清华提出 Owl-1 全景世界模式:革新长视频生成,重塑视觉体验 !

清华提出 Owl-1 全景世界模式:革新长视频生成,重塑视觉体验 !

AIGC 先锋科技
发布于 2025-02-12 15:25:02
发布于 2025-02-12 15:25:02

视频生成模型(VGMs)近年来受到了广泛关注,并且被视为通用大视觉模型的有前途候选者。 尽管它们每次只能生成短视频,但现有方法通过多次调用VGMs并以上一轮的最后一帧作为下一轮生成的条件,实现了长视频生成。然而,最后一帧只包含了场景的短期细粒度信息,导致长时段内的一致性问题。 为解决这一问题,作者提出了一种全景世界模式(Owl-1),以产生长期一致和综合的条件,从而实现高质量的长视频生成。 由于视频是对底层不断演变世界的观察,作者提出在潜在空间中建模长期发展,并利用VGMs将这些发展记录成视频。 具体而言,作者将世界表示为一个潜在状态变量,该变量可以被解码为显式的视频观测。这些观测作为预测时空动态的基础,进而更新状态变量。 演化动力学与持久状态之间的交互增强了长视频的多样性和一致性。广泛的实验表明,Owl-1在VBench-I2V和VBench-Long上的性能与当前最佳方法相当,验证了其生成高质量视频观测的能力。 相关代码:https://github.com/huang-yh/owl。
1. Introduction
随着图像生成模型的成功,视频生成也逐渐引起了广泛关注。尽管现有的视频生成模型(VGMs)已经达到了商用 Level 的性能,但所生成的视频时长仍然较短。长视频生成方法通过改善生成视频的长度和一致性来解决这一问题,促进了诸如视频扩展[35]、电影生成[40]和世界模拟[24]等多种新兴任务的发展。
尽管视频应用前景广阔,如何在保持一致性的前提下增加视频长度仍是一个开放的问题。有几项研究[1, 43]探讨了三维变分自编码器(VAE),它能够在空间和时间两个维度上压缩视频,以生成单一去噪过程中由潜在扩散模型生成的长视频。尽管在扩散过程中固有的保证了视频的一致性,但生成的视频长度仍然受限于计算资源,进一步扩展视频长度需要重新训练扩散模型。另一些研究通过分而治之的方法进行长视频生成,首先生成长视频的关键帧,然后在连续的关键帧之间进行插值[11, 38]。
然而,这些方法依赖于训练视频数据的时长,因此缺乏可扩展性。此外,逐步 Prompt 视频扩散模型生成短片段也是一种生成长视频的有前景的方法[9, 13, 32]。为了确保一致性,这些方法在每次迭代中都会根据历史片段和文本设计其 Prompt 。但是,当前用于 Prompt 构建的做法通常使用直接相邻片段的最后一帧,这些帧只包含场景的短期信息,导致在长时间段内产生不一致性。
在本文中,作者提出了一种全方位世界模式(Owl1),用于生成长期连贯且全面的条件,以实现一致的长视频生成。由于视频是底层演变世界的观测结果,确立了视频的时间一致性,作者提出在潜在空间中建模长期发展,并使用VGM将其拍摄成视频。
具体而言,作者将世界表示为一个潜在状态变量,该变量编码了底层世界的当前和历史信息。类似于拍摄过程,状态变量通过VGM解码成视频片段,作为世界观测结果。基于这些观测结果,作者进一步预测未来世界动力学,从而驱动世界的发展并更新潜在状态变量。
截至目前,作者已经构建了一个自回归状态-观测动力学模型,以模拟世界的闭环演化,这有助于提高长视频的一致性与连贯性,并通过动力学预测增强内容多样性。为了有效地建模这三个组件之间的关系,作者采用了一个预训练的大型多模态模型(LMM),利用其泛化的推理能力。
此外,作者还采用了视频扩散模型来将潜在状态解码为短视频片段。Owl-1在VBench-I2V和VBench-Long上的性能与当前最先进的方法相当,验证了其生成高质量视频观测的能力。
2. Related Work
短视频生成。在计算机视觉领域,视频生成已经成为一个关键的研究方向,因其广泛的应用而受到了广泛关注。短视频生成研究的是如何基于文本(和/或图像)条件生成视频,其中生成的视频与给定条件的一致性是主要的评估标准之一。对于文本条件,大多数方法[3, 15, 35]使用预训练的文本编码器[22, 25]对其编码,并通过交叉注意力机制融合文本特征。此外,图像到视频模型要求生成的视频包含指定的图像条件。为了有效融合精细的视觉信息,一些方法[13, 43]直接替换或连接扩散特征与图像条件编码的特征。其他方法[35]则将图像条件转化为类似于文本特征的 Token ,并在扩散特征与图像 Token 之间应用交叉注意力,以保留较为粗略 Level 的细节,如视觉风格和背景。作者的Owl-1利用上一帧的潜在状态和可选的图像条件来实现下一帧的一致且平滑的生成。
长视频生成。作为视频生成模型应用范围的一个重要扩展,长视频生成致力于提高生成视频的长度和一致性。为了实现这一目标,一些研究尝试通过设计能够在单个生成过程中压缩较长视频的3D VAEs [1, 43],或通过在视频生成模型中调查时间模块以实现高效的生成 [35] 来增加视频的持续时间。尽管端到端的生成流水线本身能够保证视频的一致性,但由于计算资源有限,生成的视频长度仍然受到限制。为了解决这个问题,分而治之的方法首先识别出描述主要叙述的关键帧,然后生成中间帧以创建一个连贯的长视频。然而,这些方法依赖于长时间段训练视频数据,但这些数据仍然不足,因此缺乏可扩展性。
另一方面,时间自回归范式采用顺序方法基于先前条件生成短视频片段。在这一范式中,已经使用了多种模型,包括扩散模型[13, 32]、空间自回归模型[19]和GAN模型[30]。这里的关键挑战是确保时间上相隔较远的片段之间的一致性,以实现连贯的长视频生成。大多数研究直接使用上一生成片段的最后一帧作为下一轮生成的视觉线索,这些帧仅包含场景的短期信息,导致时间接受域有限且长期一致性不足。相比之下,作者的Owl-1利用潜状态变量编码当前及历史关于底层世界的信息,从而实现广泛的时间接受域和视频一致性。
视频生成世界模型。视频生成模型是用于世界模型[44]的有前途候选者,世界模型旨在模拟环境的演变。对于持续时间较短的视频,生成的内容可能反映某些物理规律[21],表明视频生成模型已经学习了一些关于世界的普遍知识。而对于更长的时间范围,视频生成世界模型的重点在于捕捉驱动环境演变的整体动力学[44]。尽管这类模型已经在自主驾驶[33, 42]和具身智能[5]领域提出,它们只能预测结构化的动作而不能以自然语言的形式预测一般的世界动力学。至于一般的视频生成,目前大多数现有方法专注于提高生成视频与给定文本条件的一致性,缺乏预见世界动力学的能力。除了条件视频生成,作者的Owl-1还能够预测未来动力学,从而生成包含多样化内容的长视频。
3. Proposed 1 Approach

3.1. Omni World Model

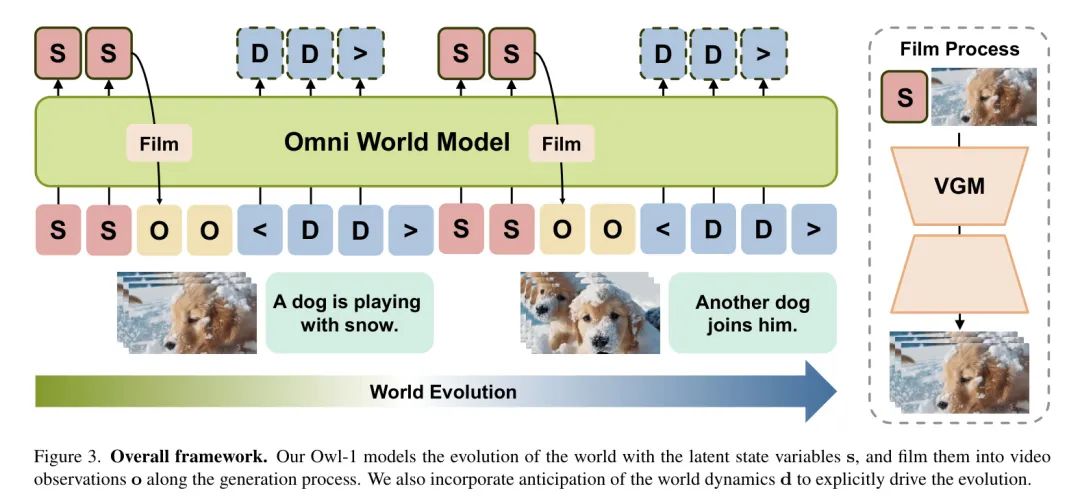
3.2. Comprehensive Condition from Latent State

3.3.Anticipation of Future Dynamics

3.4.Multi-Stage Training
在作者的Owl1的训练过程中存在几个挑战:

4. Experiments
4.1.Datasets and Benchmarks
通用视频生成数据集。作者在前两个训练阶段使用了两个通用视频生成数据集。WebVid 数据集 [1] 包含超过 1000 万条配有字幕的视频,总共约有 52000 小时的影像资料。这个大规模的文字-视频数据集涵盖了多个领域的多样化内容,非常适合用于视频-文本检索和视频生成等任务。作者从中随机选取了大约 400000 条视频。Panda70m 数据集 [8] 则包含了 7 亿条平均时长为 8 秒的视频及其高质量的自动字幕,这些字幕是通过利用多模态输入和多种跨模态教师模型的自动字幕 Pipeline 生成的。作者从该数据集中随机选取了 2000000 条视频。
密集视频字幕数据集。由于缺乏专门针对驱动视频进展动力的数据集,作者使用密集视频字幕数据集作为替代方案。ActivityNet Captions 数据集 [6] 包含 20,000 条 YouTube 视频和 100,000 个字幕标注,平均长度为 120 秒。大多数视频包含超过三个标注事件,每个事件都与相应的时长段和手动撰写的句子相关联,平均每条标注包含 13.5 个单词。Vript 数据集 [36] 是一个大规模、细粒度的视频-文本数据集,包括 12,000 条高分辨率视频和超过 400,000 个片段,这些片段以视频脚本的形式密集标注。视频片段和字幕的平均长度分别为 11 秒和 145 词。作者将使用这两个数据集的训练分割。
VBench. VBench [17] 是一个全面且分层的基准框架,将视频生成质量分解为16个具体的且分离的维度,例如主体身份不一致性、运动平滑度、时间闪烁和空间关系等,每个维度都配备有定制化的 Prompt 信息和评估方法。VBench 具备三个关键特性:全面覆盖各种视频生成方面、与人类感知相一致以及对不同维度和内容下当前模型性能的洞察。
4.2. Implementation Details
作者使用Chameleon模型[31]作为大语言模型,使用DynamiCrafter-1024[35]作为视频扩散模型。对于可训练参数,作者使用LoRA [16]对大语言模型进行微调,并对视频扩散模型的所有参数进行微调。对于视频分割,作者将每一视频分割成4秒的等长片段作为观察值,并从每个片段中抽取2帧作为大语言模型的输入。作者将可学习状态 Query 的长度设为128。在对齐和生成预训练阶段,作者在WebVid和Panda10m数据集中分别进行了10000次和10000次迭代的训练,共涉及240万条视频。在世界模型训练阶段,作者在ActivityNet Captions和Vript数据集中进行了1000次步骤的训练,共涉及2万条视频。
4.3. General Video Generation
作者使用Owl-1在VBench [17] 的两个基准上进行了评估,分别是VBench-I2V和VBench-Long,以测试其生成短视频和长视频的能力。作者在表1中报告了VBench-I2V的结果,在该基准上作者生成了2秒的短视频。作者的Owl-1在短视频生成方面的性能与当前最先进的方法相当,并且在运动流畅性、背景一致性以及时间闪烁方面表现尤为出色。这表明状态解码机制的有效性,它能够将潜在的状态变量编码为显式的视频观察。然而,作者确实观察到动态程度得分比DynamiCrafter有所下降,作者认为这是由于缺少高运动水平的训练视频数据所致。
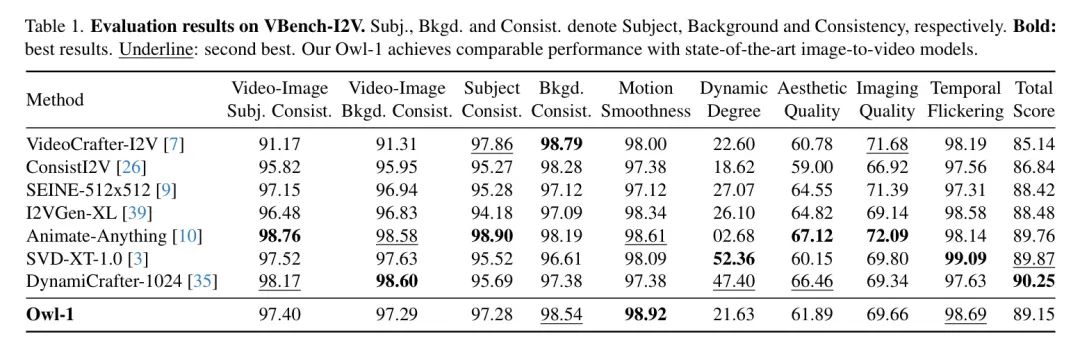
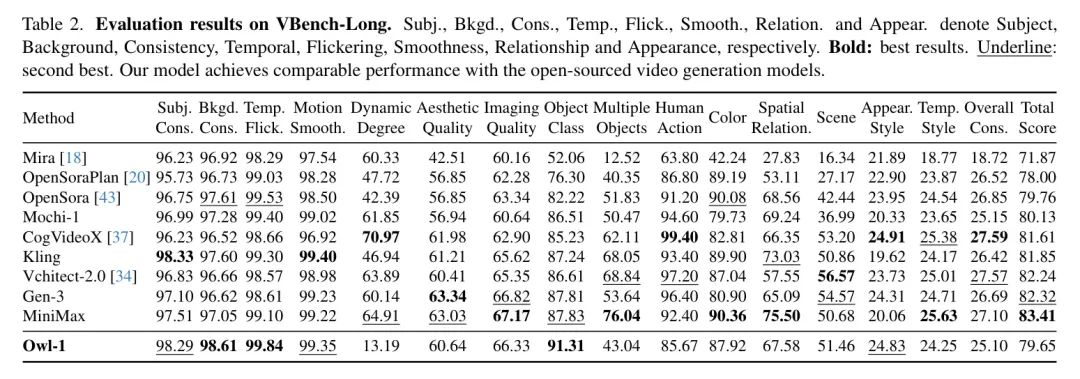
作者在表2中报告了在VBench-Long上的实验结果,作者生成了长度为7秒的视频,与其它方法类似。由于作者使用的视频扩散模型DynamiCrafter需要同时输入一张图片和一段文本描述来生成第一个片段,因此作者采用SD2.1-v [27] 图像扩散模型,从给定的文字 Prompt 生成视频的第一个帧。作者的模型在该基准测试上实现了与开源视频生成模型(例如OpenSora)相当的性能。与VBench-I2V的结果类似,作者的Owl-1在主题和背景一致性、时间闪烁以及动作流畅性方面表现更佳,但其动态程度低于其他方法,通过进一步使用更高动作水平的视频进行训练可以改进这一点。
作者在图4中可视化了Owl-1生成的视频。每个生成的视频持续时间为8秒,并且作者从每一个视频中均匀抽取了5帧。Owl-1能够生成涵盖人类动作、动物、自然景观等多种主题的全面而真实的视频。虽然在生成这些视频时作者并没有预测世界动力学,但时间一致性依然非常好,展示了作者基于状态变量提出的条件视频生成方法的有效性。图4的第二行捕捉到了男子面部的细微特征,验证了作者模型生成高分辨率视频的能力。
4.4.World Model BasedVideoGeneration
鉴于当前缺乏评估视频生成中世界模型的标准基准,作者通过定性方法评估了作者模型的能力。作者在图5中提供了生成长视频的可视化结果。对于每个 Prompt ,作者生成了3个场景,并从每个场景中抽取2帧。每个场景持续8秒钟,整个视频时长为24秒。在从一个场景过渡到另一个场景时,作者手动丢弃了最后一个场景的最后一帧中的图像条件,仅依赖于潜在状态变量作为生成条件,这极具挑战性,因为潜在状态必须包含前一视频片段的风格和上下文信息,以便以一致的方式生成下一个片段。观察结果显示,Owl-1能够生成具有合理动态预测的长期视频。第四行的视频显示了一名园丁正在使用工具修剪树枝。作者生成的视频最初关注了他的手部动作,随后展示了整体修剪效果,体现了某种逻辑。这反映了对世界演变的建模与预测。然而,作者注意到预测的动态行为存在一定的重复性,作者推测这是由于训练视频数据中的密集字幕本身具有的重复性所致。即便如此,Owl-1生成的视频在不同场景中仍保持较好的一致性。

5. Conclusion
在本文中,作者提出了一种全方位世界模型(Owl-1),用于一致的长视频生成。作者的Owl-1从世界模型的角度来解决这个问题,通过一系列状态变量来建模世界的演变。
作者引入了一个闭环的状态-观测-动力学三元组,在这个三元组中,潜在状态编码了世界的当前和历史信息,并作为视频生成的全面长期条件。随后,通过视频扩散模型从潜在状态变量中解码显式的视频观测。
为了驱动世界演变,在生成过程中融入了对世界动力学的预测,这有助于生成内容的多样性。此外,作者为Owl-1设计了一个有效的多阶段训练方案,利用了大量的短视频数据,并只在少量反映世界演变的长视频数据上进行微调。
实验结果显示,Owl-1在生成长且一致的视频方面表现出色。可视化结果进一步验证了Owl-1捕捉细粒度细节并生成具有合理动力学预测的视频的能力。
参考
[0]. Owl-1: Omni World Model for Consistent Long Video Generation .
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-10,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号