AIGC之VAE详解与代码实战


1 简介
参考论文文章: https://arxiv.org/pdf/1312.6114 https://arxiv.org/pdf/1606.05908v2 如下图所示,生成模型的目标是在一个已只分布p(z)中随机采样z,经过网络G,生成的结果x~=G(z)x=G(z)是满足训练数据p(x)的分布,我们假定生成的分布为pgpg,训练样本的分布为pdatapdata,一个非常麻烦的事是我们不知道,也无法去知道pdatapdata的分布,无法去做损失函数求解G。你可以这样理解,我们生成网络的目的是要得到pg=pdatapg=pdata,如果我都知道pdatapdata,我直接在pdatapdata采样不就完事了,还需要生成网络干嘛?让我们来回顾一下GAN网络,GAN怎么做的呢,GAN网络结构引入了D判别器,可以去翻一下前面的GAN,你会发现所有的损失函数是在D网络出来结果的损失,进而去约束G网络,实际上根本没有去求解pdatapdata的分布,通过对D做损失优化,最终G网络生成的pgpg是等于pdatapdata的,不得不佩服D网络引入的巧妙性。
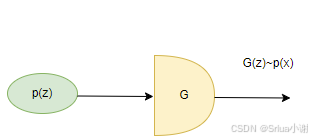
那么VAE是怎么做的,通过我们前面那么多介绍,想必应该很清楚了,单独只有一个G网络,根本是无法实现生成任务的。GAN是在后面加的判别器能更好的求解损失。那么能否在前面加一个什么网络,使我们的损失函数好做一些,能够求解呢,当然VAE便是如此,在前面加上一个解码网络,接下来我们看看VAE这个过程。 模型结构:先简单解释一下流程,Q是一个编码器,输出的结果是均值和方差,在这个均值方差的正太分布上采样一个z,输入解码网络P得到生成的结果。接下来将围绕这个结构来详细说一下VAE。
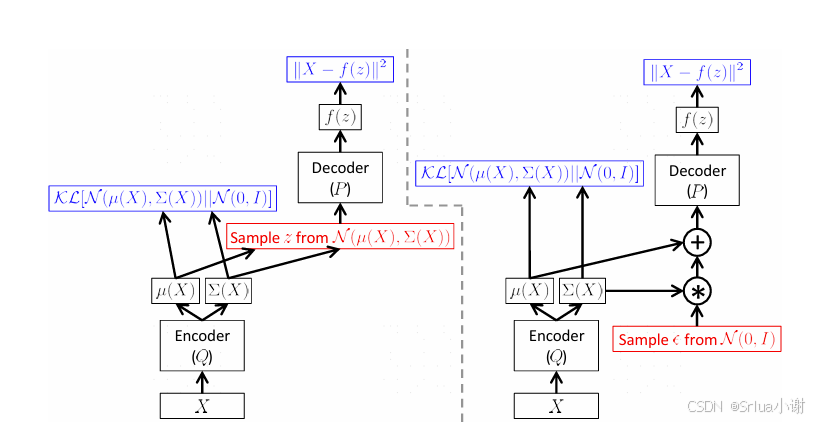
AE自编码器(Autoencoder),是把输入X编码到一个laten space中,通过一个低维向量来表示X。VAE变分自编码器(Variational AutoEncoders),laten space是满足正太分布。由于AE的laten space不是一个分布,无法从laten space采样。而如果想要有生成能力,VAE巧妙的使laten space满足正太分布,这样在正太分布上采样即完成了一个生成模型。 从模型结构我们很好理解VAE这样做是合理的,只要把X编码到一个特定分布的laten space中,从而在这个特定分布采样到解码网络即完成生成,重建损失就是AE的重建损失,为了使laten space满足特定的分布,在加上一个KL散度来约束编码器,而事实上VAE中的V(变分)就是因为VAE的推导就是因为用到了KL散度(进而也包含了变分法)。 这样整个训练和loss也就出来,因为laten space 的分布是我们假定的特定分布(如标准正太分布),因此KL散度是可求的,重建损失也就跟AE是一样的,只需要求输入和最终输出结果的距离即可,简直很完美。然而这些都真是我们想的是这样,背后的理论依据又是怎么样的。
2 理论推导
首先要解释的一点是,样本X={x(i)}1NX={x(i)}1N是独立通分布。首先作者定义了一种分布pθpθ,参数为θθ,输入x与隐变量z的关系可以表示为: pθ(z)pθ(z)表示隐变量z的先验分布; pθ(x∣z)pθ(x∣z)为释然(由果到因); pθ(z∣x)pθ(z∣x)为后验(由因到果)。 接下来作者做了个假设,假设我已经知道了真实参数θ∗θ∗,分为两步:第一步从先验pθ∗(z)pθ∗(z)中采样z(i)z(i);第二步,由pθ(x∣z=zi)pθ(x∣z=zi)可得到x(i)x(i)。那么现在问题变成求解参数θθ,我们就想到释然函数,最优的θθ必然是最后生成x(i)x(i)的概率乘积最大,也就是最大释然函数,我们先把释然函数写出来(用log表示,按照作者原论文形式写出):
log(pθ(x(i),...,x(N)))=∑i=1Nlogpθ(x(i))log(pθ(x(i),...,x(N)))=i=1∑Nlogpθ(x(i))
我们知道pθ(x)=∫pθ(z)pθ(x∣z)dzpθ(x)=∫pθ(z)pθ(x∣z)dz很难求解,上面的释然函数自然没法求解。并且后验pθ(z∣x)=pθ(x∣z)pθ(z)/pθ(x)pθ(z∣x)=pθ(x∣z)pθ(z)/pθ(x)也难求解,怎么办呢。既然这么难解怎么办呢,那就不解了,交给编码网络吧。 引入识别模型,也就是编码网络得到qϕ(z∣x)qϕ(z∣x)近似真实分布pθ(z∣x)pθ(z∣x),而往往用KL散度来描述这两个分布是否近似,因此有以下:
KL(qϕ(z∣x)∣∣pθ(z∣x))=Eqϕ(z∣x)[log(qϕ(z∣x)/pθ(z∣x))]=Eqϕ(z∣x)[logqϕ(z∣x)−logpθ(z∣x)]=Eqϕ(z∣x)[logqϕ(z∣x)−log(pθ(x∣z)pθ(z)/pθ(x))]=Eqϕ(z∣x)[logqϕ(z∣x)−log(pθ(x∣z)−logpθ(z)+logpθ(x))]=Eqϕ(z∣x)[logqϕ(z∣x)−logpθ(z)]−Eqϕ(z∣x)[log(pθ(x∣z)]+logpθ(x)=KL(qϕ(z∣x)∣∣pθ(z))−Eqϕ(z∣x)[log(pθ(x∣z)]+logpθ(x)KL(qϕ(z∣x)∣∣pθ(z∣x))=Eqϕ(z∣x)[log(qϕ(z∣x)/pθ(z∣x))]=Eqϕ(z∣x)[logqϕ(z∣x)−logpθ(z∣x)]=Eqϕ(z∣x)[logqϕ(z∣x)−log(pθ(x∣z)pθ(z)/pθ(x))]=Eqϕ(z∣x)[logqϕ(z∣x)−log(pθ(x∣z)−logpθ(z)+logpθ(x))]=Eqϕ(z∣x)[logqϕ(z∣x)−logpθ(z)]−Eqϕ(z∣x)[log(pθ(x∣z)]+logpθ(x)=KL(qϕ(z∣x)∣∣pθ(z))−Eqϕ(z∣x)[log(pθ(x∣z)]+logpθ(x)
记:L(θ,ϕ;x(i))=−KL(qϕ(z∣x(i))∣∣pθ(z))+Eqϕ(z∣x(i))[log(pθ(x(i)∣z)]..........(3)L(θ,ϕ;x(i))=−KL(qϕ(z∣x(i))∣∣pθ(z))+Eqϕ(z∣x(i))[log(pθ(x(i)∣z)]..........(3) 这就是文章中的公式(3),我们把公式(3)带入上面的式子就得到下面论文中的公式(1):
logpθ(x(i))=KL(qϕ(z∣x(i))∣∣pθ(z∣x(i)))+L(θ,ϕ;x(i))............(1)logpθ(x(i))=KL(qϕ(z∣x(i))∣∣pθ(z∣x(i)))+L(θ,ϕ;x(i))............(1)
由于KL散度的非负性,最大化释然等价于最大化L(θ,ϕ;x(i))L(θ,ϕ;x(i)),因此我们VAE的损失函数也就出来了,就是围绕公式(3)。 我们假定先验分布pθ(z)=N(0,1)pθ(z)=N(0,1)为标准正太分布,qϕ(z∣x(i))qϕ(z∣x(i))近似为N(z;μ(i),σ(i)I)N(z;μ(i),σ(i)I),左边散度那一项变为以下,具体推导可看原文或者网上的一些,这里直接给结果,其中j表示多维正太分布的维度,也就是编码输出的μ,σμ,σ维度
KL(qϕ(z∣x(i))∣∣pθ(z))≈1/2∑j=1J(1+log(σj(i))2−(μj(i))2+(σj(i))2)KL(qϕ(z∣x(i))∣∣pθ(z))≈1/2j=1∑J(1+log(σj(i))2−(μj(i))2+(σj(i))2)
这以上公式代入公式(3)得到,论文中的公式(10),注意和论文公式(10)有差别,后面一项没有做变换,后面细说,其中J表示z的维度,
L(θ,ϕ;x(i))=1/2∑j=1J(1+log(σj(i))2−(μj(i))2+(σj(i))2)+Eqϕ(z∣x(i))[log(pθ(x(i)∣z)]..........(10)L(θ,ϕ;x(i))=1/2j=1∑J(1+log(σj(i))2−(μj(i))2+(σj(i))2)+Eqϕ(z∣x(i))[log(pθ(x(i)∣z)]..........(10)
从概率角度来讲,假设pθ(x(i)∣z)pθ(x(i)∣z)也是满足正太分布,方差不变,那么什么时候这个概率最大呢,毫无疑问x=μx=μ的时候最大,也就是生成模型最终生成的结果是μμ并且等于输入X的时候概率最大,那我们就可以用mse损失来代替后一项。论文中给了两种假设,其中之一就是正太分布,另一种是伯努利分布,两种推导请参考变分自编码器(一):原来是这么一回事 - 科学空间|Scientific Spaces这里给出了详细的推导。而我们只需用mse会更加简单一些。优化最大,前面加上-号变成优化最小。 至此我们可以把公式(10)改写成可求解的loss,如下,我命名为(*)式:
−L(θ,ϕ;x(i))=−1/2∑j=1J(1+log(σj(i))2−(μj(i))2+(σj(i))2)+∣∣x(i)−f(z(i))∣∣22..........(∗)−L(θ,ϕ;x(i))=−1/2j=1∑J(1+log(σj(i))2−(μj(i))2+(σj(i))2)+∣∣x(i)−f(z(i))∣∣22..........(∗)
到这里我们基本证明了我们最开始loss的猜想,并且给出了可以求解的loss。 还有一个问题由于z(i)z(i)是在N(μ(i),σ(i)I)N(μ(i),σ(i)I)随机采样的,我们在代码中反向传播就无法计算了,就没法用torch中反向传播求梯度,导致编码器不可学习了,怎么办呢?论文中巧妙的用了等价的方法,大家都叫重参数技巧 (reparameterization trick)简称trick: z(i)=μ(i)+σ(i)⊙ϵ(i)z(i)=μ(i)+σ(i)⊙ϵ(i)
这样我们最终的loss,可以求解的,也可以做反向传播的loss也就出来了,就可以用到代码里面了,过程很复杂,结果非常完美。
−L(θ,ϕ;x(i))=−1/2∑j=1J(1+log(σj(i))2−(μj(i))2+(σj(i))2)+∣∣x(i)−f(μ(i)+σ(i)⊙ϵ(i))∣∣22..........(∗∗)−L(θ,ϕ;x(i))=−1/2j=1∑J(1+log(σj(i))2−(μj(i))2+(σj(i))2)+∣∣x(i)−f(μ(i)+σ(i)⊙ϵ(i))∣∣22..........(∗∗)
3 关键代码
3.1 模型结构
VAE是一种算法思想,并没有规定模型结构是什么样,关键是看任务。此次采用miniset来作为训练数据,看VAE的实战效果。
class VAE(nn.Module):
def __init__(self, image_size=28*28, hidden1=512, hidden2=128, latent_dims=20):
super().__init__()
# encoder
self.encoder = nn.Sequential(
nn.Linear(image_size, hidden1),
nn.ReLU(),
nn.Linear(hidden1, hidden2),
nn.ReLU(),
)
self.mu = nn.Sequential(
nn.Linear(hidden2, latent_dims),
)
self.logvar = nn.Sequential(
nn.Linear(hidden2, latent_dims),
) # 由于方差是非负的,因此预测方差对数
# decoder
self.decoder = nn.Sequential(
nn.Linear(latent_dims, hidden2),
nn.ReLU(),
nn.Linear(hidden2, hidden1),
nn.ReLU(),
nn.Linear(hidden1, image_size),
nn.Sigmoid()
)
# 重参数,为了可以反向传播
def reparametrization(self, mu, logvar):
# sigma = exp(0.5 * log(sigma^2))= exp(0.5 * log(var))
std = torch.exp(0.5 * logvar)
# N(mu, std^2) = N(0, 1) * std + mu
z = torch.randn(std.size(), device=mu.device) * std + mu
return z
def forward(self, x):
en = self.encoder(x)
mu = self.mu(en)
logvar = self.logvar(en)
z = self.reparametrization(mu, logvar)
return self.decoder(z), mu, logvar- 编码器最终的输出结果是方差var和均值mu,但是由于方差是非负的因此预测方差的对数。
self.mu = nn.Sequential(
nn.Linear(hidden2, latent_dims),
)
self.logvar = nn.Sequential(
nn.Linear(hidden2, latent_dims),
) # 由于方差是非负的,因此预测方差对数 latent space z的采样策略是N(0, 1) * std + mu,而不是直接在N(mu,std)上采样,因为直接采样,std和mu无法反向传播求梯度。
def reparametrization(self, mu, logvar):
# sigma = exp(0.5 * log(sigma^2))= exp(0.5 * log(var))
std = torch.exp(0.5 * logvar)
# N(mu, std^2) = N(0, 1) * std + mu
z = torch.randn(std.size(), device=mu.device) * std + mu
return z 3.2 训练核心代码
核心代码在于loss函数的构建,包括两部分,一个是kl散度,一个是重建损失
def loss_function(fake_imgs, real_imgs, mu, logvar, criterion, batch):
kl = -0.5 * torch.sum(1 + logvar - torch.exp(logvar) - mu ** 2) / batch
reconstruction = criterion(fake_imgs, real_imgs) / batch
return kl, reconstruction
fake_imgs, mu, logvar = vae(real_imgs)
loss_kl, loss_re = loss_function(fake_imgs, real_imgs, mu, logvar, criterion, current_batch)
loss_all = loss_kl + loss_re
optimizer.zero_grad()
loss_all.backward()
optimizer.step()4 结果展示
昨天是训练数据集,右边是生成结果,可以看到生成的结果已经很接近训练样本的风格数字了。


本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-02,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号