数据裁剪偶遇【enq: TX - index contention】
原创
数据裁剪偶遇【enq: TX - index contention】
原创
布衣530
发布于 2025-01-11 12:19:19
发布于 2025-01-11 12:19:19
背景
每月将对数据库超大表进行数据裁剪,原理是通过 alter table <table_name> truncate partition (partition_name) update indexes 命令在truncate 分区的同时对索引进行更新。生产经验告诉我:“不加update indexes 会导致全局索引失效”。 裁剪任务每月凌晨自动执行,今天正好是裁剪任务执行完成,开发反馈:“裁剪任务期间订单失败率偏高”,根据开发提供的时间段查看执行日志,发现当时正是在裁剪:AATD_DTL(脱敏处理)表。
一、AWR 分析
DB Time : 2,739.51 (mins)
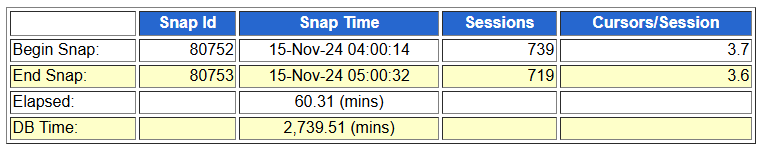
等待事件:enq: TX - index contention
- 常出现在高并发场景下,由于索引分裂产生的竞争等待。 可以认为一个session在向一个索引块中执行插入时产生了索引块的split,而其它的session也要往该索引块中插入数据,此时,其它session必须要等待split完成,由此引发了该等待事件。
- 而这些对象可以从 V$SEGMENT_STATISTICS 或从 AWR 报告中的“Segments by Row Lock Waits”或“Segments by ITL Waits”或“Service ITL Waits”中找到。
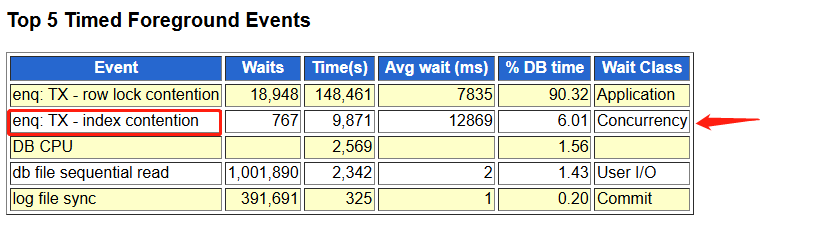
Segments by ITL Waits
- 标明获得ITL等待最严重的对象,如果发现了ITL等待很严重的对象,则应该将对象的initrans参数设置为并发操作该对象的进程个数;
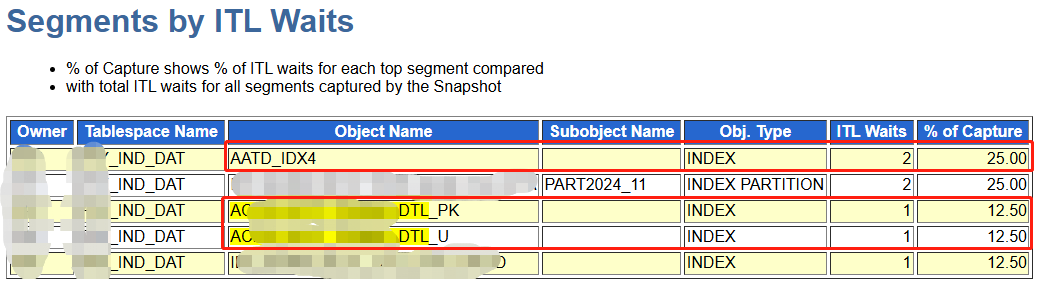
Segments by Row Lock Waits
- 获得行级锁最严重的对象
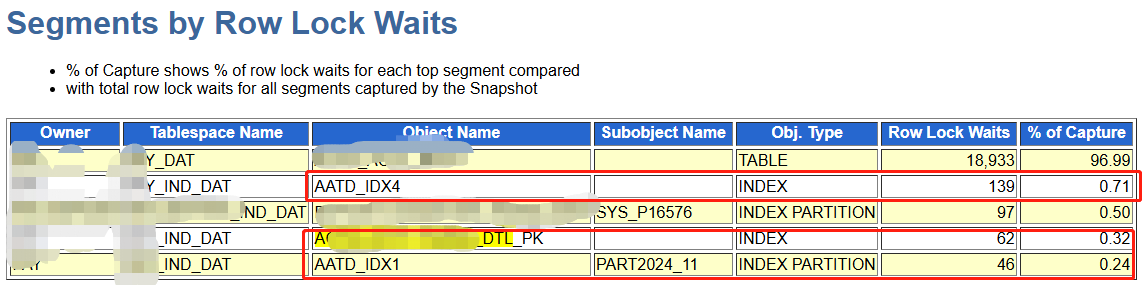
根据AWR报告及AATD_DTL涉及索引分析
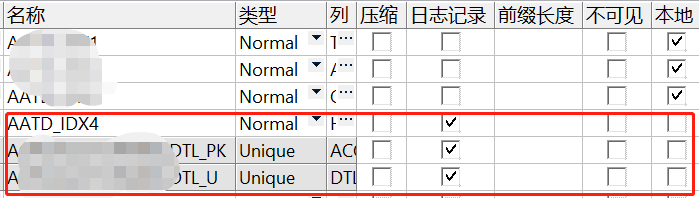
- 根据AWR分析涉及索引:AATD_IDX4、A_DTL_PK、A_DTL_U 为全局索引,其它本地索引未上AWR报告。
- truncate的分区数据为3千万然后再update index操作维护全局索引, 再加上业务的并发DML操作,导致此表上的AATD_IDX4、A_DTL_PK、A_DTL_U三个全局索引频繁分裂从而产生enq: TX - index contention事件,导致此表的插入、更新变慢,从而导致订单超时失败。
二、解决方案
- 1.将索引重建为反向键索引或散列分区 反向键索引旨在消除插入应用程序上的索引热点。 这些指标非常适合插入操作的性能。 但它的缺点是它可能影响索引范围扫描的性能。
CREATE INDEX <index name> ON <column> REVERSE- 2.将索引重建为:哈希分区索引 由于索引页,缓冲区,更新锁存器和附加索引维护活动的争用,索引的右边缘成为热点。HASH索引可以降低分裂块的急用,原理:通过HASH算法分散争用块,可以并发操作索引叶子节点,降低index block上的并发,从而降低索引分裂带来的性能。
CREATE INDEX <index name> ON <table name >(<column>) GLOBAL PARTITION BY HASH (<column>) PARTITIONS <part_num>- 3.在大量数据清除后需要对索引进行重建,重建(online 支持在线)或缩小关联的索引有助于减少等待。
-- 分区索引重建
alter index <index name> rebuild partition <partition name> online tablespace <tablespace name>;
-- 索引重建
alter index <index name> rebuild online tablespace <tablespace name>;- 4.增加索引的 PCT_FREE PCT_FREE 有助于避免索引块的 ITL 争用。当一个区块内的所有可用 ITL 当前正在使用中,而且 Oracle 的 PCT_FREE 区域没有足够的空间来动态分配新的 ITL 插槽,那么将发生 ITL 争用。
- 注:重建索引建议通过在线重定义操作。
三、确定最终解决方案
- 1、主键、唯一索引重建为:Hash索引;
- 2、其它全局索引重建为:本地索引(truncate 分区时减少索引维护);
- 3、定期对裁剪表的索引重建:rebuild,频率:1年一次;
- 总结:通过以上3个策略,缓解enq: TX - index contention事件出现频率。
四、测试Hash索引对enq: TX - index contention 降低影响
1、创建分区表:T1;索引:pk_t1_id
create table t1
( id varchar2(50),
session_id varchar2(5), -- session id
create_date date) -- 创建日期
PARTITION BY RANGE(create_date)INTERVAL(numtoyminterval(1,'month'))
(PARTITION part202107 VALUES LESS THAN(TO_DATE('20210801','yyyymmdd')),
PARTITION part202108 VALUES LESS THAN(TO_DATE('20210901','yyyymmdd'))
);
-- 索引
alter table t1 add constraint pk_t1_id primary key (id)
using index tablespace two_ind_dat;
-- 序列
drop SEQUENCE t1_seq;
CREATE SEQUENCE t1_seq
START WITH 1
INCREMENT BY 1
MINVALUE 1
MAXVALUE 9999999
CACHE 2000;2、创建存储过程:proc_insert
create or replace procedure proc_insert(v_tab_name varchar2)
as
v_month number;
v_day number;
v_sid varchar2(10);
v_part_date varchar2(20);
v_seq varchar2(20) := v_tab_name||'_seq.NEXTVAL';
v_sql varchar2(500);
begin
select USERENV('SID') into v_sid from dual;
for x in 1..10 loop
v_month := mod(x,12);--月份
if v_month = 0 then
v_month:=12;
end if;
v_day :=mod(x,28); --日
if v_day = 0 then
v_day:=28;
end if;
v_part_date:='2024-'||to_char(v_month)||'-'||to_char(v_day);
v_sql:='insert into '||v_tab_name||' (id, session_id,CREATE_DATE) values('||v_seq||','''||v_sid||''' ,to_date('''||v_part_date ||''','||'''yyyy-mm-dd'''||'))';
-- dbms_output.put_line(v_sql);
execute immediate v_sql;
commit;
end loop;
end;3、创建并发JOB
- 创建JOB:200 并发 每秒向 T1 表插入
declare
v_job pls_integer;
begin
for i in 1 .. 200 loop
dbms_job.submit(v_job,
what => 'BEGIN proc_insert(''t1''); END;',
next_date => sysdate,
Interval => 'sysdate+ 1/(24 * 60 * 60)');
commit;
end loop;
end;
/- 删除JOB
declare
CURSOR c1
IS
select job from user_jobs where schema_user='TWO';
BEGIN
for v_c in c1
loop
dbms_job.remove(v_c.job);
-- dbms_output.put_line('drop job:'||v_c.job|| 'succeed');
end loop;
END;
/4、查看等待事件
col event for a45
SELECT inst_id,EVENT, SUM(DECODE(WAIT_TIME, 0, 0, 1)) "Prev", SUM(DECODE(WAIT_TIME, 0, 1, 0)) "Curr", COUNT(*) "Tot" , sum(SECONDS_IN_WAIT) SECONDS_IN_WAIT
FROM GV$SESSION_WAIT
WHERE event NOT
IN ('smon timer','pmon timer','rdbms ipc message','SQL*Net message from client','gcs remote message')
AND event NOT LIKE '%idle%'
AND event NOT LIKE '%Idle%'
AND event NOT LIKE '%Streams AQ%'
GROUP BY inst_id,EVENT
ORDER BY 1,5 desc;
5、查看表数据
SQL> select session_id,count(*) from t1 group by session_id;
SESSI COUNT(*)
----- ----------
1423 1050
1481 1170
972 10
1350 570
849 1210
967 1090
528 1040
......略6、创建分区表:T3 ;Hash索引:pk_t3_hash_id
create table t3
( id varchar2(50),session_id varchar2(5),create_date date)
PARTITION BY RANGE(create_date)INTERVAL(numtoyminterval(1,'month'))
(PARTITION part202107 VALUES LESS THAN(TO_DATE('20210801','yyyymmdd')),
PARTITION part202108 VALUES LESS THAN(TO_DATE('20210901','yyyymmdd'))
);
-- 索引
alter table t3 add constraint un_t3_hash_id unique (id)
using index (CREATE UNIQUE INDEX pk_t3_hash_id ON t3(ID)
TABLESPACE two_ind_dat GLOBAL PARTITION BY HASH(ID)PARTITIONS 64 );
-- 序列
drop SEQUENCE t3_seq;
CREATE SEQUENCE t3_seq
START WITH 1
INCREMENT BY 1
MINVALUE 1
MAXVALUE 9999999
CACHE 2000;7、操作同T1,略
8、T1、T3 1小时AWR报告对比分析
- 负载下降:61.49%

- TOP 5 等待事件:enq: TX - index contention 消失

- Segments by ITL Waits 变化:No data exists

9、测试对比小结:
- 由此对比Hash索引降低enq: TX - index contention事件很明显,对Insert 并发负载下降同样很明显;
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号