模糊眼底图像的校准分割


概述
在医学图像分析的场景中,经常会遇到来自多个临床专家或评估者对于一张图像的不同标注,以期减轻对于模糊图像的诊断错误。 我们这里要介绍的方法来自CVPR2021的一篇工作,其提出了一种可以挖掘多评价者标注中蕴藏的丰富的一致或不一致信息的方法,并利用其校准模型预测,提升模型的分割性能。
模型概述
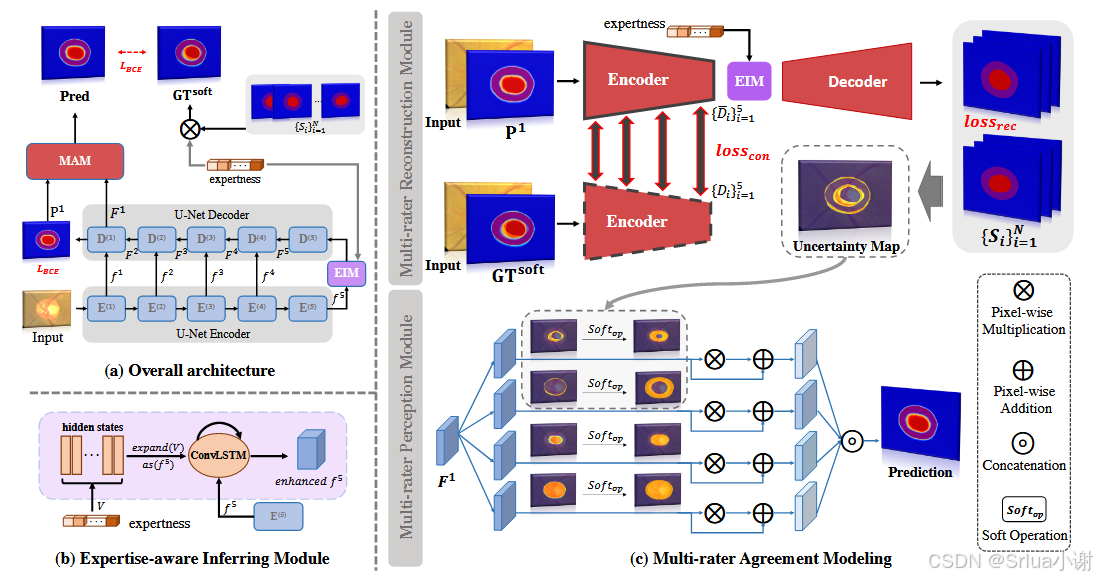
上图是对整个MRNet框架及模型构造的详细介绍,下面这张图是略去了中间的可视化结果之后,对MRNet处理流程的清晰展示:
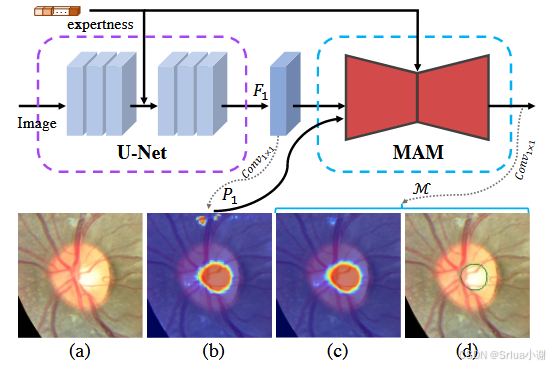
- (a) 输入图像
- (b) 初始粗略预测的热力图
- (c)最终精细预测的热力图
- (d) 最终精细预测的分割边界
这里提出了MRNet,用于显式建模多评估者之间的一致和不一致性。其有两项主要贡献:
- 设计了一种基于专家知识的推理模块(EIM),用于将不同评估者的专业水平编码为高级语义特征,嵌入到网络中作为先验知识;
- 可以从粗略的预测中重构多评估者的评分,并且利用多评估者之间的一致或不一致性信息进一步提升分割性能。
整体框架
- 该框架的特色在于考虑了各位评估者之间潜在的共识/分歧知识。
- 该框架是一个从粗到细的处理流程。
- 阶段1采用U-Net架构,编码器采用从ImageNet上预训练得到的ResNet34, 在瓶颈层插入一个专家推断模块(EIM), 用于将各个评估者的专业信息嵌入到高级语义特征之中,增强后的特征传递给U-Net的解码器模块,得到多层解码特征。 最终层的解码特征经过conv1*1, 再经过一个sigmoid激活函数,生成粗略预测结果P1
- 阶段2是想对阶段1中的粗略预测结果进行细化处理,其由两个按顺序排列的模块组成 多评估者重构模块(MRM)旨在重构原始的各个评估者的评估,并基于这些评估得到像素级的不确定性图,用以表示不同区域的评估者间的变异性。 多评估者感知模块(MPM)利用软注意力机制,借助不确定性图对粗略预测进行精细化处理。
主要模块
1. Expertise-aware Inferring Module
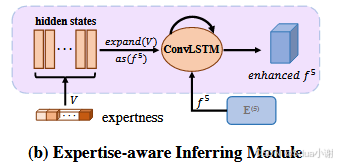
- 在EIM模块中,多位评估者的专业水平被表示为一个归一化的专业向量,然后嵌入到网络中,同时决定了网络的实际软GT标签,作为学习目标,公式为
GTsoft=∑i=1NSiVi→φ(x,V)GTsoft=∑i=1NSiVi→φ(x,V)
- 三种不同的专业向量生成策略:
- major vote (所有评估者之间权重均等)
- 单一评估者模式 (随机选择一个评估者,权重设置为1,其余为0)
- 随机权重分配 (随机为每个评估者分配权重,然后归一化为单位向量)
不同的专业向量分配策略的使用,使得模型学会了将各个评估者的影响/权重和最终的软真实预测关联在一起; 也是一种有效的数据增强策略,增加了数据的多样性以及输入-输出对的数量,以供模型学习
(其实我觉得这里其实就是单纯的数据增强操作,并不能像作者描述的那样起到编码专业水平的作用,因为专业向量是随机生成的,不包含真正的先验知识)
- 这里利用一个ConvLSTM模块,以生成增强特征。 ConvLSTM是一个强大的循环模型,其可以捕捉特征和不同专业水平之间的相关性,还可以归纳出具有判别力的动态特征。该过程为,公式为 ht=◯tConvLSTM(f5,ht−1), t=1,2,…,Tht=◯tConvLSTM(f5,ht−1),t=1,2,…,T
2. Multi-rater Resconstruction Module
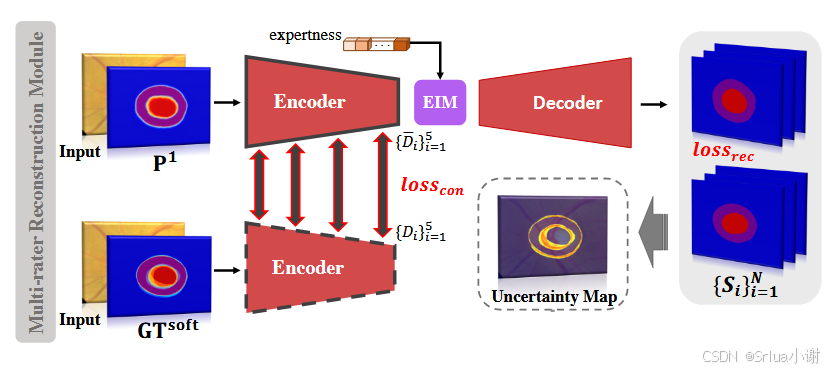
对于这一模块,我们要思考的是,它是怎么捕捉到评估者之间的分歧信息的 — 通过反映不同评估者间差异的uncertainty map来表示
- 该模块(MRM)的目标是从U-Net骨干网络得到的软预测P1和给定的专家矢量V中进一步重建各个评估者对应的标注。同时,基于这些重建的多评估者标注,生成反映评估者间变异性的uncertainty map
- 具体来说,将初始预测P1和输入图像concatenate一起,输入到使用VGG16作为特征编码器的编解码网络中(VGG架构在保持输入图像的拓扑和感知特征方面的优越能力而闻名)。在MRM的瓶颈层,嵌入通过EIM模块编码的专家矢量V的语义特征。MRM的解码器通过最后一层中的多个conv1*1来试图重建各个评估者对应的标注。 这里使用重建损失Loss_rec来衡量重建的多评估者评分与各个评估者的实际标注之间的相似度。 此外,为了进一步提高MRM模块的重建性能,融合的软标签连同给定的专家矢量一起送入网络,一重建个别评估者的评分。这里使用一致性损失Loss_con, 以增强从软预测P1和GT_soft中提取特征之间的连贯性。
评分不一致的不确定性地图可以通过对多个评估者预测的逐像素标准差来估计,计算公式为 Umap=1N∑i=1N(Sˉi−1N∑i=1NSˉi)2Umap=N1∑i=1N(Sˉi−N1∑i=1NSˉi)2 这里得到的不确定性地图被送到下一个模块,以进一步细化初始的粗略预测。
3. Multi-rater Perception Module
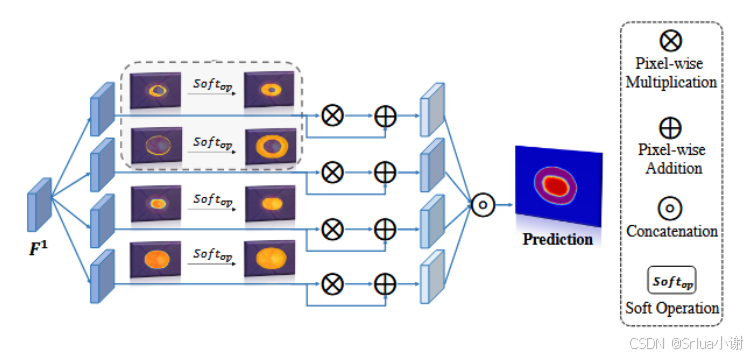
- 该模块是研究如何利用MRM获取的不确定性信息进一步提高分割性能。 本文创新性地设计了一个多评估者感知模块(MPM),该模块通过设计地多分支软注意力机制,更好地捕捉和强调模糊区域。
- 加强不确定区域:具体来说,给定由U-Net骨干网络获得的特征图F1和由MRM生成的不确定性图Umap,我们使用空间注意力策略来强调高度不确定的区域。由于估计的不确定性图可能在物体边界存在潜在的不确定性或不完整性,如果直接使用“硬”空间注意力,可能会对模型性能产生负面影响。因此,这里采用“软”注意力,旨在扩大不确定区域的覆盖范围,以便有效感知和捕捉多个评估者之间的分歧线索。 “软”注意力的公式为 Soft(Umap)=Ωmax(FGauss(Umap,k),Umap)Soft(Umap)=Ωmax(FGauss(Umap,k),Umap)
- 加强高确定性区域:除了加强高不确定性区域,软注意力机制来应用于加强高确定性区域。在联合视盘和视杯分割任务中,F1被送入四个带有软空间注意力的并行分支,得到 Aj={Umapcup,Umapdisc,Pcup1,Pdisc1}j=14Aj={Umapcup,Umapdisc,Pcup1,Pdisc1}j=14 原始特征F1和空间增强特征之间采用跳跃连接,以缓解注意力图中的潜在错误传播到网络中的问题: F~j=F1+Soft(Aj)⊗F1F~j=F1+Soft(Aj)⊗F1
最后的总训练损失是U-NET骨干网络,MRM模块以及MPM模块损失的组合: L=LBCE(P1,GTsoft)+LBCE(M,GTsoft)+αlosscon+(1−α)lossrecL=LBCE(P1,GTsoft)+LBCE(M,GTsoft)+αlosscon+(1−α)lossrec
复现过程
实验效果
这里使用的数据来自RIGA数据集,其是一个公开可用的数据集,用于视网膜杯盘分割,总共包含750张来自三个来源的彩色眼底图像,其中包括460张来自MESSIDOR,195张来自BinRushed,95张来自Magrabia。六位来自不同组织的青光眼专家手动标注了RIGA基准数据集中的视杯和视盘轮廓。数据的划分方式我遵照原论文的设置。 下载好的数据的网盘链接已放置在附件中。
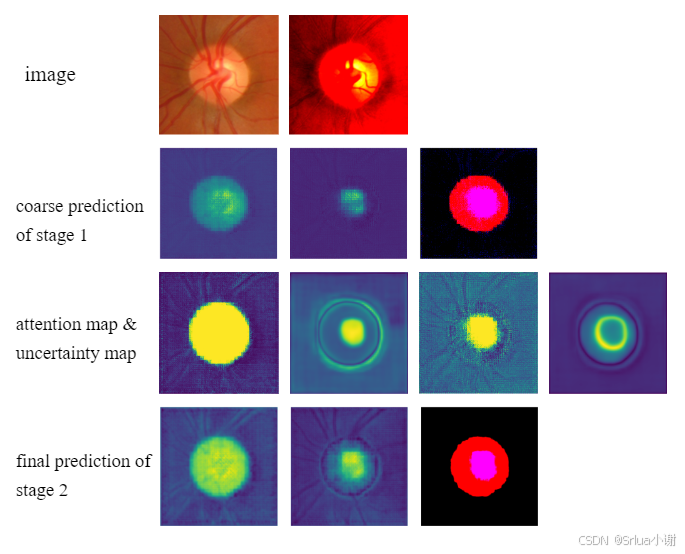
在RIGA数据集上,我复现原论文后得到的以上可视化结果(针对一个样本)
- 第一行,image: 初始image, 经过数据增强后的image
- 第二行,阶段1的粗略预测:视盘分割预测,视杯分割预测,两者叠加
- 第三行,基于MRM重构的预测计算出的uncertainty map: 视盘注意力图,视盘不确定性图,视杯注意力图,视杯不确定性图
- 视盘/视杯注意力图,表示网络认为某个像素属于视盘/视杯的概率
- 视盘/视杯不确定性图,表示视盘/视杯区域的多评估者预测之间的差异,即模型对这些区域的不确定性
- 第四行,阶段2的最终预测:视盘分割预测,视杯分割预测,两者叠加
实验步骤
本文进行了较为完整的复现,模型权重、下载好的数据集(RIGA)以及实验结果文件我已放置在附件中的网盘链接中,欢迎下载
1. 下载附件中的项目文件 2. train
python demo.py # set '--phase' as train3. test
python demo.py # set '--phase' as test环境设置
Ubuntu 20.04 x86_64 CUDA 12.1 python 3.9.18 torch 1.11.0+cu113

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号