文件系统基准测试应用IOR-简介
原创

IOR简介
IOR(交叉或随机)是一种常用的文件系统基准测试应用程序,特别适合评估并行文件系统的性能。该软件通常以源代码形式分发,通常需要在目标平台上编译。IOR 不是特定于 Lustre 的基准测试,可以在任何符合 POSIX 的文件系统上运行,但它需要完全安装和配置的文件系统实现才能运行。对于 Lustre,这意味着必须安装、配置和运行 MGS、MDS 和 OSS 服务,并且有一组 Lustre 客户端节点在运行,并安装了 Lustre 文件系统
IOR 可用于测试使用各种接口和访问模式的并行文件系统的性能。IOR 使用 MPI 进行进程同步 - 通常,HPC 集群中的多个节点上会并行运行多个 IOR 进程。作为用户空间基准测试应用程序,它适用于比较不同文件系统的性能。通常,每个参与安装目标文件系统的客户端节点都会运行一个 IOR 进程,但这是完全可配置的
IOR 是一个并行 IO 基准测试,可用于测试使用各种接口和访问模式的并行存储系统的性能。IOR 存储库还包括 mdtest 基准测试,该基准测试专门测试不同目录结构下存储系统的峰值元数据速率。这两个基准测试都使用通用的并行 I/O 抽象后端,并依赖 MPI 进行同步
本文简介
这是有关 IOR 基本用法的简短教程,以及如何使用 IOR 处理缓存对性能影响的一些技巧
运行IOR
运行 IOR 有两种方法:
- 带参数的命令行: 可执行文件后跟命令行选项。 $ ./ior -w -r -o filename 这将对文件“filename”执行写入和读取操作。
- 带脚本的命令行: 命令行上的任何参数都将为测试运行建立默认值,但脚本可以与此结合使用,以便在执行代码期间改变特定测试。仅使用脚本之前的参数! $ ./ior -W -f script 这使得“脚本”中的所有测试默认使用写入数据检查。
本教程使用第一种,因为这样更容易操作并了解 IOR。第二种选择被认为更有用,可以安全地设置基准测试,以便以后重新运行或测试许多不同的情况
参考脚本
mpirun ./ior -f script -Wscript:
IOR START
api=[POSIX|MPIIO|HDF5|HDFS|S3|S3_EMC|NCMPI|RADOS]
testFile=testFile
hintsFileName=hintsFile
repetitions=8
multiFile=0
interTestDelay=5
readFile=1
writeFile=1
filePerProc=0
checkWrite=0
checkRead=0
keepFile=1
quitOnError=0
segmentCount=1
blockSize=32k
outlierThreshold=0
setAlignment=1
transferSize=32
singleXferAttempt=0
individualDataSets=0
verbose=0
numTasks=32
collective=1
preallocate=0
useFileView=0
keepFileWithError=0
setTimeStampSignature=0
useSharedFilePointer=0
useStridedDatatype=0
uniqueDir=0
fsync=0
storeFileOffset=0
maxTimeDuration=60
deadlineForStonewalling=0
useExistingTestFile=0
useO_DIRECT=0
showHints=0
showHelp=0
RUN
# additional tests are optional
transferSize=64
blockSize=64k
segmentcount=2
RUN
transferSize=4K
blockSize=1M
segmentcount=1024
RUN
IOR STOPIOR 入门
IOR 使用以下参数按顺序写入数据:
blockSize(-b)transferSize(-t)segmentCount(-s)numTasks(-n)
最好用图表来说明:
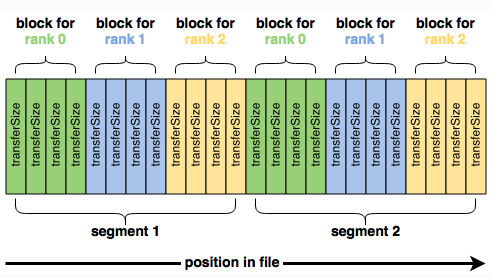
这四个参数就是您开始使用 IOR 所需的全部参数。但是,单纯地运行 IOR 通常会得到令人失望的结果。例如,如果我们运行一个四节点 IOR 测试,总共写入 16 GiB:
$ mpirun -n 64 ./ior -t 1m -b 16m -s 16
...
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
write 427.36 16384 1024.00 0.107961 38.34 32.48 38.34 2
read 239.08 16384 1024.00 0.005789 68.53 65.53 68.53 2
remove - - - - - - 0.534400 2我们每秒只能从 Lustre 文件系统中获取几百兆字节的数据,但 Lustre 的实际性能应该要高得多。
使用-F(filePerProcess=1)选项将写入单个共享文件切换为每个进程写入一个文件可以显著改变性能:
$ mpirun -n 64 ./ior -t 1m -b 16m -s 16 -F
...
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
write 33645 16384 1024.00 0.007693 0.486249 0.195494 0.486972 1
read 149473 16384 1024.00 0.004936 0.108627 0.016479 0.109612 1
remove - - - - - - 6.08 1这在很大程度上是因为让每个 MPI 进程在自己的文件上工作可以消除由于文件锁定而产生的任何争用。
但是,我们的简单测试和每个进程一个文件的测试之间的性能差异有点极端。事实上,Lustre 上实现 146 GB/秒读取率的唯一方法是四个计算节点中的每一个都为 Lustre 提供超过 45 GB/秒的网络带宽——也就是说,每个计算和存储节点都有 400 Gbit 的链路。
页面缓存对基准测试的影响
实际情况是,IOR 读取的数据实际上并非来自 Lustre;相反,文件的内容已经在缓存,IOR 能够直接从每个计算节点的 DRAM(缓存) 中读取它们。由于 Linux(和 Lustre)使用写回缓存(write-back)来缓冲 I/O,因此数据最终在 IOR 的写入阶段被缓存,因此 IOR 不是直接将数据写入和读取到 Lustre,而是实际上主要与每个计算节点上的内存进行通信。
更具体地说,尽管每个 IOR 进程都认为它正在将数据写入 Lustre 上的文件,然后从 Lustre 中读回该文件的内容,但实际上
- 将数据写入缓存在内存中的文件副本。如果在此写入之前内存中没有缓存的文件副本,则首先将修改的部分加载到内存中。
- 内存中的文件部分(称为“页面”)现在与 Lustre 上的内容不同,被标记为“脏”
- write() 调用完成,IOR 继续,尽管写入的数据仍未提交给 Lustre
- 操作系统内核独立于 IOR,不断扫描文件缓存,查找已在内存中更新但未在 Lustre 中更新的文件(“脏页”),然后将缓存的修改提交给 Lustre
- 脏页被声明为非脏页,因为它们现在与磁盘上的内容同步,但它们仍保留在内存中
然后,当 IOR 的读取阶段跟在写入阶段之后时,IOR 能够从内存中检索文件的内容,而不必通过网络与 Lustre 通信(这样带缓存的性能偏高)。
有几种方法可以测量底层 Lustre 文件系统的读取性能。最粗暴的方法是简单地写入比总页面缓存所能容纳的数据更多的数据,这样在写入阶段完成时,文件的开头已经从缓存中被逐出。例如,增加段数 ( -s) 以写入更多数据可以非常清楚地揭示我的测试系统上节点的页面缓存何时溢出:
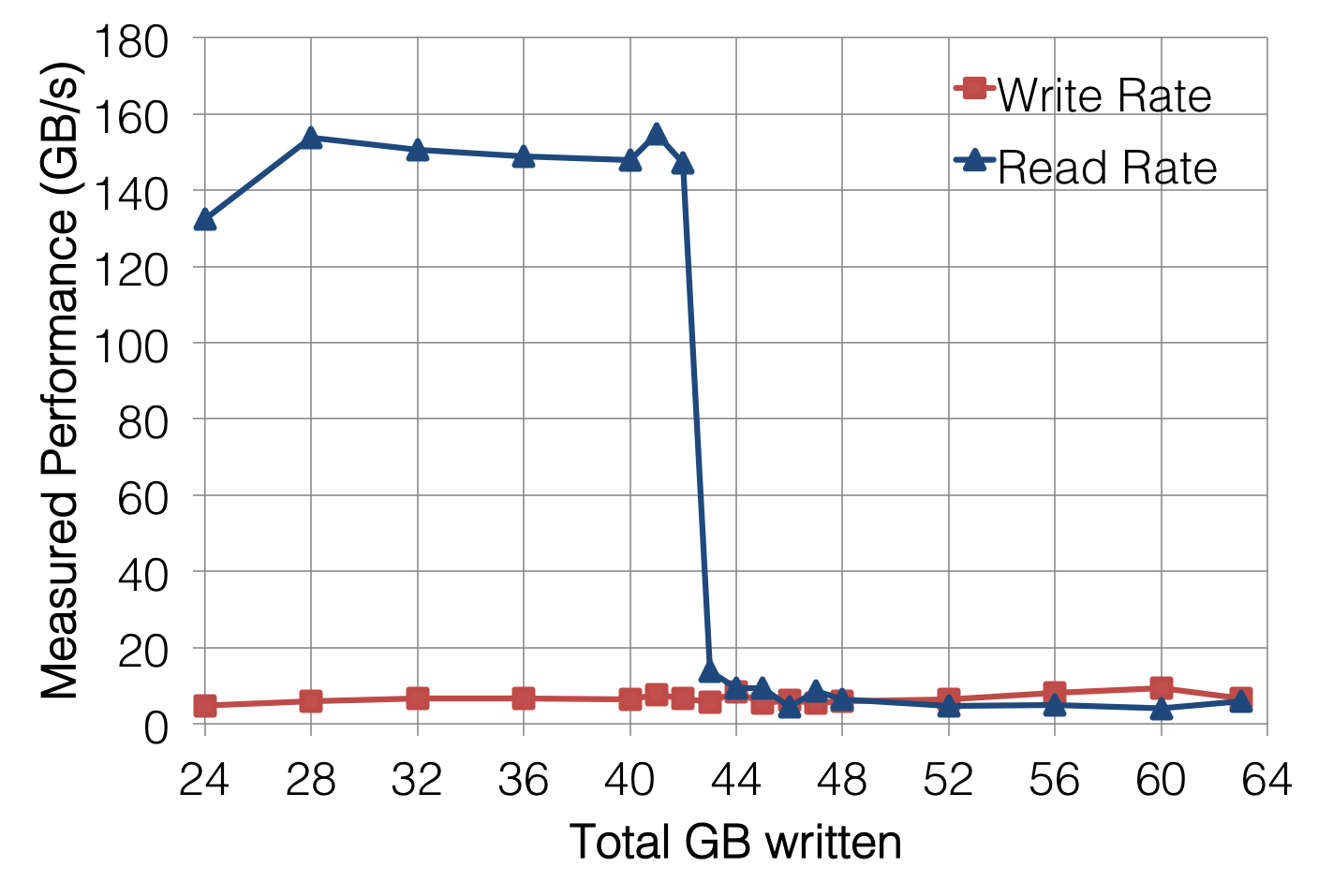
../_images/tutorial-ior-overflowing-cache.png
但是,这会导致在具有大量节点内存的系统上运行 IOR 需要很长时间。
更好的选择是让每个节点上的 MPI 进程仅读取它们未写入的数据(错开读写)。例如,在每个节点四个进程的测试中,将 MPI 进程到块的映射移动四位,使得每个节点 N 读取节点 N-1 写入的数据。
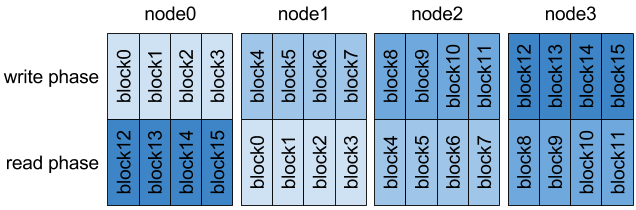
../_images/tutorial-ior-reorderTasks.png
由于页面缓存不在计算节点之间共享,因此以这种方式转移任务可确保每个 MPI 进程都在读取其未写入的数据。
IOR 提供了-C选项 ( reorderTasks) 来执行此操作,它强制每个 MPI 进程读取其相邻节点写入的数据。使用此选项运行 IOR 可提供更可靠的读取性能:
$ mpirun -n 64 ./ior -t 1m -b 16m -s 16 -F -C
...
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
write 41326 16384 1024.00 0.005756 0.395859 0.095360 0.396453 0
read 3310.00 16384 1024.00 0.011786 4.95 4.20 4.95 1
remove - - - - - - 0.237291 1但现在应该很明显,写入性能也高得离谱。同样,这是由于页面缓存,当写入已提交到内存而不是底层 Lustre 文件系统时,它会向 IOR 发出写入已完成的信号。
为了解决页面缓存对写入性能的影响,我们可以在所有 write() 返回后立即发出 fsync() 调用,以强制将我们刚刚写入的脏页刷新到 Lustre。包括 fsync() 完成所需的时间,我们可以衡量数据写入页面缓存以及页面缓存写回 Lustre 所需的时间。
IOR 提供了另一个方便的选项-e(fsync) 来实现这一点。而且,再次强调,使用此选项会大大改变我们的性能测量:
$ mpirun -n 64 ./ior -t 1m -b 16m -s 16 -F -C -e
...
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
write 2937.89 16384 1024.00 0.011841 5.56 4.93 5.58 0
read 2712.55 16384 1024.00 0.005214 6.04 5.08 6.04 3
remove - - - - - - 0.037706 0我们最终对文件系统的带宽进行了可信的测量。
击穿页面缓存
由于 IOR 是专门为 I/O 基准测试而设计的,因此它提供了这些选项,让您尽可能轻松地确保您实际测量的是文件系统的性能,而不是计算节点的内存。话虽如此,它生成的 I/O 模式旨在展示峰值性能,而不是反映实际应用程序可能尝试执行的操作,因此,在很多情况下,使用 IOR 测量 I/O 性能并不总是最佳选择。有几种方法可以让我们变得聪明,并在更一般的意义上击败页面缓存,以获得有意义的性能数字。
在测量写入性能时,绕过页面缓存实际上非常简单;打开带有标志的文件O_DIRECT直接写入磁盘。此外,fsync()可以将调用插入到应用程序中,就像使用 IOR 的选项一样-e 。
测量读取性能要复杂得多。如果你有幸在测试系统上拥有 root 访问权限,你可以强制 Linux 内核清空其页面缓存,方法是:
# echo 1 > /proc/sys/vm/drop_caches (用于回收不使用的pagecache页面)事实上,在运行任何基准测试(例如 Linpack)之前,这通常是一种很好的做法,因为它可以确保当基准测试应用程序开始分配内存供自己使用时,不会因为内核试图驱逐页面而损失性能。
不幸的是,我们中的许多人没有系统上的 root 权限,所以我们必须更加聪明。事实证明,有一种方法可以向内核传递一个POSIX_FADV_DONTNEED提示,即页面缓存中不再需要某个文件:
#define _XOPEN_SOURCE 600
#include <unistd.h>
#include <fcntl.h>
int main(int argc, char *argv[]) {
int fd;
fd = open(argv[1], O_RDONLY);
fdatasync(fd);
posix_fadvise(fd, 0,0,POSIX_FADV_DONTNEED);
close(fd);
return 0;
}使用 POSIX_FADV_DONTNEED 传递的效果posix_fadvise()通常是该文件的所有页面都会从 Linux 的页面缓存中被逐出。但是,这只是一个提示,而不是保证,内核会异步逐出这些页面,因此页面可能需要一两秒钟才能真正离开页面缓存。幸运的是,Linux 还提供了一种方法来探测文件中的页面,以查看它们是否驻留在内存中。
最后,最简单的方法通常是限制可用于页面缓存的内存量。由于应用程序内存始终优先于缓存内存,因此只需在节点上分配大部分内存就会强制清除大部分缓存页面。较新版本的 IOR 提供了 memoryPerNode 选项,可以执行此操作,其效果正如人们所期望的那样:
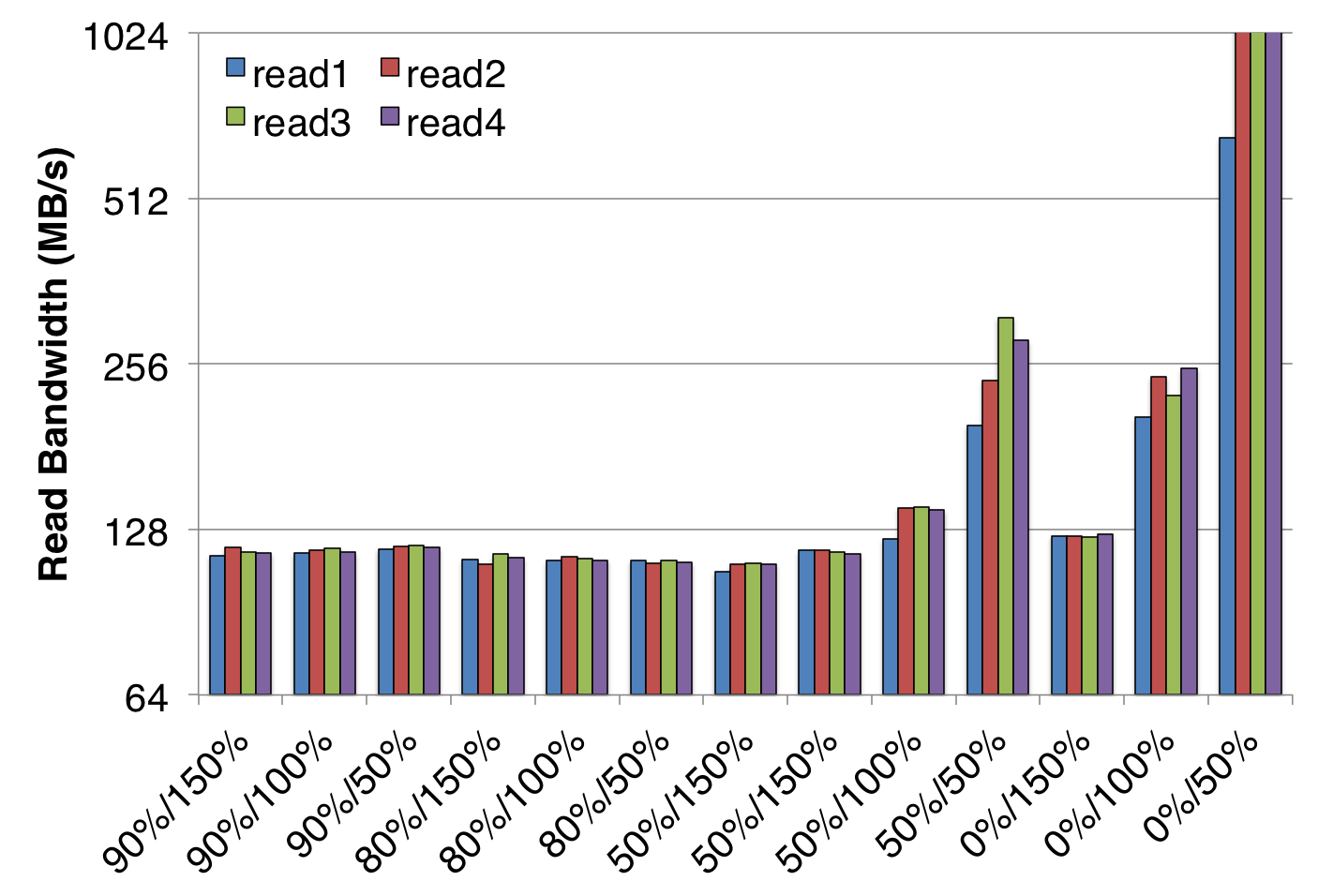
../_images/tutorial-ior-memPerNode-test.png
上图显示了单个节点的测量带宽,其中总 DRAM 为 128 GiB。每个 x 标签上的第一个百分比是基准测试保留为应用程序内存的 128 GiB 量,第二个百分比是总写入量。例如,“50%/150%”数据点对应于为应用程序分配的 50% 节点内存(64 GiB),以及总共读取 192 GiB 的数据。
此基准测试是在单个旋转磁盘上运行的,其速度不超过 130 MB/秒,因此显示性能高于此值的条件得益于一些页面由缓存提供。这完全有道理,因为当相对于读取的数据量而言有足够的内存进行缓存时,获得了异常高的性能测量值。
推论
测量 I/O 性能比测量 CPU 性能要复杂一些,这在很大程度上是由于页面缓存的影响。话虽如此,页面缓存的存在是有原因的,而且在许多情况下,应用程序的 I/O 性能确实可以通过大量使用缓存的基准来最好地体现。
例如,BLAST 生物信息学应用程序两次重新读取其所有输入数据;第一次初始化数据结构,第二次填充它们。由于第一次读取缓存每个页面并允许第二次读取来自缓存而不是文件系统,因此在禁用页面缓存的情况下运行此 I/O 模式会导致其速度慢约 2 倍:
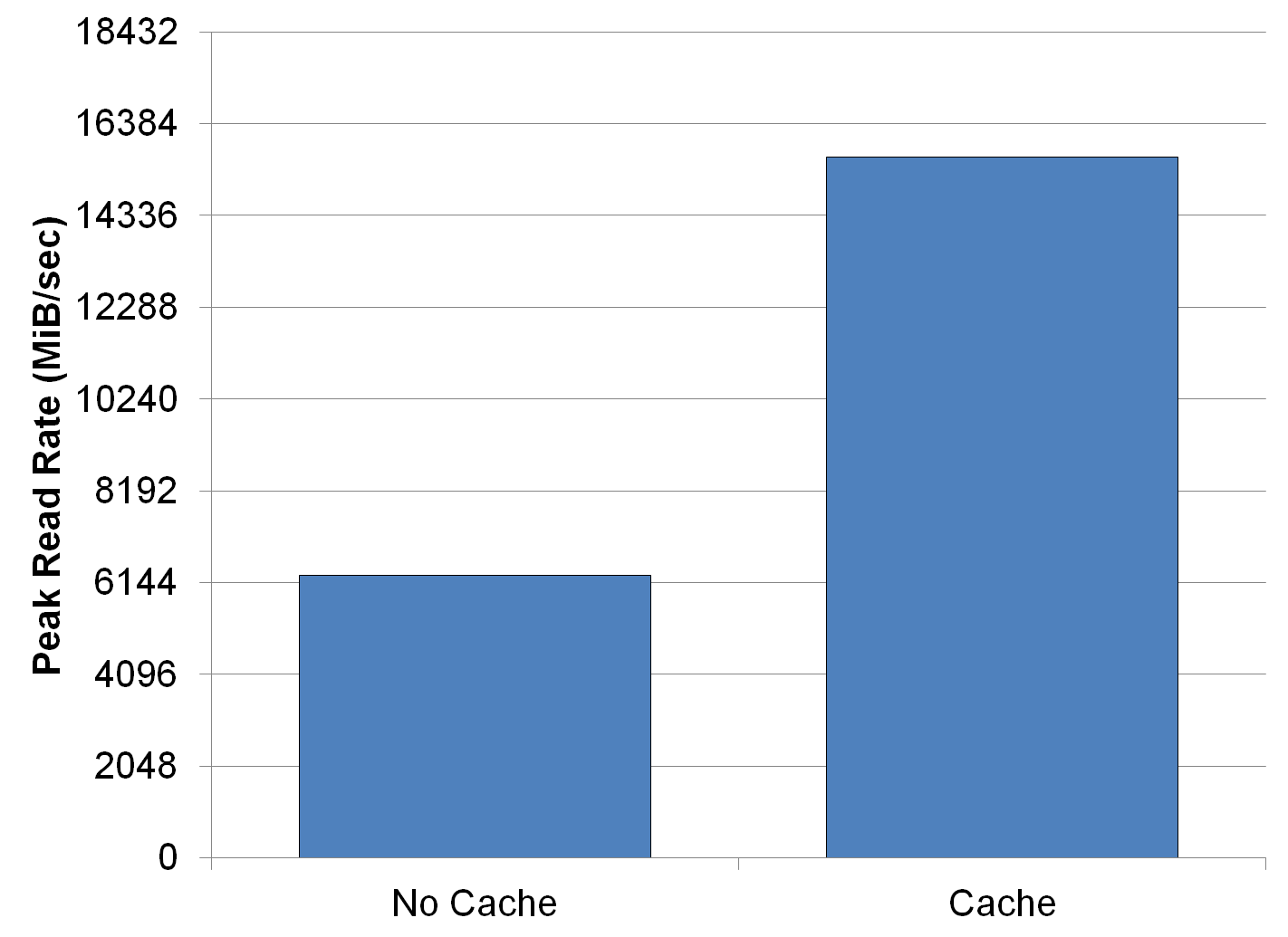
../_images/tutorial-cache-vs-nocache.png
因此,让页面缓存发挥作用通常是使用实际应用程序 I/O 模式进行基准测试的最现实方法。一旦您知道页面缓存如何影响您的测量,您就很有可能推断出最有意义的性能指标是什么。
参考
IOR WIKI: https://wiki.lustre.org/IOR
IOR手册/简介: https://ior.readthedocs.io/en/latest/intro.html
IOR快速入门: https://github.com/hpc/ior/blob/main/doc/sphinx/userDoc/tutorial.rst
IOR项目: https://github.com/hpc/ior
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号