DeepSeek R1专家并行
原创

混合专家Moe原理
DeepSeek R1和V3一样,采用混合专家,模型结构图如下:
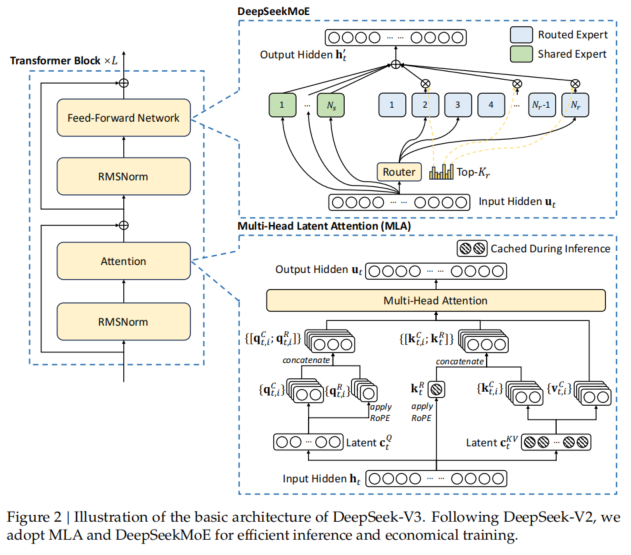
DeepSeek R1模型结构图
混合专家相当于Transformer结构中的FFN,R1每一层网络有1个共享专家(shared expert)、256个路由专家(routed expert),每个token的推理会激活8个路由专家。
可以大大降低计算量,同时专家可以方便的扩展。部署的时候专家还可以分开部署,即做专家并行,降低了对硬件资源的需求。
专家并行
如上文所说,256个路由专家每次只会激活8个,如果每个节点都包含所有的专家,大多数时候会有很多专家空闲,白白占用着显存。所以有了专家并行的概念,专家并行来自google 2020年的paper:GShard,原文链接:2006.16668。专家并行过程如下图:
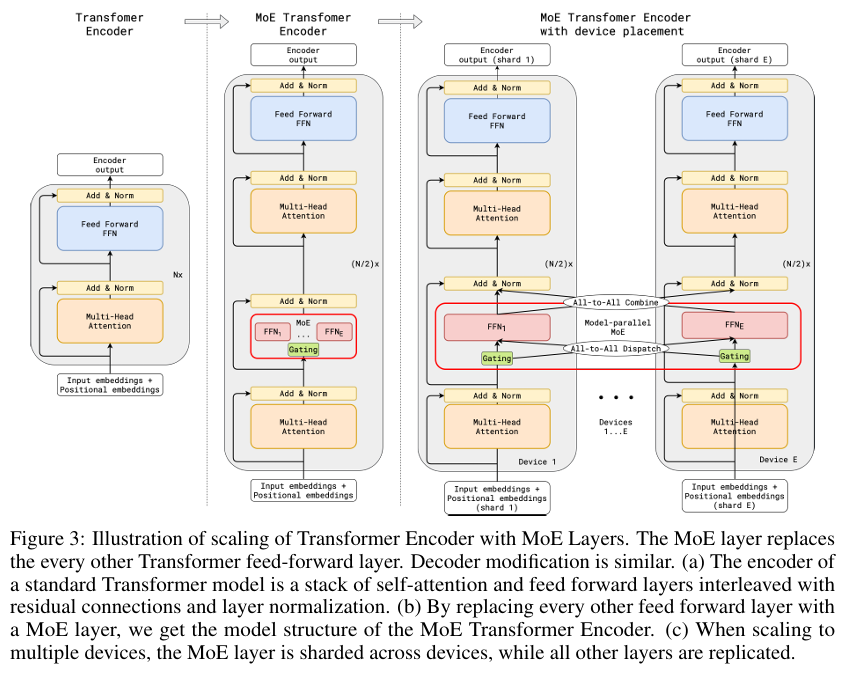
专家并行原理
每一个分片(节点、GPU卡)只会加载部分专家,如果某个分片上的计算需要其他分片的专家,可以通过All2All通信实现。
2021年Switch Transformers2101.03961也提出了更高效的并行方式,不过主要针对google的TPU。
2021年清华大学提出的FastMoe2103.13262,可以适用于GPU和pytorch。
2023年微软提出了Tutel2206.03382,优化了All2All通信性能。
2022年斯坦福大学、微软和谷歌联合发表了MegaBlocksMegaBlocks: Efficient Sparse Training with Mixture-of-Experts,主要解决的是 1 个 GPU 上有多个专家时,由于负载不均衡导致的 Token 丢弃或者 Padding 无效计算问题。
DeepSeek R1的专家并行实现可以参考ColossalAI:https://github.com/hpcaitech/ColossalAI/blob/main/colossalai/shardformer/modeling/deepseek_v3.py#L100
通信优化
All2All 是集合通信库(比如 NCCL)中另一种常见的通信原语,用于多个设备之间进行数据交换。All2Alll 操作允许每个参与的设备将其本地数据分发到其他设备,同时从其他设备接收数据。
同时,DeepSeek开源了其对All2All通信的优化实现,详见代码库DeepEP:deepseek-ai/DeepEP: DeepEP: an efficient expert-parallel communication library,专用于专家并行训练和推理的加速。针对NVLink(NVLink是英伟达开发的高速互联技术,主要用于GPU之间的通信,提升带宽和降低延迟)到RDMA(远程直接内存访问,一种网络数据传输技术,用于跨节点高效通信)的非对称带宽转发场景进行了深度优化,不仅提供了高吞吐量,还支持SM(Streaming Multiprocessors)数量控制,兼顾训练和推理任务的高吞吐量表现。
专家负载均衡
在训练和推理中,有的专家使用频率很高,导致该专家所在的机器负载较高,有的专家可能很少被使用到,机器都是空闲的。我们可以对热点专家做冗余,也就是冗余专家,在不同的机器部署多份该专家。冗余专家策略可以根据用户实时任务调整,决定哪些专家应该冗余,放到哪台机器合适。
DeepSeek开源了专家做负载均衡的代码:deepseek-ai/EPLB: Expert Parallelism Load Balancer。
参考资料
DeepSeek V3:DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3
DeepSeek R1:DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1
vLLM:vllm/vllm/model_executor/models/deepseek_v2.py at main · vllm-project/vllm
ColossalAI:ColossalAI/colossalai/shardformer/modeling/deepseek_v3.py at main · hpcaitech/ColossalAI
GShard:https://arxiv.org/pdf/2006.16668
Switch Transformers:2101.03961
FastMoe:https://arxiv.org/pdf/2103.13262
Tutel:https://arxiv.org/pdf/2206.03382
MegaBlocks:https://arxiv.org/pdf/2211.15841
DeepEP:deepseek-ai/DeepEP: DeepEP: an efficient expert-parallel communication library
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号