Triton Inference Server调研
原创
Triton Inference Server调研
原创
aaronwjzhao
修改于 2025-01-14 10:23:43
修改于 2025-01-14 10:23:43
整体框架
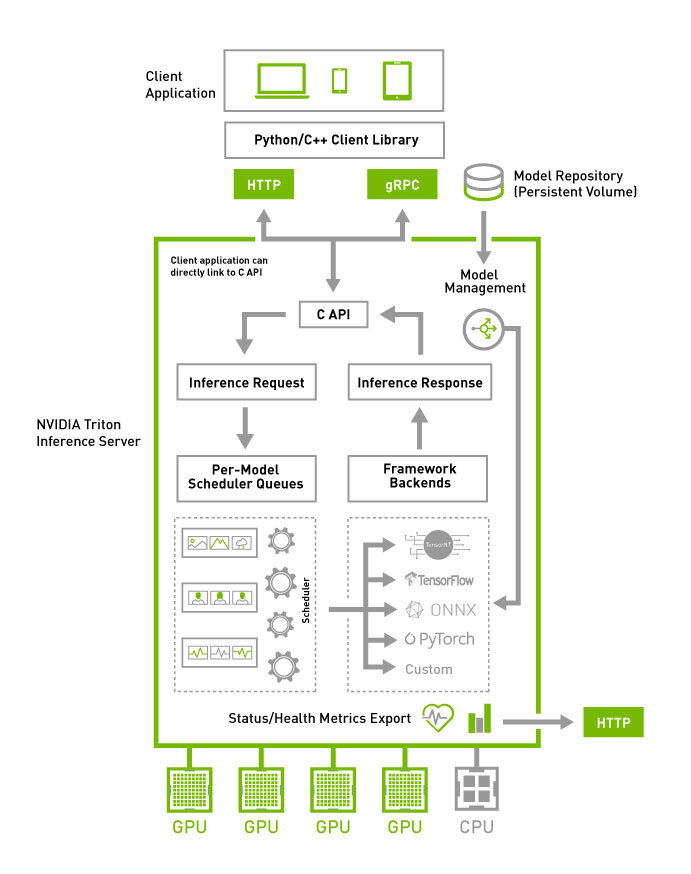
Triton Architecture Diagram
用户请求通过HTTP或gRPC接口发送到triton server,triton根据支持的多种调度策略、批量算法,把请求路由到不同的框架后端(如Pytorch、ONNX等)。
框架后端执行完,返回结果到server,server层返回给用户。
服务层功能
- 框架后端支持情况:目前已经支持TensorRT-LLM、vLLM、Python Backend、Pytorch Backend、onnxruntime、TensorFlow、TensorRT、FIL、DALI等后端
- Response Cache:根据模型名字、模型版本、输入prompt缓存对应的输出,可以选择缓存到内存、redis数据库(也支持用户自己拓展新的缓存类型)。如果遇到同样的prompt,可以直接返回给用户,缓解框架后端负载。
- Ensemble Scheduler:一个或多个模型串联的pipeline(有向无环图)
- Rate Limiter:限流模块,根据资源情况决定请求什么时间执行,保证用户请求较多时,系统的稳定。
- 请求取消:检测grpc客户端取消请求,在server层、框架后端层都可以中断处理,框架后端层的中断机制需要不同的后端自己支持。
- Dynamic Batcher:在server层收到请求后,在一定时间内等待其他请求,拼成batch给backend模型。可以提高吞吐量
- 并发模型执行:允许多个模型、一个模型的多个实例同时在一个系统内执行
- 隐式状态管理:在多个请求间保存中间状态,需要对应的backend也支持,目前只有onnxruntime、tensorrt、pytorch支持
模型管理
模型文件存储支持本地文件系统、Google Cloud Storage、Amazon S3、Azure Storage等,目录结构需要按照统一的格式,如下所示:

模型存储样例
config.pbtxt是配置文件,可以配置使用的框架后端、输入输出、batch size、使用哪些推理加速技术等,实例如下:

config.pbtxt配置样例
模型控制模式
对于正在运行的triton server模型服务,如果模型文件发生了更新,可以发送load/unload操作到triton server,可以支持三种模式的更新策略。
- NONE:不支持模型更新
- EXPLICIT:手动触发模型更新(给server发送HTTP/gRPC请求),加载失败,原模型不会被更新,不会影响用户体验
- POLL:Triton框架会定期检查模型仓库的更改,自动加载新的模型,且加载失败,原模型不会被更新。
资源扩展
多节点
当部署一个分布式模型时,将创建一个“leader”节点和一些“workers”节点,以满足模型的并行性要求。
- leader节点负责处理推理请求和响应功能,以及推理请求tokenizer和结果decode。
- worker提供了扩展的GPU计算和内存容量
多实例
自动缩放使基于LLM的服务能够根据当前负载自动分配和释放资源,适应当前的工作量强度。
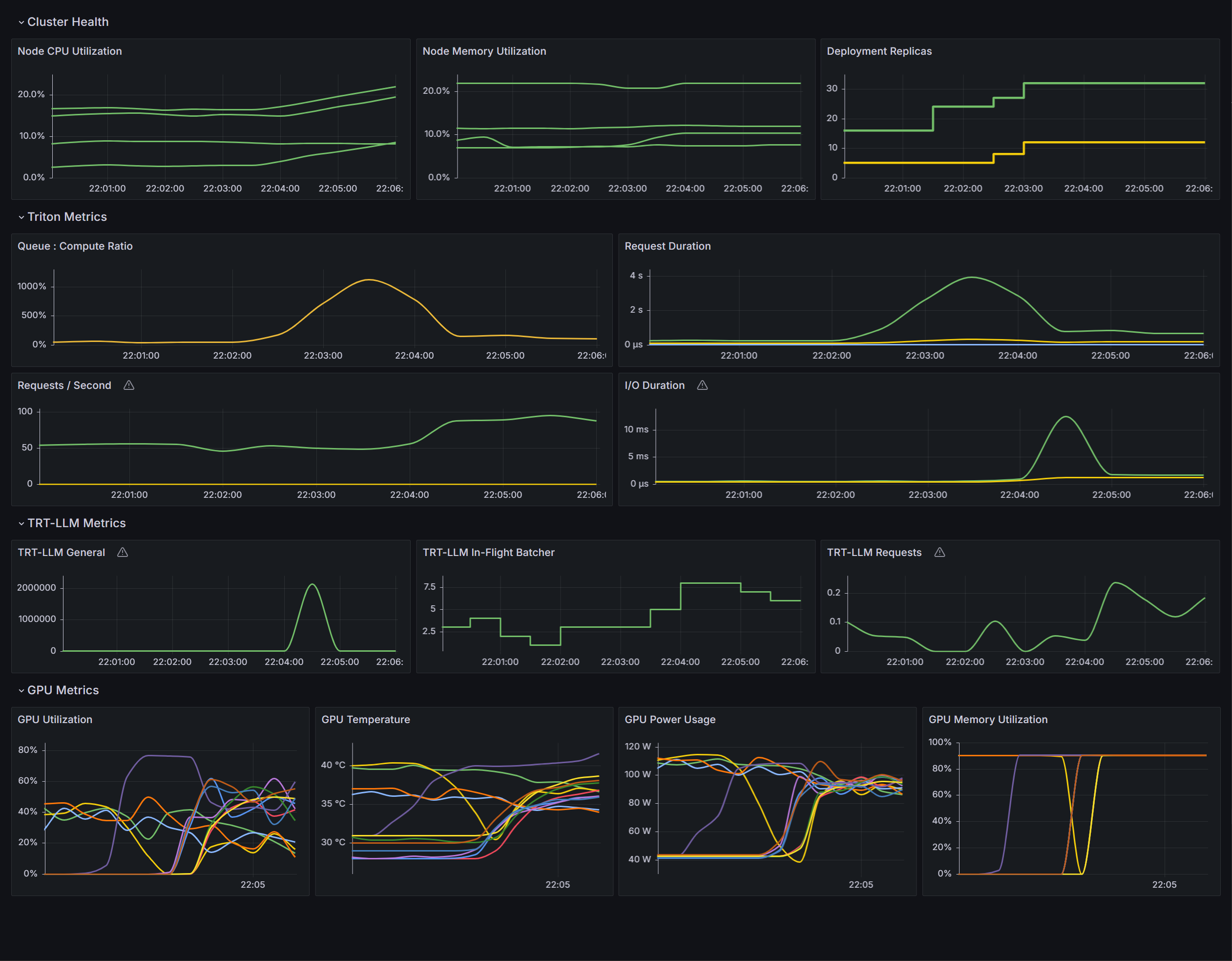
多实例监控
AI Agent
约束解码
通过施加特定的约束,确保生成的输出符合预定义的标准,如长度、格式或内容限制。比如让模型输出JSON结构的数据
函数调用
函数调用是一种强大的机制,它允许llm执行更复杂的任务(例如,多代理系统中的代理编排),这些任务需要超出其固有知识的特定计算或数据检索。
通过识别何时需要一个特定的功能,llm可以动态地扩展它们的功能,使它们在实际应用程序中更加通用和有用。
模型支持情况
模型类型 | 模型列表 |
|---|---|
文生文 | 常见模型都支持 |
多模态 | Llava1.5-7B |
文生图 | stable-diffusion-v1-5stable-diffusion-xl |
项目结构
server(triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge inferencing solution.):对用户的入口,包含http和grpc协议相关的实现
core(triton-inference-server/core: The core library and APIs implementing the Triton Inference Server.):框架核心库,包含推理后端定义、缓存定义及核心功能的执行过程
各种推理框架后端:
- vllm:triton-inference-server/vllm_backend
- pytorch:triton-inference-server/pytorch_backend: The Triton backend for the PyTorch TorchScript models.
- python:triton-inference-server/python_backend: Triton backend that enables pre-process, post-processing and other logic to be implemented in Python.
- tensorrt-llm:triton-inference-server/tensorrtllm_backend: The Triton TensorRT-LLM Backend
- dali:triton-inference-server/dali_backend: The Triton backend that allows running GPU-accelerated data pre-processing pipelines implemented in DALI's python API.
- onnxruntime:triton-inference-server/onnxruntime_backend: The Triton backend for the ONNX Runtime.
- openvino:triton-inference-server/openvino_backend: OpenVINO backend for Triton.
- .......
请求cache设备:
- redis:triton-inference-server/redis_cache: TRITONCACHE implementation of a Redis cache
- 本地内存:triton-inference-server/local_cache: Implementation of a local in-memory cache for Triton Inference Server's TRITONCACHE API
Demo运行
安装docker:
sudo apt install docker.io拉取镜像,本文选择vllm作为执行后端,docker镜像站:Triton Inference Server | NVIDIA NGC:
docker pull nvcr.io/nvidia/tritonserver:24.12-vllm-python-py3安装nvidia container toolkit:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit启动triton server:
sudo docker run --gpus '"device=1"' -it --net=host --rm -p 8000:8000 --shm-size=1G --ulimit memlock=-1 --ulimit stack=67108864 -v ./:/work -w /work nvcr.io/nvidia/tritonserver:24.12-vllm-python-py3 tritonserver --model-repository ./model_repositoryAPI调用:
$ curl -X POST localhost:8000/v2/models/vllm_model/generate -d '{"text_input": "What is Triton Inference Server?", "parameters": {"stream": false, "temperature": 0}}'网页访问,本文选择gradio来编写简单的demo页面(是一个可以用python来构建深度学习web页面的开源库,gradio-app/gradio: Build and share delightful machine learning apps, all in Python. 🌟 Star to support our work!
):
import argparse
import json
import gradio as gr
import requests
def http_bot(prompt):
headers = {"User-Agent": "vLLM Client"}
pload = {
"text_input": prompt,
"parameters": {
"stream": False,
"temperature": 0
}
}
response = requests.post(args.model_url,
headers=headers,
json=pload,
stream=True)
for chunk in response.iter_lines(chunk_size=8192,
decode_unicode=False,
delimiter=b"\0"):
if chunk:
data = json.loads(chunk.decode("utf-8"))
print(data)
output = data["text_output"]
yield output
def build_demo():
with gr.Blocks() as demo:
gr.Markdown("# Triton Inference Server\n")
inputbox = gr.Textbox(label="Input",
placeholder="Your sentence here and press ENTER")
outputbox = gr.Textbox(label="Output",
placeholder="Generated result from the model")
inputbox.submit(http_bot, [inputbox], [outputbox])
return demo
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--host", type=str, default="0.0.0.0")
parser.add_argument("--port", type=int, default=8005)
parser.add_argument("--model-url",
type=str,
default="http://localhost:8000/v2/models/vllm_model/generate")
args = parser.parse_args()
demo = build_demo()
demo.queue().launch(server_name=args.host,
server_port=args.port,
share=True)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号