时序论文35|LPTM:用于跨领域时序任务预训练模型(引入动态切分)

时序论文35|LPTM:用于跨领域时序任务预训练模型(引入动态切分)

科学最Top
发布于 2025-01-09 20:32:39
发布于 2025-01-09 20:32:39

论文标题:Large Pre-trained time series models for cross-domain Time series analysis tasks
论文链接:https://arxiv.org/abs/2311.11413
论文链接:https://github.com/AdityaLab/Samay
前言
先来说说这篇文章的核心贡献吧。虽然洋洋洒洒篇幅很长,其实最重要的创新点就一个,可以概括为:针对时间序列分析任务中从多领域异构数据提取有效输入的难题,设计了自适应分割模块,它依据自监督预训练损失确定各领域最优分割策略,克服了以往固定长度分割的局限。
并以此为基础,提出了大规模预训练模型 LPTM,本文并没有对backbone从模型的角度进行改进,核心创新主要还是上面说的自适应分割,使 LPTM 在不同领域数据集上能灵活适应。据作者所述,该模型在零样本和微调场景下均优于众多基线模型,且所需数据(减少约40%)和训练时间(减少约50%)更少。
本文模型
整体思路也非常简单,分两步,先基于不同领域的数据集进行预训练,然后放入到原transformer。
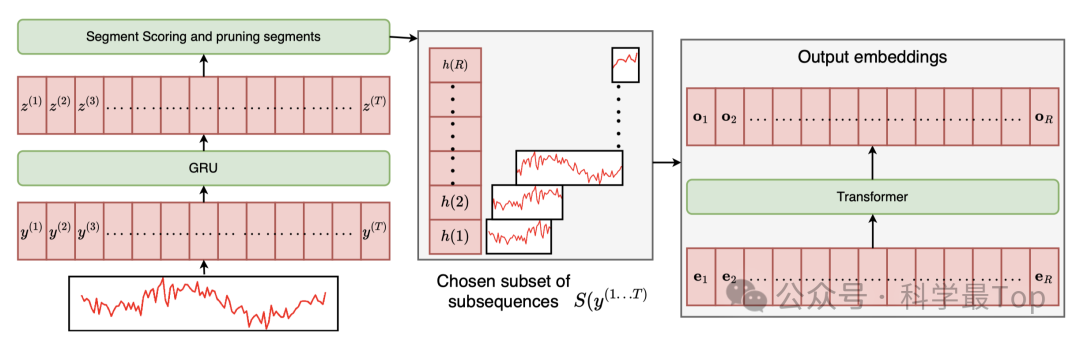
01 出发点
先看预训练部分,这一部分的核心就是上文说的Adaptive Segmentation module。自从patch TST之后,大多数基于transformer的时序都是将输入时间序列分割成等长的片段,并将每个片段作为token输入到模型中。但是,固定大小的token也过于僵化,无法捕捉在时间和数据集之间表现出不同行为的序列的语义。
具体来说,不同的预训练数据集可能具有不同的时间尺度、周期性。例如,疫情时间序列通常每周观察一次,可能具有季节性、峰值和突然爆发等特征。相比之下,经济数据通常每季度采集一次,数据分布更单调,有突然的异常和变化。其实对于时间戳更密集的数据,需要比其他松散的数据进行更精细的分割。
02 如何切分?
首先要知道文中说的SSL loss,SSL 是 Self - Supervised Learning(自监督学习)的缩写,SSL loss 即自监督学习损失。用于评估自监督学习任务的性能。那么很自然的,在预训练阶段,可以通过寻找让 SSL loss 尽可能低的分割策略,帮助模型更好地捕捉时间序列内在结构和模式。

上面就是Adaptive Segmentation module的算法流程部分,其实本质上就是一种枚举策略,可以分为三部分:
- 第一块是打分,这里作者把序列过了一层GRU获得序列表示,然后通过双层循环枚举每种切分可能,并根据公式获得切分的评分值。
- 第二块是选择,枚举每个起始位置对应的最高切分方式。比如:第i时刻,切分方式可能有(i,j),(i,j+1)等等。选出每个起始时刻的最高分。很明显这种选择方式一定能保证切分的序列是连续的,但大概率是有重叠。
- 第三块是去重,因为上一步选择过程大概率是有重复,所以这一步在之前的集合中,从评分最低的序列开始剔除,直到序列不连续为止。这样就获得了变长的patch切分集合。
03 如何训练
由于每个patch的长度不相等,这样的数据实际是无法并行训练的。所以作者使用self-attention获得不同切片的向量表示,这一步使切片长度得到统一。
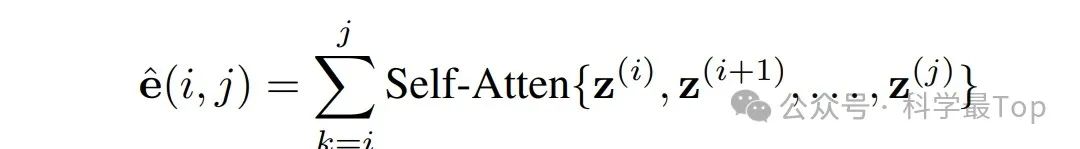
以上就是论文的主要创新点,剩下的训练和分析其实没什么好说的,大家感兴趣的可以看原文,对了这篇论文是发表在NIPS2024上。
实验结论

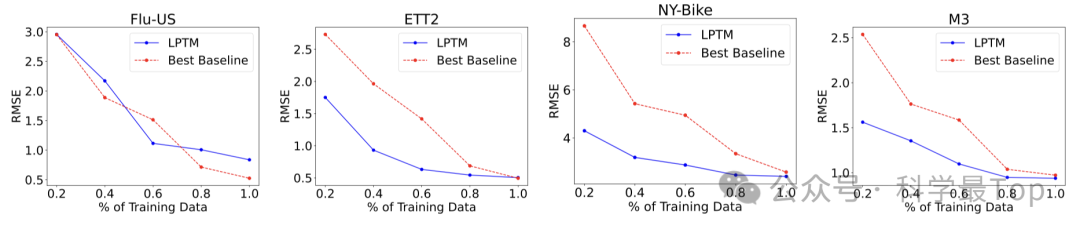
LPTM 与现有先进模型相比,使用更少的预训练数据、训练数据以及更少的训练步骤就能达到与之相当的性能水平,并且在零样本设置下也能有良好的表现,表明作者提出的自适应分割方法以及整个 LPTM 框架在处理跨领域时间序列数据时的有效性和优势。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-01-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号