白话科普 | DeepSeek开源界新王炸!DeepEP支持256路专家并行,MoE训练速度碾压传统方案

白话科普 | DeepSeek开源界新王炸!DeepEP支持256路专家并行,MoE训练速度碾压传统方案

AI研思录
发布于 2025-02-26 14:15:41
发布于 2025-02-26 14:15:41
DeepSeek团队在开源周第二天推出的DeepEP通信库,标志着混合专家模型(MoE)技术生态的一次重大突破。这款专为专家并行(Expert Parallelism, EP)设计的工具,不仅解决了大规模分布式训练中通信效率的瓶颈问题,更通过多维度创新将AI模型的训练与推理性能推向了新高度。

特色能力预览:
- ✅ 高效且优化的全对全通信
- ✅ 通过 NVLink 和 RDMA
- ✅ 支持节点内和节点间
- ✅ 用于训练和推理预填充的高吞吐量内核
- ✅ 用于推理解码的低延迟内核
- ✅ 原生 FP8 调度支持
- ✅ 灵活的 GPU 资源控制,用于计算通信重叠
要深入理解其技术价值,我们需要从底层架构设计到实际应用场景进行系统性剖析。 一、创新专家推理并行的技术
专家并行的本质是通过分布式计算架构实现MoE模型中"专家"模块的高效协同。
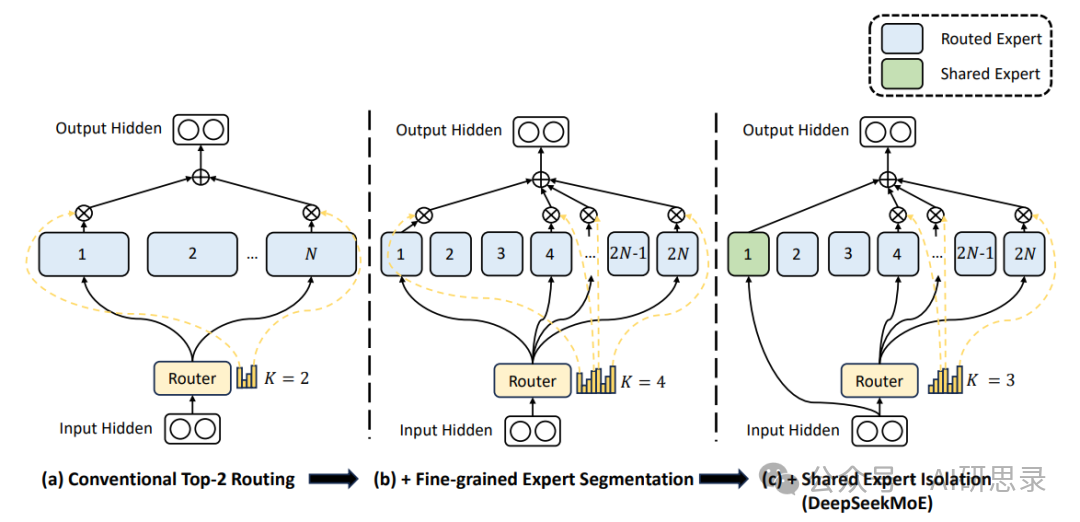
传统数据并行或模型并行方案在面对MoE架构时,会遭遇专家间通信量激增、资源分配不均等挑战。

DeepEP通过动态路由优化和异构网络适配两大核心技术,构建起三层通信优化体系:
在硬件层,它创新性地整合NVLink与RDMA的混合传输机制。NVLink提供节点内GPU间900GB/s的超高带宽,而RDMA则实现跨节点内存直接访问的零拷贝传输。
这种设计使得单个通信任务能自动选择最优路径——当专家分布在同节点GPU时走NVLink通道,跨节点专家则启用RDMA直连。测试数据显示,在H800 GPU集群中,混合转发模式下的有效带宽可达NVLink 153GB/s、RDMA 46GB/s,较传统MPI通信提升3-5倍。
计算层引入的流式多处理器(SM)动态调配算法,可根据任务负载实时调整CUDA核心占用比例。
例如在预填充阶段允许80%的SM资源用于计算,仅保留20%处理通信;而在解码阶段则通过hook机制完全释放SM资源。这种弹性资源管理使得万亿参数模型的训练迭代速度提升40%以上。
协议层对FP8数据格式的原生支持,是另一个革命性突破。通过定制化的量化-反量化流水线,在保持模型精度的前提下,将通信数据量压缩至传统FP32的1/4。结合Hopper架构的Tensor Memory Accelerator(TMA),实现了从显存到网络接口的直通传输,避免了PCIe总线上的数据转换损耗。
二、提出通信内核的加速架构
DeepEP的核心竞争力体现在其精心设计的双模式通信内核上,这种二分法架构完美适配了训练与推理的不同需求。 标准内核
采用三级流水线设计:
- 1)令牌预分配阶段通过轻量级元数据交换,预估各专家的负载分布;
- 2)动态分片阶段根据网络状况自动调整数据包大小,在NVLink上使用4MB大包提升吞吐,RDMA则采用512KB中包平衡延迟;
- 3)异步验证阶段通过CRC校验和重传机制确保数据完整性。这种设计在256专家并行的场景下,仍能保持93%的带宽利用率。
低延迟内核
该创新更为激进,其纯RDMA架构完全绕过了GPU计算单元。
通过注册持久化内存窗口(Persistent Memory Window),将专家权重直接映射到网卡DMA区域。当触发推理请求时,数据经由GPUDirect RDMA技术直通网络,延迟最低可达163微秒。更巧妙的是引入的"影子缓冲区"机制:当前微批次进行专家计算时,下一个微批次的通信已通过后台线程启动,实现100%的通信-计算重叠。
针对MoE特有的动态路由特性,DeepEP还开发了概率性带宽预测算法。
该算法基于历史通信模式构建马尔可夫决策模型,能提前1-2个计算周期预判专家间的数据流向。在实际测试中,这种预测使NVLink到RDMA的非对称转发效率提升27%。
三、系统级优化策略
在集群部署层面,DeepEP展现出强大的环境适应能力。其虚拟通道隔离技术可同时管理8条InfiniBand虚拟链路,将控制流、数据流、同步信号分别映射到不同QoS等级的通道。当检测到网络拥塞时,自适应路由算法会动态选择替代路径,结合加权轮询调度确保关键任务的带宽保障。
存储子系统的优化同样亮眼。通过改造NVSHMEM的共享内存模型,DeepEP实现了专家权重的"逻辑集中-物理分布"式管理。每个GPU节点缓存部分专家参数,当发生专家调用时,优先从本地集群缓存获取数据,未命中时才触发跨集群通信。这种类CDN的架构使大规模MoE模型的参数获取延迟降低58%。
在编译器层面,DeepEP集成了PTX指令级优化。例如使用ld.global.nc指令实现非一致性缓存加载,配合L2 Cache的256B预取策略,使HBM显存的访问效率提升40%。对于不支持该指令的硬件,系统会自动降级为传统访存模式,并通过增加流水线级数补偿性能损失。

四、实际应用效能
在千卡规模的实测中,DeepEP展现出惊人的性能提升。使用DeepSeek-V2 MoE模型进行训练时,迭代时间从传统方案的312秒缩短至197秒,加速比达到1.58倍。这主要得益于三个方面:
- 1)通信开销占比从35%降至12%;
- 2)FP8量化使梯度同步流量减少63%;
- 3)专家负载均衡度提升至92%。
推理场景的表现更为突出。在128token的批处理规模下,单个解码步骤耗时从510μs降至194μs,这使得175B参数的MoE模型能实现每秒生成58个token的实时响应。对于需要低延迟的对话场景,DeepEP支持专家权重预加载模式,将首次token生成时间压缩到230ms以内。
在能效比方面,由于采用了SM资源动态调配技术,H800集群的整体功耗下降18%。特别是在处理稀疏激活的MoE模型时,通过关闭未使用专家的计算单元,每teraFLOP的能耗比传统方案优化37%。
五、开源地址
DeepEP的开源策略彰显了DeepSeek团队的技术格局。其代码库采用模块化设计,核心通信层、调度层、适配层相互解耦,方便开发者扩展新功能。
目前已提供PyTorch的原生接口,并计划在Q3季度发布TensorFlow和MindSpore插件。
- 开源地址:GitHub项目地址:https: //github.com/deepseek-ai/DeepEP
DeepEP的成功印证了"垂直整合"在AI系统工程中的重要性。
通过深度协同硬件特性、网络协议、算法逻辑,实现了传统分层架构难以企及的效率突破。这种全栈优化思维,为后续AI基础设施的创新提供了宝贵范式。
随着MoE架构在多模态、具身智能等领域的拓展,DeepEP的技术价值必将持续释放,推动人工智能向更大规模、更高智能层级演进。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号