如何利用 ClickHouse 实现高级分析:MySQL 到 ClickHouse 实时数据同步指南

如何利用 ClickHouse 实现高级分析:MySQL 到 ClickHouse 实时数据同步指南

Tapdata
发布于 2024-12-27 20:15:28
发布于 2024-12-27 20:15:28
在数据驱动的时代,企业必须依靠先进的数据分析能力来提升竞争力。随着数据量的激增和业务需求的复杂化,传统的关系型数据库已经无法满足高效处理和实时分析的需求。ClickHouse 作为一款高性能的列式数据库,凭借其卓越的查询性能和可扩展性,成为处理大规模数据并执行复杂分析任务的理想选择。基于 ClickHouse 的实时数仓,也成为诸多企业在寻找强时效性、高数据准确性、低开发运维成本的数据分析与运营决策解决方案的优选之一。
本文将介绍如何实现 MySQL、Oracle 或 MongoDB 到 ClickHouse 的实时数据同步,并分享如何构建高效、可靠的数据管道,从而为企业级的数据处理和分析需求铺路。
需求背景:为什么选择将数据移动到 ClickHouse?
之所以选择 ClickHouse 作为数据目标来承载企业内部的数据处理与分析需求,本质上是因为其具有以下几点关键优势:
1. 高查询性能 ClickHouse 专为大数据集设计,具有极低的延迟。其列式存储模型可以快速访问特定数据块,显著提高查询速度,尤其是在处理需要聚合和复杂计算的分析性工作负载时。
2. 高效的数据压缩 ClickHouse 采用先进的数据压缩技术,显著减少数据的存储占用。这不仅有助于降低成本,还能提升查询性能,因为需要扫描的数据量减少,从而提高整体效率。
3. 实时数据分析 通过 ClickHouse,企业可以实现实时数据分析。它能够快速摄取数据并支持并发查询,意味着您可以在数据到达的同时获得即时洞察,帮助企业做出快速决策。
4. 可扩展性 ClickHouse 支持横向扩展,可以轻松将数据分布到多个节点上。随着数据量的不断增长,分析能力也能同步扩展,且不会出现性能瓶颈。
5. 完善的 SQL 支持 ClickHouse 提供全面的 SQL 支持,便于具有 SQL 基础的用户无缝操作数据库。这种兼容性大大减少了学习成本,使团队能够快速上手并充分发挥现有技能。
如何将数据同步至 ClickHouse?
将数据同步至 ClickHouse 涉及数据的提取、转换、加载和同步等多个环节。不同的业务需求和技术环境可能决定了选择不同的同步方案。一些时候,手动方案可以满足数据迁移的基本需求,而在数据量较大或实时性要求较高的场景下,采用自动化工具能够提升迁移效率并降低人工干预的风险。接下来,我们将分别介绍这两类常见的数据同步方案,帮助大家了解各自的具体流程与适用场景,为进一步选择提供参考。
手动方案:传统数据移动流程
1. 数据提取 将数据从源数据库(如 MySQL、Oracle 或 MongoDB)导出的过程。通常采用 SQL 查询或使用数据库客户端工具进行提取。
步骤:
- 使用数据库客户端工具(如 MySQL Workbench、SQL Developer 或 MongoDB Compass)手动执行查询,提取数据。
- 如果是 MySQL 或 Oracle,可以使用 SQL 语句通过 SELECT INTO OUTFILE 或 SPOOL 将数据导出为 CSV 或 TSV 格式。
示例:
- MySQL 数据导出:
SELECT * FROM source_table
INTO OUTFILE '/path/to/exported_data.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';- Oracle 数据导出:
SPOOL /path/to/exported_data.csv
SELECT * FROM source_table;
SPOOL OFF;工具:
- MySQL Workbench、SQL Developer、MongoDB Compass 等客户端工具。
- SQL 或 Python 脚本(使用 pymysql、cx_Oracle 或 pymongo 等库进行数据提取)。
2. 数据转换
在数据提取之后,需要对数据进行清洗和转换,以适应目标数据库(ClickHouse)的要求。这个环节通常需要使用 ETL 工具或自定义脚本。
步骤:
- 数据清洗:去除无效或重复的数据。
- 数据转换:根据目标表的结构转换数据类型、格式等。
- 如果源数据格式是 CSV,可以使用 Python 脚本或 ETL 工具(如 Talend、Pentaho 或 Apache Nifi)进行转换。
示例:
- 使用 Python 转换 CSV 数据:
import pandas as pd
# 读取 CSV 数据
df = pd.read_csv('/path/to/exported_data.csv')
# 数据清洗,去除空值
df.dropna(inplace=True)
# 转换列的数据类型(例如,将日期列转为日期格式)
df['date'] = pd.to_datetime(df['date'])
# 将清洗后的数据保存为新的 CSV 文件
df.to_csv('/path/to/cleaned_data.csv', index=False)工具:
- Python(pandas、csv 等库)进行数据清洗和转换。
- ETL 工具(如 Talend、Apache Nifi)进行数据处理和格式转换。
3. 数据加载
数据加载是将转换后的数据导入目标数据库(ClickHouse)的过程。此步骤通常使用数据库导入工具或者 SQL 脚本进行数据加载。
步骤:
- 使用数据库的导入工具(如 ClickHouse-client、clickhouse-csv-loader)将清洗后的数据加载到目标数据库中。
- 也可以通过 SQL 插入语句手动加载数据。
示例脚本:
- ClickHouse 导入 CSV 数据:
clickhouse-client --query="INSERT INTO target_table FORMAT CSV" < /path/to/cleaned_data.csv工具:
- ClickHouse-client 或 clickhouse-csv-loader:用于将 CSV 数据批量导入到 ClickHouse。
- SQL 插入语句:例如使用 INSERT INTO 来逐行插入数据,但这种方式效率较低。
4. 实时同步
为了实现实时数据同步,需要编写增量同步的脚本,定期从源数据库提取数据,并将变化的部分(例如通过时间戳或标记字段)同步到目标数据库。
步骤:
- 通过定时任务(如 cron 作业)定期运行增量数据同步脚本。
- 利用源数据库的变更数据捕获(CDC)机制,捕获数据变化,并将其同步到目标数据库。
示例脚本:
- 使用 Python 获取增量数据并同步到 ClickHouse:
import pymysql
import clickhouse_driver
连接 MySQL 数据库
mysql_conn = pymysql.connect(host='localhost', user='user', password='password', db='source_db')
cursor = mysql_conn.cursor()
获取增量数据(例如:最近24小时的数据)
query = "SELECT * FROM source_table WHERE last_updated > NOW() - INTERVAL 1 DAY"
cursor.execute(query)
new_data = cursor.fetchall()
连接 ClickHouse
clickhouse_conn = clickhouse_driver.Client('localhost')
将增量数据插入 ClickHouse
for row in new_data:
clickhouse_conn.execute('INSERT INTO target_table VALUES', [row])
mysql_conn.close()
clickhouse_conn.disconnect()工具:
- Python 脚本:用于定期查询源数据库并同步增量数据。
- Cron 或 Airflow:用于调度定时任务,定期执行增量同步脚本。
- Change Data Capture (CDC):使用 MySQL 的 binlog 或类似技术捕获数据变更。
5. 错误处理
在手动迁移过程中,错误处理是不可忽视的一部分。通常需要人工监控数据同步过程,并处理可能出现的错误(如数据冲突、数据丢失、连接失败等)。
步骤:
- 监控数据同步日志,及时发现问题。
- 手动排查问题(例如,重新运行失败的脚本或手动修复数据问题)。
工具:
- 日志分析工具:如 ELK Stack 或 Splunk,用于分析错误日志并监控数据同步过程中的异常。
- 手动重试机制:手动执行失败的迁移任务,确保数据一致性。
6. 维护和更新
随着时间推移,手动方案的维护变得更加复杂,尤其是在数据源或目标数据库发生变化时。需要定期更新脚本,确保其与数据库结构的兼容性。
步骤:
- 更新数据库表结构和字段类型时,手动调整迁移脚本和同步逻辑。
- 维护数据质量,定期进行数据清洗和审查。
工具:
- Git:用于版本控制,方便管理迁移脚本的更新和修改。
小结
手动数据迁移方案需要依赖大量人工干预和多个工具来完成数据提取、转换、加载、实时同步等环节。每个环节都可能面临不同的技术挑战,需要编写和维护复杂的脚本,同时需要不断地进行手动调整和监控。因此,尽管这种方案可行,但在处理大规模数据时效率低且容易出错。
自动化数据移动工具:如 TapData
不同于传统方案,利用一些现代化的自动数据移动工具,完成数据从 MySQL、Oracle 或 MongoDB 到 ClickHouse 的同步并不复杂。以 TapData 为例,作为行业内以低延迟数据移动为核心的数据移动工具,它提供了简化的流程,能够高效且准确地处理实时数据复制、实时数据集成与消费等深入数据底层的关键需求。其关键优势在于
- 出色的 CDC(Change Data Capture,变更数据捕获)能力,开箱即用的实时同步
- 集中数据中心架构(Data Hub),便于统一管理与数据共享
- 内置 100+ 数据连接器,轻松连接各种数据源
- 低代码自动化工作流程,减少错误、提升效率
ClickHouse + Metabase 教程:如何使用 TapData 实现数据实时同步与实时分析(分步演示)
以 MySQL 实时同步到 ClickHouse,并为开源数据分析和可视化工具 Metabase 供数为例:
第 1 步:连接数据源 MySQL
首先,建立 TapData 与待同步的源数据库(MySQL)之间的连接:
- 配置连接:在 TapData 界面中,通过填写数据库主机名、端口和认证信息创建新的连接。确保连接安全且稳定。
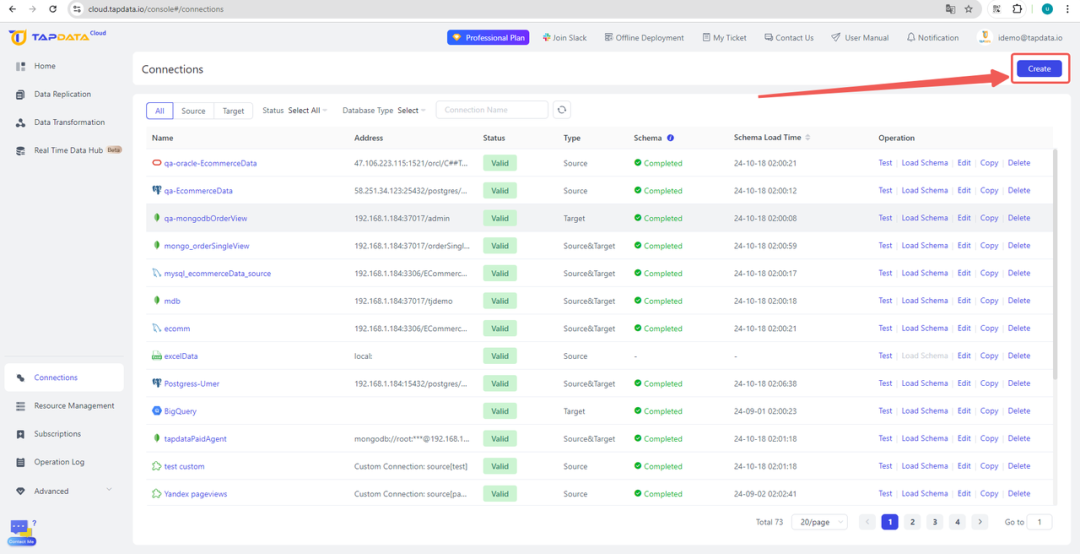
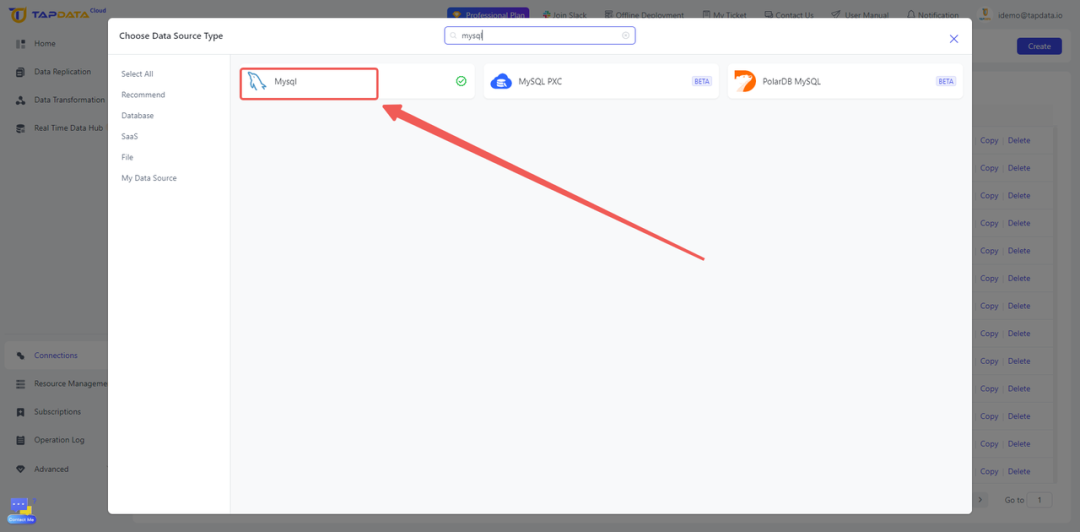
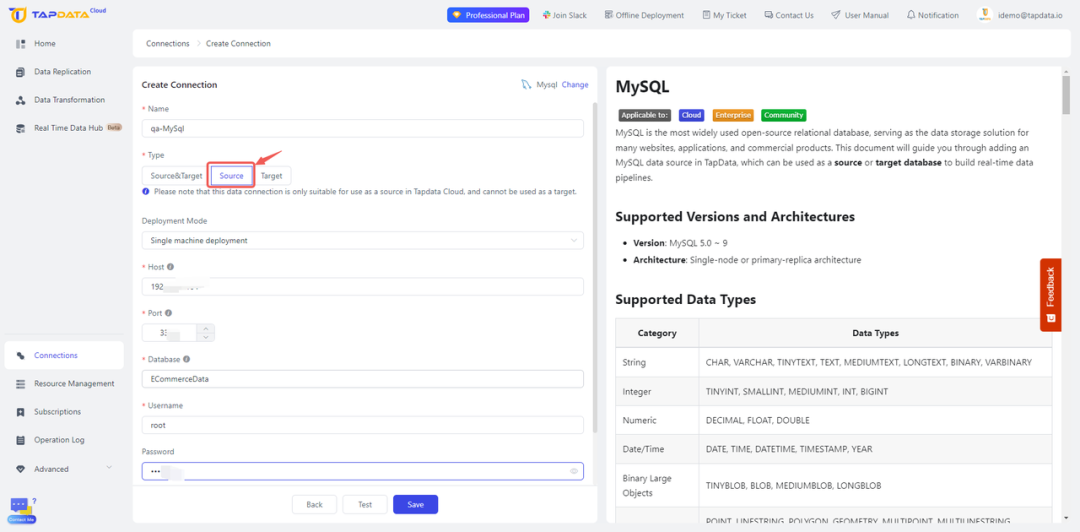
- 测试连接并保存:在继续下一步操作之前,测试连接以确认 TapData 能够有效地与源数据库通信。
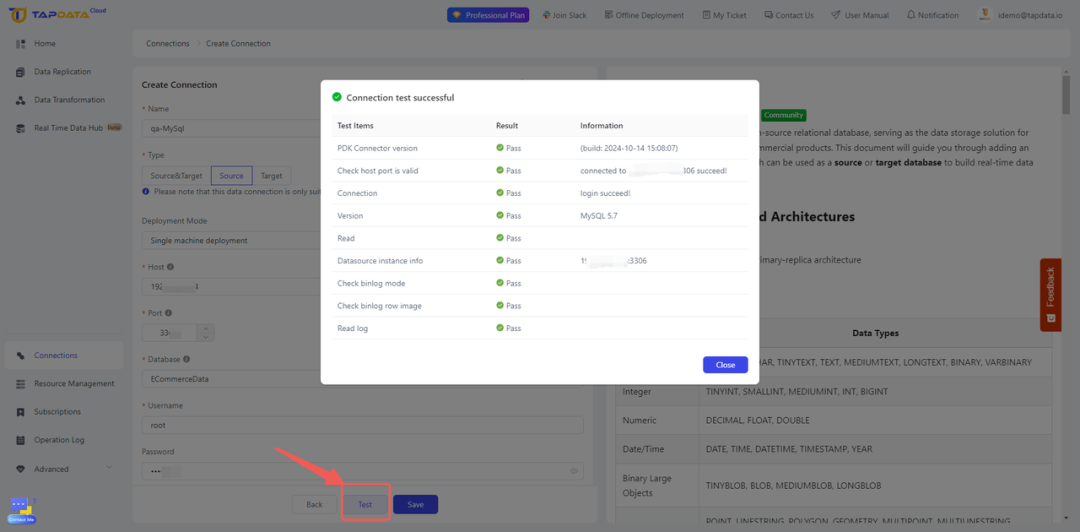
第 2 步:连接目标 ClickHouse 数据库
- 配置连接:在 TapData 中,通过配置数据库主机名、端口和身份验证详细信息来创建新连接。确保连接安全稳定。
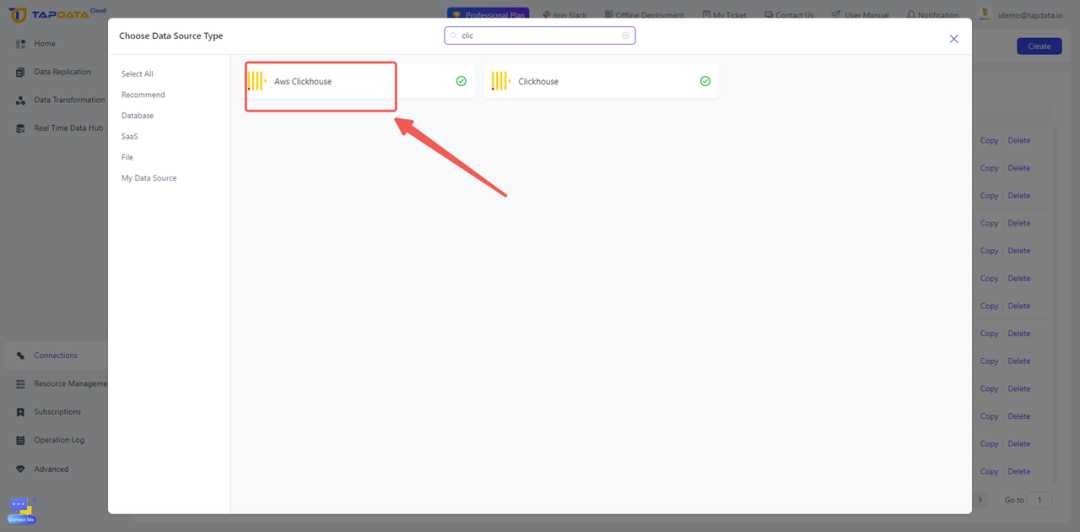
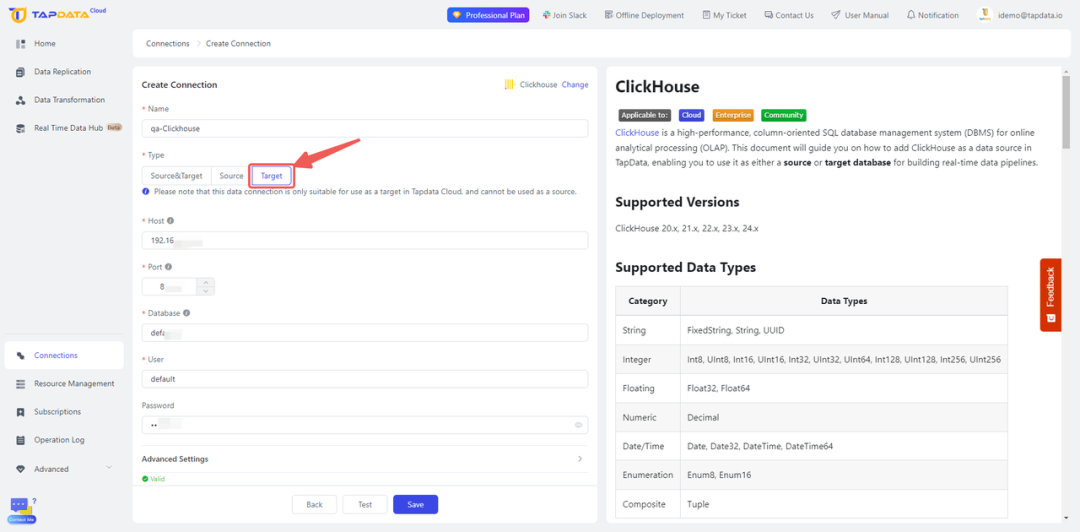
- 测试连接并保存:在继续之前,仍然是完成连接测试以确保 TapData 可以有效地与目标数据库通信。
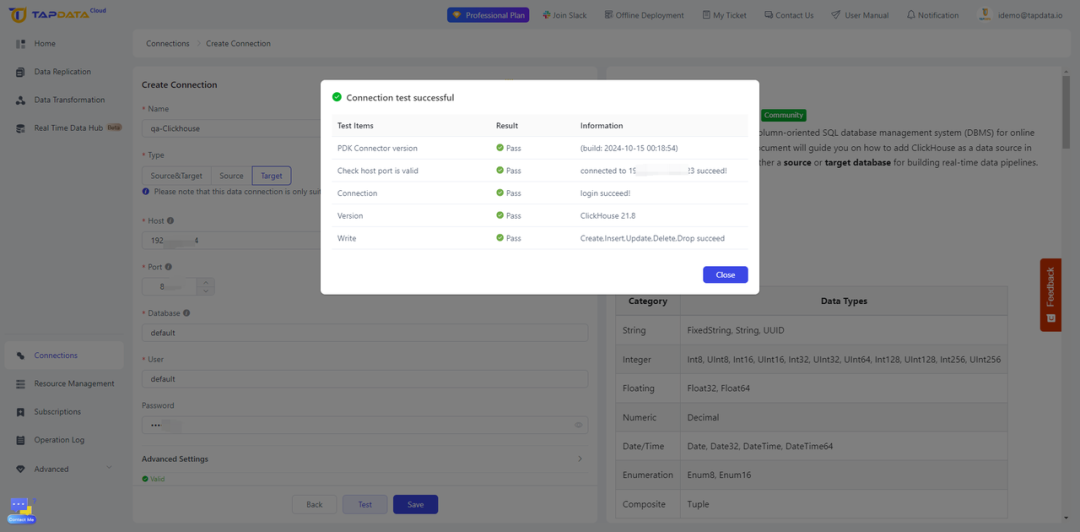
第 3 步:构建实时复制的数据管道
设置数据管道用以进行实时数据同步:
- 进入数据复制功能页面,在这里单击创建按钮:
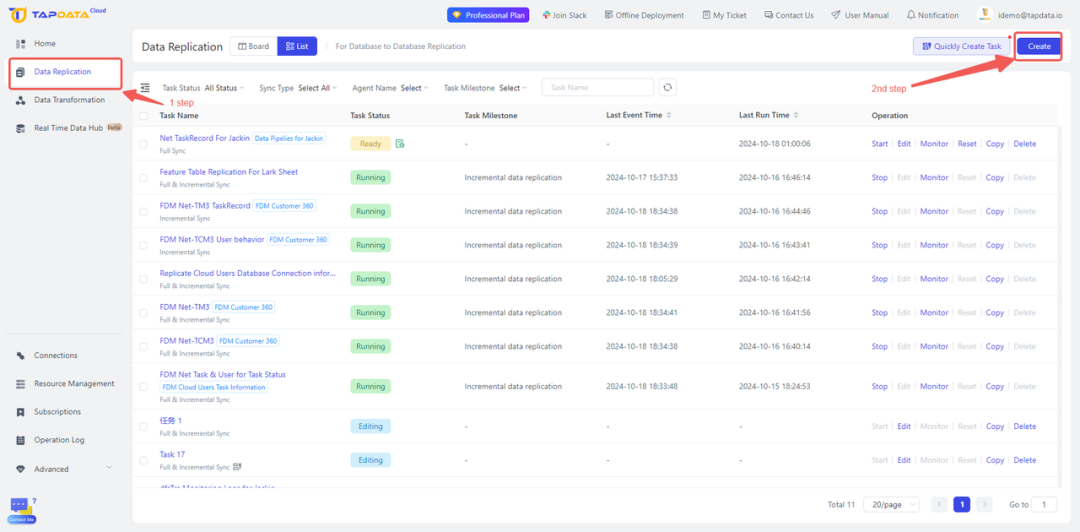
- 通过拖拉拽的方式,在画布页面上,摆放好该数据复制任务的源(MySQL)与目标(ClickHouse)节点:
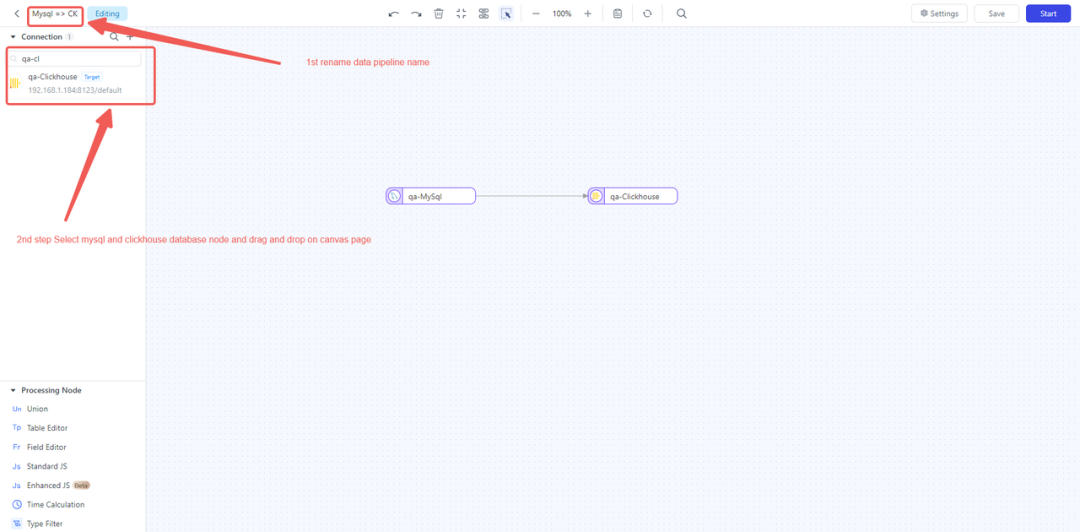
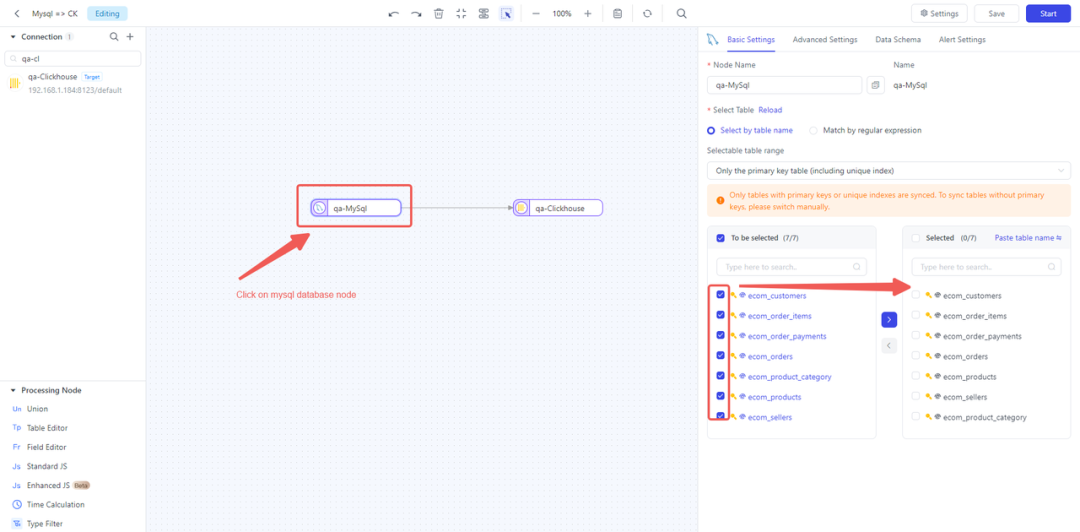
- 配置 MySQL 节点:单击 MySQL 节点并选择待实时复制到 ClickHouse 的表。
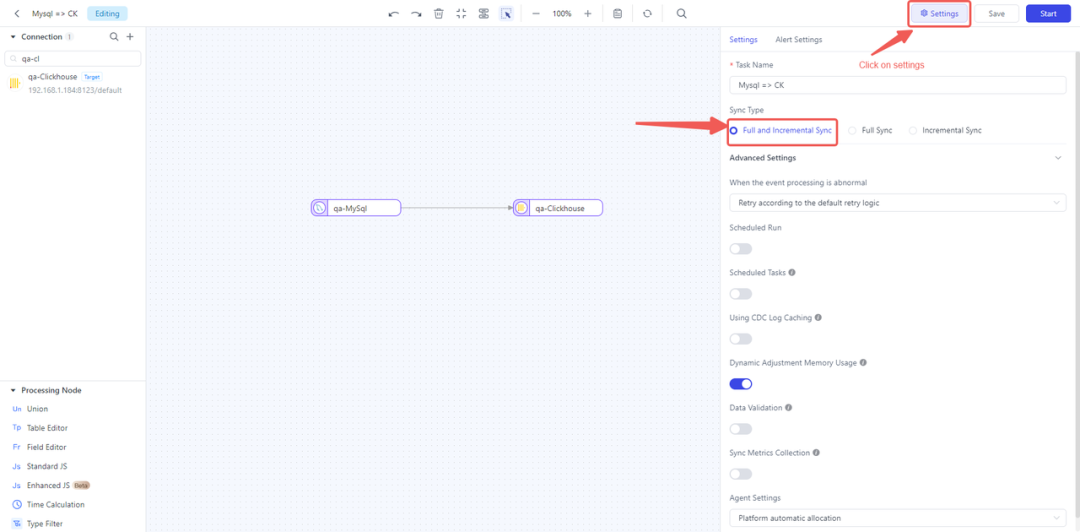
- 调整同步设置:单击 MySQL 节点的设置并选择全量和增量同步选项,以确保首次复制存量数据,并在完全同步后自动开始捕获增量或 CDC 数据。
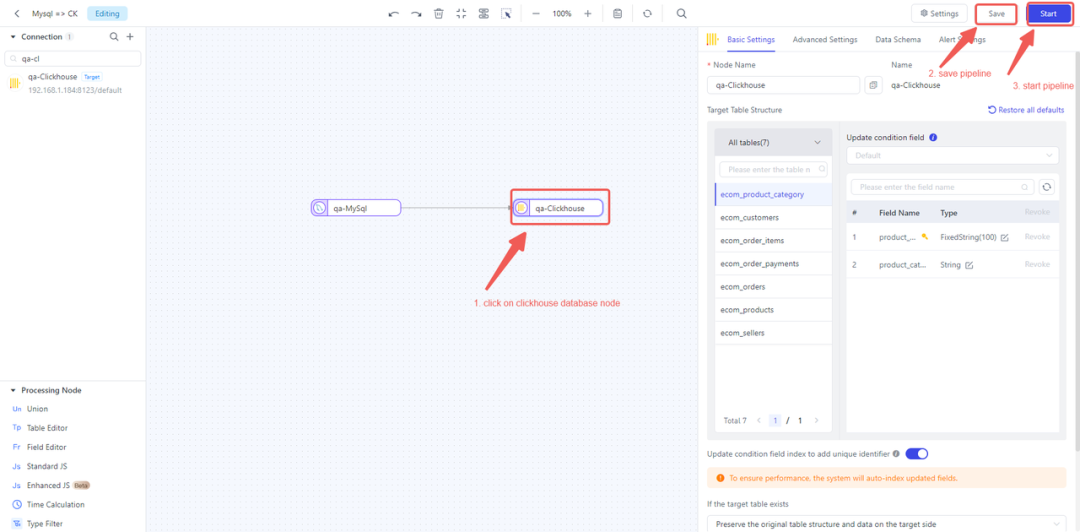
- 配置 ClickHouse 节点:单击 ClickHouse 节点,然后用默认配置保存数据管道并启动任务。
- 任务监控:任务启动后,将跳转到监视页面,可以在其中跟踪复制任务状态并验证数据是否成功复制。
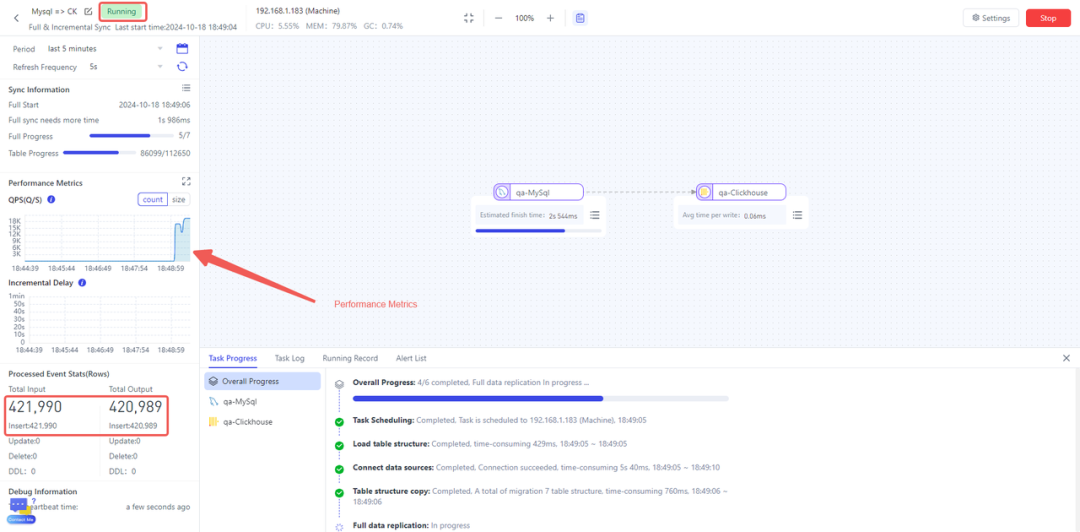
现在,我们已经创建了一个从MySQL到ClickHouse的实时管道。MySQL中的每个更改都将在短短几秒钟内更新ClickHouse。
第 4 步:将 ClickHouse 与 Metabase 连接
假设要通过 Metabase 实现对 ClickHouse 数据的实时分析和可视化,具体操作步骤如下:
① 将 Metabase 连接到 ClickHouse
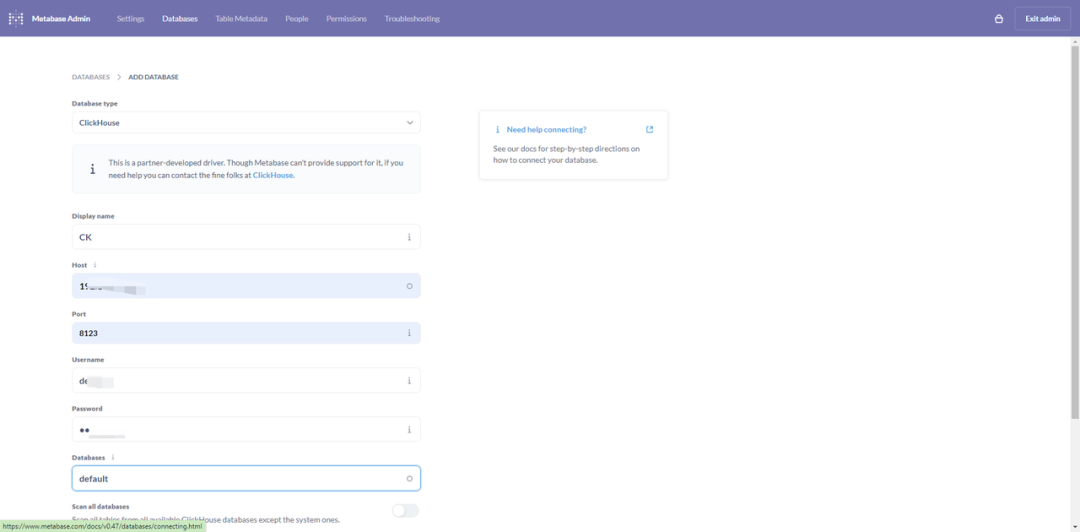
- 启动 Metabase
- 添加新数据库:在管理(Admin)面板选择数据库(Database),并点击【添加数据库】(Add a database)
- 配置数据库连接:
- 数据库类型:选择“ClickHouse”。
- 名称:为该数据库连接指定一个名称。
- 主机:输入 ClickHouse 服务器的主机名或 IP 地址。 端口:输入端口号(默认通常是 8123)。
- 数据库名称:指定您要连接的数据库名称。用户名和密码:
- 提供必要的身份验证信息。
- 保存连接:输入所有详细信息后,单击“保存”
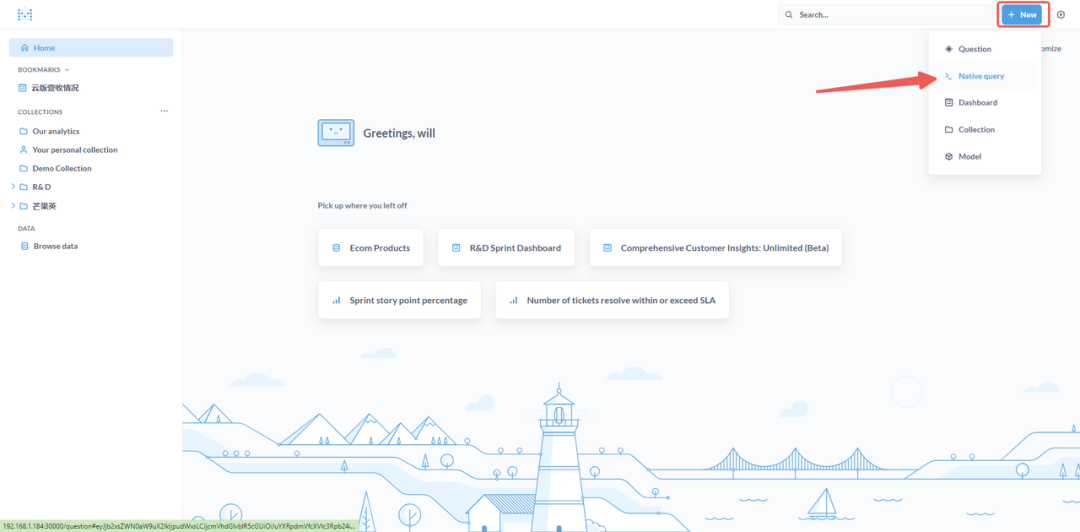
② 为仪表板创建 Question
- 单击“新建”按钮,从下拉框中选择“原生查询(Native query)”。此选项允许直接编写 SQL 查询。
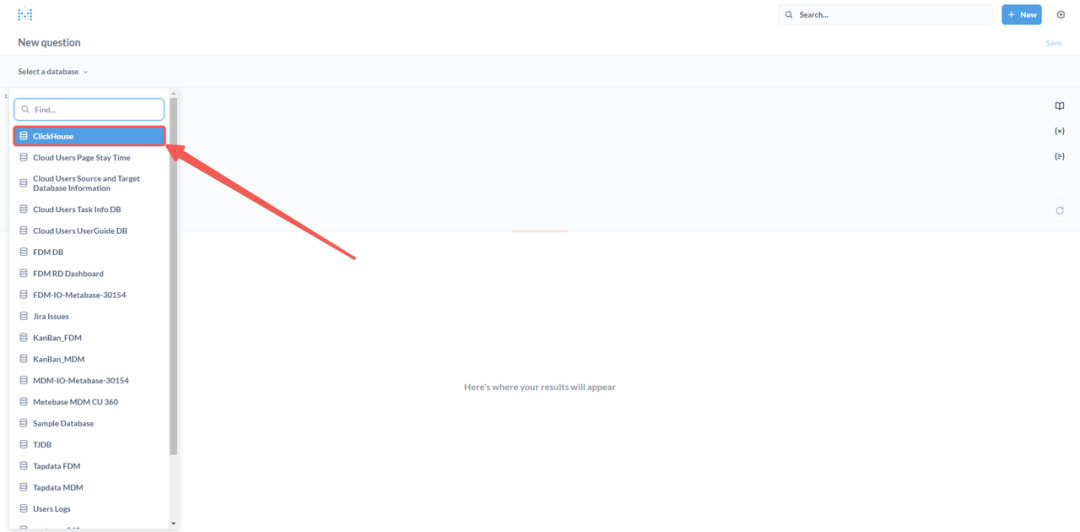
③ 选择数据库
从可用数据库列表中选择 ClickHouse 数据库,确保后续的查询在正确的数据源上运行。
④ 在查询编辑器中输入 SQL 查询,以获取所需数据
例如,若要按状态统计订单数量,可以使用以下查询:点击【运行 Run】按钮(或【执行 Execute】)以执行查询,并在表格中查看结果。
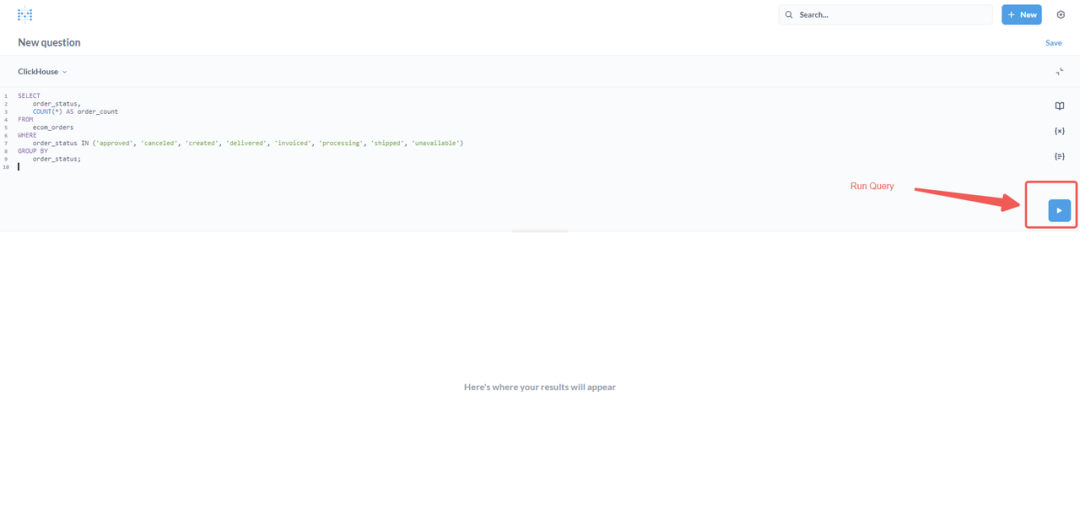
⑤ 点击结果面板顶部的可视化选项(图表图标)
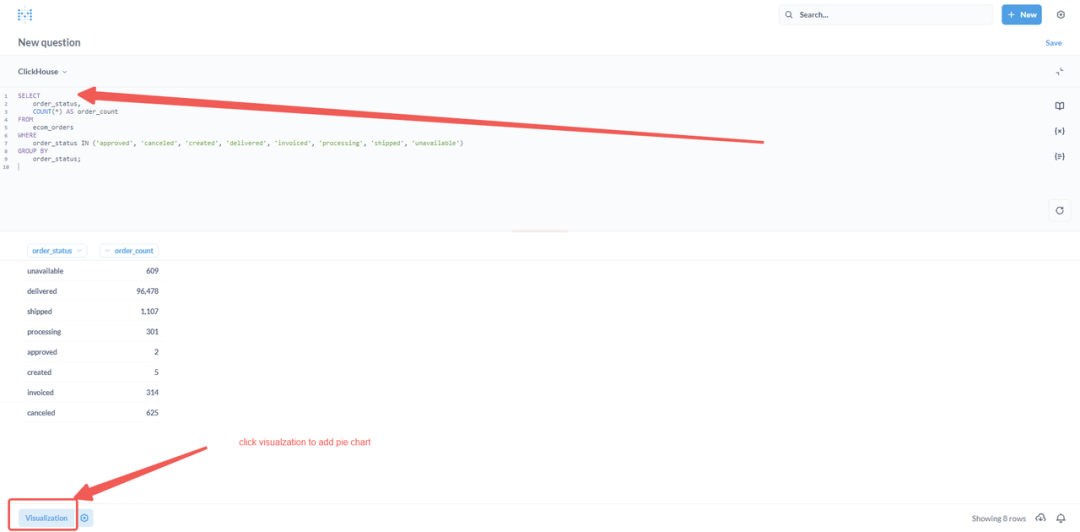
⑥ 从可视化类型中选择“饼图”。如对饼图结果满意,即可点击“保存”按钮。
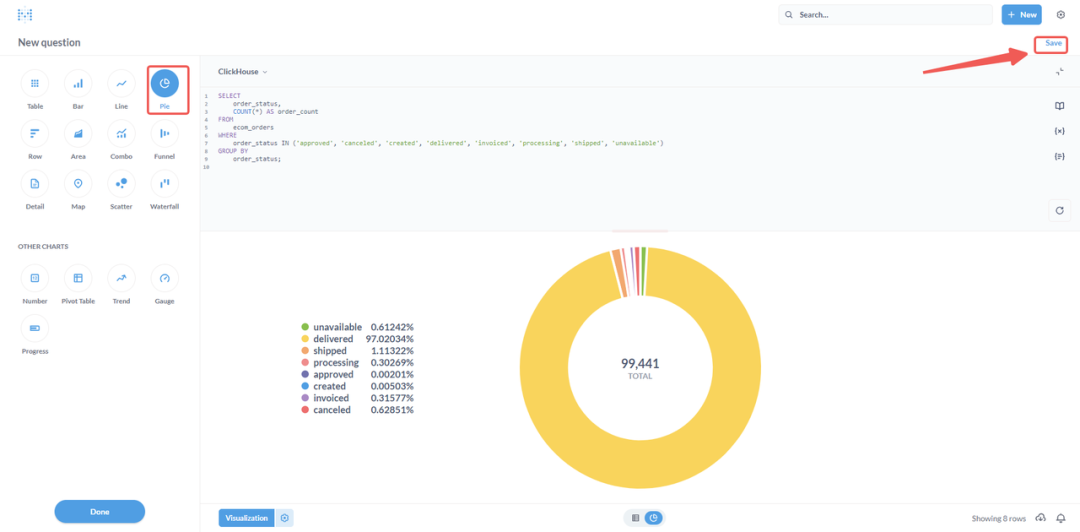
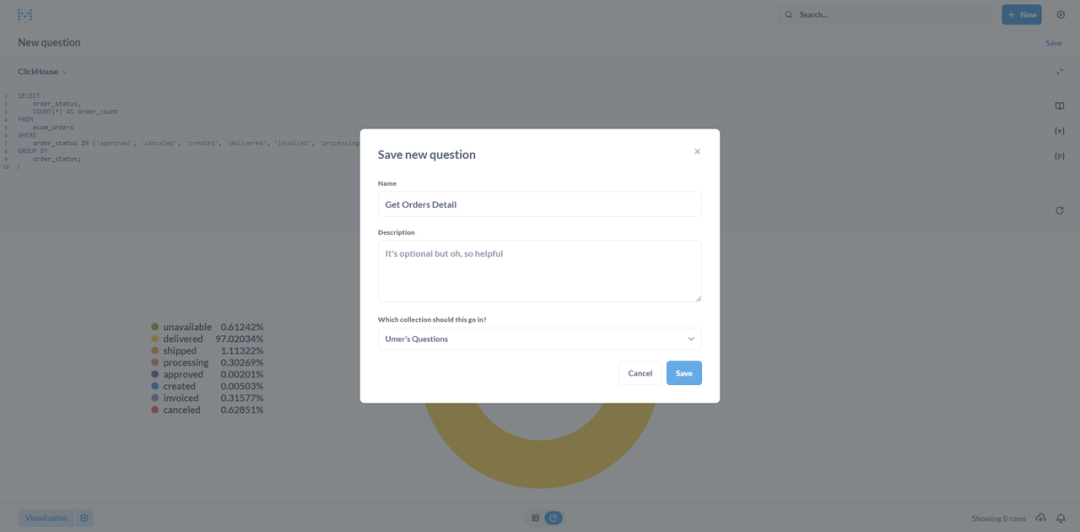
⑦ 添加新仪表板
从 Metabase 首页,点击“新建仪表板”,并为其命名。
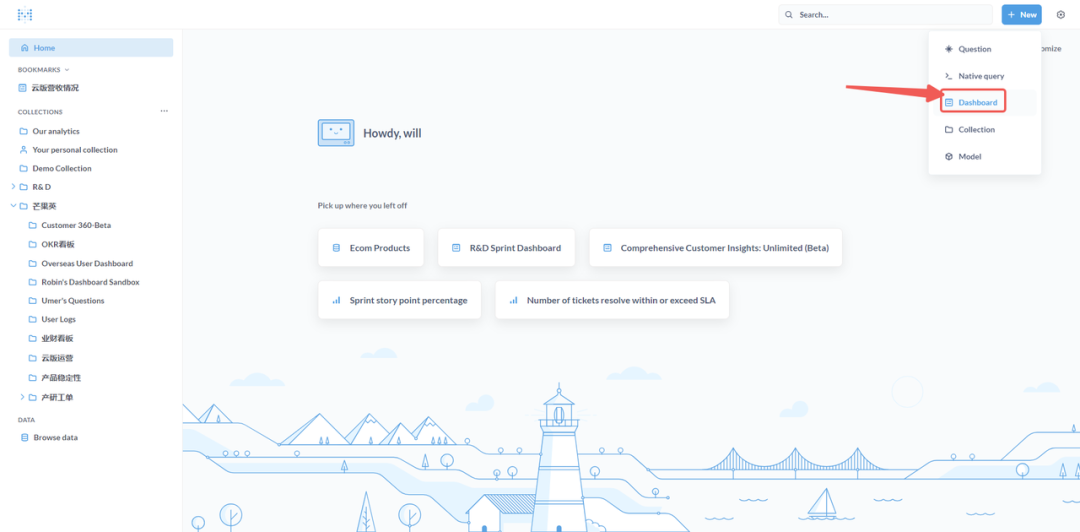
⑧ 添加我们在前面步骤中创建的 Question
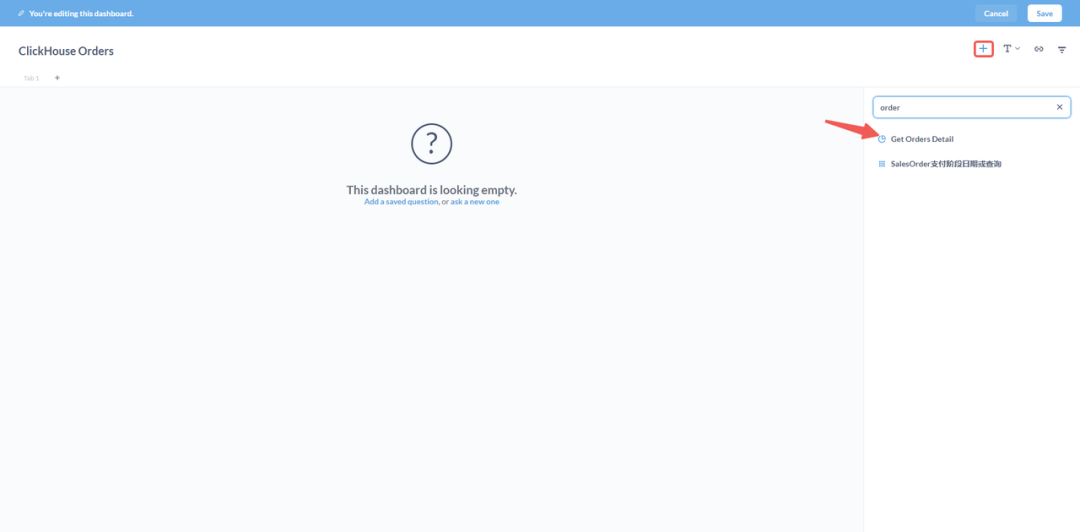
⑨ 保存带有我们添加的 Question 的仪表板
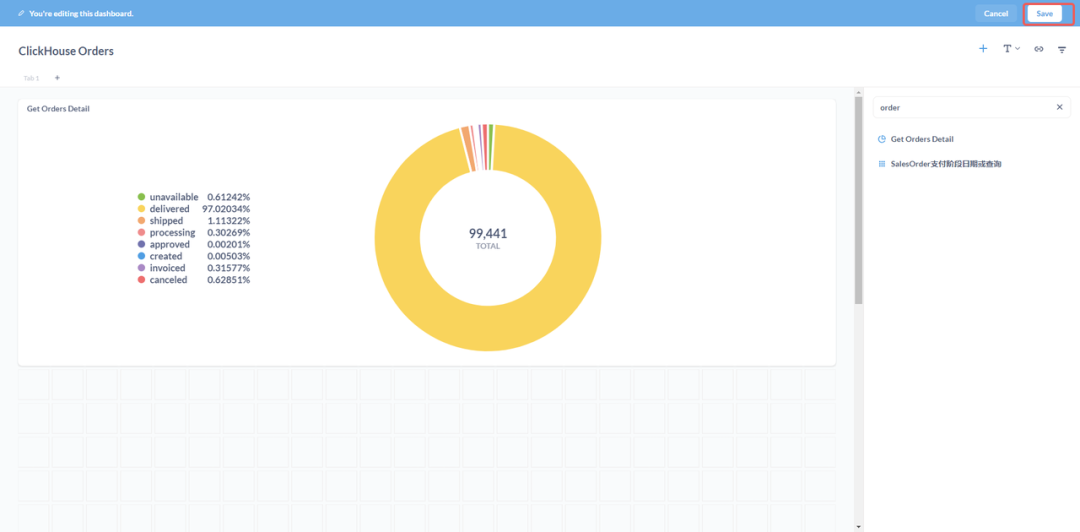
小结
综上所述,借助 TapData 的实时复制管道,实现 MySQL、Oracle 以及 MongoDB 等数据库到 ClickHouse 的实时数据移动,不仅能够提升数据处理性能,还能帮助企业利用 ClickHouse 的高效查询、实时分析和数据压缩功能,快速获得关键业务洞察。结合 Metabase 等数据分析工具的可视化能力,企业可以轻松构建强大的数据管道,推动数据驱动的决策过程。通过实施这些方案,组织能够优化数据操作、提高分析效率,并增强团队在面对复杂数据时的决策信心。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号