你有一份待查收的 TextIn 文档解析内测邀请函!
原创
你有一份待查收的 TextIn 文档解析内测邀请函!
原创
合合技术团队
修改于 2025-01-13 14:23:07
修改于 2025-01-13 14:23:07
近期,为便捷智能文档处理流程,TextIn文档解析推出内测版本,支持内置参数,完成去水印与切边矫正处理,有效提升解析准确率与输出结果质量。
内测功能详情见下:
1 内置参数,去除图片和PDF水印
实操场景下,部分带有明显水印的文件,会在解析过程中由于水印干扰产生错漏字现象。
TextIn ParseX将去水印功能内置到了产品中,帮助提升解析效果,减少文件另行去水印带来的时间消耗,同时也让代码编写更为便捷。
- 使用示例:
步骤一:登录TextIn官网TextIn - API中心,获取app-id和secret-code。
步骤二:调用官方示例代码:
import requests
import json
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
class TextinOcr(object):
def __init__(self, app_id, app_secret):
self._app_id = app_id
self._app_secret = app_secret
self.host = 'https://api.textin.com'
def recognize_pdf2md(self, image, options):
"""
pdf to markdown
:param options: request params
:param image: file bytes
:return: response
options = {
'pdf_pwd': None,
'dpi': 144, # 设置dpi为144
'page_start': 0,
'page_count': 1000, # 设置解析的页数为1000页
'apply_document_tree': 0,
'markdown_details': 1,
'page_details': 0, # 不包含页面细节信息
'table_flavor': 'md',
'get_image': 'none',
'parse_mode': 'scan', # 解析模式设为scan
}
"""
url = self.host + '/ai/service/v1/pdf_to_markdown'
headers = {
'x-ti-app-id': self._app_id,
'x-ti-secret-code': self._app_secret
}
return requests.post(url, data=image, headers=headers, params=options)
if __name__ == "__main__":
# 请登录后前往 “工作台-账号设置-开发者信息” 查看 app-id/app-secret
textin = TextinOcr('#####c07db002663f3b085#####', '######1b1b11a9f9bcd7cc7b######')
image = get_file_content('file/example.pdf')
resp = textin.recognize_pdf2md(image, {
'page_start': 0,
'page_count': 1000, # 设置解析页数为1000页
'table_flavor': 'md',
'parse_mode': 'scan', # 设置解析模式为scan模式
'page_details': 0, # 不包含页面细节
'markdown_details': 1,
'apply_document_tree': 1,
'dpi': 144 # 分辨率设置为144 dpi
})
print("request time: ", resp.elapsed.total_seconds())
result = json.loads(resp.text)
with open('result.json', 'w', encoding='utf-8') as fw:
json.dump(result, fw, indent=4, ensure_ascii=False)步骤三:将下列去水印的参数集成到代码中,替换上述源代码中的48-62行
resp = textin.recognize_pdf2md(image, {
'remove_watermark':1, # 去水印功能的控制参数
'get_image': 'objects'
})
result = json.loads(resp.text)
filepath = 'pdf2md_remove_watermark.md'
with open(filepath, 'w', encoding='utf-8') as f:
f.write(result['result']['markdown'])步骤四:运行最终替换好的代码并得到去水印后识别更精准的解析文件。
- 效果示例:
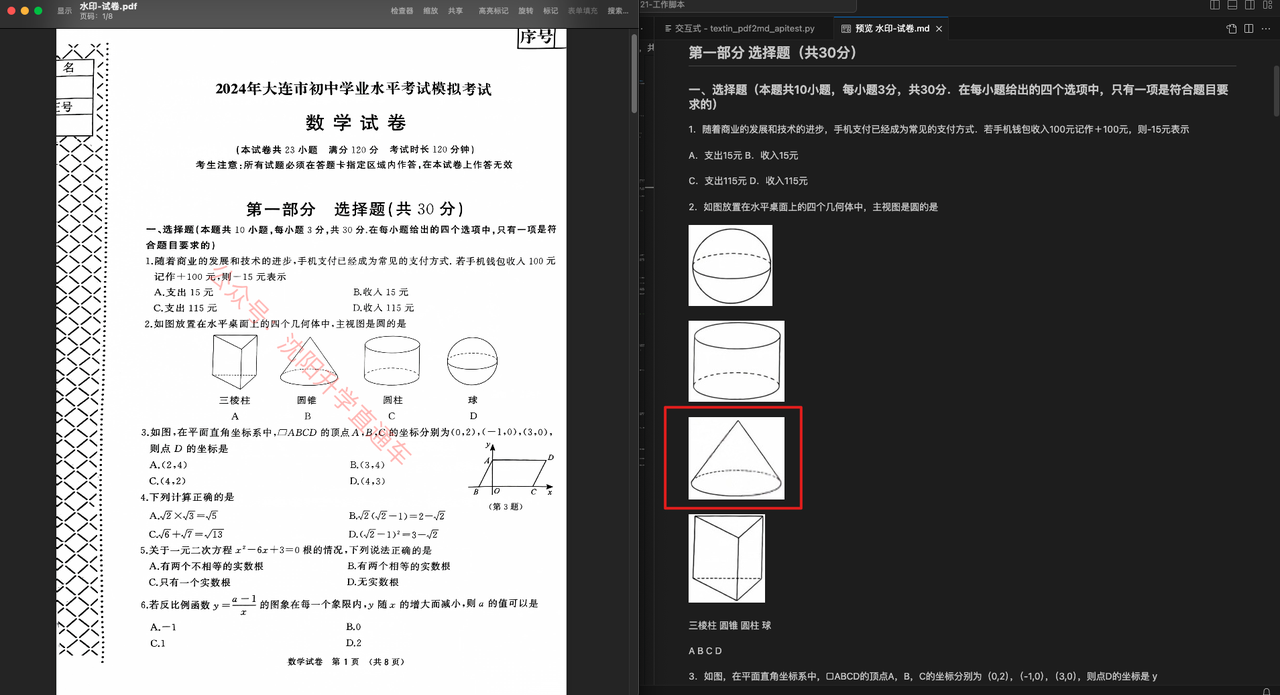

可以看到,不仅解析结果中全文没有出现水印上的文字内容,还一并去除了图片上的水印,用户可以轻松提取到干净的文字及插图。
- 注意事项:
- 去水印参数支持图片、PDF、word文件;
- 目前去水印的能力擅长解决倾斜文本,对于图片类、logo文字、横排文字的去除效果有待提升,还请理解。
2 内置图片切边矫正参数,提升识别效果
内测版本还支持用户内置图片切边矫正能力,用于提升拍摄角度不正或歪曲变形的照片的识别效果。
- 常用场景:医疗报告单据、征信报告、作业照片等
- 使用示例:
步骤一:登录TextIn官网TextIn - API中心,获取app-id和secret-code。
步骤二:调用官方示例代码
步骤三:将下列切边矫正增强功能的参数集成到代码中,一键替代源代码中的48-62列
resp = textin.recognize_pdf2md(image, {
'crop_enhance':1, # 切边矫正增强功能的控制参数
})
result = json.loads(resp.text)
filepath = 'pdf2md_remove_watermark.md'
with open(filepath, 'w', encoding='utf-8') as f:
f.write(result['result']['markdown'])步骤四:运行最终替换好的代码并得到切边矫正后识别更精准的解析文件。
- 效果示例:
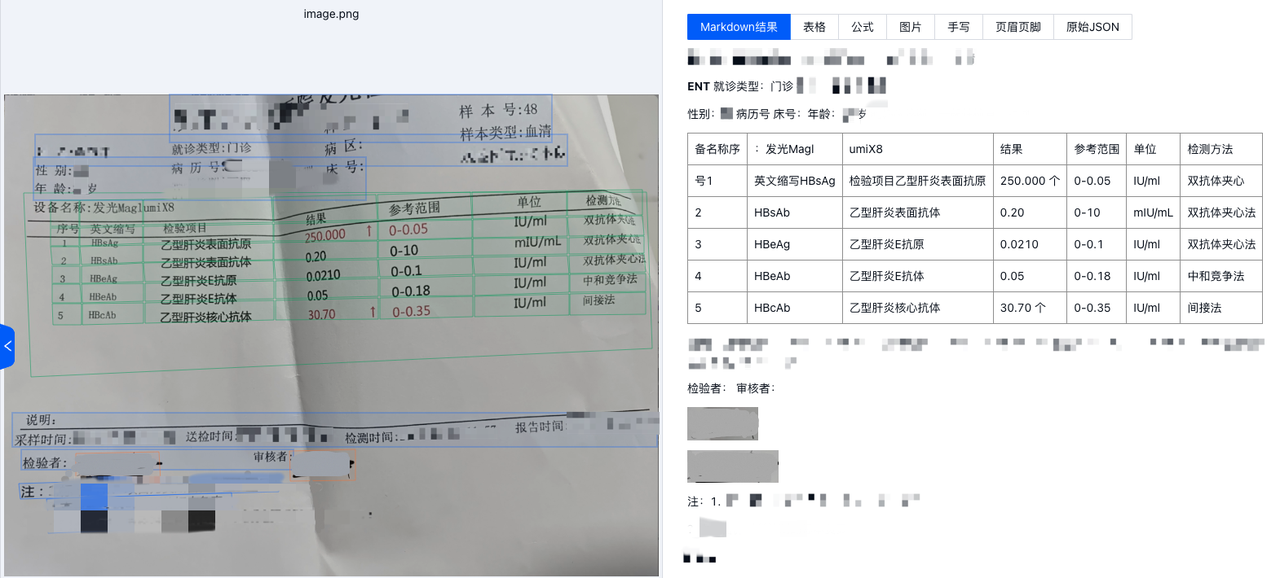
无切边矫正的效果
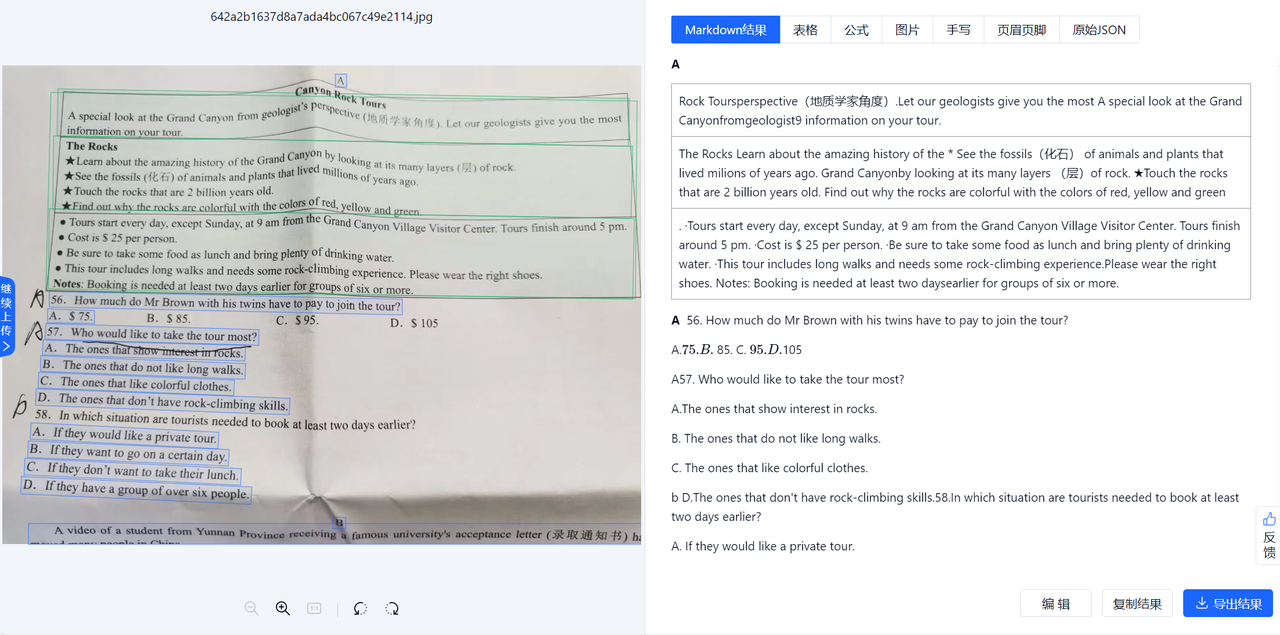
无切边矫正的效果
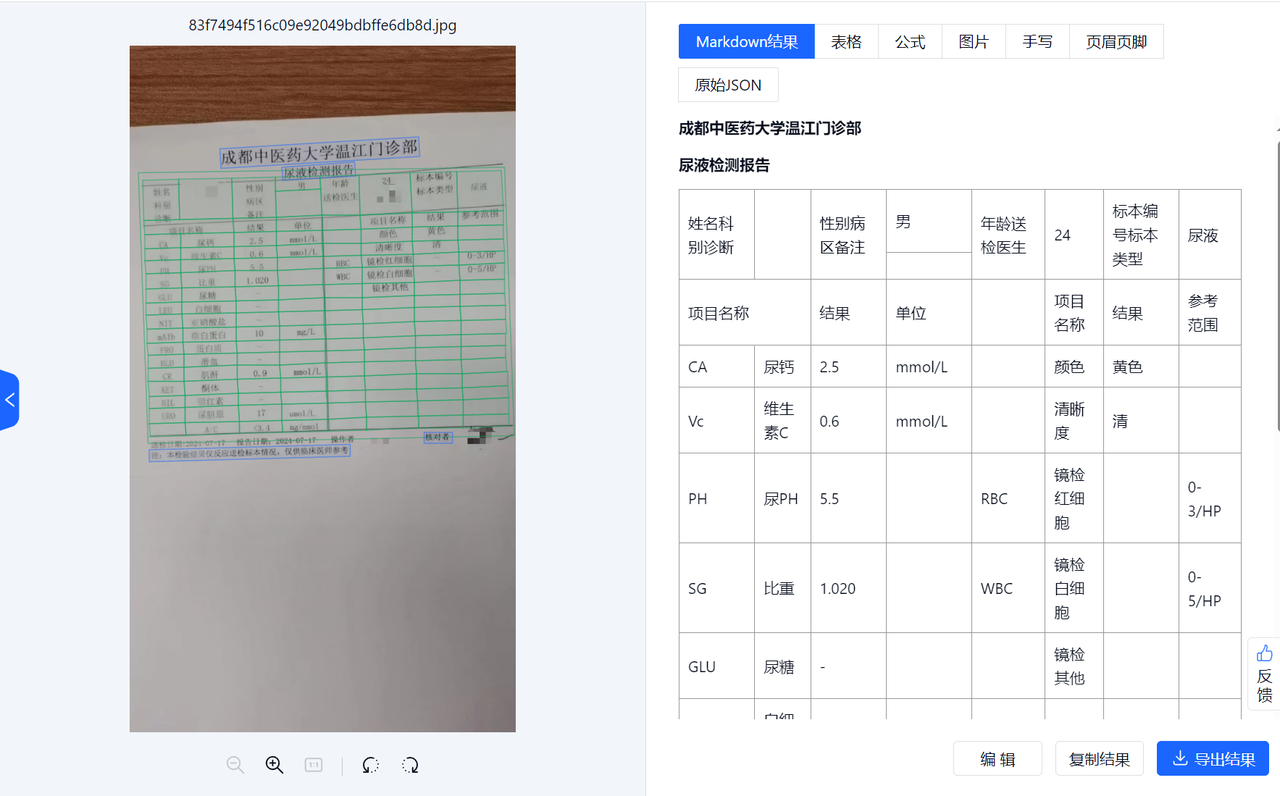
无切边矫正的效果
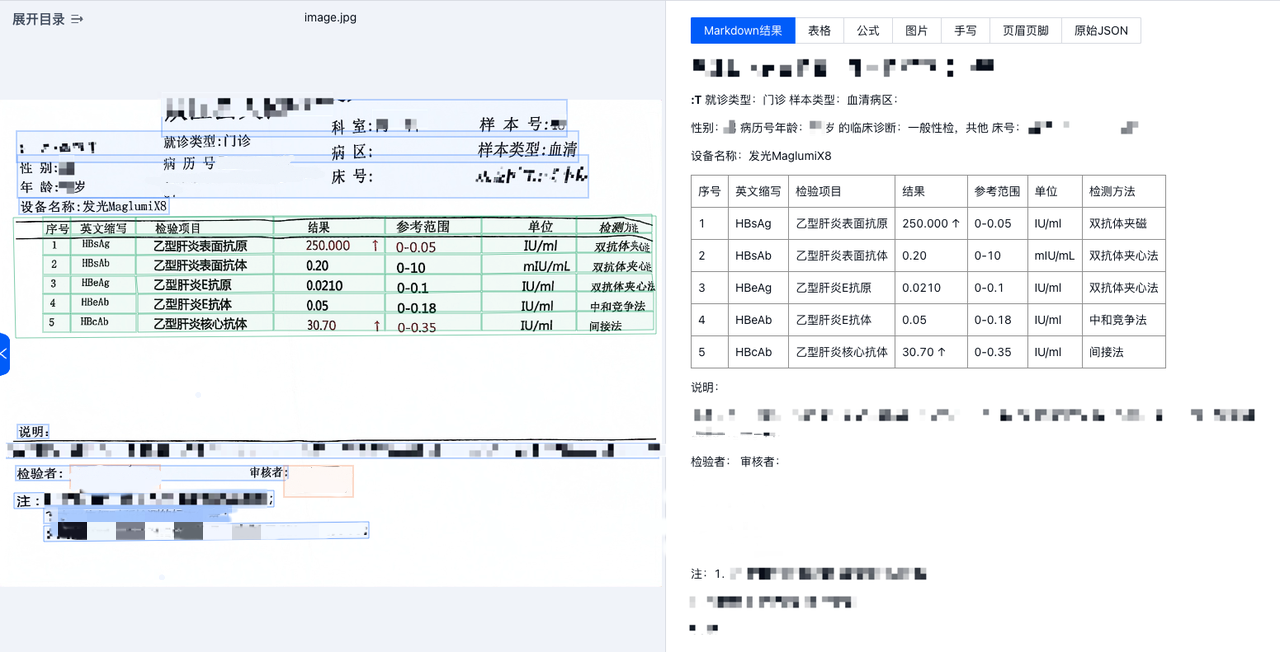
切边矫正之后的效果
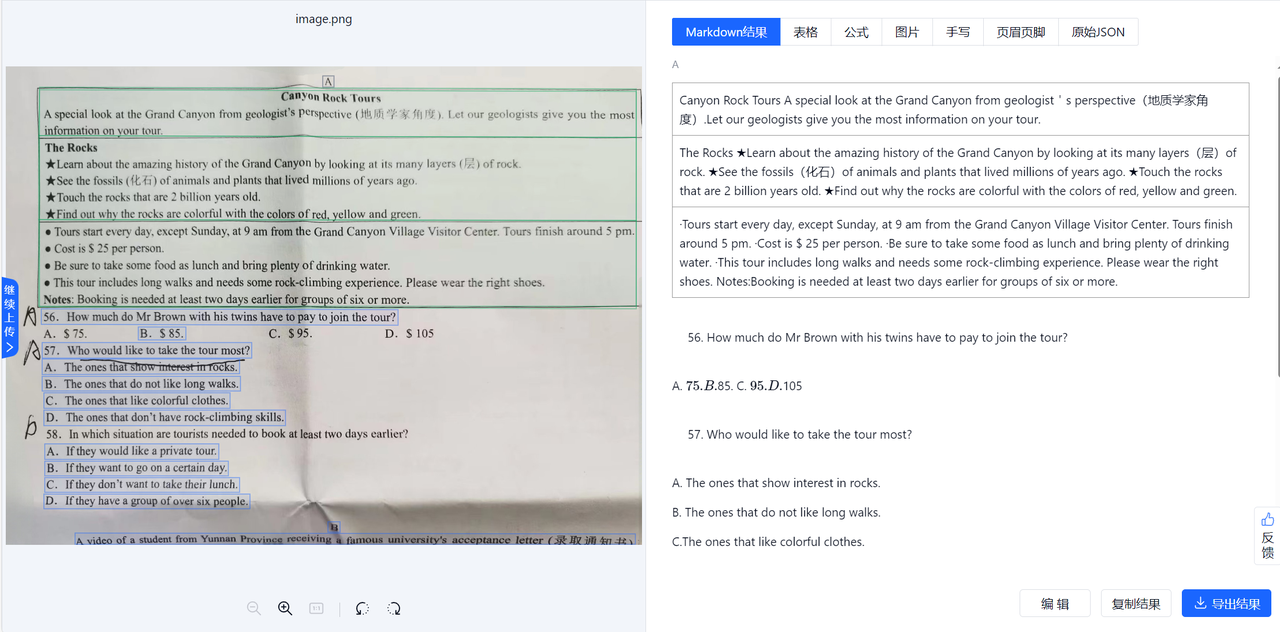
切边矫正之后的效果
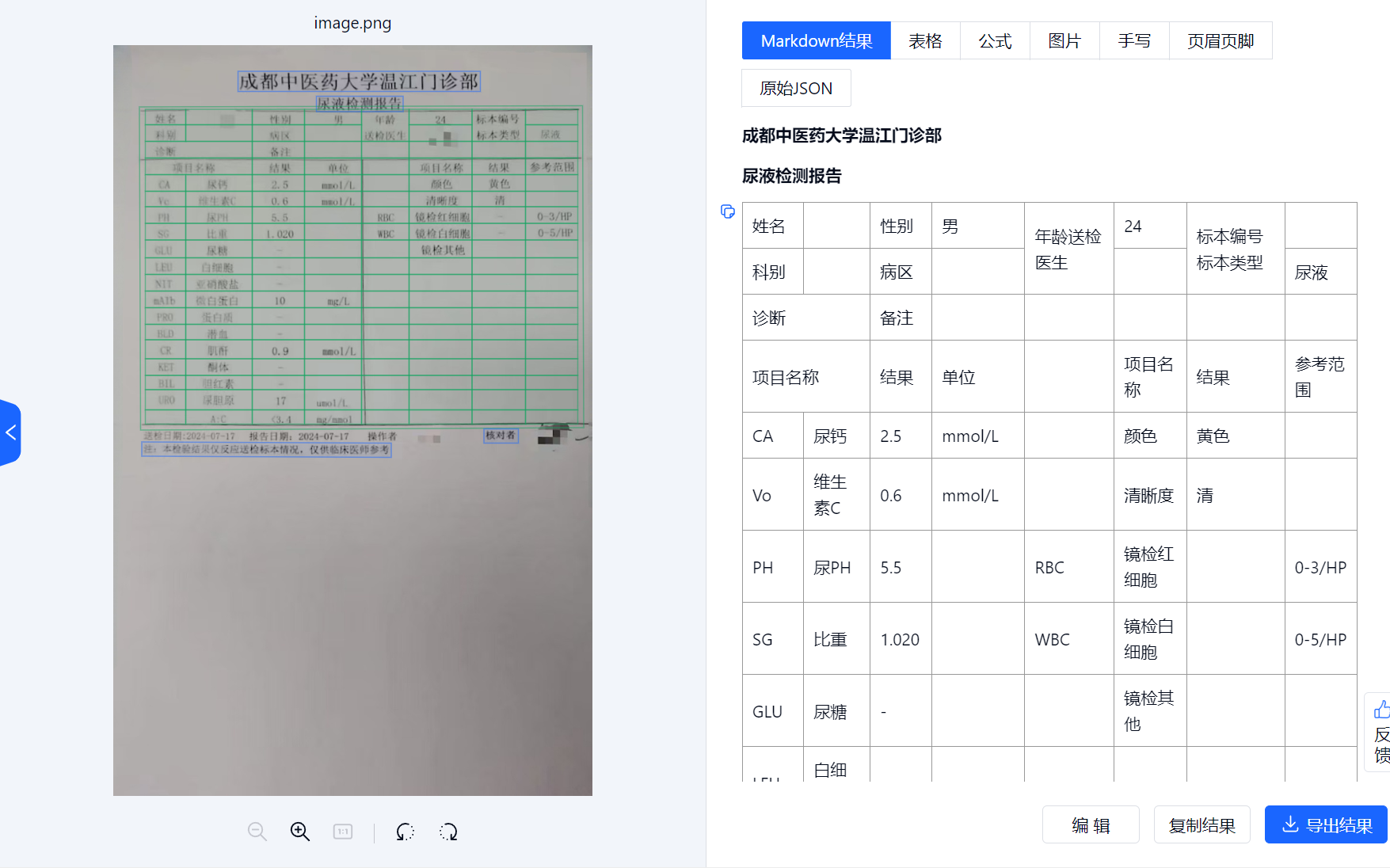
切边矫正之后的效果
可以看到,在矫正之后,表格的解析准确率有显著提高,同时,表格边框错误的问题也得到了优化。
- 注意事项:
切边矫正的能力存在上限,并不能完美解决所有照片歪曲的问题,如有可能,建议尽量保证输入图片的质量。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号