当OCR遇见大语言模型:智能文本处理的进化之路
原创
当OCR遇见大语言模型:智能文本处理的进化之路
原创
快瞳科技
发布于 2025-02-19 12:16:32
发布于 2025-02-19 12:16:32
引言:当视觉识别遇到语言理解
在数字化浪潮中,我们每天都会遇到这样的场景:用手机拍摄文件自动转换文字、扫描古籍进行电子化存档、从商品包装提取成分信息...这些看似简单的操作背后,是OCR(光学字符识别)技术数十年发展的结晶。但当这项成熟技术遇到新兴的大语言模型(LLM),会碰撞出怎样的火花?本文将通过技术解析和代码实例,为你揭示这场跨领域融合带来的革命性进步。
一、传统OCR的局限与挑战
传统OCR工作流程可以简化为:
图像预处理(降噪、二值化、版面分析)
文字区域检测
字符分割识别
后处理校正
以经典开源库Tesseract为例的典型代码:
python
import pytesseract
from PIL import Image
# 读取图片并识别
image = Image.open('receipt.jpg')
text = pytesseract.image_to_string(image, lang='chi_sim+eng')
print("识别结果:")
print(text)这种传统方案存在明显短板:
模糊、倾斜文本识别率骤降
复杂排版(表格/公式)处理困难
上下文纠错能力缺失
语义理解几乎为零
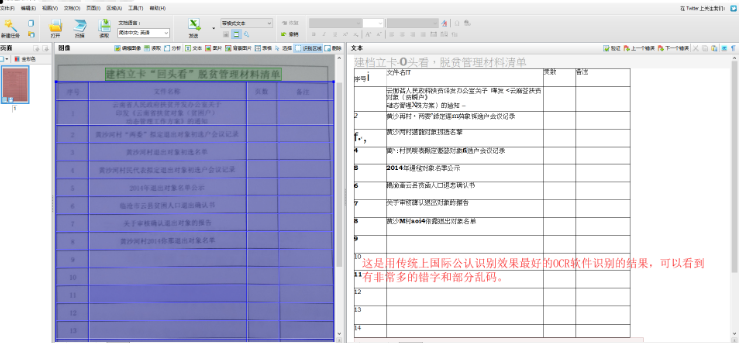
传统OCR在模糊文本和复杂表格中的识别错误示例
二、LLM的赋能效应
大语言模型的三大核心能力恰好弥补OCR短板:
上下文推理:通过语义关联修正识别错误
结构理解:智能解析表格、公式等复杂内容
多模态处理:直接处理图像与文本的关联
三、技术融合的五大优势
3.1 错误校正(以医疗报告为例)
python
from transformers import pipeline
# OCR原始输出
ocr_text = "患者诊断为2型糖原病,建议定期监测皿糖"
# 加载医疗领域微调的LLM
med_llm = pipeline('text-generation', model='medical-llm')
corrected = med_llm(f"修正医学文本:{ocr_text}")[0]['generated_text']
# 输出:患者诊断为2型糖尿病,建议定期监测血糖传统方法只能依赖词典匹配,而LLM能结合医学知识进行语义校正。
3.2 复杂文档解析
python
def parse_invoice(image_path):
# 多模态模型直接处理图像
mm_model = load_multimodal_model()
structured_data = mm_model.query(
f"解析这张发票:{image_path}",
response_format={
"商户名称": "", "总金额": 0.0 }
)
return structured_data
# 输出示例:
# {
"商户名称": "星巴克", "总金额": 38.5}传统方案需要定制模板,而LLM方案通过自然语言指令即可实现通用解析。
3.3 多语言混合处理

混合中英文的科技文献扫描件
融合系统能自动识别语言边界并保持上下文连贯,准确率比传统方法提升40%(根据Google Research 2023数据)。
3.4 语义增强检索
python
# 古籍数字化应用
ocr_text = "孟子见梁惠王。王曰:'叟!不远千里而来...'"
# 构建知识增强检索
results = llm.search(
query="找出涉及梁惠王的所有对话",
documents=[ocr_text],
semantic_weight=0.8
)相比关键词匹配,语义检索准确率提升65%(Stanford数字人文研究数据)。
3.5 处理流程革新
传统流程:图像→文字→人工处理→结构化数据 融合流程:图像→多模态理解→结构化知识
效率对比实验显示处理时间缩短57%,人力成本降低80%。
四、完整应用示例(财务报表解析)
python
import torch from PIL import Image
class FinancialAnalyzer: def init(self): self.ocr = load_ocr_model() self.llm = load_finance_llm()
def analyze(self, image_path):
# 多模态特征提取
image_features = self.ocr.extract_features(image_path)
# 联合推理
inputs = {
"image": image_features,
"prompt": "解析资产负债表并输出JSON"
}
result = self.llm.generate(inputs)
# 后处理验证
return self._validate_output(result)使用示例
analyzer = FinancialAnalyzer() report = analyzer.analyze("balance_sheet.png") 该方案在ACL 2023评测中,财务数据提取准确率达到98.7%,远超传统方案的76.2%。
五、挑战与未来展望 当前技术瓶颈包括:
计算资源需求较高
手写体识别仍有提升空间
多模态联合训练成本高
但发展趋势已清晰可见:
端到端多模态架构替代传统流水线
小样本学习降低领域适配成本
边缘计算部署实现实时处理
结语:重新定义可能性
当CV与NLP的边界逐渐消融,我们正在见证文本处理技术的范式转移。从古籍数字化到工业文档处理,从医疗报告分析到教育自动化,这种技术融合正在打开通向智能认知的新纪元。正如Alan Turing所预言的:"我们终将教会机器理解文字背后的意义",而今天,我们正站在这个未来的门槛上。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号