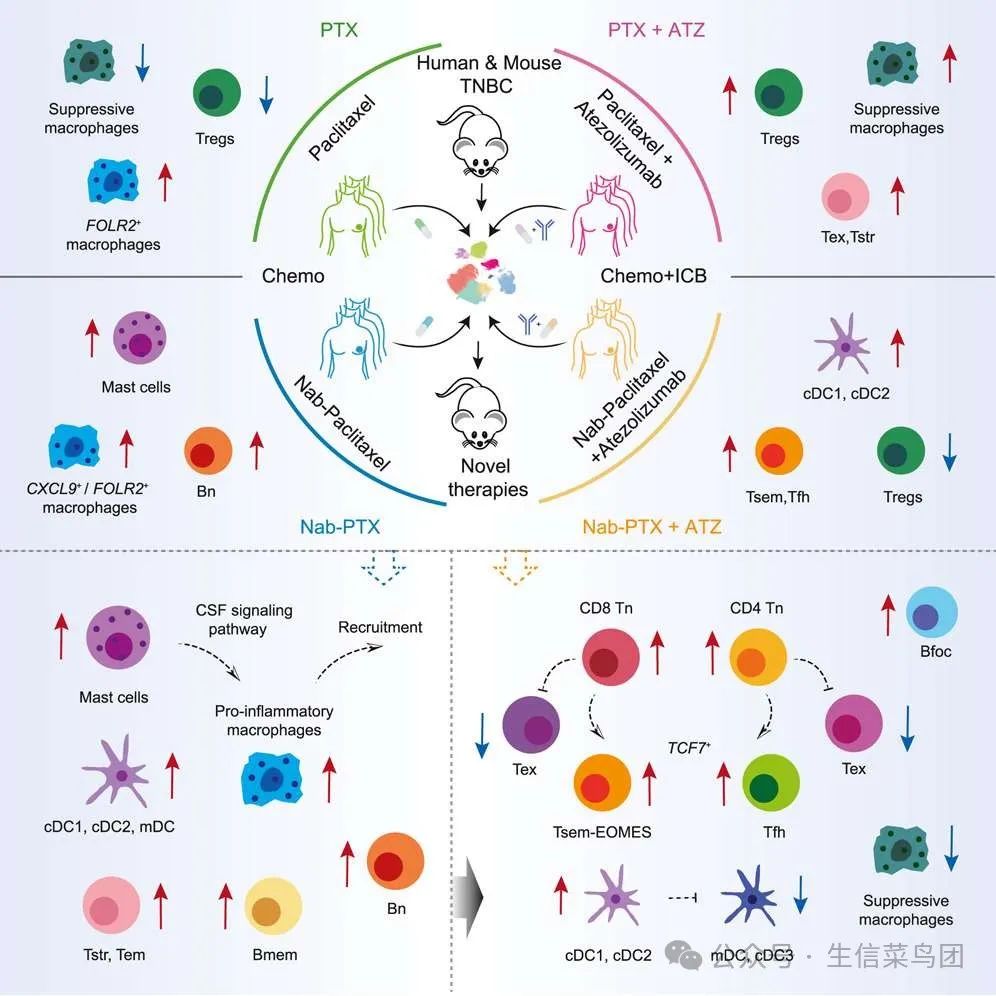
f2
f2
作者从44例TNBC患者中获得了78份肿瘤活检样本,鉴定出28个T细胞子集,14个B细胞子集,11 NK细胞子集和18个髓细胞子集。
在补充材料Table S3中,作者详细提供了各个细胞亚群的marker:
其中,髓系细胞包括:
- Mono-S100A8
- Mono-IL1B
- Macro-NUPR1
- Macro-CXCL9
- Macro-CCL2
- Macro-CCL3L1
- Macro-FOLR2
- Macro-FTH1
- Macro-SELENOP
- Macro-IL1B
- Macro-FN1
- Macro-RNASE1
- Macro-ISG15
- Macro-MT1X
- MAST-TPSAB1
- cDC1-CLEC9A
- cDC2-CLEC10A
- mDC-LAMP3
- cDC2-CD1A
- pDC-LILRA4
这篇文章并未提供代码,作者将整理好的单细胞数据存放在[https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE266919]
可以简单跑一下试试:
# Step1.读入数据 --------------------------------------------------------------
### 1.读入数据
seurat.data = readRDS("./GSE266919_Myeloid.rds")
seurat.data
# 计算 logcounts(对数归一化)
logcounts(seurat.data) <- log1p(counts(seurat.data)) # 使用 log(x + 1) 转换
seurat.obj <- as.Seurat(seurat.data,counts = "counts",data = "logcounts")
seurat.obj
# Step2.三步走:标准化、特征选择和归一化分析 ------------------------------------------------
### 2.三步走:标准化、特征选择和归一化分析
seurat.obj <- seurat.obj %>% NormalizeData(verbose = F) %>%
FindVariableFeatures(selection.method = "vst", nfeatures = 2000, verbose = F) %>%
ScaleData(verbose = F)
seurat.obj
# Step3.降维和聚类,检查批次 --------------------------------------------------------
### 3.1 降维和聚类
seurat.obj = seurat.obj %>%
RunPCA(npcs = 30, verbose = F) %>%
#RunTSNE(reduction = "pca", dims = 1:30, verbose = F) %>%
RunUMAP(reduction = "pca", dims = 1:30, verbose = F)
seurat.obj
### 3.2 检查批次
options(repr.plot.width = 10, repr.plot.height = 4.5)
p1.compare=wrap_plots(ncol = 2,
DimPlot(seurat.obj, reduction = "pca", group.by = "Sample")+NoAxes()+ggtitle("Before_PCA"),
DimPlot(seurat.obj, reduction = "umap", group.by = "Sample")+NoAxes()+ggtitle("Before_UMAP"),
guides = "collect"
)
p1.compare
### 3.3 若无批次,继续运行聚类
seurat.obj <- FindNeighbors(seurat.obj, dims = 1:30)
for (res in c(0.05,0.1,0.3,0.5,0.8,1,1.2,1.4,1.5,2)){
print(res)
seurat.obj <- FindClusters(seurat.obj,resolution = res, algorithm = 1)
}
#umap可视化
cluster_umap <- wrap_plots(ncol = 5,
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.0.05", label = T) & NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.0.1", label = T) & NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.0.3", label = T)& NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.0.5", label = T) & NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.0.8", label = T) & NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.1", label = T) & NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.1.2", label = T) & NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.1.4", label = T)& NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.1.5", label = T)& NoAxes(),
DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.2", label = T)& NoAxes()
)
cluster_umap
# ggsave(cluster_umap,filename = "Outplot/Step3.Before_inter.cluster_umap.pdf",
# width = 25, height = 9)
# 选择一个合适的分辨率
Idents(object = seurat.obj) <- "originalexp_snn_res.0.3"
options(repr.plot.width = 6, repr.plot.height = 5)
p1 <- DimPlot(seurat.obj, reduction = "umap", group.by = "originalexp_snn_res.0.3", label = T)& NoAxes()
# Step4.亚群注释 --------------------------------------------------------------
options(repr.plot.width = 7.5, repr.plot.height = 10)
check_genes = c("S100A8","S100A9",'FCN1','CD52', # Mono-S100A8
'SOD2',"CXCL2",'C5AR1', # Mono-IL1B
'IFI30',"NUPR1","GPNMB",'CTSD', # Macro-NUPR1
"ACP5","HLA-DQA1",'PLD3',# Macro-CXCL9
"CCL2","HMOX1","IFI6","TNF",# Macro-CCL2
"IFI27","CCL3L1",'FABP5', # Macro-CCL3L1
"C3","FCGR2A", "ALOX5AP",'PLD4',# Macro-FOLR2
"FTH1","FTL","B2M","HSP90AA1", "TMSB4X", # Macro-FTH1
"SELENOP","LGMN","CD5L", "MUCL1","RSAD2", # Macro-SELENOP
"G0S2", "IL1B","RPS29", # Macro-IL1B
"FN1","CCL7","MT2A",'TGFBI','HSP90AB1', # Macro-FN1
"RNASE1","KLF6","CXCL3",# Macro-RNASE1
"CXCL10","IRF1","ISG15", # Macro-ISG15
"RAB42","PLIN2","MT1X","CFD", # Macro-MT1X
"TPSAB1","TPSB2",'CPA3', # MAST-TPSAB1
"CPVL","CST3","LYZ","SNX3", # cDC1-CLEC9A
"RGS2","CXCR4","INSIG1","GPR183", # cDC2-CLEC10A
"MARCKSL1","FSCN1","TXN","CCR7", # mDC-LAMP3
"S100B","MMP9","LMNA","CD1A", # cDC2-CD1A
"GZMB","JCHAIN","IRF7","ITM2C" # pDC-LILRA4
)
## 运行以下命令检查 check_genes 中是否有重复的基因名称
duplicated_genes <- check_genes[duplicated(check_genes)]
duplicated_genes
p1 <- DotPlot(object = seurat.obj, features = check_genes,assay = "originalexp",scale = T) +
coord_flip()
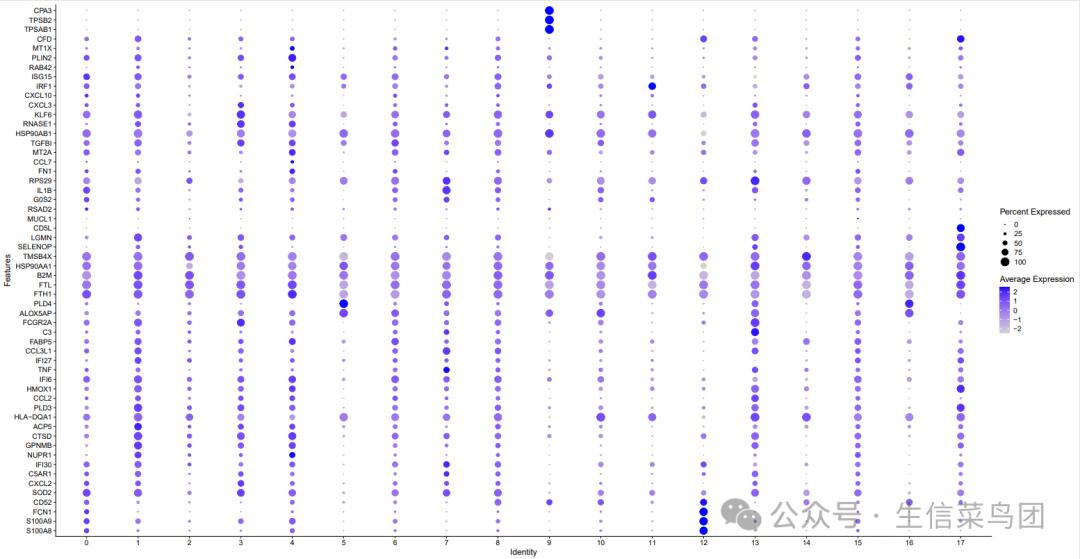
虽然说是髓系,但这两篇文章并没有囊括中性粒细胞亚群。如果需要中性粒的亚群分类,可以参考这篇——

cell type | |||||||||
|---|---|---|---|---|---|---|---|---|---|
ARG1+Neu | HBA1 | HBB | HBA2 | HBD | H3-3A | H3-3B | AC005747-1 | AL442635-1 | CD163 |
CXCL8+IL1B+Neu | FRMD4B | QSOX1 | SLC7A5 | ATP13A3 | OXSR1 | GPAT4 | B3GNT5 | PDE4B | PRKDC |
CXCR2+Neu | CARD8-AS1 | MRVI1 | PLEKHO1 | MOSPD2 | NCF1C | ST3GAL2 | UBR2 | P2RY13 | |
HLA-DR+CD74+Neu | PTPRCAP | IGKV3-20 | HLA-DPB1 | HLA-DPA1 | AHNAK | HLA-DQA1 | CD52 | CD99 | CRIP1 |
IFIT1+ISG15+Neu | HERC5 | OAS3 | XAF1 | IFIT1 | ISG15 | IFIT2 | |||
MMP9+Neu | CD177 | SLCO4C1 | CAMP | PGLYRP1 | SYNE1 | PCMT1 | FCN1 | ARAP2 | |
NFKBIZ+HIF1A+Neu | AL355881-1 | HPS5 | MAPK6 | AL499604-1 | SEC24A | ADORA2A | PIK3IP1 | ||
S100A12+Neu | S100A12 | CDA | TSPO | TXN | S100A6 | S100A4 | S100P | OAZ1 | CMTM2 |
TXNIP+Neu | TXNIP | MALAT1 | B2M | FCGR3B | HLA-B | IFITM2 | DUSP1 | ||
VEGFA+SPP1+Neu | CLCN7 | MIF | CCL3 | SLC3A2 | PI3 | P4HA1 | VEGFA | LGALS3 | RALGDS |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号