【Linux】多线程(概念,控制)


🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm=1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12625432.html
前言
💬 hello! 各位铁子们大家好哇。 今日更新了Linux线程的内容 🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
再谈地址空间
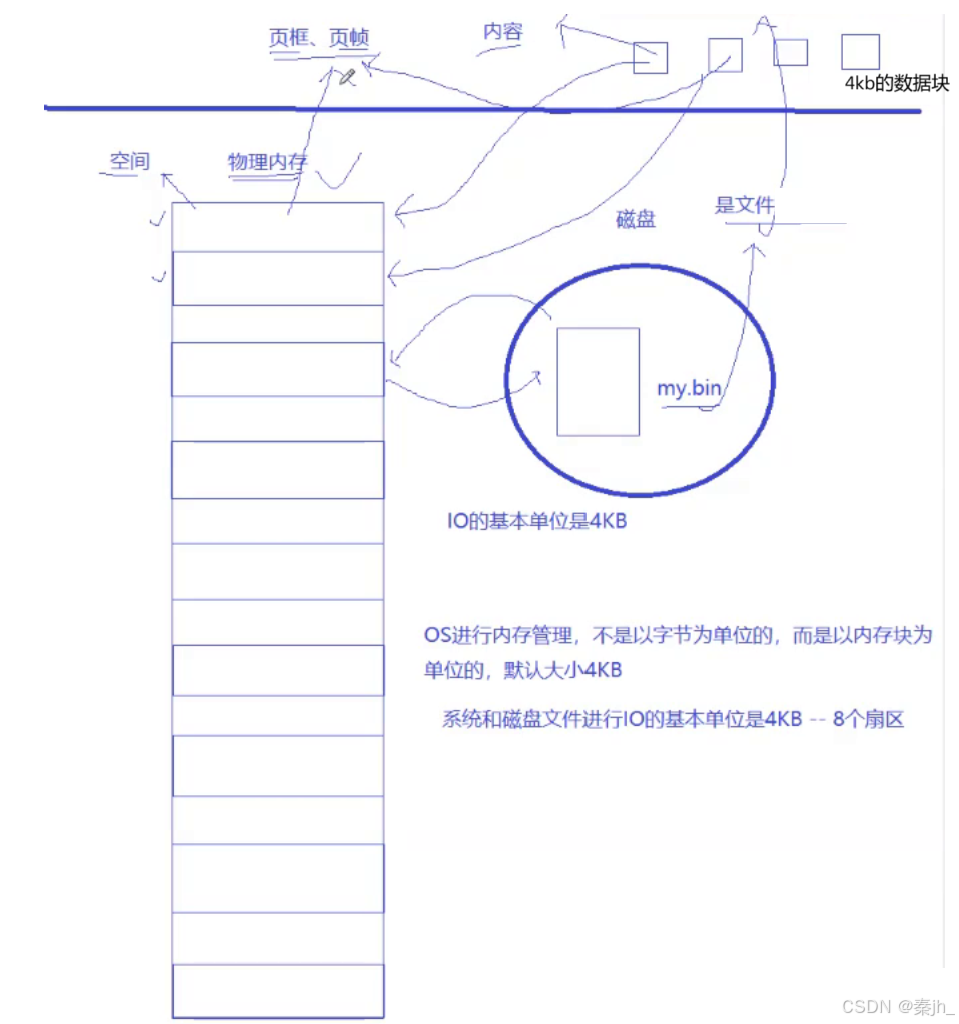
OS进行内存管理,不是以字节为单位的,而是以内存块为单位的,默认大小是4KB。 系统和磁盘文件进行IO的基本单位是4KB--8个扇区。 文件在磁盘中存的时候是有自己的dateblock的,每个dateblock的大小都是4KB。所以内存管理时,加载就是把程序的数据块加载到指定的内存块中。
为了方便进行表述,4kb的空间+内容有一个名字,叫页框或页帧。 在内核里有一个struct page来管理每一个页框。内存看成是数组,第一个page的起始地址就是数组下标*4==0 ,第二个page的起始地址是数组下标*4==4。所以每个page都有了下标。
虚拟地址如何转换为物理地址?
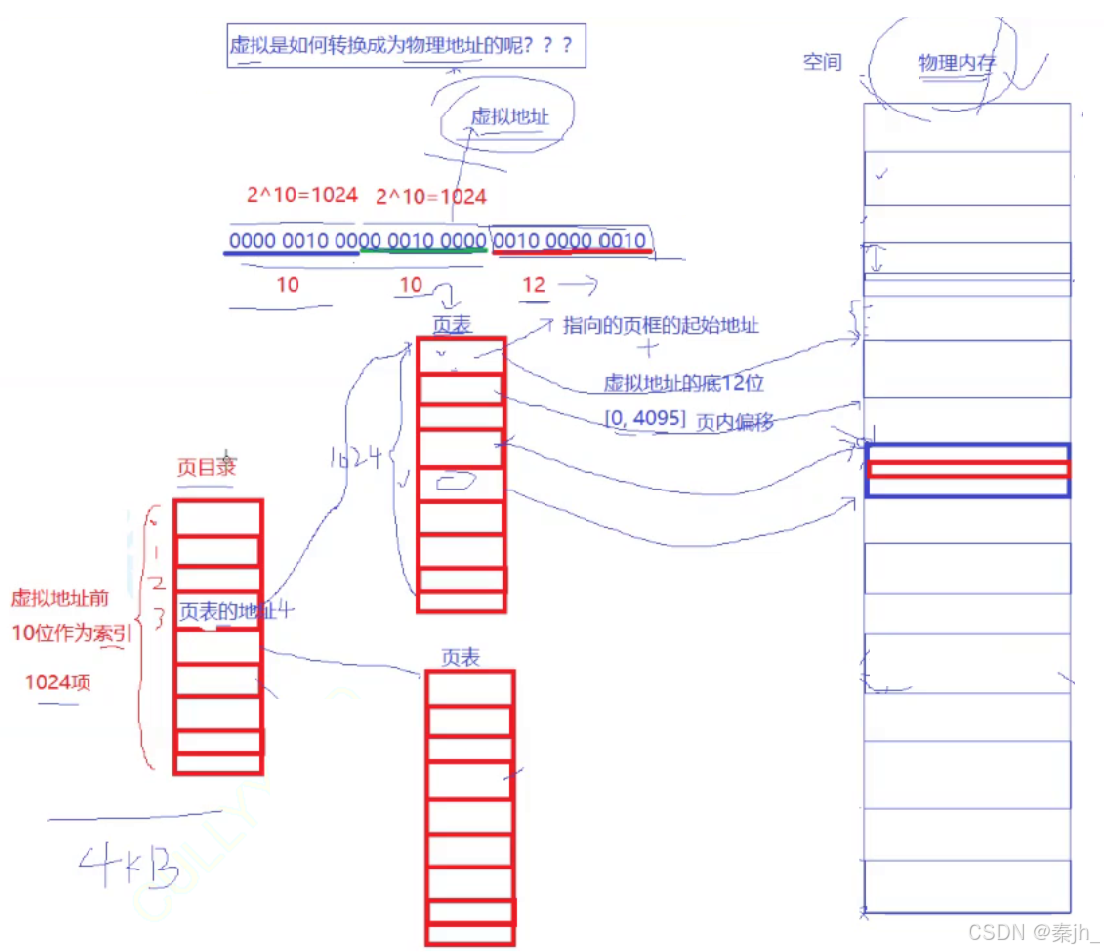
虚拟地址的前10个比特位索引页目录,中间10个比特位索引页表。 页表指向对应页框的起始地址。虚拟地址的低12位+页框的起始地址就能找到页框内的任意一个字节了。 这种页表也叫二级页表,用来搜索页框。 虚拟地址本质是一种资源。
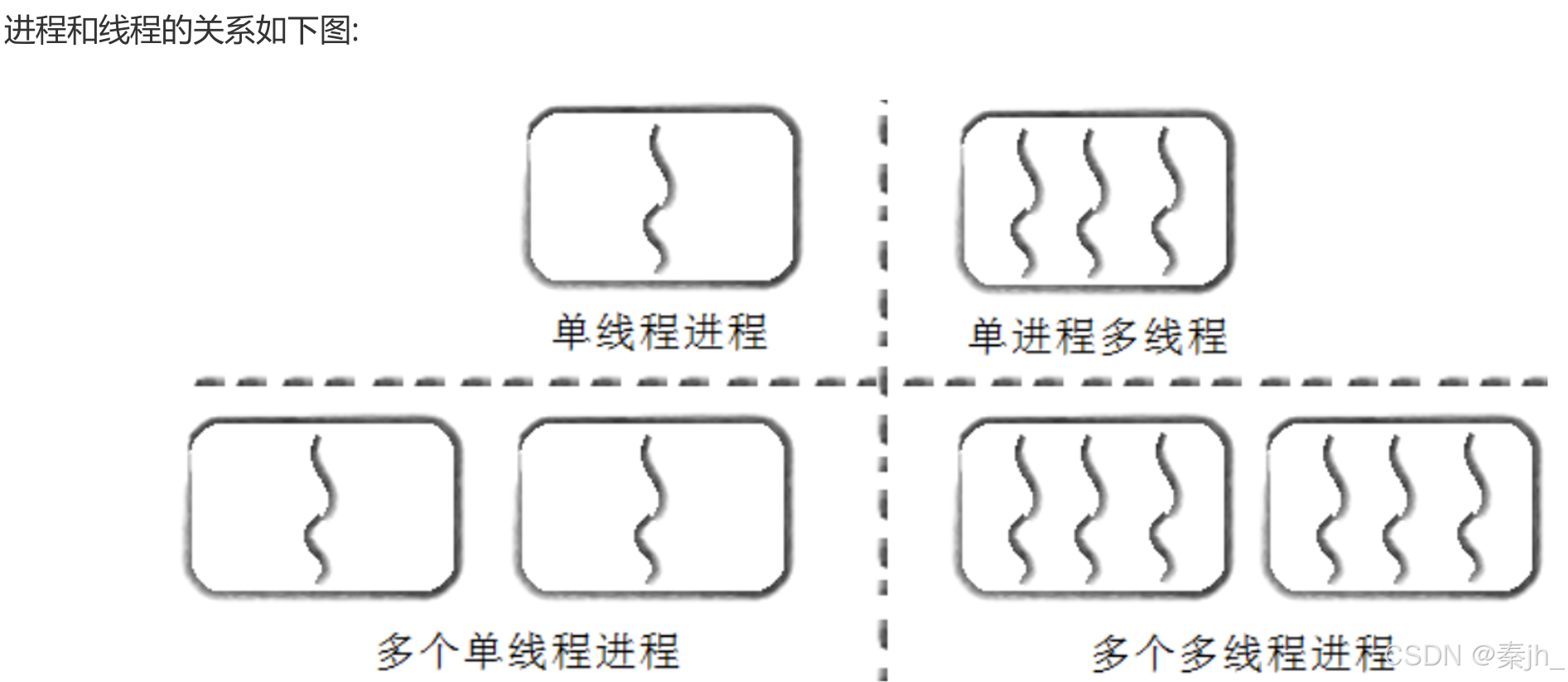
线程概念
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
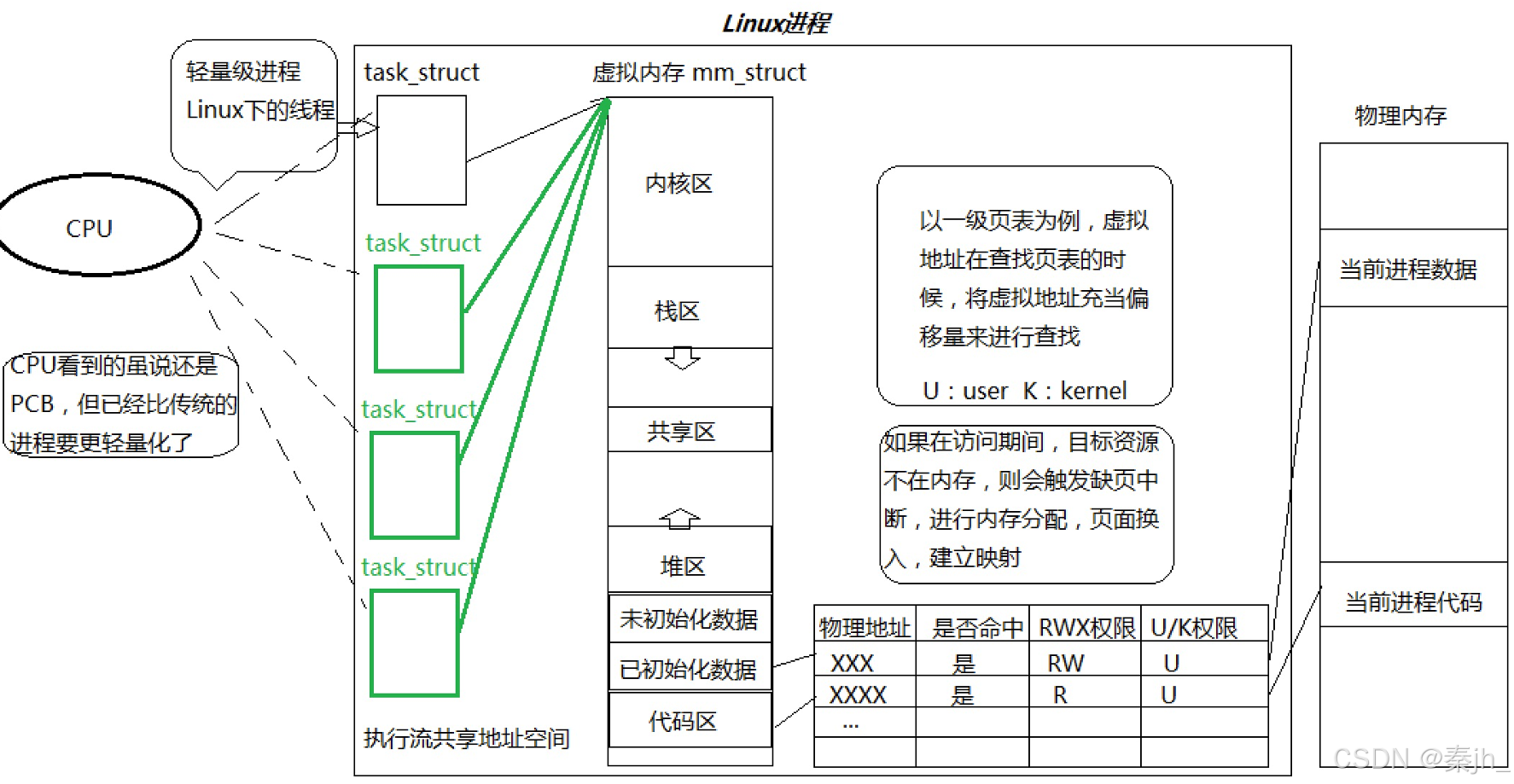
线程:在进程内部运行,是CPU调度的基本单位。 进程:承担分配系统资源的基本实体。 我们以前讲的进程内部都是只有一个执行流的进程。 Windows系统里有struct tcb结构体描述线程,Linux系统选择复用struct pcb结构体。所以Linux是用进程模拟的线程。 Linux中CPU不区分task_struct 是进程还是线程,都看做执行流。 CPU看到的执行流<=进程。 Linux中的执行流叫:轻量级进程。
创建线程初识

功能:创建一个新的线程 参数
- thread:返回线程ID
- attr:设置线程的属性,attr为nullptr表示使用默认属性(这里用默认即可)
- start_routine:是个函数指针,线程启动后要执行的函数。返回值类型为void*,参数类型为void*
- arg:传给线程启动函数的参数
返回值:成功返回0;失败返回错误码
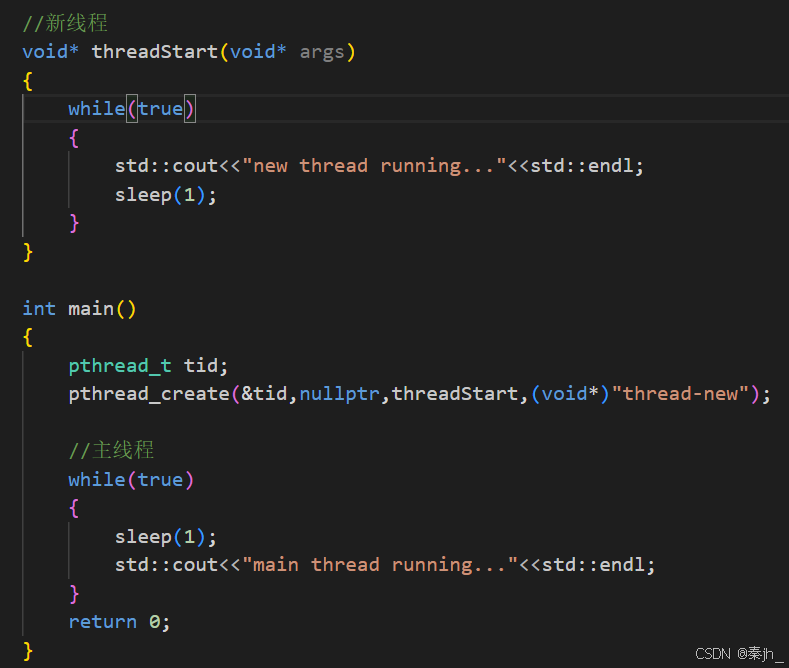

直接编译,会报错,说直接创建线程是未定义的行为。 Linux中要使用线程,编译时要引入pthread库。


运行程序, 因为主次线程里都是死循环打印,结果主次线程都有打印,说明有多执行流,即线程创建成功了。


打印出他们的pid,可以看到主次线程的pid都是一样的,因为这两个线程他们都属于同一个进程内部,所以对应的进程pid是一样的。

如果想查看线程,可以通过指令 ps -aL 。他们的pid都是一样的。LWP就是Light Weight Process,即轻量级进程,就是线程的id。 我们把pid和lwp都相等的执行流叫主线程。
线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程的缺点
- 性能损失
- 健壮性降低
- 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了 不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。(多线程程序,如果其中一个线程出问题,整个进程就会出问题)
- 缺乏访问控制
线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
Linux进程VS线程
- 进程是资源分配的基本单位
- 线程是调度的基本单位
- 线程共享进程数据,但也拥有自己的一部分数据:
- 线程ID
- 一组寄存器(重要)
- 栈(重要)(线程运行的时候,会形成各种临时变量,临时变量会被每个线程保存在自己的栈区)
- errno
- 信号屏蔽字
- 调度优先级
进程的多个线程共享同一地址空间,除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户id和组id
Linux线程控制
POSIX线程库
- 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的
- 要使用这些函数库,要通过引入头文件<pthread.h>
- 链接这些线程函数库时要使用编译器命令的“-lpthread”选项
创建线程
前面已经简单介绍了pthread_create的使用。在创建完成后,主线程会继续向下执行代码,新线程会去执行参数3所指向的函数。此时执行流就一分为二了。
线程等待

功能:等待线程结束 参数
- thread:线程ID
- retval:它指向一个指针,指向线程的返回值 (输出型参数)
参数2的类型是void**,用来接收新线程函数的返回值,因为新线程函数的返回值类型是void*。未来要拿到新线程的返回值void*,放到void* retval中时,这里的参数就得传&retval。 返回值:成功返回0;失败返回错误码
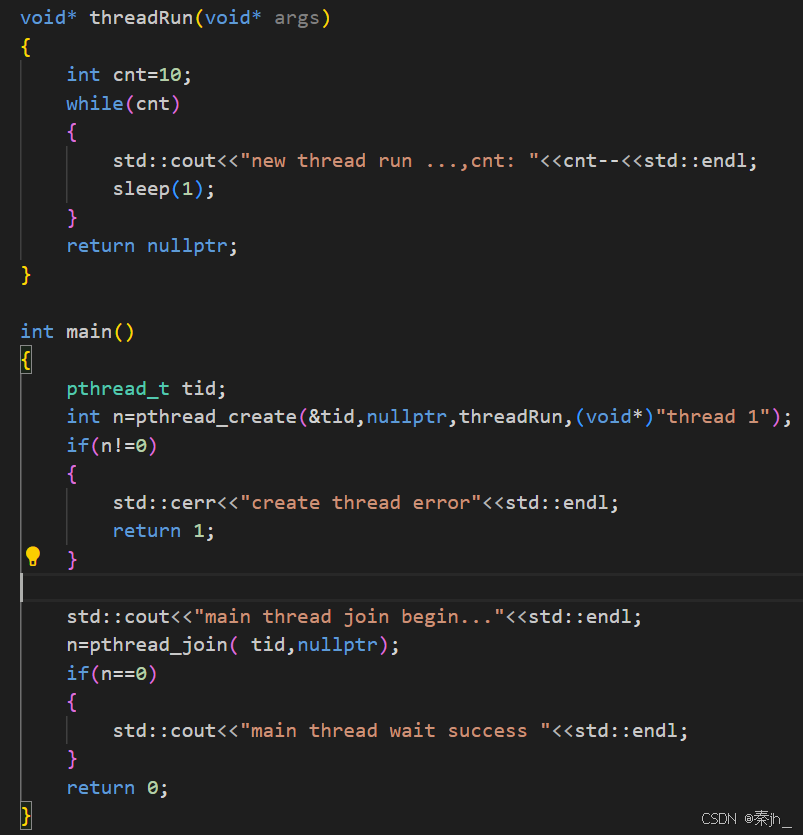
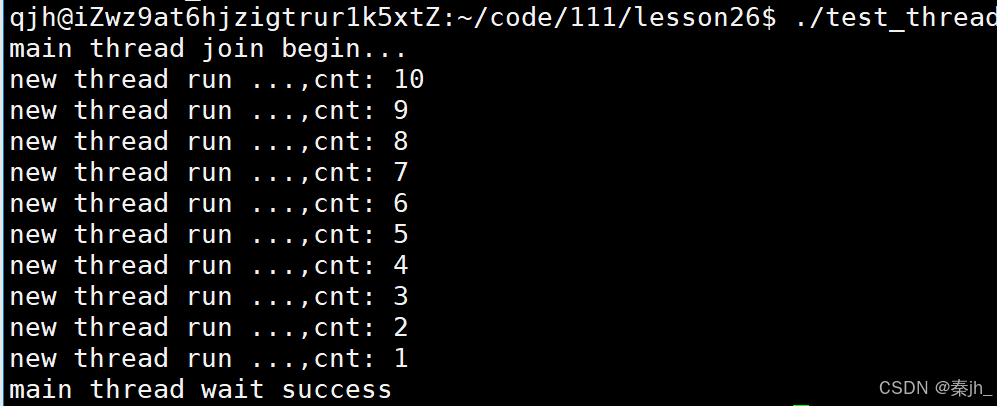
如上图,为pthread_create和pthread_join的简单使用。pthread_t类型由库提供。主线程和新线程谁先运行,这是不确定的。
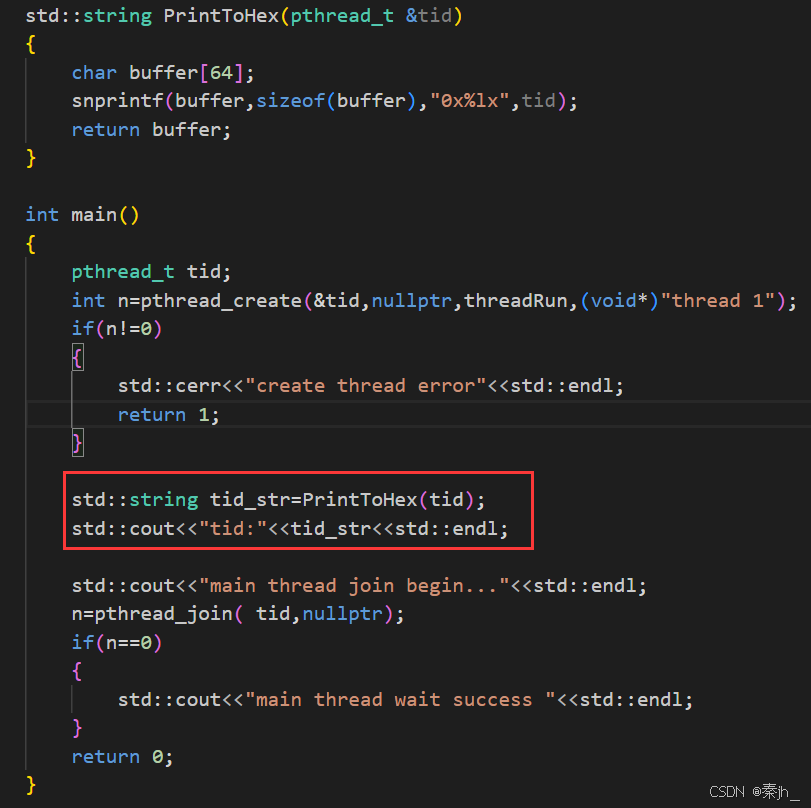


我们把tid以字符串的形式打印出来,发现是一个虚拟地址,他跟线程id不一样。
线程函数传参
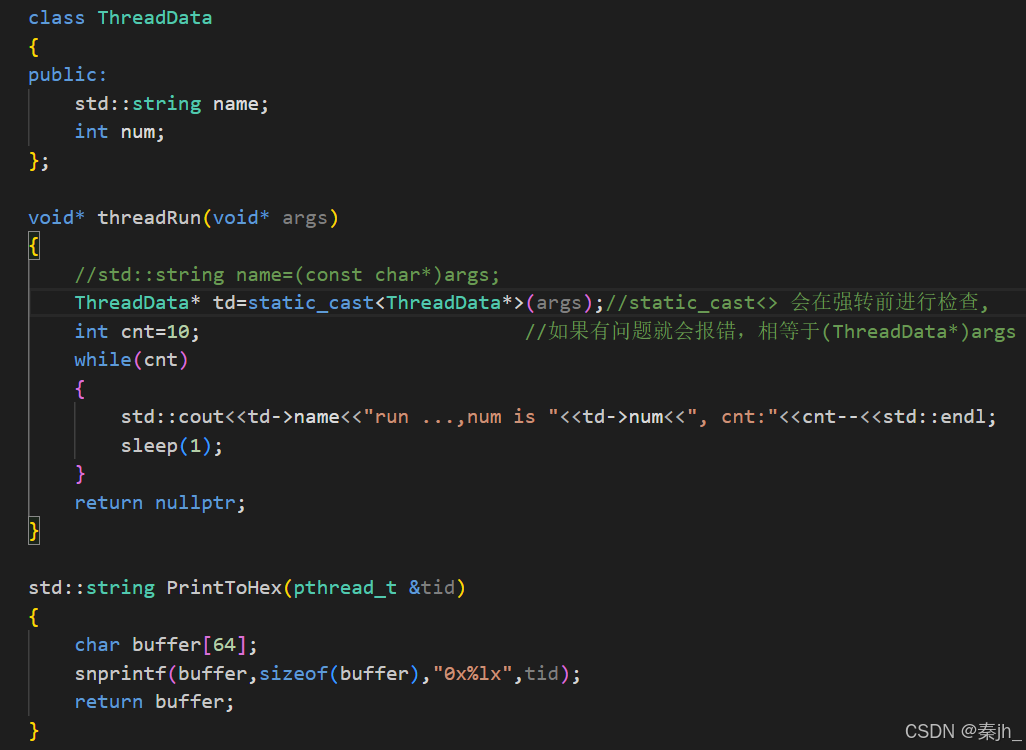
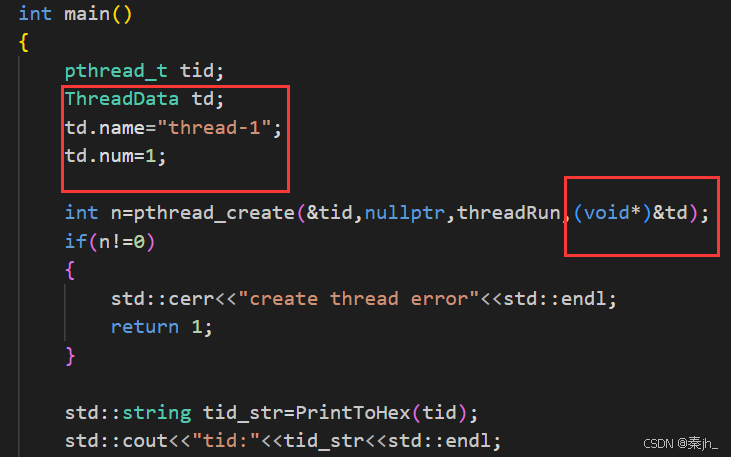
线程函数传参,可以传任意类型,一定要记住还可以传类对象的地址。 有了这个,就意味着可以给线程传递多个参数,甚至方法了。 上面的td对象是在主线程的栈上的,新线程访问了主线程栈上的临时变量,我们不推荐这种做法。因为如果main函数有第二个对象,他们在读取时没有影响,但其中一个对象在修改时,另一个也会跟着修改。推荐做法如下图:
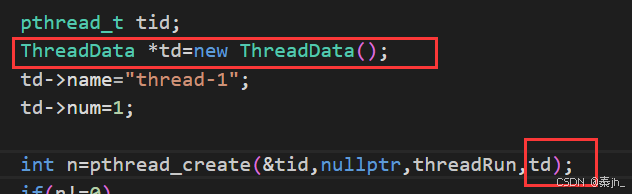
我们建议在堆上申请一段空间,未来需要第二个对象时,再重新new一个对象,这样多线程就不会互相干扰了。
线程函数返回值
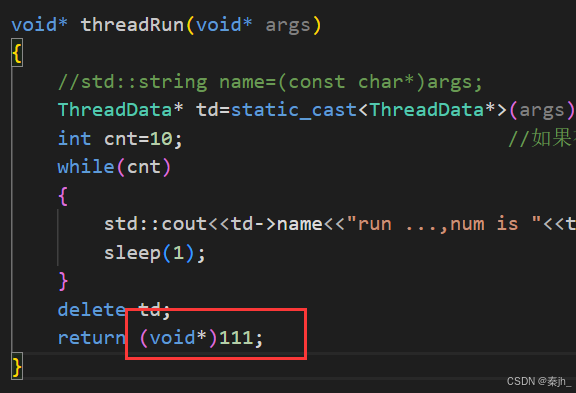
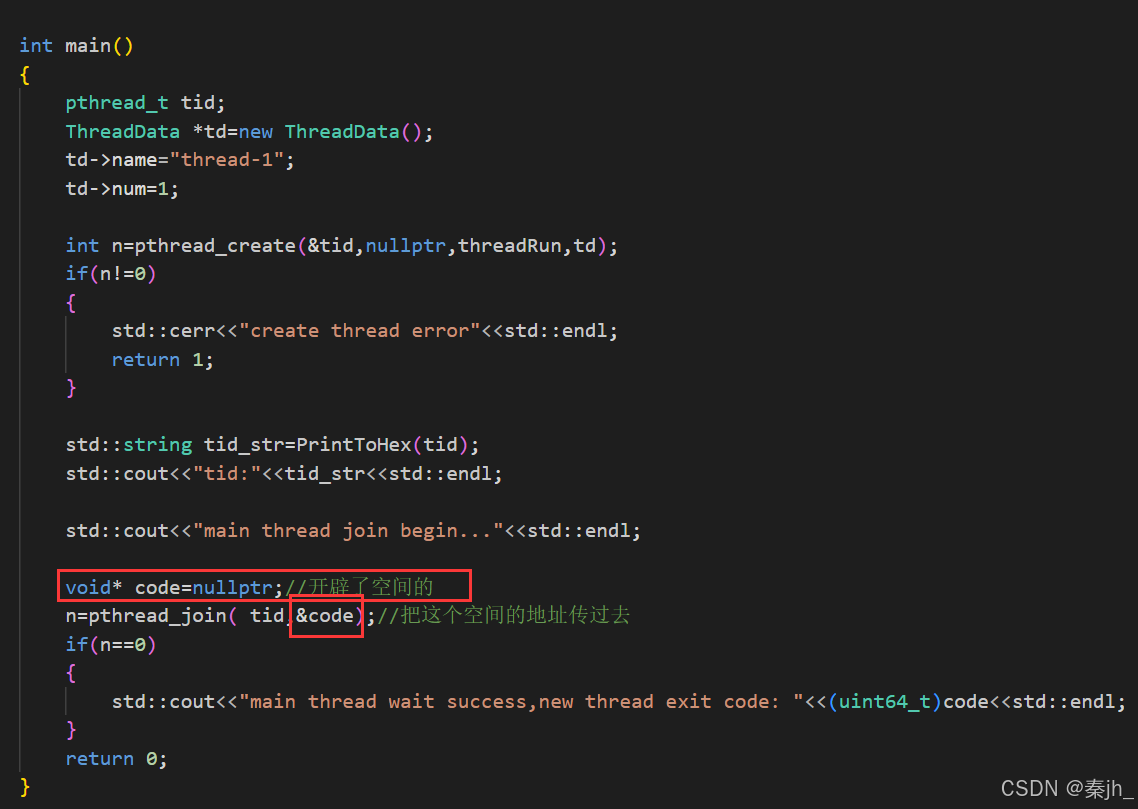
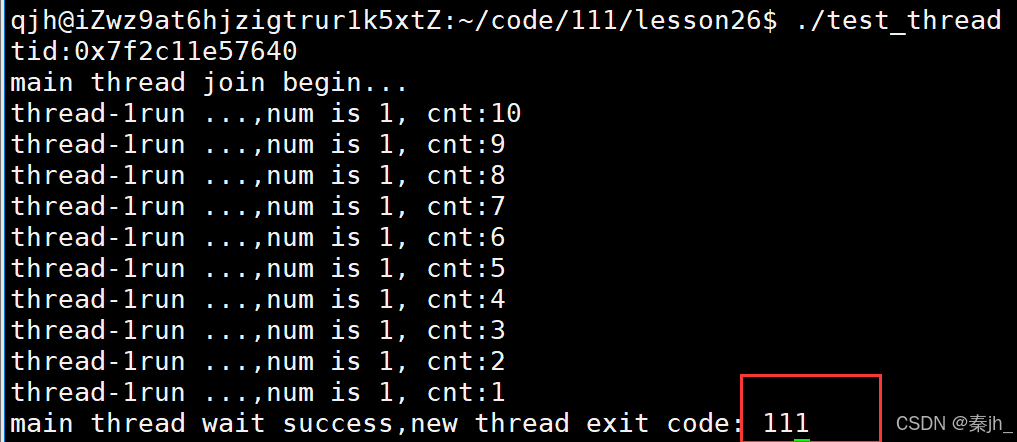
如果新线程返回值不是nullptr,而是别的退出信息时。主线程可以在join时拿到退出信息,如上图,定义了一个指针code,这个指针是开辟了空间的,把空间的地址传过去,就能拿到退出信息了。
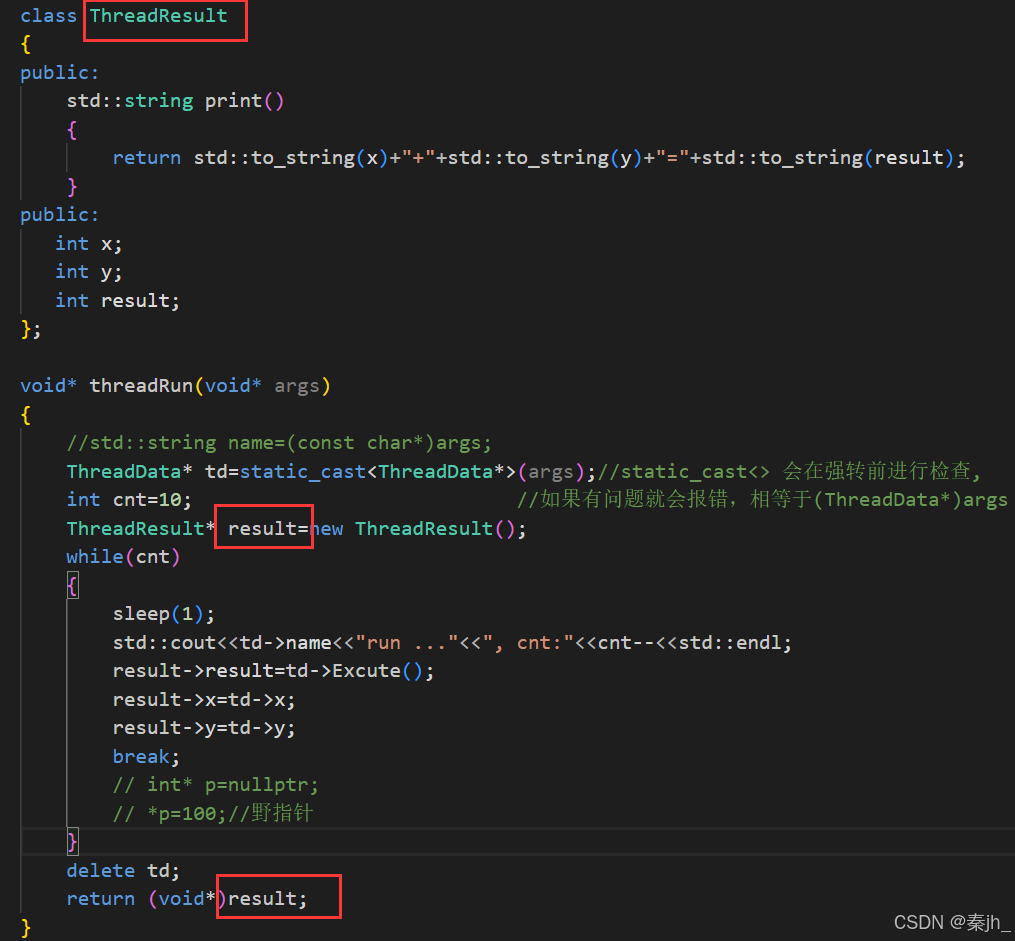
返回值还可以是类对象的地址,主线程接收时用对应类类型对象接收即可。 如果新线程异常了,整个进程就崩溃了,包括主线程。因为信号是发给进程的,不是发给线程的。所以只考虑正确的返回值,不考虑异常,因为异常时整个程序就挂掉了。
创建多线程
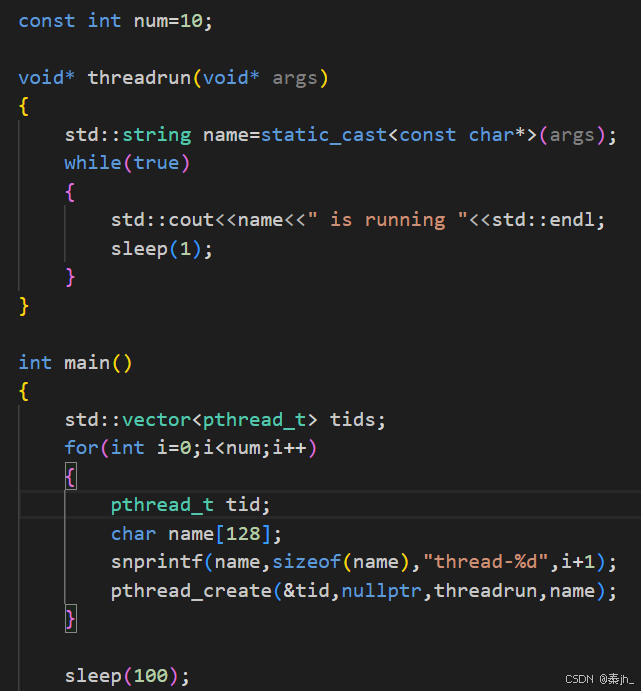
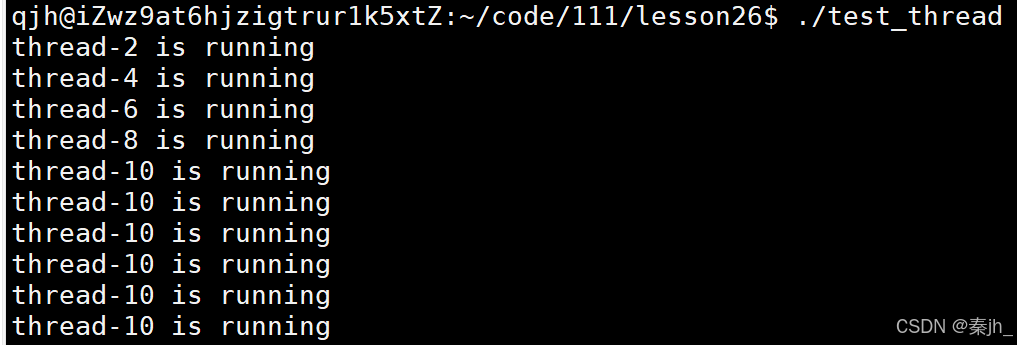
下面是完整代码:
const int num=10;
void* threadrun(void* args)
{
std::string name=static_cast<const char*>(args);
while(true)
{
std::cout<<name<<" is running "<<std::endl;
sleep(1);
break;
}
return args;
}
int main()
{
std::vector<pthread_t> tids;
for(int i=0;i<num;i++)
{
//1.线程的id
pthread_t tid;
//2.线程的名字
char* name=new char[128];
snprintf(name,128,"thread-%d",i+1);
pthread_create(&tid,nullptr,threadrun,name);
//3.保存所有线程的id信息
tids.push_back(tid);
//tids.emplace_back(tid);
}
for(auto tid:tids)
{
void* name=nullptr;
pthread_join(tid,&name);
// std::cout<<PrintToHex(tid)<<"quit ..."<<std::endl;
std::cout<<(const char* )name<<" quit..."<<std::endl;
delete (const char* )name;
}
return 0;
}运行结果为什么线程名是乱的?因为即使我们的线程是按顺序创建的,但他们不是按顺序启动的。而且上面的name,属于main函数栈上的空间,即main函数栈空间上的公共区传给了每一个线程,所以线程名会被不断覆盖。所以上面这么写是有问题的,要在堆在开辟空间。
线程终止
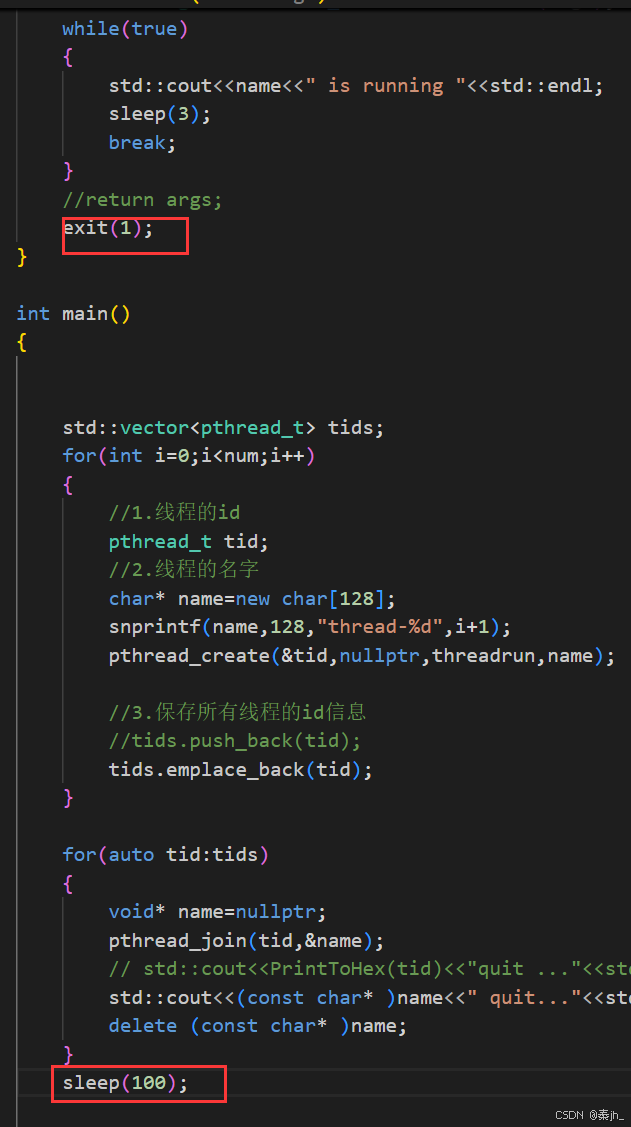
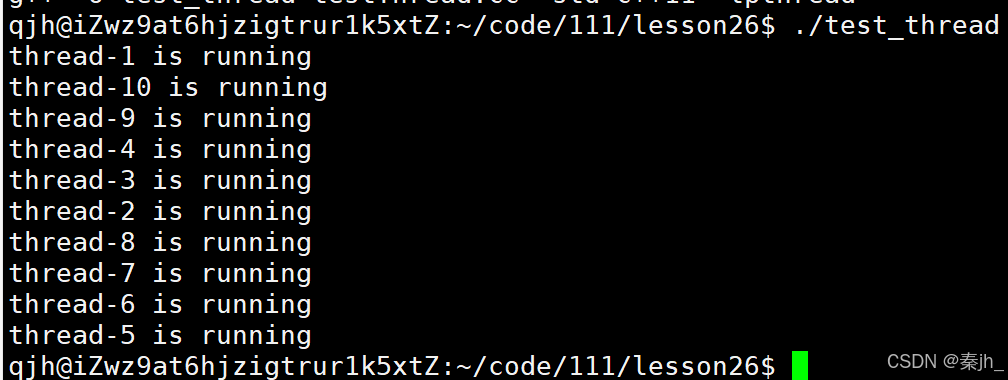
运行后,发现主线程没有打印quit语句。因为exit是专门用来终止进程的,不能用来终止线程。任意一个线程调用exit,都可能会导致进程退出。
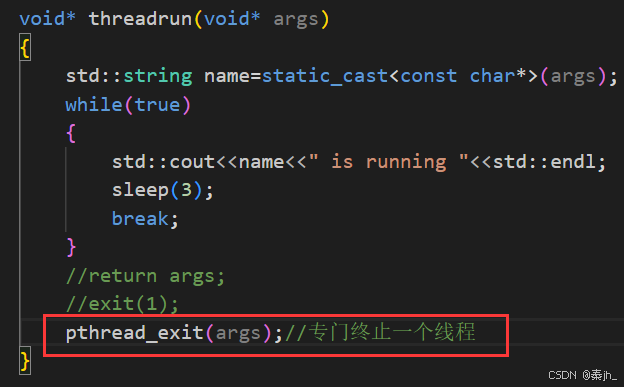
除了用return结束线程,pthread_exit是专门用来终止一个线程的,使用如下图:
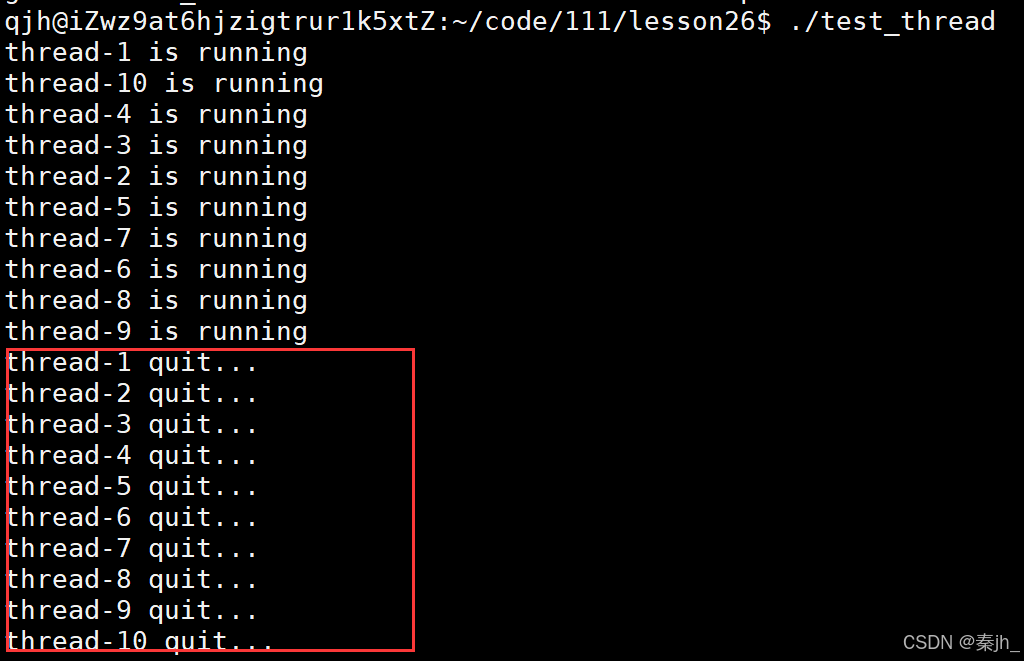
下面是终止线程的另一种方法:

主线程调用pthread_cancel取消新线程。取消一个线程的前提是线程得存在。
下面是使用举例:
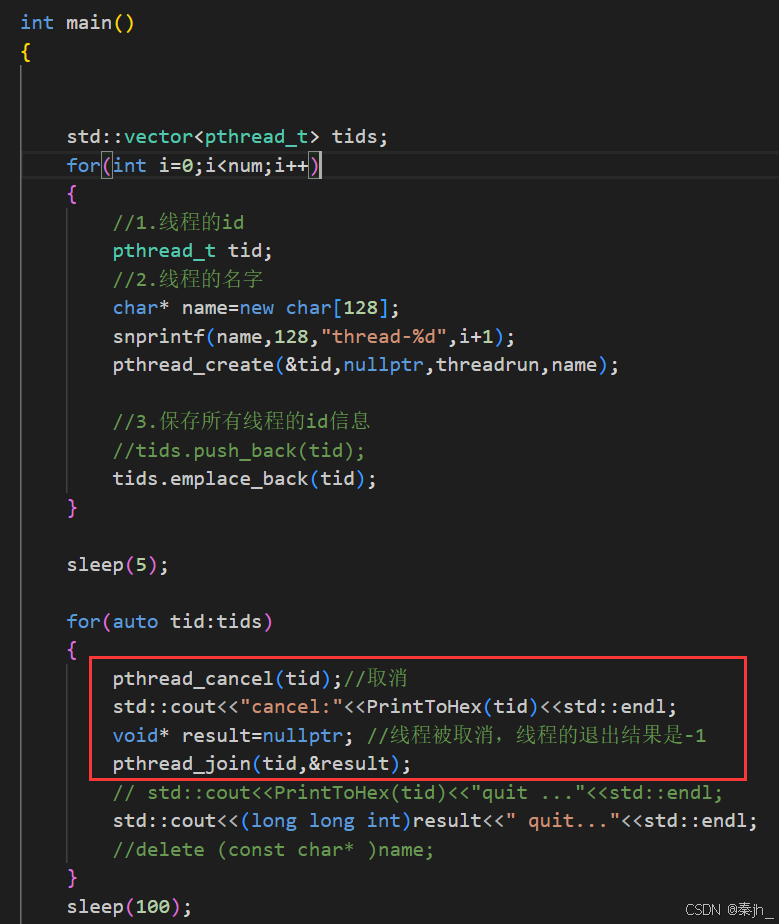
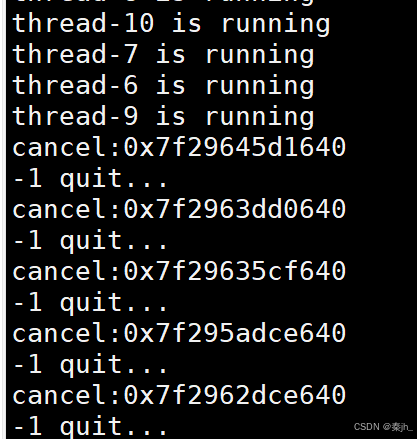
线程取消一个就join一个。由上图可知,线程被取消后,线程的退出结果是-1。 -1对应pthread库中的一个宏。

分离线程

- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源
- joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
- 如果一个线程被分离,线程的工作状态就是分离状态,不需要被join,但依旧属于进程内部。

作用:哪个线程调用该接口,就返回他自己的线程id。相当于以前的getpid。
void* threadrun(void* args)
{
pthread_detach(pthread_self());
std::string name=static_cast<const char*>(args);
while(true)
{
std::cout<<name<<" is running "<<std::endl;
sleep(3);
break;
}
pthread_exit(args);//专门终止一个线程
}
int main()
{
std::vector<pthread_t> tids;
for(int i=0;i<num;i++)
{
//1.线程的id
pthread_t tid;
//2.线程的名字
char* name=new char[128];
snprintf(name,128,"thread-%d",i+1);
pthread_create(&tid,nullptr,threadrun,name);
tids.emplace_back(tid);
}
for(auto tid:tids)
{
void* result=nullptr; //线程被取消,线程的退出结果是-1
int n=pthread_join(tid,&result);
std::cout<<(long long int)result<<" quit... ,n: "<<n<<std::endl;
}
return 0;
}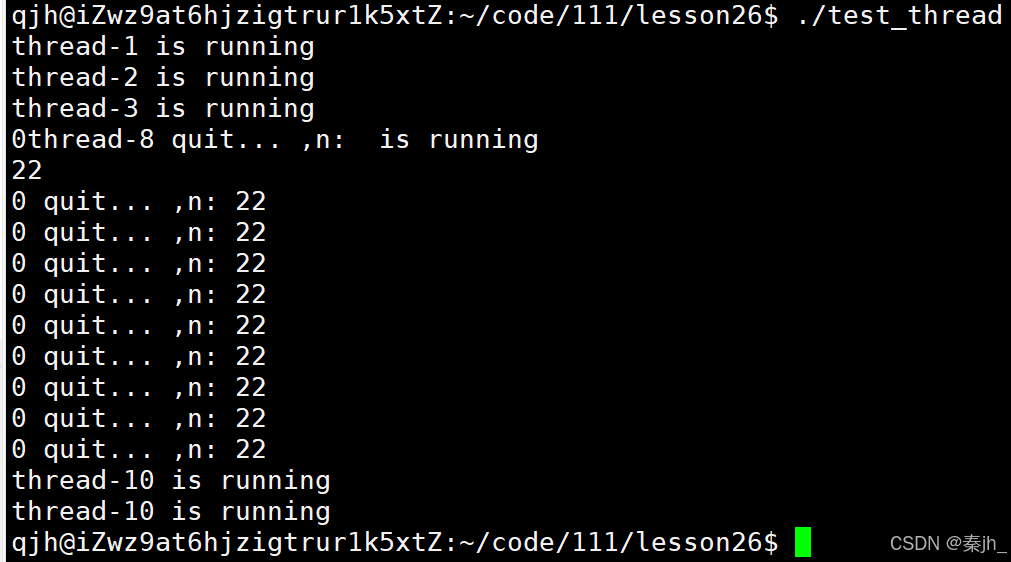
运行上面代码,程序直接挂掉了。因为新线程已经分离,主线程不会卡在join,而是会继续往后走,主线程结束了,整个进程就结束了,新线程可能还没起来就死亡了。 所以分离线程后,主线程就可以做自己的事了,不用管新线程。 即使新线程分离,只要分离的线程异常了,还是会影响整个进程。
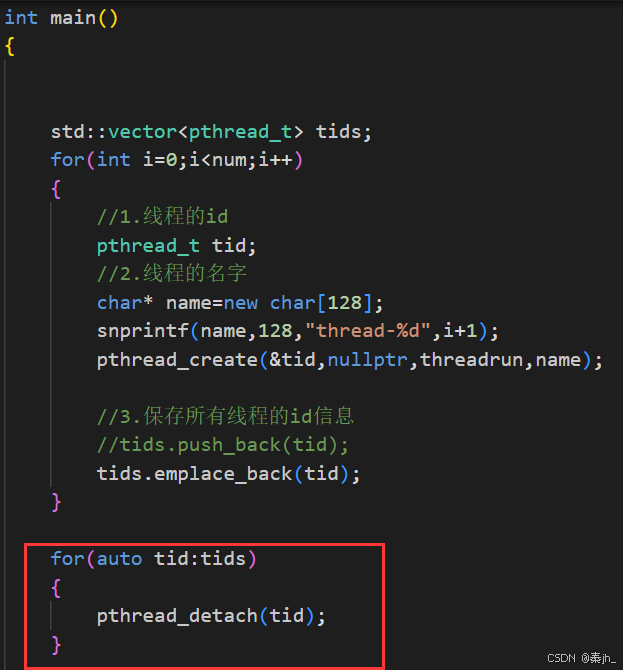
除了可以让新线程自己分离,也可以由主线程进行分离。
C++11使用多线程
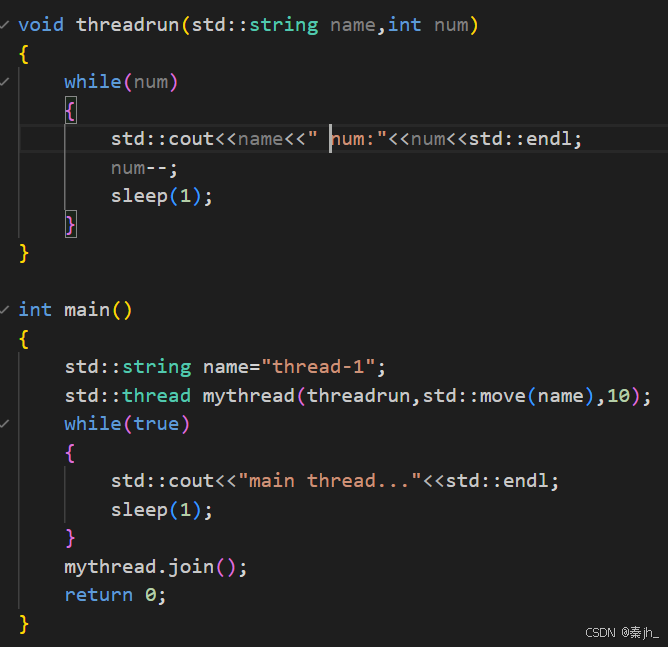
C++11里使用多线程,创建时是支持可变参数的。大致用法跟前文讲的差不多。
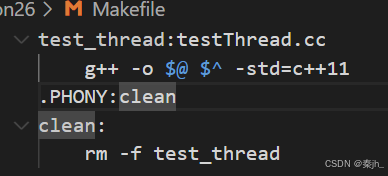
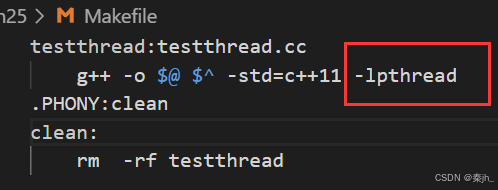
我们把makefile文件里的 -lpthread 去掉然后编译。
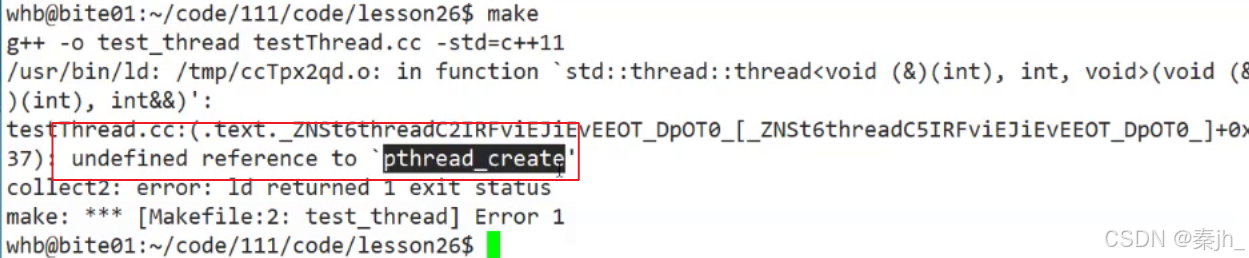
编译后,报错了,链接时报错。所以C++语言在Linux中要编译支持多线程,也要加 -lpthread。
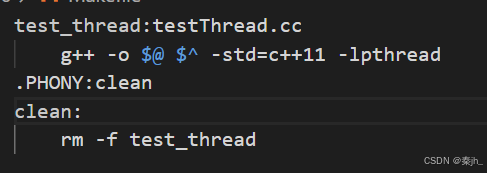
C++11的多线程本质:就是对原生线程库接口的封装。 Linux中,C++11要支持多线程,底层必须封装Linux环境的pthread库,编译的时候都得带。 在Windows下要编译多线程程序不用带-lpthread。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-11-11,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号