带你彻底搞懂分布式配置中心
原创
带你彻底搞懂分布式配置中心
原创
写bug的高哈哈
发布于 2025-02-10 10:35:24
发布于 2025-02-10 10:35:24
在分布式系统中有效地管理配置信息是系统开发过程中的基本要求。因为,在一个分布式系统中,势必存在多个服务,这些服务一般都会构建开发、测试、预发布、生产等多套环境,每套环境都是一个集群,而且针对不同的环境,我们都会采用一套不同的配置体系。
那你想一想,在多个环境下的各个服务实例中,如何有效且统一地管理这些配置信息,保证都能实时地同步更新呢?
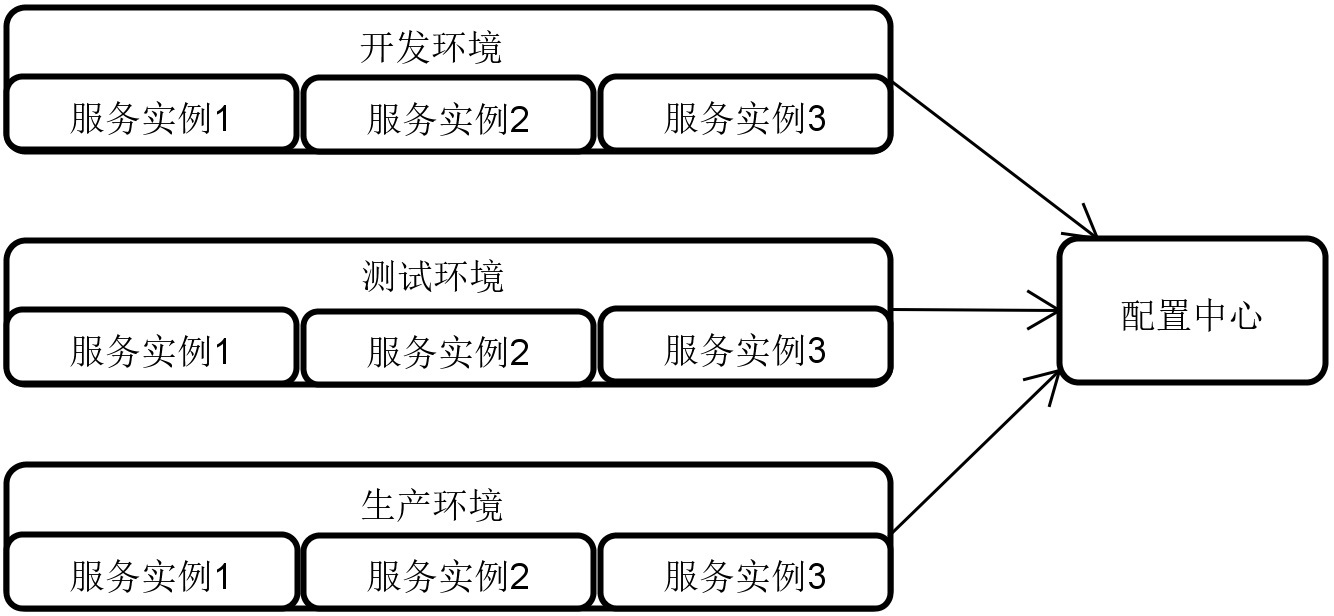
配置中心示意图
考虑到服务的数量和配置信息的分散性,我们一般都需要 引入配置中心的设计思想和相关工具。每个分布式系统都应该有一个配置中心,而各个服务中所使用到的配置信息都应该维护在配置中心中。
配置中心的核心设计思想就是把系统中所有的配置内容都进行集中化、统一化管理,从而解决因为数量和环境导致的配置信息不一致问题。
讲到这里,你可能会问,配置中心到底长什么样呢?所以接下来,我们先来梳理一下配置中心的基本模型,你可以边看边想一想,这样的模型结构能具备什么功能特性。
配置中心模型
关于配置中心的组成,业界存在一种比较标准的基础结构。
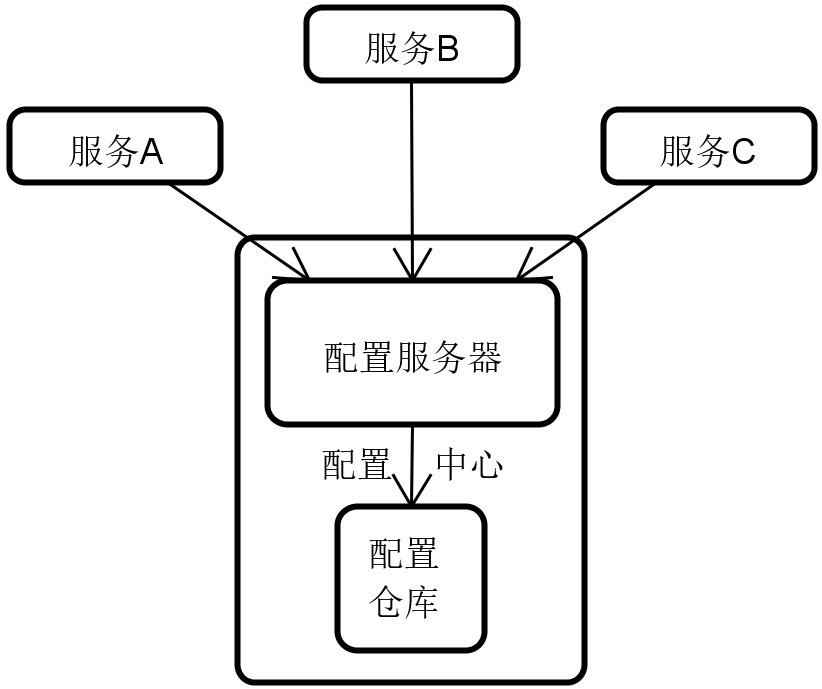
配置中心组成结构
你可以看到,对一个典型的配置中心而言,主要有两个组成部分:配置服务器和配置仓库。接下来我会一一讲解它们的作用。
配置服务器和配置仓库
我们看一下配置服务器。配置服务器的核心作用就是对接来自各个服务的配置信息请求,这些服务会通过配置服务器提供的统一接口,获取存储在配置仓库中所需的配置信息。
所以,它的作用主要体现在两个方面。
一是,配置服务器需要统一维护配置中心存储的各种配置信息。
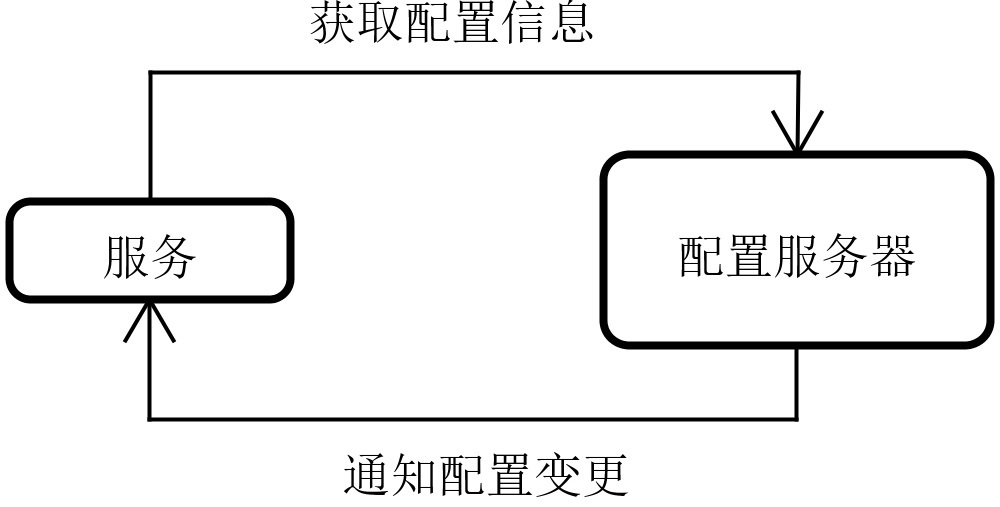
配置服务器与服务之间的交互关系
第二个作用,从图中你也可以看到, 配置服务器需要提供一种通知机制,在配置信息变化之后,能够主动把变更信息传递到各个服务,从而确保各个服务能够使用最新的配置内容。针对这点,不同的配置中心实现工具会采用不同的策略,我们在后续内容中会对这块内容展开讨论。
所以原则上,配置服务器可以独立完成配置信息的存储和维护工作。但是为了确保配置信息在存储机制上的独立性和隔离性,我们也可以把这部分工作剥离出来放到单独的一个媒介中,这个媒介就是配置仓库。因此你要注意,配置仓库并不是必需的。
构建独立配置仓库的主要优势在于能够抽象配置存储过程,从而支持不同的存储方案,包括文件系统、各种第三方工具以及各种自定义的存储媒介,这样就能满足不同业务场景下的多样化存储需求。
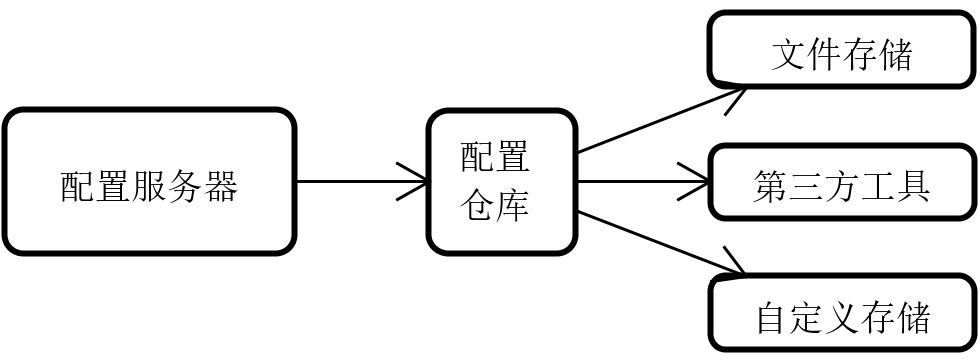
配置服务器与配置仓库之间的关联关系
配置中心功能特性
介绍完配置中心的两个基本成分和作用之后,接下来我们来讨论一下, 作为一个配置中心应具备的核心功能,包括隔离性、一致性和安全性。
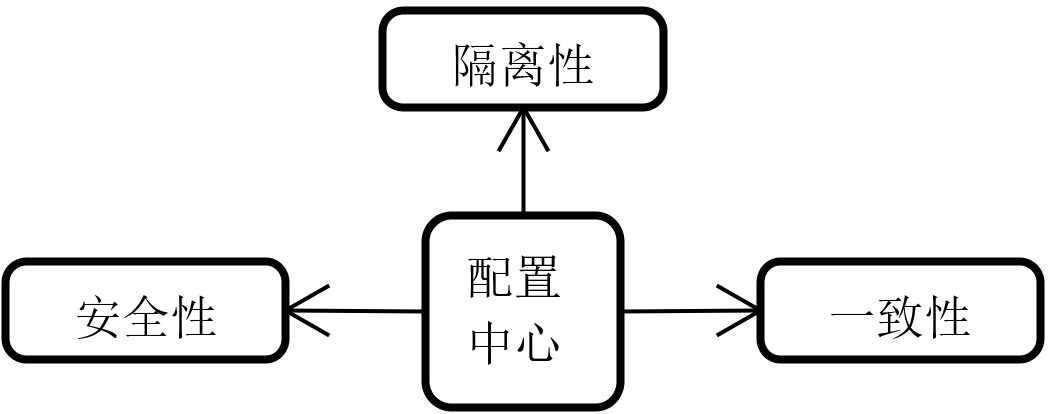
配置中心的核心需求
- 隔离性
首先针对配置信息的管理,做到隔离性是最基本的要求。所谓隔离性,指的就是特定配置项只能用于特定环境中,不同环境中的配置项不应该相互混淆。如果配置中心无法实现隔离性,那么各个环境之间的配置内容就会相互混淆,例如本来用于开发环境的配置内容一旦被作用于测试环境,那么后果是不堪设想的。
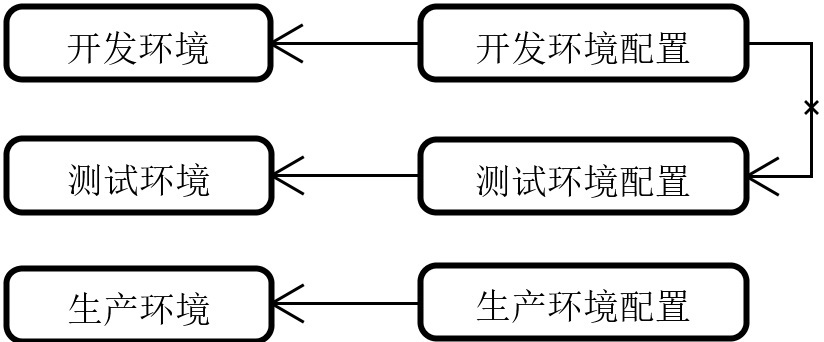
配置中心隔离性示意图
- 一致性
第二个功能,一致性的讨论对象是集群环境。在一个集群环境中的所有服务都应该使用同一份完全相同的配置信息,针对配置信息的操作结果,对于这些服务而言,应该是完全一致的。
想象一下,假如在一个集群环境中针对某个服务存在三个实例,那么访问每个服务实例都应该得到统一的结果,而前提就是这些服务实例都应该保存着同一份配置信息。
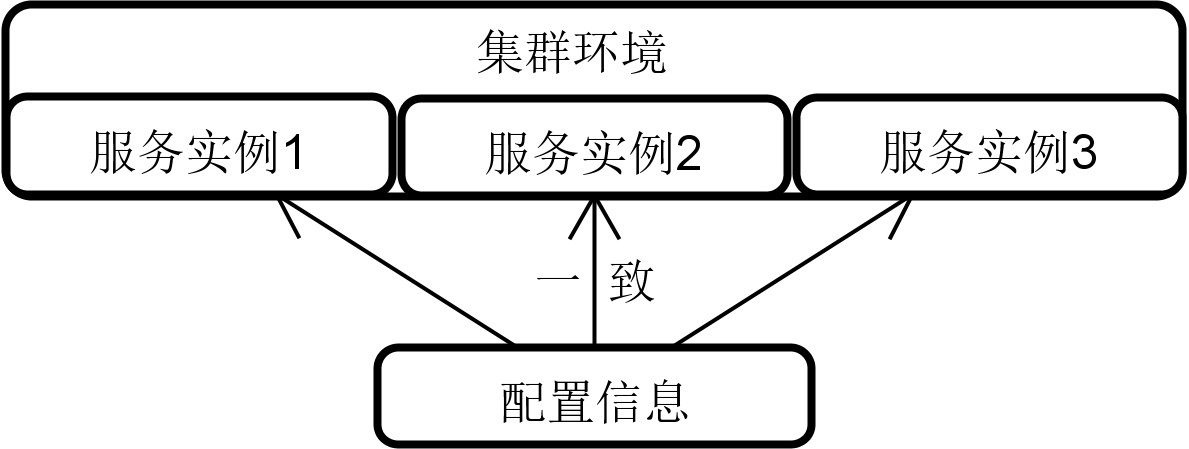
配置中心一致性示意图
- 安全性
最后一个功能,安全性,你比较容易理解。只有在通过合法的授权之后,开发人员才能访问配置中心里的关键配置内容,避免敏感信息的泄露。
这里针对安全性,我们需要讨论两个维度,一个维度是从配置服务器的角度出发,确保位于服务器上的配置信息不被随意访问,另一个维度则是从数据传输的角度出发,确保敏感配置信息得到应有的保护。
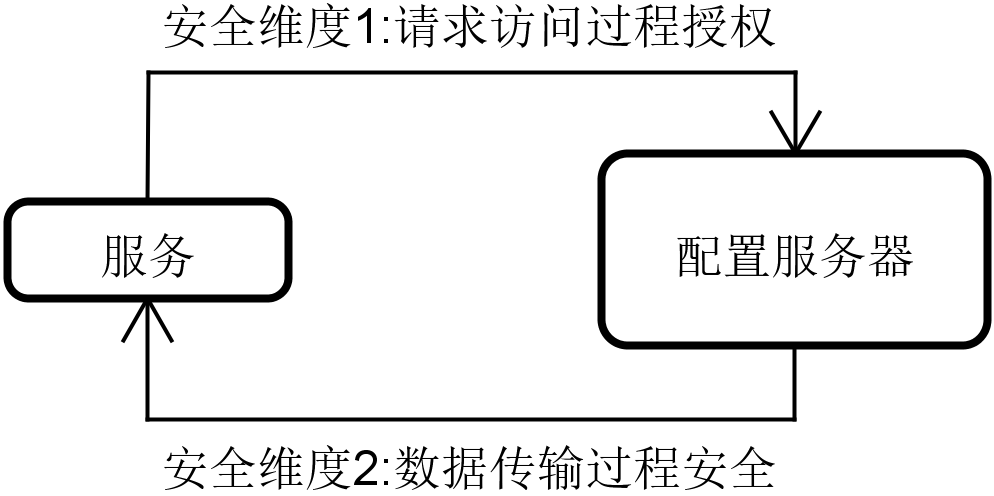
配置中心安全性示意图
我们刚刚讲了配置中心的 2 个组成结构和 3 点功能特性,实际上,组成结构和功能特性之间是相辅相成的。
从结构上讲,正是因为把配置仓库从配置服务器中单独抽离出来,我们才能更好把握配置操作和配置存储两者之间的边界,从而实现隔离性。而独立维护配置仓库也能更好的实现配置信息之间的一致性。另一方面,因为各个配置仓库之间在实现上存在差异,因此针对安全性的控制,则需要有专门的配置服务器来承接这部分职责。
配置中心实现工具
业界配置中心的实现工具非常多。国外比较典型的配置中心实现工具,包括 etcd、Consul、ZooKeeper、Spring Cloud Config;国内具有代表性的,包括百度开源的 Disconf、阿里巴巴提供的 Diamond。
今天我们就不对这些工具一一展开了,仅重点讨论 ZooKeeper 和 Spring Cloud Config,因为这两款工具在构建分布式以及微服务架构中应用非常广泛。
讲到配置中心,就不得不提 ZooKeeper 了。ZooKeeper 是一款分布式协调工具,本质上是一种树状结构,我们可以对树中的每个节点设置监听器。监听器的作用就是为了实时感知。当某一个节点的信息有任何变动,所有监听该节点的其他节点都可以实时获取通知,并根据需要,实现自定义的处理逻辑。
对配置中心而言,所有服务就是 ZooKeeper 的客户端,这些服务通过监听包含配置信息的 ZooKeeper 节点,就能获取配置信息的更新内容。你可以看看基于 ZooKeeper 实现配置中心的示意图,这个过程本质上就是对 ZooKeeper 节点和监听器的合理利用。
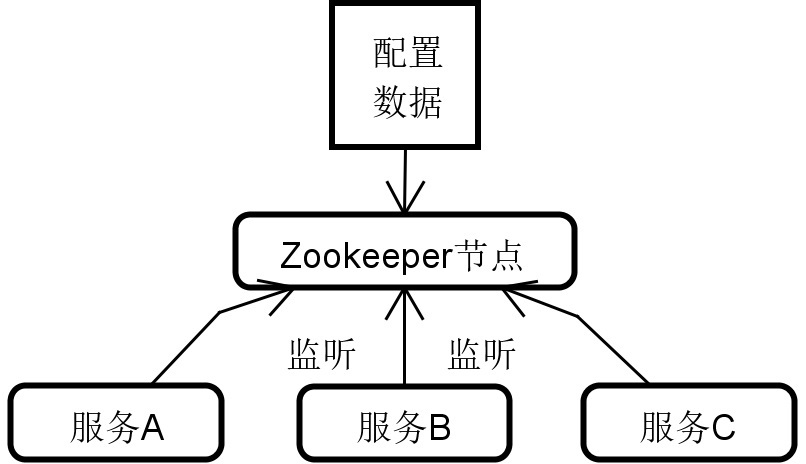
ZooKeeper 实现配置中心示例图
最后我们来看 Spring Cloud Config。在设计思路上,Spring 家族中的 Spring Cloud Config 与 ZooKeeper 完全不同。ZooKeeper 是把配置信息保存在内部的节点上,这些节点本质上就是操作系统的文件系统。而 Spring Cloud Config 同样可以将配置信息保存在文件系统中。
但更多的场景中,更推荐使用 Git 等配置仓库来存储配置信息。作为目前版本控制领域的主流实现框架,Git 的分布式版本控制功能够确保配置信息得到很好的维护。
在关键的配置变化通知机制上,ZooKeeper 依赖变更事件的发送和监听器机制来通知客户端;而 Spring Cloud Config 则会发送事件到 Spring Cloud Bus 消息总线,然后由消息总线通知相关的服务。
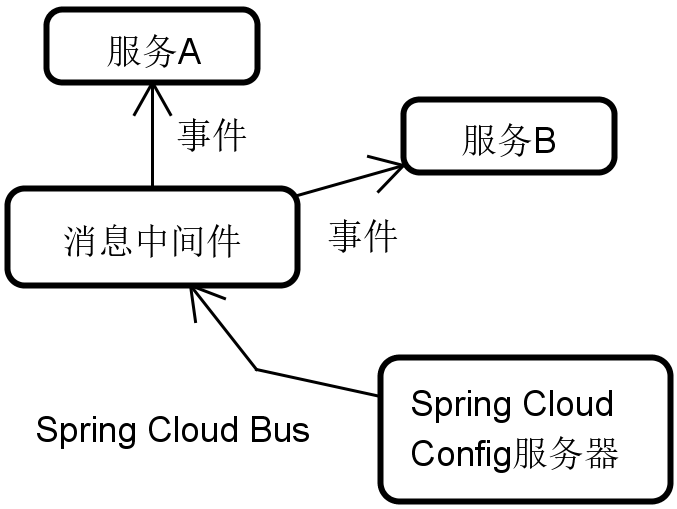
基于 Spring Cloud Bus 的事件传播机制
显然,不同的工具有不同的设计原理和实现方式。这些工具的核心区别在于两个方面,存储媒介和变更通知机制。
从存储媒介上讲,不同方案对于开发人员而言并没有太大的影响,因为配置存储属于配置中心的内部实现机制。
但针对变更通知机制,不同的方案往往需要开发人员采用不同的技术体系与配置中心进行有效集成,这就需要充分理解工具本身的原理。
这里,我们进一步分析一下 Spring Cloud Config 这款配置中心工具,来看看它是如何分别满足配置中心的三大功能特性:隔离性、一致性、安全性。
Spring Cloud Config 中的配置仓库,既支持传统的基于目录组织结构的文件系统,也支持 Git、SVN 等具备版本控制功能的外部工具。因此,针对隔离性,我们可以基于这些工具自身的功能特性,来实现环境与环境之间的完全隔离。至于一致性,也是一样的设计思路和实现原理。
针对安全性,从配置服务器的角度,对“请求访问过程授权”需求,我们可以基于 Spring 家族中的安全框架 Spring Security 来提供用户访问认证;而从数据传输的角度,针对“数据传输过程安全”,解决方案是使用数据加密,Spring Cloud Config 同时支持包括对称与非对称加密两种具体实现方式。
除了这些特性之外,Spring Cloud Config 还提供了易管理性。对所有的配置数据,Spring Cloud Config 都开放了一套完整的 RESTful API,任何系统都可以基于 HTTP 协议来访问配置仓库中的配置数据,从而构建满足多样化需求的管理界面。
总结
配置中心是分布式架构中的一个基础组件,而业界关于如何实现配置中心也有一些基本的模型和工具。在今天的内容中,针对如何设计和实现一款配置中心工具,我们梳理了配置中心所必须要考虑的组成结构和功能特性。同时,我们结合业界主流的配置中心开源框架做了对比,并重点对 Spring 家族中的 Spring Cloud Config 展开了详细分析。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号