每日学术速递2.10


CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Power by Kimi&苏神 编辑丨AiCharm
点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
1.Seeing World Dynamics in a Nutshell

标题:简要了解世界动态
作者:Qiuhong Shen, Xuanyu Yi, Mingbao Lin, Hanwang Zhang, Shuicheng Yan, Xinchao Wang
文章链接:https://arxiv.org/abs/2502.03465
项目代码:https://github.com/Nut-World/NutWorld

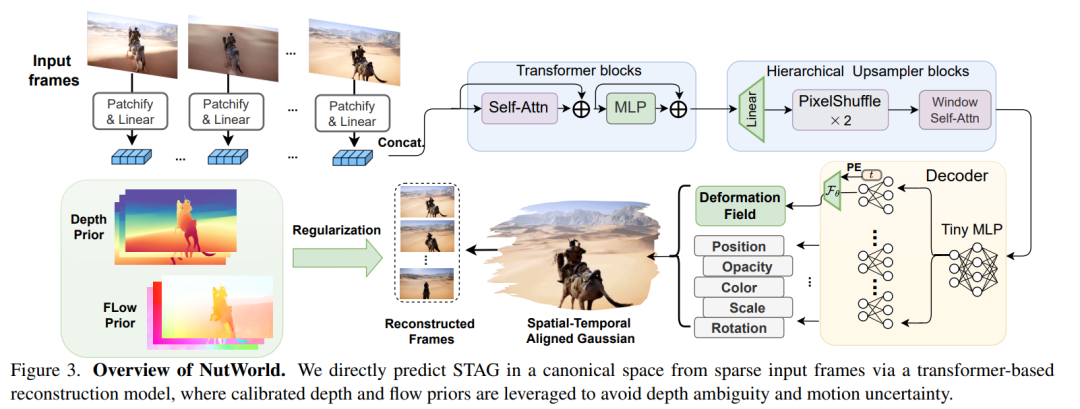



摘要:
我们考虑了以空间和时间相干的方式有效地表示随意捕获的单目视频的问题。虽然现有方法主要依赖于 2D/2.5D 技术,将视频视为时空像素的集合,但由于缺乏时间连贯性和明确的 3D 结构,它们难以处理复杂的运动、遮挡和几何一致性。从单目视频中汲取灵感,作为动态 3D 世界的投影,我们探索通过时空中高斯基元的连续流动来表示视频的内在 3D 形式。在本文中,我们提出了 NutWorld,这是一种新颖的框架,可以在单次前向传递中有效地将单目视频转换为动态 3D 高斯表示。NutWorld 的核心引入了结构化的时空对齐高斯 (STAG) 表示,实现了具有有效深度和流正则化的无优化场景建模。通过全面的实验,我们证明了 NutWorld 实现了高保真视频重建质量,同时实时支持各种下游应用。演示和代码将在此 https URL 上提供。
这篇论文试图解决什么问题?
这篇论文试图解决如何高效地表示随意捕获的单目视频(monocular videos)中的动态场景的问题。具体来说,论文关注以下几个关键问题:
- 空间和时间一致性:现有方法主要依赖于2D/2.5D技术,将视频视为时空像素的集合,这些方法在处理复杂运动、遮挡和几何一致性方面存在困难,因为它们缺乏时间连贯性和明确的3D结构。
- 动态场景表示:论文探索将视频表示为其内在的3D形式,即通过在时空中连续流动的高斯(Gaussian)原素来表示。
- 单目视频中的挑战:随意捕获的单目视频缺乏用于动态场景重建的精确相机位姿,这使得现有方法难以分离相机运动和场景动态,导致渲染质量下降甚至重建失败。
- 非结构化性质和空间歧义:大多数现有的动态高斯绘制方法依赖于每场景优化的变形网络或每帧高斯生成,这与论文提出的前馈预测范式不兼容。此外,高斯原素的空间非结构化特性使它们在逆向渲染中容易陷入局部最小值,阻碍了动态3D场景的前馈建模。
为了解决这些问题,论文提出了一个名为NutWorld的框架,该框架能够在单次前向传递中将单目视频有效地转换为动态3D高斯表示,通过引入结构化时空对齐的高斯(STAG)表示,实现了无需优化的场景建模,并有效实现了深度和流的正则化。通过大规模预训练,NutWorld能够处理任意长度的视频,同时保持时空一致性。
论文如何解决这个问题?
论文通过提出一个名为NutWorld的框架来解决高效表示随意捕获的单目视频的问题。NutWorld框架通过以下几个关键组件来解决上述挑战:
1. 结构化时空对齐高斯(STAG)表示
- 规范空间:使用正交相机坐标系替代绝对3D世界坐标系,消除了显式相机姿态估计的需要,并在统一的规范空间中对相机和对象运动进行建模,避免了尺度歧义。
- STAG定义:STAG将每个动态高斯约束到特定的像素位置和时间戳,与之前预测无约束高斯的方法不同。STAG通过像素对齐的方式解码高维像素到3D高斯,并与相应的变形场在渲染时结合。
2. 优化自由的流水线
- 基于Transformer的网络:该网络将视频帧映射到STAG表示,无需显式的位置嵌入,因为深度坐标已经编码了空间信息。
- 层次上采样网络:逐步扩展编码特征的空间分辨率,生成更高分辨率的特征图。
- STAG解码器:从上采样的特征图中预测静态高斯属性及其可变形场。
3. 深度和流的校准2D先验正则化
- 深度正则化:使用尺度和位移不变损失来对齐渲染深度和估计的伪深度,使模型对场景中的相对深度进行有效预测。
- 光流正则化:利用全局STAG轨迹,通过与预计算的光流场之间的关联,确保在单次前向传递中保持一致的运动。
4. 训练和推理
- 整体目标:结合MSE损失、光流正则化和深度正则化来训练模型。
- 长视频段处理:通过将输入视频分割成重叠的段,并在相邻段之间共享一帧,实现长视频的推理,保持时空一致性。
通过这些方法,NutWorld框架能够将单目视频有效地转换为动态高斯绘制表示,同时保持高保真视频重建质量,并实现实时推理速度。此外,该框架还支持多种下游视频应用,包括新视角合成、一致性深度估计、视频分割、视频编辑和帧插值,展示了其作为通用视频表示框架的潜力。
论文做了哪些实验?
论文中进行了一系列实验来验证NutWorld框架的有效性,包括视频重建和多种下游任务。以下是实验的具体内容:
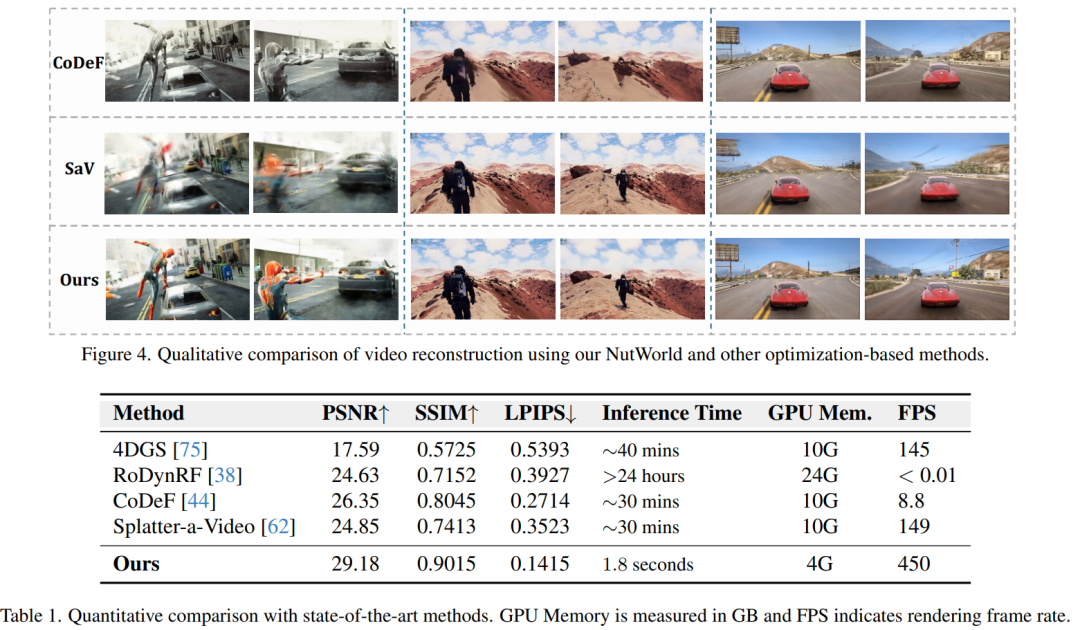
1. 视频重建
- 实验设置:使用MiraData和RealEstate10K数据集进行预训练,随机选择50个测试视频片段进行评估。
- 质量指标:使用PSNR、SSIM和LPIPS等标准重建质量指标进行评估。
- 比较基线方法:与现有的优化方法进行比较,包括Splatter-a-Video (SaV)、4DGS、RoDynRF和CoDeF等。
- 定性与定量结果:NutWorld在视频重建质量上优于比较方法,同时在计算效率上有显著提升。
2. 下游任务
- 视频对象分割:利用STAG的显式性质进行对象分割,无需特定任务训练。
- 帧插值:利用STAG的连续轨迹进行场景动态的任意帧率插值。
- 一致性深度预测:通过校准的深度正则化防止深度崩溃,保持场景几何的一致性。
- 视频编辑:结合MLLM引导的编辑模型,实现精确的帧级编辑。
- 新视角合成:通过深度先验减少空间歧义,实现新视角渲染。
3. 消融研究
- STAG表示:通过放宽STAG的位置约束来验证其有效性。
- 深度先验:评估没有深度监督时模型的性能变化。
- 光流先验:评估没有光流监督时模型的运动一致性。
4. 训练和推理
- 训练目标:结合MSE损失、光流正则化和深度正则化进行训练。
- 长视频推理:采用基于段的推理策略处理长视频,保持时空一致性。
这些实验结果表明,NutWorld不仅在视频重建方面达到了高保真度,而且在多种下游任务中展现了良好的适用性和适应性,验证了其作为一个通用视频表示框架的潜力。
论文的主要内容:
这篇论文提出了一个名为NutWorld的新型框架,旨在高效地表示随意捕获的单目视频,并保持空间和时间上的连贯性。以下是论文的主要内容总结:
- 问题定义:论文考虑了如何将日常拍摄的单目视频以空间和时间上连贯的方式进行有效表示的问题。现有的方法主要依赖于2D/2.5D技术,这些技术在处理复杂动态场景时存在挑战,尤其是在面对遮挡和非刚性形变时。
- NutWorld框架:提出了NutWorld框架,它能够将单目视频转换为动态3D高斯表示,仅需单次前向传递。该框架核心是结构化时空对齐的高斯(STAG)表示,它允许无需优化的场景建模,并有效实现了深度和流的正则化。
- STAG表示:STAG表示通过在规范空间中对每个动态高斯约束到特定像素位置和时间戳,解决了高斯绘制中的非结构化问题,并提供了显式的空间和时间对应关系。
- 网络架构:介绍了基于Transformer的网络架构,该架构能够将输入视频帧映射到STAG表示,并通过层次上采样网络和STAG解码器预测高斯属性和变形场。
- 正则化策略:利用校准的深度和光流先验来解决单目视频中的深度歧义和运动不确定性问题,通过深度和光流正则化来训练模型。
- 实验验证:通过在RealEstate10K和MiraData数据集上的实验,验证了NutWorld在视频重建质量上的高保真度,并展示了其在多种下游任务中的应用潜力,包括视频对象分割、帧插值、视频编辑和新视角合成。
- 消融研究:通过消融实验验证了STAG表示、深度先验和光流先验对模型性能的贡献,并证明了这些组件对维持视频重建质量的重要性。
- 结论与未来方向:论文总结了NutWorld框架的主要贡献,并提出了未来可能的研究方向,包括集成更丰富的视觉特征和适应视频生成任务。
总体而言,NutWorld框架通过其创新的STAG表示和有效的正则化策略,在单目视频的动态场景表示方面取得了显著的性能,展示了作为通用视频表示框架的潜力。
2.SKI Models: Skeleton Induced Vision-Language Embeddings for Understanding Activities of Daily Living
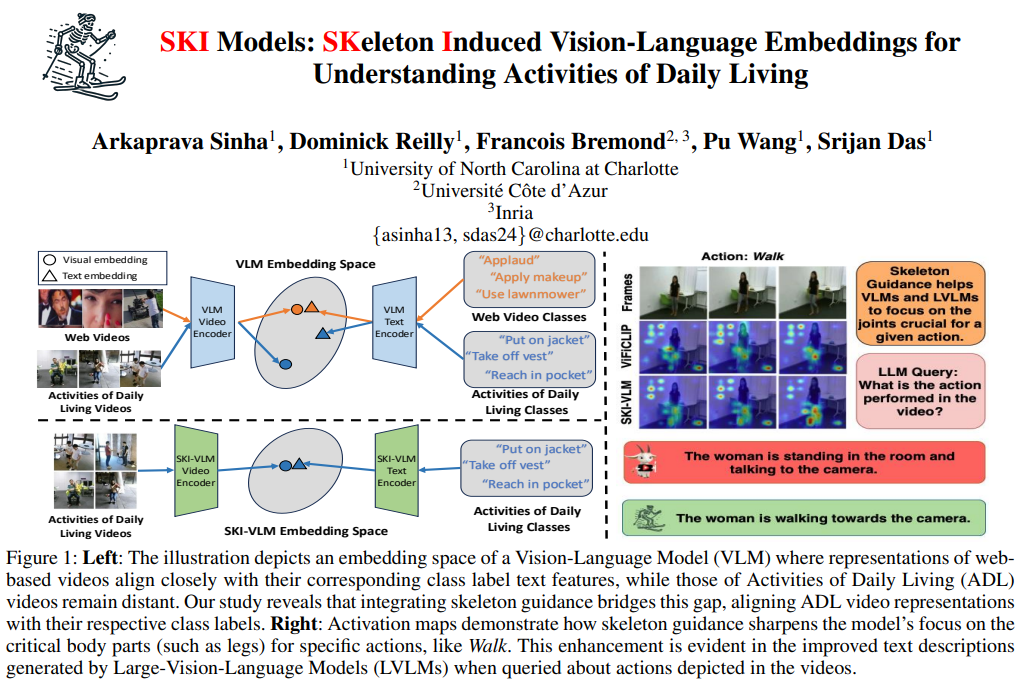
标题: SKI 模型:用于理解日常生活活动的骨骼诱导视觉语言嵌入
作者: Arkaprava Sinha, Dominick Reilly, Francois Bremond, Pu Wang, Srijan Das
文章链接:https://arxiv.org/pdf/2502.03459
摘要:
CLIP 等视觉语言模型的引入使基础视频模型的开发成为可能,这些模型能够推广到看不见的视频和人类动作。然而,这些模型通常是在 Web 视频上训练的,这些视频通常无法捕捉日常生活活动 (ADL) 视频中存在的挑战。现有作品通过结合 3D 骨架和 RGB 视频,解决了 ADL 特有的挑战,例如相似的外观、微妙的运动模式和多个视点。但是,这些方法没有与语言集成,从而限制了它们推广到看不见的动作类的能力。在本文中,我们介绍了 SKI 模型,它将 3D 骨骼集成到视觉语言嵌入空间中。SKI 模型利用骨架语言模型 SkeletonCLIP 通过协作训练将骨架信息注入视觉语言模型 (VLM) 和大型视觉语言模型 (LVLM)。值得注意的是,SKI 模型在推理过程中不需要骨架数据,从而提高了它们在实际应用中的稳健性。SKI 模型的有效性在三个流行的 ADL 数据集上进行了验证,用于零镜头动作识别和视频字幕生成任务。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是如何将3D骨架信息有效地整合到视觉-语言(Vision-Language)模型中,以提高对日常活动(Activities of Daily Living, ADL)视频的理解。具体来说,论文中提到了几个关键问题:
- 现有视觉-语言模型的局限性:现有的视觉-语言模型,如CLIP,主要在网络视频上进行训练,这些视频通常包含明显的动作和外观特征。然而,这些模型在处理ADL视频时面临挑战,因为ADL视频涉及的动作外观相似、动作模式微妙,并且可能从多个视角捕捉。这些特点限制了这些模型对ADL视频的泛化能力。
- 结合3D骨架和RGB视频的方法:为了解决ADL视频的特定挑战,如相似的外观、微妙的运动模式和多个视点,以往的研究通过结合3D骨架和RGB视频来解决。但这些方法没有与语言信息整合,限制了它们对未见动作类别的泛化能力。
- 零样本学习(Zero-shot Learning)的挑战:如何将3D骨架信息引入到视觉-语言嵌入空间中,以便在零样本学习中有效地识别ADL,是一个关键问题。零样本学习对于监控系统来说至关重要,因为它们需要检测出指示认知衰退的异常人体动作。
为了解决这些问题,论文提出了SKI(Skeleton Induced)模型,这些模型通过一个称为SkeletonCLIP的骨架-语言模型将3D骨架信息整合到视觉语言模型(VLMs)和大型视觉语言模型(LVLMs)中。SKI模型不需要在推理阶段使用骨架数据,增强了它们在现实世界应用中的鲁棒性。
论文如何解决这个问题?
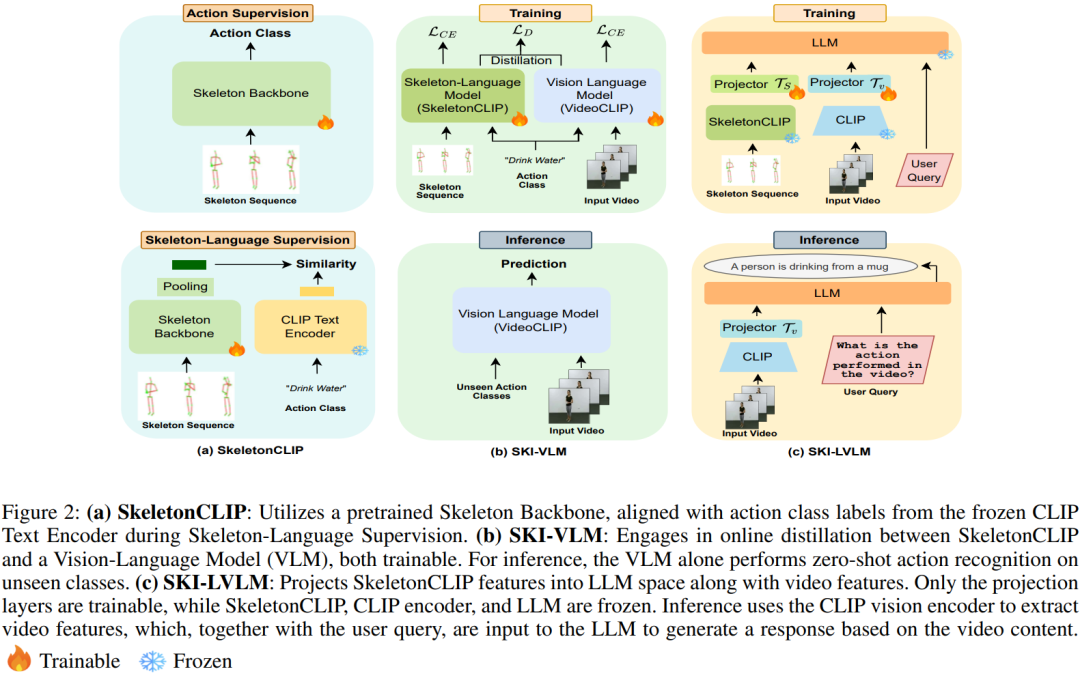
文通过提出SKI(Skeleton Induced)模型解决了将3D骨架信息整合到视觉-语言模型中的问题,具体方法如下:
- SkeletonCLIP模型:
- 引入一个骨架-语言模型,SkeletonCLIP,它通过联合学习3D骨架和语言表示来对齐这两种模态。
- SkeletonCLIP包含一个骨架编码器和一个文本编码器,利用预训练的CLIP文本编码器来平衡大规模骨架序列数据的有限性。
- SKI-VLM(Skeleton Induced VLM):
- 通过SkeletonCLIP蒸馏(SCD)策略将SkeletonCLIP整合到VLM中,从而将3D骨架信息融入VLM的嵌入空间。
- 在训练阶段,SKI-VLM使用在线知识蒸馏方法,同时训练SkeletonCLIP和VLM,以最小化模态特定特征和文本特征之间的相似性。
- 在推理阶段,仅使用VLM,不需要骨架数据,降低了计算开销。
- SKI-LVLM(Skeleton Induced LVLM):
- 将SkeletonCLIP特征作为额外的模态整合到大型视觉语言模型(LVLMs)中,增强其对视频数据中细微和复杂动作的解释能力。
- 使用投影层将视觉和骨架特征映射到大型语言模型(LLMs)的输入空间。
- 在训练时,仅训练投影层,而在推理时,仅使用视觉输入,避免了骨架数据的需求。
- 实验验证:
- 在三个流行的ADL数据集上验证SKI模型的有效性,包括零样本动作识别和视频描述生成任务。
- 展示了SKI-VLM在NTU60和NTU120数据集上的性能,并评估SKI-LVLM在Charades数据集上生成文本描述的能力。
通过上述方法,论文成功地将3D骨架信息整合到了视觉-语言模型中,提高了模型对ADL视频的理解和零样本学习的能力,同时在实际应用中避免了骨架数据的需求,增强了模型的实用性和鲁棒性。
论文做了哪些实验?
论文中进行了一系列实验来验证SKI模型的有效性,具体实验包括:
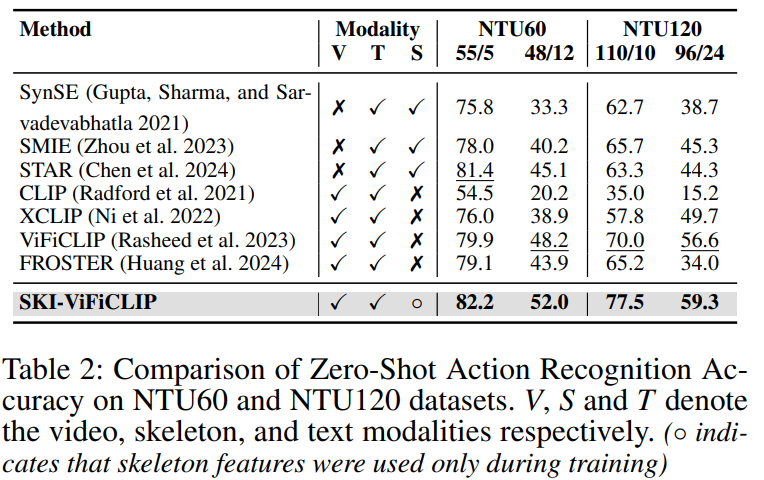
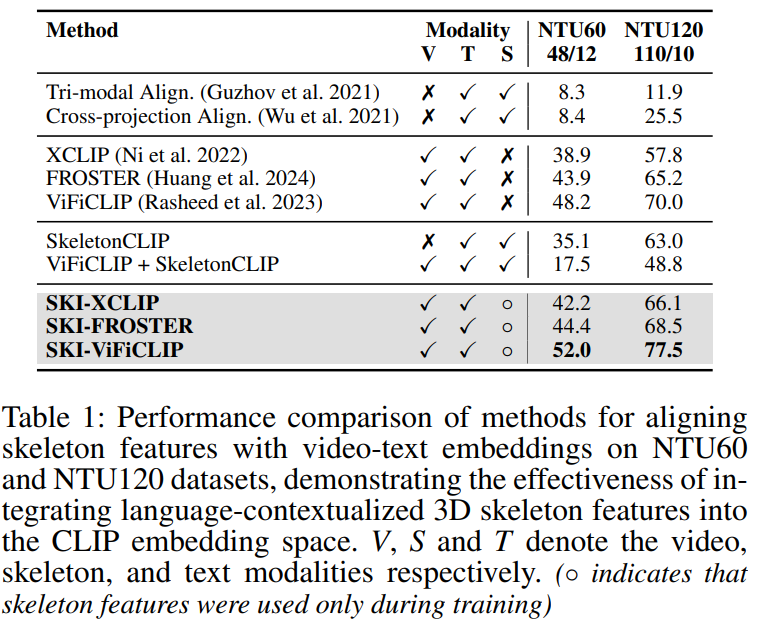
- 零样本动作识别(Zero-Shot Action Recognition):
- 在大规模的NTU-RGB+D-60 (NTU60) 和 NTU-RGB+D-120 (NTU120) 数据集上评估SKI-VLMs的性能。
- 这些数据集包含多个动作类别的视频-姿态对,用于测试模型在未见类别上的动作识别能力。
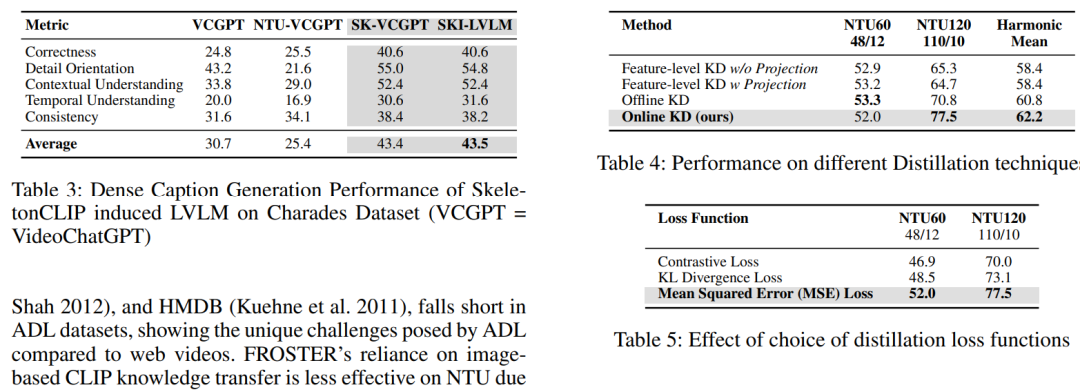
- 视频描述生成(Dense Video Captioning):
- 在Charades数据集上评估SKI-LVLM的视频描述生成能力,使用Llama 3.1模型根据五个指标进行评估:信息正确性、细节导向、上下文理解、时间理解和一致性。
- 不同蒸馏技术的性能比较:
- 对比了不同知识蒸馏(KD)策略,包括特征级KD、离线KD和在线KD(即论文提出的SCD方法)。
- 不同蒸馏损失函数的效果:
- 研究了不同蒸馏损失函数对SKI-VLM性能的影响,包括对比损失、KL散度损失和均方误差(MSE)损失。
- SkeletonCLIP文本编码器的影响:
- 考察了SkeletonCLIP文本编码器是可训练的还是冻结的对SKI-VLM性能的影响。
- 预训练策略的验证:
- 通过不同场景下的实验(无预训练、仅SkeletonCLIP预训练、仅ViFiCLIP预训练以及两者都预训练)来验证预训练策略的有效性。
- 注意力图可视化:
- 对比了ViFiCLIP和SKI-VLM在NTU数据集上的动作关注图,展示了SKI-VLM如何更精确地关注视频中的关键人体部位。
这些实验全面评估了SKI模型在不同方面的表现,包括动作识别的准确性、视频描述的质量以及模型的泛化能力。通过这些实验,论文证明了将3D骨架信息整合到视觉-语言模型中可以显著提高模型对ADL视频的理解和零样本学习的能力。
论文的主要内容:
论文的主要内容可以总结如下:
- 问题陈述:
- 论文指出,现有的视觉-语言模型(如CLIP)在处理日常活动(ADL)视频时存在泛化能力不足的问题,因为这些视频的动作外观相似、动作模式微妙,并且可能从多个视角捕捉,这限制了模型的“泛化性”。
- SKI模型介绍:
- 论文提出了SKI(Skeleton Induced)模型,包括SKI-VLM和SKI-LVLM,通过整合3D骨架信息到视觉-语言嵌入空间来提高对ADL视频的理解和零样本学习的能力。
- SkeletonCLIP模型:
- 引入了一个骨架-语言模型SkeletonCLIP,它通过联合学习3D骨架和语言表示来对齐这两种模态,为将骨架信息整合到VLM和LVLM提供了基础。
- SKI-VLM模型:
- 通过SkeletonCLIP蒸馏(SCD)策略将SkeletonCLIP整合到VLM中,实现了3D骨架信息与视觉-语言嵌入空间的融合,增强了VLM对ADL视频的理解能力。
- SKI-LVLM模型:
- 将SkeletonCLIP特征作为额外的模态整合到大型视觉语言模型(LVLMs)中,增强了模型对视频数据中细微和复杂动作的解释能力。
- 实验验证:
- 在NTU60和NTU120数据集上验证了SKI-VLM在零样本动作识别任务上的性能,并在Charades数据集上评估了SKI-LVLM的视频描述生成能力,证明了SKI模型的有效性。
- 贡献总结:
- 提出了一种新的方法来整合骨架信息到视觉-语言模型中,增强了模型对ADL视频的理解和零样本学习的能力,为构建多模态基础模型提供了新的视角。
- 未来工作:
- 论文提出了未来可能的研究方向,包括进一步探索不同骨架-语言模型的集成、提高模型泛化能力、优化计算效率等。
总体而言,论文通过引入SKI模型,为视觉-语言模型在处理ADL视频任务中面临的挑战提供了一种创新的解决方案,并通过实验验证了其有效性。
3.Dress-1-to-3: Single Image to Simulation-Ready 3D Outfit with Diffusion Prior and Differentiable Physics

标题: Dress-1-to-3:具有扩散先验和可微分物理场的单张图像到仿真就绪的 3D 装备
作者:Xuan Li, Chang Yu, Wenxin Du, Ying Jiang, Tianyi Xie, Yunuo Chen, Yin Yang, Chenfanfu Jiang
文章链接:https://arxiv.org/abs/2502.03449
项目代码:https://dress-1-to-3.github.io/





摘要:
大型模型的最新进展显著推动了图像到 3D 重建的发展。但是,生成的模型通常融合成一个整体,这限制了它们在下游任务中的适用性。本文重点介绍 3D 服装生成,这是具有动态服装动画的虚拟试穿等应用的关键领域,这些应用要求服装可分离且可用于模拟。我们介绍了 Dress-1-to-3,这是一种新颖的管道,可从野外图像中重建具有缝纫图案和人类的物理合理、模拟就绪的分离服装。从图像开始,我们的方法将用于创建粗缝纫图案的预训练图像到缝纫图案生成模型与用于生成多视图图像的预训练多视图扩散模型相结合。使用基于生成的多视图图像的可区分服装模拟器进一步完善缝纫图案。多功能实验表明,我们的优化方法大大增强了重建的 3D 服装与输入图像的人体的几何对齐。此外,通过集成纹理生成模块和人体动作生成模块,我们制作了定制的物理合理且逼真的动态服装演示。
这篇论文试图解决什么问题?
这篇论文试图解决的主要问题是从单视图图像中重建出模拟就绪(simulation-ready)的3D服装和人物模型。具体来说,论文关注于3D服装生成领域,旨在实现以下目标:
- 从单张图片生成可分离的服装和人物模型:现有技术通常将服装和人物模型融合为一个整体,限制了其在下游任务(如虚拟试穿和动态服装动画)中的应用。论文提出的Dress-1-to-3流程能够从随意姿势的单视图图像中重建出物理上合理的、可分离的服装和人物模型。
- 优化服装图案(sewing patterns)和人物姿态:通过结合预训练的图像到缝纫图案生成模型和多视图扩散模型,论文方法能够创建出与输入图像几何对齐的3D服装和人物模型。
- 生成具有物理参数的模拟就绪服装:通过一个可微分的服装模拟器优化服装图案和缝合线,生成具有物理材料参数的服装,这些参数能够与2D观测结果对齐。
- 提高重建质量和多样性:论文提出的方法能够重建出训练数据分布之外的服装形状,并且能够生成细节丰富、多样化的服装重建结果,反映现实世界中的服装变化。
总的来说,这项工作的目标是创建一个从单张图片到模拟就绪3D服装的端到端流程,这个流程不仅能够生成与输入图像对齐的高质量3D服装,还能够生成相应的纹理和动态展示,这对于虚拟现实、电影行业、时尚设计和游戏等领域具有重要意义。
论文如何解决这个问题?
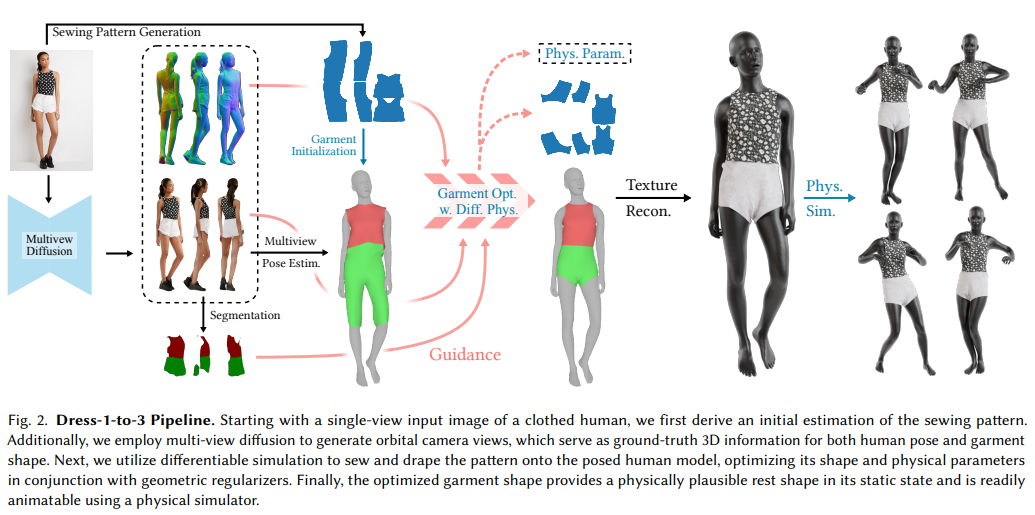
论文通过提出一个名为Dress-1-to-3的新颖流程来解决从单视图图像中重建出模拟就绪的3D服装和人物模型的问题。这个流程涵盖了以下几个关键步骤:
1. 预优化步骤(Pre-optimization Steps)
- 服装图案生成(Sewing Pattern Generation): 使用预训练的SewFormer模型从单视图图像生成初始的服装缝纫图案。
- 多视图图像生成(Multi-view Image Generation): 利用多视图扩散模型MagicMan生成一致的多视图RGB图像和对应的法线图,作为后续重建步骤中人体姿态和服装形状的真值数据。
- 人体姿态估计(Human Body Reconstruction): 使用SMPL-X模型和OSX算法从输入的单视图图像获得初步的人体姿态和形状估计,并通过多视图图像进行优化。
- 服装初始化(Garment Initialization): 将生成的2D图案缝合并铺设到预测的人体模型上,初始化3D服装。
2. 服装优化(Garment Optimization)
- 优化概述(Optimization Overview): 迭代微调缝纫图案参数,使静态铺设在姿势人体模型上的服装与所有视图中的多视图图像匹配。
- 渲染损失(Rendering Losses): 使用服装掩模损失、RGB损失和法线渲染损失来优化服装的几何形状和外观。
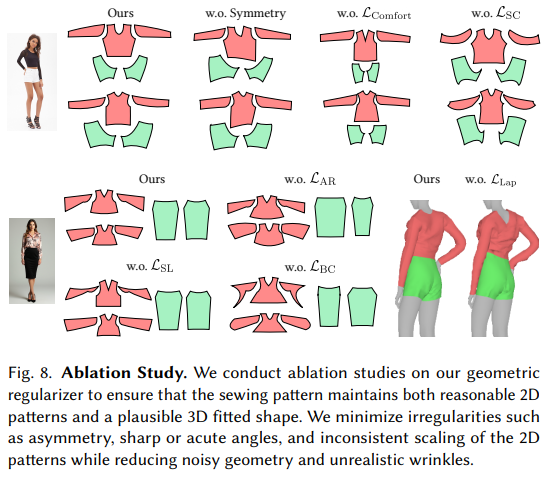
- 几何正则化(Geometric Regularizers): 引入多个几何损失来正则化缝纫图案优化,包括面积比损失、边界角正则化、舒适损失、拉普拉斯损失和接缝损失。
- 后迭代处理(Post-Iteration Processing): 在每次迭代后执行一些处理,如优化负三角形面积以防止三角形翻转。
- 重新网格化(Remeshing): 在优化迭代中自动重新网格化,以解决因大变形导致的网格质量下降问题。
3. 后优化步骤(Post-optimization Steps)
- 纹理生成(Texture Generation): 使用视觉语言模型和图像扩散技术自动生成服装纹理。
- 服装模拟(Showcase under Human Motions): 使用CIPC物理仿真器模拟穿着优化后服装的人物动态场景。
4. 实现细节(Implementation)
- 可微分仿真层(Differentiable Simulation Layer): 使用NVIDIA Warp实现CIPC仿真,以便利用自动微分功能。
- 损失平衡(Balancing between Losses): 合理设置渲染损失和几何正则化损失的权重,以达到最佳优化效果。
通过上述步骤,Dress-1-to-3流程能够从单视图图像中生成与输入图像对齐的、模拟就绪的3D服装和人物模型,并且能够生成相应的纹理和动态展示。这种方法不仅提高了重建质量,还增加了服装模型在下游任务中的适用性。
论文做了哪些实验?
论文中进行了以下实验来评估Dress-1-to-3方法的有效性和性能:
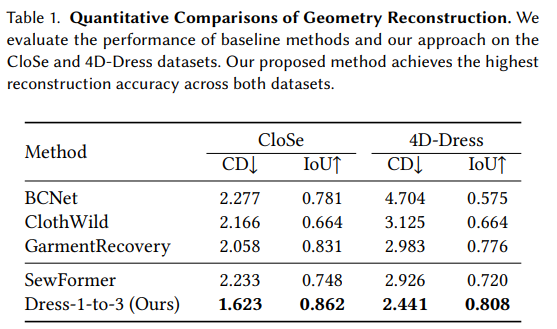
1. 几何重建比较(Geometry Reconstruction Comparison)
- 基准测试(Benchmark): 使用CloSe和4D-Dress数据集进行比较研究,这些数据集包含多种人体形状、姿态和相应的前视图图像。
- 基线比较(Baselines): 与现有的单视图服装重建方法进行比较,包括BCNet、ClothWild、GarmentRecovery和SewFormer。
- 结果(Results): 使用Chamfer Distance (CD)和Intersection over Union (IoU)两个指标对基线方法和提出的方法进行定量评估,结果表明Dress-1-to-3在两个数据集上都取得了最高的重建精度。
2. 服装图案评估(Sewing Pattern Evaluation)
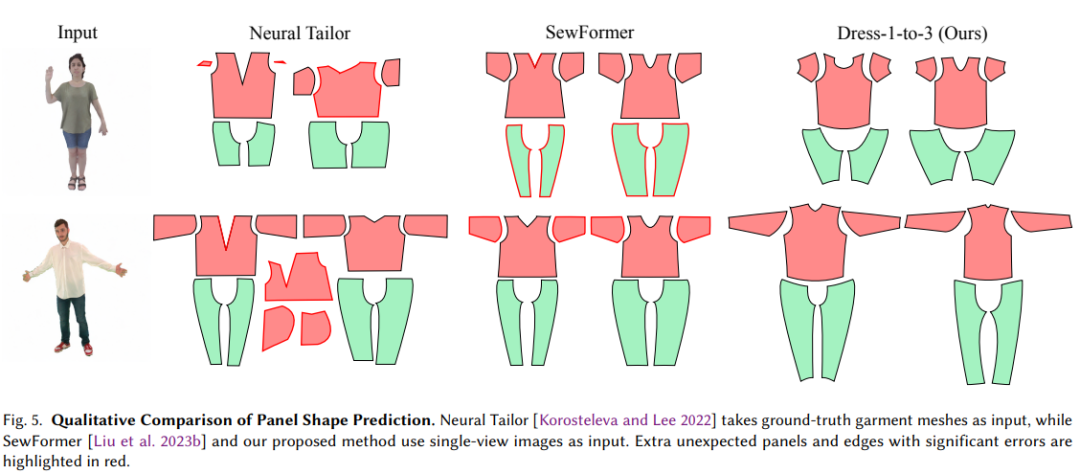
- 与现有方法比较: 与Neural Tailor和SewFormer两种预测服装缝纫图案的方法进行比较。
- 结果(Results): 通过定性结果展示,Dress-1-to-3优化方法能够显著提高从单视图图像输入的服装图案的准确性。
3. 带纹理的服装重建和模拟(Textured Garment Reconstruction and Simulation)
- 测试图像(Test Images): 使用DeepFashion2和DeepFashionMultimodal数据集中的现实世界图像和合成时尚图像进行测试。
- 带纹理的服装重建(Textured Garment Reconstruction): 展示了Dress-1-to-3使用各种来源的野外测试图像生成完美贴合3D服装的能力,并自动检索视觉上合理的服装纹理。
- 服装模拟(Garment Simulation): 展示了优化后的3D服装可以无缝集成到基于物理的仿真中,如视频游戏中使用的仿真。
4. 消融研究(Ablation Study)
- 几何正则化(Geometric Regularizers): 对Dress-1-to-3中的各个几何正则化损失项进行消融研究,以评估它们对最终服装重建质量的贡献。
这些实验全面评估了Dress-1-to-3方法在不同方面的表现,包括几何重建精度、服装图案预测的准确性、纹理生成能力和动态模拟的真实性。通过这些实验,论文证明了所提出方法的有效性和优越性。
论文的主要内容:
这篇论文提出了一个名为Dress-1-to-3的新颖流程,旨在从单视图图像中重建出模拟就绪的3D服装和人物模型。以下是论文的主要内容总结:
1. 研究动机
- 传统数字人物和服装创建流程复杂且耗时。
- 现有图像到3D资产重建技术通常生成的模型不适合动态模拟和动画。
- 需要一个能够生成分离的、模拟就绪的服装和人物模型的流程。
2. Dress-1-to-3流程
- 结合2D多视图扩散和3D缝纫图案重建的优势。
- 从单视图图像出发,通过预训练的模型生成服装缝纫图案。
- 使用多视图扩散模型产生多视图图像,用于优化3D服装。
- 利用可微分的服装模拟器优化服装图案和物理参数。
3. 关键技术
- 多视图扩散模型:生成用于指导3D重建的多视图图像。
- 服装图案生成:使用SewFormer从图像生成初始服装图案。
- 可微分服装模拟:基于CIPC(Codimensional Incremental Potential Contact)的模拟方法,优化服装图案和物理参数。
- 几何正则化:使用多种几何损失函数来引导优化过程,保证服装图案的合理性和服装的舒适度。
4. 实验
- 在CloSe和4D-Dress数据集上与现有方法比较,展示了优越的几何重建精度。
- 评估了服装图案预测的准确性,并与现有技术比较。
- 展示了使用野外图像进行纹理服装重建和模拟的能力。
- 通过消融研究验证了各个组件和正则化项的贡献。
5. 结论与未来工作
- Dress-1-to-3能够从单视图图像生成与输入图像对齐的模拟就绪的3D服装和人物模型。
- 尽管取得了良好的结果,但方法在处理多层服装和初始缝纫图案估计方面仍有限制。
- 提出了未来可能的改进方向,包括提高服装图案预测的准确性和处理更复杂的服装。
总的来说,这篇论文提出了一个创新的端到端流程,能够将单视图服装图像转换为详细的3D模拟就绪服装,这对于虚拟现实、时尚设计和游戏产业等领域具有重要的应用价值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号