两个案例带你看懂YashanDB执行计划

两个案例带你看懂YashanDB执行计划

用户11512874
发布于 2025-02-19 12:00:40
发布于 2025-02-19 12:00:40
前言
执行计划是数据库查询优化的基石。学习阅读执行计划有助于深入了解数据库对SQL查询的解析和执行机制。执行计划揭示了查询的逻辑流程,包括表连接方式、数据过滤和聚合方法以及结果排序规则,这对于诊断性能瓶颈、优化查询速度和提高资源利用率至关重要。开发人员可以通过分析执行计划,识别索引使用的有效性,确定是否需要调整查询结构,以及是否需要更新数据库统计信息,从而编写更高效的SQL代码,提升数据库性能,确保数据检索兼具速率与成本效益。
简而言之,学习阅读执行计划是每个数据库开发者和管理员必备的技能。在本文中,将会基于YashanDB已发布版本,详细展开YashanDB执行计划的阅读方式。
YashanDB执行计划详解
在接下来的所有演示中,我们将基于如下的建表语句进行:
CREATE TABLE T1 (ID INT, SCORE INT);
CREATE TABLE T2 (ID INT, NAME VARCHAR(10));对于以上的两张表,我们将使用两个较为简单的查询语句用作范例,其中一个包含子查询信息,另一个不包含,为大家详细讲解如何阅读执行计划。
例1:不包含子查询
SELECT avg(score), name FROM t1 JOIN t2 ON t1.id = t2.id
WHERE t2.id > 50 GROUP BY t2.name HAVING avg(score) > 60;查看YashanDB计划的方法很简单,在对应需要查看执行计划的语句开头加入explain关键字,服务端即可返回执行计划并在客户端打印。
通过这种方式将上述语句打印后可以得到如下图的执行计划:
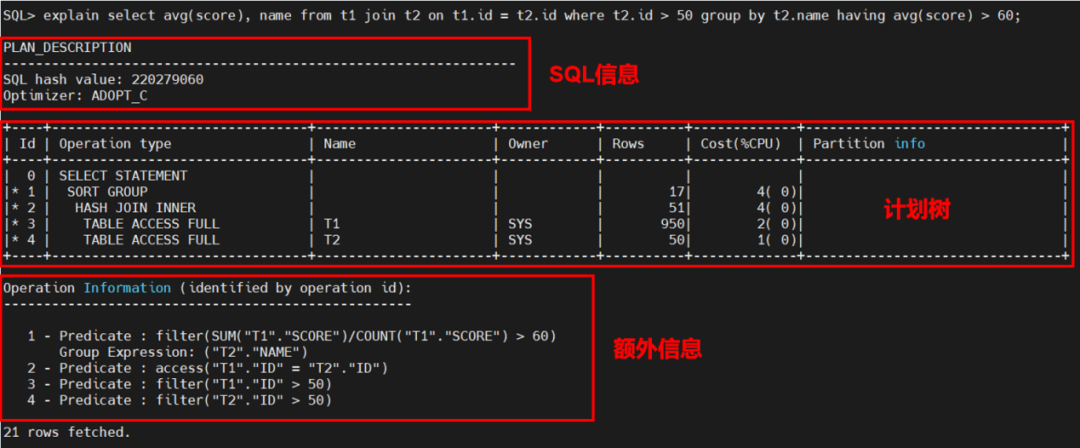
图 1:执行计划范例
按照图1中所示,我们将分为三部分阅读打印出来的信息。
SQL信息
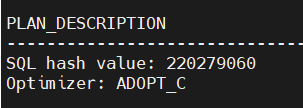
第一行SQL hash value表示的是当前输入的SQL文本的唯一标识,在一些计划或SQL语句相关的视图中可以直接通过这个值找到这条SQL语句。
第二行Optimizer表示的是优化当前语句执行计划所选用的优化器,ADOPT_C表示的是基于代价的优化器(Cost Base Optimizer)。在YashanDB于22.2版本正式上线CBO之后,所有的计划优化都由CBO进行,不存在其它优化方式。
计划树部分

YashanDB的计划树部分按照表格的形式进行打印,共七列,其从左到右包含的信息分别是:
- Id:算子序号,是该算子在整个计划树中的唯一标识。
- Operation type:算子名称。
- Name:当前算子操作的存储对象名称,一般是表名/视图名/索引名等。
- Owner:当前算子操作对象所属的用户。
- Rows:当前算子执行的条数,该数据为优化器根据语句综合当前统计信息所预估的。
- Cost:计划树执行到当前算子所需的代价(总时长)。
- Partition info:当计划树中有对分区表的操作时,将会在这一列显式分区的扫描方案。
YashanDB的计划是按照树形结构来进行连接的,整体对外的形式则是一颗多叉树,执行方式是从根节点开始的先深度后广度的后序遍历。
树形结构的父节点与子节点则是通过缩进来表示,处于同一缩进等级下的算子表示拥有相同的父节点,图中序号3和4的算子缩进相同,是序号2哈希连接的子节点。
对于不同的连接方式来说,上下两个孩子的含义也不相同,YashanDB当前支持哈希(Hash)连接,嵌套循环(Nested Loop)连接还有归并(Merge)连接,哈希连接中上方子节点是探查表(Probe),下方子节点是构建表(Build);而对于嵌套循环连接和归并连接来说,上方是左表,下方表示右表。
额外信息部分
最后一部分则是最下方标题为Operation Information的部分,该部分在不打开额外开关的情况下显示的是对应序号算子所包含的谓词信息、分组信息等。在这里重点介绍的则是filter(过滤谓词)和access(访问谓词)两个信息。
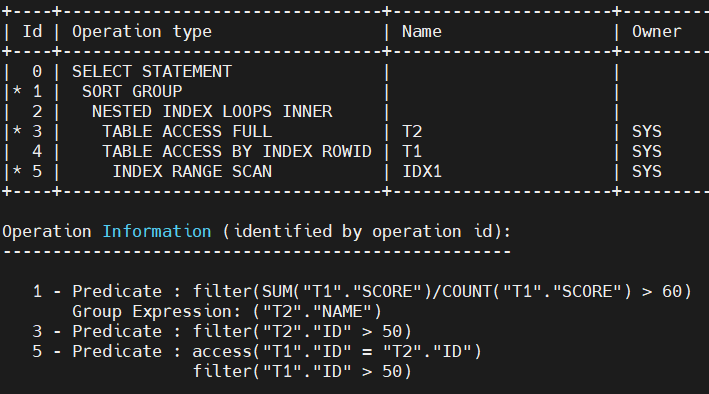
图 2:包含过滤与访问谓词的例子
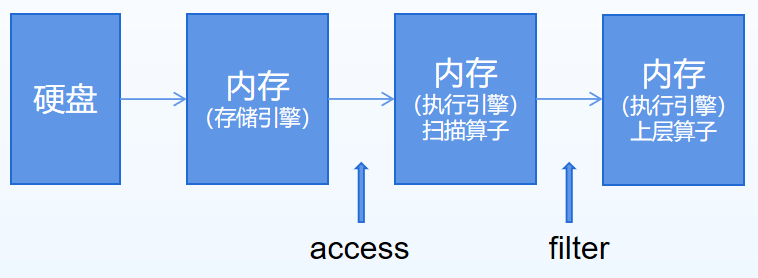
图 3:数据访问流程
根据上面的执行流程,我们可以较为简单地认为access与filter的区别如下:
- 某个算子上可能会同时出现access与filter两种谓词;
- access(访问谓词):是在某个算子从前一层获取数据时提前处理数据的谓词。用于数据被选出之前的检索,可减少不必要的数据传输和处理,提高效率;
- filter(过滤谓词):当某个算子获取到数据进入自身缓存区时,再检查数据是否满足条件的谓词。用于数据选出后的重新过滤,能进行更精细的筛选。
数据库的表连接操作可以认为是从两个表中各取出一条数据,将其拼接在一起。当表连接过程中有访问谓词,如图1中序号为2为例,T1.ID = T2.ID,可以近似地认为在数据连接之前,扫描的过程中就判断这两条数据是否满足了连接条件;而不是像嵌套循环连接那样,先将两边的数据拼合起来,再判断这条数据是否满足过滤条件。
总之,哈希连接通过提前使用访问谓词进行判断,可以避免不必要的数据拼合操作,提高连接操作的效率。
至此为止,我们计划上的一些基本信息就已经说明完了。
我们上面讲到的例子都是不包含子查询的语句,而子查询同样也是查询时出现频率非常高的语法成分。我们先看以下的语句:
例2:包含子查询
SELECT avg(score), name FROM t1 JOIN t2 ON t1.id = t2.id
WHERE t2.id > (SELECT subq_t1.id FROM t1 subq_t1 WHERE id = 50)
GROUP BY t2.name HAVING avg(score) > 60;其执行计划如下图所示:
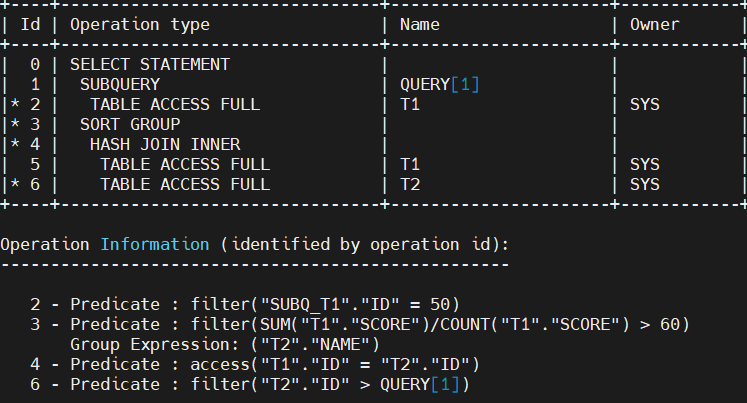
图 4:包含子查询的执行计划
在拿到含子查询的执行计划时,首先界定子查询计划范围。图中Name栏序号1的算子被标记为QUEYR[1],在YashanDB中主查询的查询序号为0,因此QUERY[1]算子即为子查询起始,到下一个同缩进算子(即序号 3 的 SORT GROUP)为止,即1-2号算子属于QUERY[1]的范围。此外下方算子信息中的QUERY[1],表示它将会在序号为6的TABLE ACCESS FULL上被执行。
YashanDB索引扫描方式
另外可能也有小伙伴们会对图2中的索引扫描方式感兴趣,在这里也稍微介绍一下YashanDB常见的扫描方式。
- TABLE ACCESS FULL:全表扫描,将表中数据全部扫描,不包含访问谓词。
- INDEX ACCESS FULL:全索引扫描,与全表扫描类似,扫描的对象变为索引,不包含访问谓词。
- INDEX FAST FULL SCAN:快速索引扫描,根据索引物理块相连进行扫描,返回数据无序,不包含访问谓词。
- INDEX UNIQUE SCAN:索引唯一值扫描,当索引为主键索引或唯一索引且访问条件为等值条件时,可以直接在索引上查询对应的位置,实现单点查询并返回。
- INDEX RANGE SCAN:索引范围查询,根据索引的有序性,只扫描满足条件的某一段范围内的数据,搭配访问谓词使用。
- INDEX SCAN MIN/MAX:索引最大/最小值扫描,YashanDB的普通索引按照B树形式进行构建,当在聚合查询需要查询最大或最小值时,可以直接访问索引的头节点或尾节点以直接得到该列的最大或最小值。
- INDEX SKIP SCAN:索引跳跃扫描,索引扫描中较为复杂的一种,下面结合场景进行说明。当有一个学校成员的表格,其中记录了某个学校里所有学生的信息,包括性别,年龄,年级,入学考试总分等,该表有且仅有一个索引index1,其建立在性别与入学考试总分这两项上。当DBA想查询入学考试总分在500 - 600分区间的所有学生列表时,按照索引结构来说,并不能直接使用index1来进行过滤,此时我们可以直接跳过index1的性别这一列,在性别这一列的每一个取值上,做一个 500 < 总分 < 600的过滤。即在性别为男与性别为女这两个子树上分别做500 < 总分 < 600的过滤。
- TABLE ACCESS BY INDEX ROWID:回表操作,严格来说属于任意索引扫描的一部分,当索引所能提供的列不完全满足上方算子要求时,索引需要根据自身ROWID信息,回到表中重新取得缺失的列数据,由于会产生更多的额外IO操作,因此在数据库应用中应当避免大数据量的回表。
在数据库调优的过程中,索引的建立与选择是对数据库性能影响大的环节,适合的索引与适合的索引扫描方式往往能带来性能上的质的提升。因此,数据库调优过程中需要平衡索引的使用,确保索引的创建和维护对性能的提升大于其带来的开销。正确的索引策略需要基于对查询模式、数据访问模式和业务需求的深入理解。
拓展功能:投影信息
投影信息为YashanDB计划打印的拓展功能。投影指的是上层算子从表或下方算子的结果集中选择特定的列(字段)来形成一个结果集,而不需要包括其他列。其使用方法为:在待打印的查询语句前加入如下关键字EXPLAIN PLAN SET PROJ ON FOR。
对例1的语句打开投影打印后可以得到如图5所展示的计划。
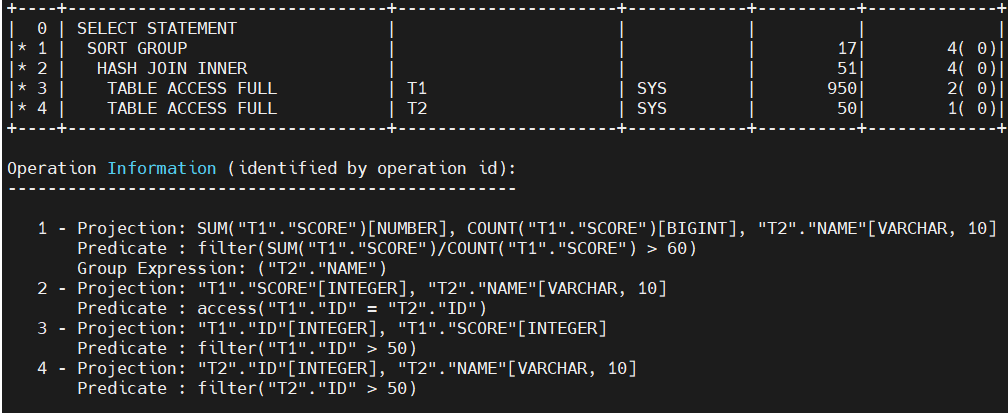
图 5:例1语句打开投影后的显示结果
在图中我们可以看到,正常情况下,两张两列的表进行连接后的结果应该是4列,而此处序号为2的哈希连接,其projection信息仅有T1.SCORE与T2.NAME两列,这是由于上层分组算子仅使用了这两列进行运算,因此传递给下层算子的需求也仅仅只是这两列。
这种投影优化后,可以看到join实际只需提供两列,当表列很多但实际用列较少时,上层算子无需在内存中记录不需要的表达式,可节省大量内存空间。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号