【机器学习】无监督学习携凝聚型层次聚类登场。无需预设标签,仅凭数据内在特质,逐步归拢聚合,挖掘隐藏群组,为复杂数据剖析开启智能、高效的新思路。

【机器学习】无监督学习携凝聚型层次聚类登场。无需预设标签,仅凭数据内在特质,逐步归拢聚合,挖掘隐藏群组,为复杂数据剖析开启智能、高效的新思路。

逆向-落叶
发布于 2025-01-20 18:51:02
发布于 2025-01-20 18:51:02
引言
层次聚类(Hierarchical Clustering)是一种重要的聚类方法,它通过不断合并或分裂数据点的方式,生成一个层次结构(Dendrogram)来表示数据之间的相似性。与其他聚类方法(如K均值聚类)不同,层次聚类不需要预先指定聚类的数量,这使得它在许多实际问题中非常适用,特别是当数据的自然聚类数目不明确时。 层次聚类有两种主要类型:凝聚型层次聚类(Agglomerative Clustering)和分裂型层次聚类(Divisive Clustering)。凝聚型层次聚类是从每个数据点开始,逐步合并最相似的簇,直到所有数据点合并为一个簇。分裂型层次聚类则从一个整体簇开始,逐步分裂成更小的簇,直到每个数据点都是一个独立的簇。
1.层次聚类概述
层次聚类的定义
层次聚类是一种通过递归合并(凝聚型)或递归分裂(分裂型)数据点的方式,逐步构建出一个层次结构的聚类方法。层次聚类的结果通常通过**树状图(Dendrogram)**表示,它可以直观地显示数据点之间的相似性或距离关系。
层次聚类分为两种主要形式:
- 凝聚型层次聚类(Agglomerative Clustering):从每个数据点视为一个独立簇开始,通过逐步合并最相似的簇,直到最终所有数据点合并为一个簇。
- 分裂型层次聚类(Divisive Clustering):从一个包含所有数据点的簇开始,通过逐步分裂簇,直到每个数据点成为一个独立的簇。
2. 层次聚类的优缺点
优点:
- 不需要预先指定聚类数量:层次聚类不需要事先指定聚类的数量,用户可以根据树状图的形状选择最佳的聚类数量。
- 能够处理任意形状的簇:层次聚类能够处理复杂形状的簇,而不像K均值聚类那样要求簇的形状为球形。
- 直观的可视化:通过树状图,层次聚类能够清晰地展示数据点之间的关系。
缺点:
- 计算复杂度高:层次聚类的计算复杂度通常为O(n²),这意味着对于大规模数据集,计算量会非常大。
- 对噪声和离群点敏感:层次聚类通常基于距离度量,噪声和离群点可能会影响聚类的质量。
- 不可扩展到大数据集:由于计算复杂度较高,层次聚类不适合处理非常大的数据集。
2. 凝聚型层次聚类的基本概念
凝聚型层次聚类是一个自底向上的过程。从每个数据点作为一个簇开始,不断合并相似的簇,直到所有样本都属于同一个簇或满足停止条件。
- 初始化:每个样本点视为一个独立的簇。
- 迭代:计算簇之间的距离,合并距离最小的两个簇。
- 停止条件:直到所有样本点被聚集为一个簇,或者达到预定的簇数目。
算法流程
凝聚型层次聚类的算法可以总结为以下几个步骤:
2.1 初始化
开始时,每个数据点都被当作一个簇。即每个数据点是一个簇,这时簇的数目等于样本数。
2.2 计算簇间距离
在每次迭代中,需要计算所有簇之间的距离。距离的计算可以使用多种方式,最常见的有:
- 欧氏距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
- 余弦相似度(Cosine Similarity)
2.3 合并最相似的簇
在每一次迭代中,找到距离最小的两个簇,将它们合并为一个簇。
2.4 更新距离矩阵
合并两个簇后,需要更新簇间的距离矩阵,重新计算新簇与其他簇之间的距离。
2.5 重复过程
继续合并最相似的簇,直到满足停止条件。停止条件通常是聚类数目达到指定值,或者所有样本点都被归为一个簇。
3. 簇间距离的计算方式
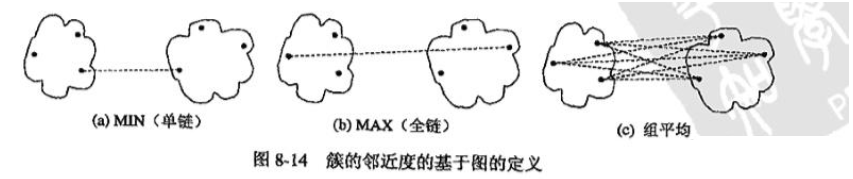
在凝聚型层次聚类中,簇与簇之间的距离是决定是否合并的关键。常见的计算方式有:
3.1 单链接(Single Linkage)
单链接方法中,簇间的距离定义为两个簇中最近的点之间的距离。公式为:
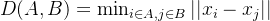
D(A, B) = \min_{i \in A, j \in B} ||x_i - x_j||
其中,A 和 B 为两个簇,
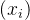
(x_i)
和
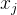
x_j
是簇 A 和簇 B 中的样本,
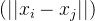
(||x_i - x_j||)
是它们之间的距离。
3.2 全链接(Complete Linkage)
全链接方法中,簇间的距离定义为两个簇中最远的点之间的距离。公式为:
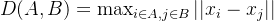
D(A, B) = \max_{i \in A, j \in B} ||x_i - x_j||
3.3 平均链接(Average Linkage)
平均链接方法中,簇间的距离定义为所有样本点之间距离的平均值。公式为:
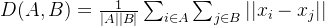
D(A, B) = \frac{1}{|A||B|} \sum_{i \in A} \sum_{j \in B} ||x_i - x_j||
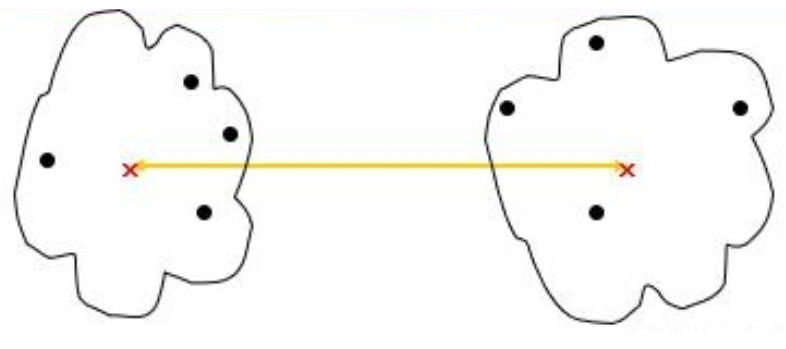
3.4 中心链接(Centroid Linkage)
中心链接方法中,簇间的距离是两个簇的质心(即簇内样本点的平均值)之间的距离。公式为:
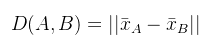
其中,
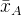
\bar{x}_A
和
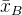
\bar{x}_B
是簇 A 和 B 的质心。
以下是一个完整的 凝聚型层次聚类(Agglomerative Hierarchical Clustering) 的 Python 实现。此实现使用 scipy 和 numpy 来完成数据的聚类,并使用 matplotlib 来进行结果的可视化。
4.凝聚型层次聚类代码实现
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import pdist, squareform
# 计算每两个簇之间的距离
def compute_distance_matrix(X):
"""
计算样本点之间的距离矩阵
"""
return squareform(pdist(X, metric='euclidean')) # 计算欧氏距离矩阵
# 凝聚型层次聚类
def agglomerative_clustering(X, n_clusters=2):
"""
凝聚型层次聚类实现
:param X: 数据集 (n_samples, n_features)
:param n_clusters: 目标聚类数量
:return: 每个数据点的簇标签
"""
# 初始化每个数据点是一个单独的簇
clusters = [[i] for i in range(len(X))]
distance_matrix = compute_distance_matrix(X) # 初始化距离矩阵
# 迭代直到剩下目标数量的簇
while len(clusters) > n_clusters:
# 寻找距离最近的两个簇
min_dist = np.inf
cluster_a, cluster_b = None, None
for i in range(len(clusters)):
for j in range(i + 1, len(clusters)):
dist = np.min(distance_matrix[clusters[i], :][:, clusters[j]]) # 计算两个簇之间的最小距离
if dist < min_dist:
min_dist = dist
cluster_a, cluster_b = clusters[i], clusters[j]
# 合并两个簇
new_cluster = cluster_a + cluster_b
clusters.remove(cluster_a)
clusters.remove(cluster_b)
clusters.append(new_cluster)
# 更新距离矩阵
new_dist_row = np.min(distance_matrix[cluster_a, :][:, cluster_b], axis=1) # 计算合并后的簇与其他簇的距离
distance_matrix = np.delete(distance_matrix, cluster_b, axis=0) # 删除已合并簇的行
distance_matrix = np.delete(distance_matrix, cluster_b, axis=1) # 删除已合并簇的列
distance_matrix = np.column_stack((distance_matrix, new_dist_row)) # 添加新簇的距离列
new_dist_col = np.append(new_dist_row, np.inf) # 新簇与其他簇的距离
distance_matrix = np.row_stack((distance_matrix, new_dist_col)) # 添加新簇的距离行
# 返回聚类结果
labels = np.zeros(len(X))
for idx, cluster in enumerate(clusters):
for sample in cluster:
labels[sample] = idx
return labels
# 示例数据
np.random.seed(0)
X = np.random.rand(10, 2) # 10个二维数据点
# 执行凝聚型层次聚类
n_clusters = 3
labels = agglomerative_clustering(X, n_clusters=n_clusters)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.title(f'Agglomerative Hierarchical Clustering (n_clusters={n_clusters})')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()代码解析
1. 计算距离矩阵
def compute_distance_matrix(X):
"""
计算样本点之间的距离矩阵
"""
return squareform(pdist(X, metric='euclidean')) # 计算欧氏距离矩阵- 该函数计算数据集中每两个点之间的欧氏距离,并返回一个对称的距离矩阵。
pdist计算所有点之间的成对距离,squareform将它转化为对称矩阵。
2. 凝聚型层次聚类算法
def agglomerative_clustering(X, n_clusters=2):
"""
凝聚型层次聚类实现
:param X: 数据集 (n_samples, n_features)
:param n_clusters: 目标聚类数量
:return: 每个数据点的簇标签
"""- 该函数实现了凝聚型层次聚类的过程。我们从每个数据点开始,每次合并距离最小的两个簇,直到达到预定的簇数量。
3. 簇合并过程
在每一轮合并中,我们计算两个簇之间的最小距离,找到最相似的簇并将它们合并。在合并后,我们更新距离矩阵,删除已合并簇的行和列,并计算新簇与其他簇的距离。
4. 返回标签
合并操作完成后,clusters 变量中存储了每个簇的样本索引。通过遍历这些簇并为每个簇中的点分配一个唯一的标签,最终返回所有样本的簇标签。
5. 可视化
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.title(f'Agglomerative Hierarchical Clustering (n_clusters={n_clusters})')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()- 我们使用
matplotlib绘制了二维数据点的散点图,并为不同簇的点使用不同的颜色表示。c=labels会根据聚类结果为每个点分配不同的颜色。
6. 结果可视化
运行该代码后,您将看到一个二维的散点图,其中每个数据点根据所属的簇被不同颜色标记。图中的 n_clusters=3 表示我们设置了3个簇。如果您修改 n_clusters 参数,可以观察不同簇数下的聚类效果。
总结
凝聚型层次聚类是一种自下而上的聚类方法,它逐步将最相似的簇合并成一个层次结构,直至所有数据点合并为一个簇。尽管该方法计算复杂度较高,但其生成的层次树可以为数据提供丰富的层次信息,帮助理解数据的结构和内在关系。凝聚型层次聚类适用于那些不确定簇数、数据具有层次结构或簇的形态复杂的情况,是一种非常有用的聚类方法。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号