MySQL 核心模块揭秘 | 50 期 | Update 更新的记录,Rollback 怎么回滚?

MySQL 核心模块揭秘 | 50 期 | Update 更新的记录,Rollback 怎么回滚?

爱可生开源社区
发布于 2025-01-23 20:06:58
发布于 2025-01-23 20:06:58
正文
1. 准备工作
创建测试表:
CREATE TABLE `t6` (
`id` int unsigned NOT NULL,
`name` varchar(32) DEFAULT '',
`mobile` char(11) DEFAULT '',
`sex` enum('男','女','未填写') DEFAULT NULL,
`address` varchar(128) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_address` (`address`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
插入测试数据:
INSERT INTO `t6` (`id`, `name`, `mobile`, `sex`, `address`) VALUES
(1, '唐僧', '12800128000', '男', '东土大唐'),
(5, '西梁女王', '11800118000', '女', '女儿国'),
(10, '张三', '13800138000', '男', '张家口'),
(15, '李四', '13900139000', '男', '李家庄'),
(20, '王五', '15900159000', '男', '王家大院'),
(25, '紫霞仙子', '19900199000', '女', '九龙城'),
(30, '猪八戒', '16900169000', '男', '高老庄'),
(35, '孙悟空', '17900179000', '男', '花果山'),
(40, '沙和尚', '18900189000', '男', '流沙河');
修改 <id = 35> 的记录:
UPDATE `t6`
SET `mobile` = '17988179888', `address` = '水帘洞'
WHERE `id` = 35;
回滚:
ROLLBACK;
2. 读取 Undo 日志
回滚 Update 操作过程中读取 Undo 日志,和回滚 Insert 操作过程中读取 Undo 日志的流程一样,这里不再赘述。
3. 解析 Undo 日志
准备工作中,Update 语句修改 <id = 35> 的记录产生的 Undo 日志如下:
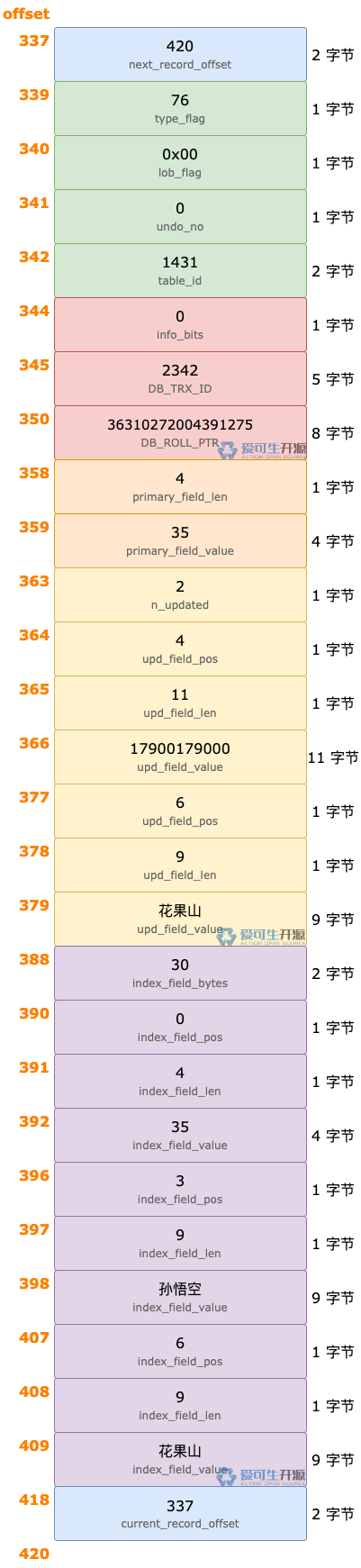
3.1 解析参数
更新记录产生的 Undo 日志,也有称为参数的部分。和插入记录产生的 Undo 日志的不同之处如下:
- 更新记录产生的 Undo 日志有 4 个属性,比插入记录产生的 Undo 日志增加了
lob_flag属性。这个属性值在代码里被硬编码为 0x00。 - 更新记录产生的 Undo 日志的
type_flag属性,相当于插入记录产生的 Undo 日志的type属性。 Undo 日志只有四种类型,用 11 ~ 14 表示,只需要 4 位就够了,但它实际占用了 1 字节(8 位)。 本着勤俭节约的原则,更新记录产生的 Undo 日志,在 Undo 日志类型剩下的 4 位中设置了一些标志,所以,它的属性名用type_flag来表示。
参数区域,对应图中 offset [339, 344):
- type_flag,值为 76,由
12 | 64得到。 12 在代码里定义为TRX_UNDO_UPD_EXIST_REC,表示这条 Undo 日志由更新记录产生,参数区域之后的其它属性按照TRX_UNDO_UPD_EXIST_REC类型的 Undo 日志格式解析。 64 在代码里定义为TRX_UNDO_MODIFY_BLOB,有这个标志就意味着 Undo 日志的参数区域包含lob_flag属性。 - lob_flag,因为 type_flag 中设置了
TRX_UNDO_MODIFY_BLOB标志,所以 Undo 日志中写入了 lob_flag 属性。这个属性值硬编码为 0x00,实际上没有使用。 - undo_no,值为 0。说明这是 Update Undo 段中第一条 Undo 日志。
- table_id,值为 1431。这是 <id = 35> 的记录所属表的 ID。InnoDB 会用这个 ID 打开表,用于回滚过程中的后续操作。
3.2 解析头信息和隐藏字段
头信息和隐藏字段区域,对应图中 offset [344, 358),包含 3 个属性:
- info_bits,值为 0。这是 <id = 35> 的记录的头信息中第 1 字节第 5 ~ 8 位的值。
- DB_TRX_ID,值为 2342。这是 <id = 35> 的记录被当前回滚事务更新之前的 DB_TRX_ID 字段值。
- DB_ROLL_PTR,值为 36310272004391275。这是 <id = 35> 的记录被当前回滚事务更新之前的 DB_ROLL_PTR 字段值。
解析出来之后,这 3 个属性的值会保存到回滚操作内存对象(undo_node)的 update 属性中。
回滚时,这 3 个属性的值分别被拷贝到 <id = 35> 的记录的头信息、DB_TRX_ID 和 DB_ROLL_PTR 字段中。
3.3 解析主键字段
主键字段区域,对应图中 offset [358, 363),包含 2 个属性:
- primary_field_len,值为 4。表示 t6 表的主键字段值(id = 35)在 Undo 日志中占用 4 字节。
- primary_field_value,值为 35。这是 <id = 35> 的记录的主键字段(id)值。
解析出来之后,主键字段值保存到回滚操作内存对象(undo_node)的 ref 属性中。
3.4 解析更新字段
更新字段区域,对应图中 offset [363, 388),存放的是 <id = 35> 的记录中 mobile、address 两个字段在表中的位置,以及更新之前的值。
n_updated 是被更新的字段数量。n_updated 之后,每组 <upd_field_pos, upd_field_len, upd_field_value> 对应一个字段的信息。
解析出来之后,更新字段的信息保存到回滚操作内存对象(undo_node)的 update 属性中。
3.5 二级索引字段
二级索引字段区域,对应图中 offset [388, 418),存放的是 <id = 35> 的记录对应的所有二级索引记录更新之前的字段值。
因为每个二级索引记录的末尾都包含主键字段,所以,Undo 日志的这个区域中记录了 id 字段的信息。每组 <index_field_pos, index_field_len, index_field_value> 对应一个字段的信息。
这个区域存放的二级索引字段信息,回滚时不需要解析,因为用不到。purge 线程清理标记删除的二级索引记录时才会用到。
4. 查找主键索引记录
前面从 Undo 日志中解析主键字段值(id)得到 35,保存到了回滚操作内存对象(undo_node)的 ref 属性中。现在需要根据主键字段值去主键索引的 B+ 树中查找 <id = 35> 的记录。
找到记录之后,读取记录中所有字段值,保存到回滚操作内存对象(undo_node)的 row 属性中。另外,还会保存指向主键索引 B+ 树中 <id = 35> 的记录的指针,后面回滚这条主键索引记录时会用到。
undo_node 对象的 row 属性中,既包含我们创建表时指定的字段,也包含 InnoDB 自己加上的隐藏字段 DB_TRX_ID、DB_ROLL_PTR。因为我们创建表时指定了主键,记录中不会包含隐藏字段 DB_ROW_ID。row 属性中保存的各字段值如下:
- id = 35
- name = 孙悟空
- mobile = 17988179888
- sex = 男
- address = 水帘洞
- DB_TRX_ID = 2345
- DB_ROLL_PTR = 562949962269009
以上这些是 t6 表中 <id = 35> 的记录被当前回滚事务修改之后的各字段值。其中 DB_TRX_ID 是当前回滚事务的 ID,DB_ROLL_PTR 是当前 Undo 日志的地址。
5. 构造回滚记录
这里所说的回滚记录,更直观的说,就是 <id = 35> 的记录,被当前回滚事务更新之前的样子。
回滚记录由回滚操作内存对象(undo_node)的 row、update 两个属性中保存的各字段值合并得到。
row 属性保存着 <id = 35> 的记录中各字段被当前回滚事务更新之后的值。update 属性保存着 <id = 35> 的记录中 mobile、address、DB_TRX_ID、DB_ROLL_PTR 四个字段,以及记录的头信息中第 1 字节第 5 ~ 8 位被当前事务更新之前的值。
合并之后的回滚记录保存到回滚操作内存对象(undo_node)的 undo_row 属性中,各字段值如下:
- id = 35
- name = 孙悟空
- mobile = 17900179000
- sex = 男
- address = 花果山
- DB_TRX_ID = 2342
- DB_ROLL_PTR = 36310272004391275
undo_row 属性中保存的回滚记录的各字段值,用于回滚二级索引记录。upddate 属性中保存的各字段值,用于回滚主键索引记录。
6. 回滚二级索引记录
Update 操作更新二级索引记录的一个或者多个字段,不会原地更新二级索引记录,而是先标记删除原记录,再插入一条新记录。
以示例 SQL 为例,Update 操作会更新二级索引 idx_address 的 address 字段,流程如下:
- 标记删除 idx_addresss 中 <address = 花果山, id = 35> 的记录。
- 插入 <address = 水帘洞, id = 35> 的新记录到 idx_address 中。
回滚时,也只需要回滚 idx_address 中对应 <id = 35> 的记录,流程如下:
- 根据回滚操作内存对象(
undo_node)的row属性中保存的 address 和 id 字段值,构造二级索引记录 <address = 水帘洞, id = 35>。 - 找到 idx_address 中 <address = 水帘洞, id = 35> 的记录。
- 物理删除 idx_address 中 <address = 水帘洞, id = 35> 的记录。
- 根据回滚操作内存对象(
undo_node)的undo_row属性中保存的 address 和 id 字段值,构造二级索引记录 <address = 花果山, id = 35>。 - 找到 idx_address 中 <address = 花果山, id = 35> 的记录。
- 取消 idx_address 中 <address = 花果山, id = 35> 的记录的头信息中的删除标志。这条二级索引记录就恢复为正常记录了。
7. 回滚主键索引记录
前面构造主键索引记录时,已经找到了主键索引中 <id = 35> 的记录,也保存了指向主键索引 B+ 叶子结点中 <id = 35> 的记录的指针。回滚主键索引记录时,可以直接使用这个指针操作 <id = 35> 的记录。
用回滚操作内存对象(undo_node)的 update 属性中保存的 <id = 35> 的记录的信息,回滚主键索引记录的流程如下:
- 用 update 属性中保存的
mobile、address、DB_TRX_ID、DB_ROLL_PTR四个字段的值,把 <id = 35> 的记录恢复到被当前回滚事务更新之前的状态。 - 用 update 属性中保存的头信息,更新 <id = 35> 的记录的头信息中第 1 字节第 5 ~ 8 位,把记录的头信息恢复到被当前回滚事务更新之前的状态。
8. 总结
回滚 Update 操作产生的一条 Undo 日志的主要流程如下:
- 读取一条 Undo 日志。
- 解析 Undo 日志。
- 查找主键索引记录。
- 构造回滚记录(undo_row)。
- 用回滚记录中保存的各字段值,回滚二级索引记录。
- 用头信息和隐藏字段区域、更新字段区域解析出来的头信息和各字段值,回滚主键索引记录。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-01-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号