TCP/IP学习笔记


摘要:
本文详细介绍了OSI七层模型和TCP/IP四层模型,包括各层的功能、协议及其在数据通信中的作用,如应用层负责数据格式,传输层的TCP和UDP,网络层的IP和MAC寻址,以及数据链路层的硬件接口。以HTTP请求为例,展示了数据从应用层到网络层再到数据链路层的完整过程。
1 网络的分层
(1)OSI(Open System Interconnect,开放式系统互连)七层模型与TCP/IP 四层模型
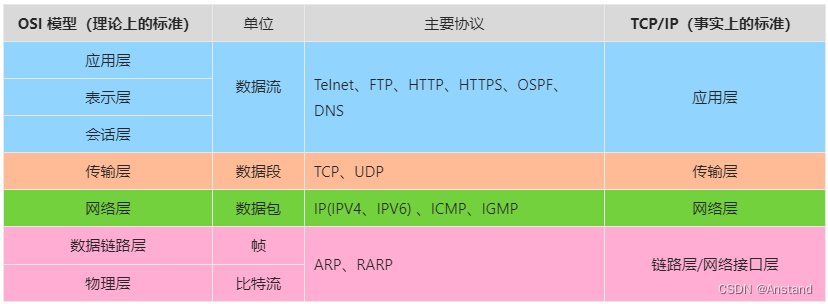
1.1 七层模型与四层模型
结构名 | 功能 | 主要设备 |
|---|---|---|
应用层 | 是最靠近用户的OSI层。用户接口、应用程序。应用层向应用进程展示所有的网络服务。当一个应用进程访问网络时,通过该层执行所有的动作。 | 网关 |
表示层 | 可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。例如,PC程序与另一台计算机进行通信,其中一台计算机使用扩展二一十进制交换码(EBCDIC),而另一台则使用美国信息交换标准码(ASCII)来表示相同的字符。如有必要,表示层会通过使用一种通格式来实现多种数据格式之间的转换。 | 网关 |
会话层 | 通过传输层(端口号:传输端口接收端口)建立数据传输的通路。主要在你的系统之间发起会话或者接受会话请求(设备之间需要互相认识可以是IP也可以是MAC或者是主机名)。 | 网关 |
传输层 | 定义了一些传输数据的协议和端口号(WWW端口80等),端到端控制,确保按顺序无错的发送数据包。如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与TCP特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ聊天数据就是通过这种方式传输的)。 主要是将从会话层接收的数据进行分段和传输,到达目的地址后再进行重组。常常把这一层数据叫做段。 | 网关 |
网络层 | 路由,寻址,网络层确定把数据包传送到其目的地的路径。就是把逻辑网络地址转换为物理地址。如果数据包太大不能通过路径中的一条链路送到目的地,那么网络层的任务就是把这些包分成较小的包。在位于不同地理位置的网络中的两个主机系统之间提供连接和路径选择。 | 路由器,网桥路由器 |
数据链路层 | 保证无差错的数据链路,一方面接收来自网络层(第三层)的数据帧并为物理层封装这些帧;另一方面数据链路层把来自物理层的原始数据比特封装到网络层的帧中。起着重要的中介作用。数据链路层由 IEEE802 规划改进为包含两个子层:介质访问控制(MAC)和逻辑链路控制(LLC)。 | 交换机、网桥、网卡 |
物理层 | 主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后再转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。 | 集线器、中继器、电缆,发送器,接收器 |
(2)TCP/IP 四层模型

1.2 四层模型代表
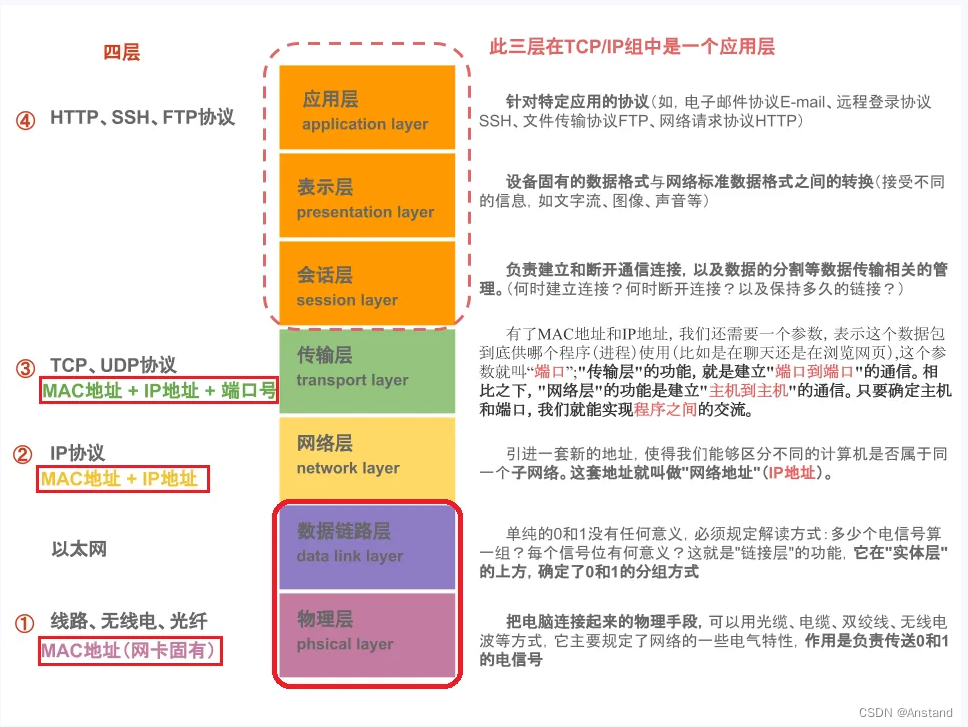
IP的作用:用于区分不同的计算机是否属于同一个子网络。
Mac的作用:用来标识具体用户,为了解决IP盗用的安全问题。例如一个局域网内,交换机会把IP和Mac地址做一个映射操作,交换机就是根据Mac地址进行发送和接受数据的,而端口号port则是决定与哪个应用进行通信和信息交互。
ARP(Address Resolution Protocol,地址解析协议)是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。借助 IP 获取 mac 地址。基于MAC地址的这种特点,局域网采用了用MAC地址来标识具体用户的方法。注意:具体实现:在交换机内部通过“表”的方式把MAC地址和IP地址一一映射,也就是所说的IP、MAC绑定。
MAC 地址是绑定在网卡上的,它是一个用来确认网络设备位置的位址。在OSI模型中,第三层网络层负责IP地址,第二层数据链路层则负责MAC位址 [1] 。MAC地址用于在网络中唯一标示一个网卡,一台设备若有一或多个网卡,则每个网卡都需要并会有一个唯一的MAC地址 [2] 。
IP:地址则是管理员分配的

网络层:网络层的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做“网络地址”,这是我们平时所说的IP地址。网络层协议包含的主要信息是源IP和目的IP。
网络层速记:IP(核心协议)
源IP —— 目标IP
IP协议的作用: 在 网络环境中唯一标识一台主机。
IP地址本质:2进制数。—— 点分十进制 IP地址 (string)
IP和MAC的作用:
网络地址(IP):帮助我们确定计算机所在的子网络
MAC 地址:则将数据包送到该子网络中的目标网卡。
处理顺序:从逻辑上可以推断,必定是先处理网络地址,然后再处理 MAC 地址
传输层:端口:确定进程
- 对于同一个端口,在不同系统中对应着不同的进程
- 对于同一个系统,一个端口只能被一个进程拥有
传输层速记:
TCP / UDP(核心协议)
port —— 在 一台主机上唯一标识一个进程。
应用关系:通过网络层IP确认交互端,通过MAC确认信息发送目标,最终通过端口指定要发生信息交互的程序
2 如何实现通信?
数据通信:
封装: 应用层 —— 传输层 —— 网络层 —— 链路层 。 没有经过封装的数据,不能在网络环境中传递。
解封装 : 链路层 —— 网络层 —— 传输层 —— 应用层
从上往下,每经过一层,协议就会在包头上面做点手脚,加点东西,传送到接收端,再层层解套出来,如下示意图:
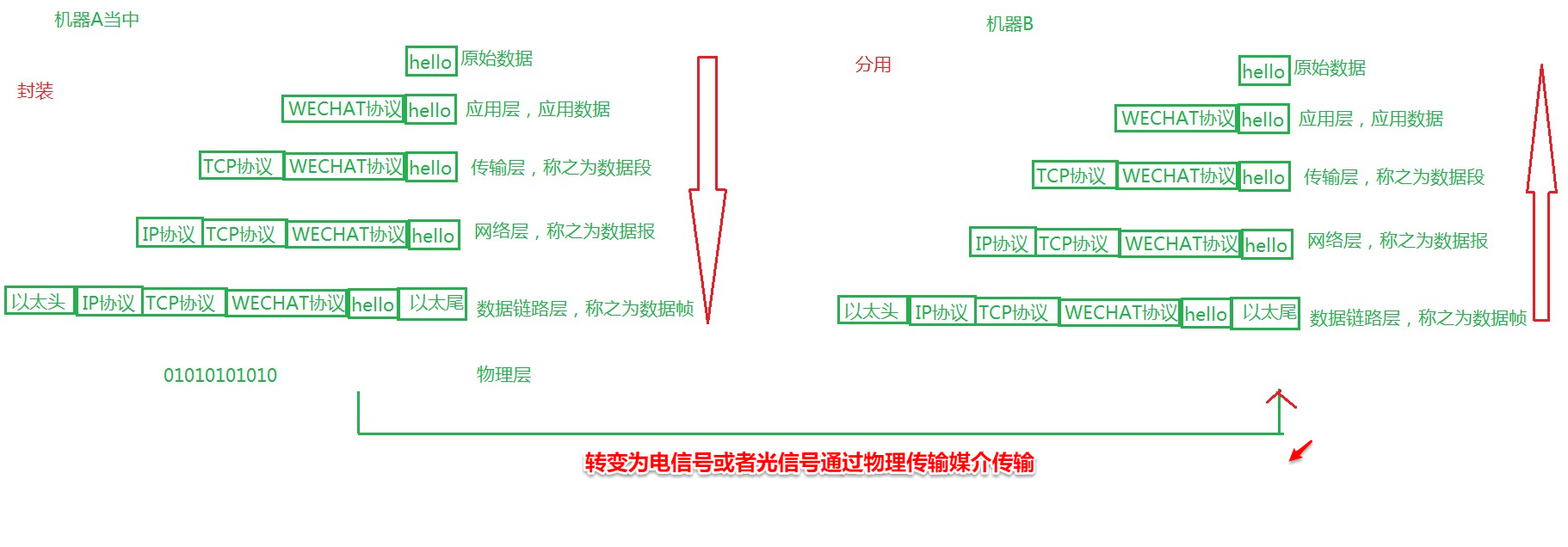
我们先从应用层开始讲起:
应用层:规定应用数据的数据格式,比如说FTP、DNS、SMTP等等,同时HTTP协议也属于应用层的范围。通俗来讲,应用层决定这一次通信要干嘛。
传输层:建立端口到端口的通信,提供两台计算机之间的数据传输,传输层中包含着两个很叼的协议,分别是TCP和UDP协议。面试中经常提及的三次握手,四次挥手就是TCP协议的部分内容
网络层:通过MAC地址和IP地址将互联网上的任意两台主机建立通信,网络层则是用来处理这些流动的数据包,也就是如果把相应的数据包路由到指定的地点,为通信时的网络传输选择传输路线
数据链路层:数据链路层包含了软件与硬件的接口部分,以及各种网络设备的硬件,也就是整个网络通信过程中最底层的基础设施,确定电信号0和1的分组方式
简单了解了每一层的作用之后,我们试着串起来,摸索一下一次整体的http请求到响应的过程。
拿访问google做个例子
1、访问google.com,按下回车。
2、应用层准备好请求报文,通过DNS服务进行域名解析,得到google的ip地址,并将报文发到传输层。传输层收到报文后,会将请求的数据包进行拆分,打包,并对每个包裹打上tag。在请求报文的基础上,加上一层TCP的首部信息,然后发往网络层。
3、到了网络层以后,IP协议就发挥了巨大的作用,IP协议中需要两个比较重要的信息,那就是ip地址和mac地址。ip已经在应用层通过dns解析出来了,那mac怎么办。。。真尴尬,然而这时ARP协议又冒了出来,它可以根据ip地址反向查询到目标主机的mac地址。好了,现在啥都有了,打包带走,把数据发到数据链路层。
4、终于走到基础设施这里了,此时数据包就在一根根光纤中旋转跳跃的奔向目的地,当然,整个过程不一定是直达的,可能需要经过各种中转站,就跟坐火车转车一样的。
5、请求到达服务器后,先从数据链路层往上走,并验证消去以太网首部信息,在网络层消去IP首部,在传输层消去TCP首部,就像剥洋葱一样一层一层去皮,最后剩下的就请求报文。在应用层对请求做出处理之后,需要对请求返回一个响应。而整个响应的传输过程就和请求一样,一层一层的封装,响应到达客户端时再一层一层的消去首部,最后呈现响应的结果。
3 TCP协议的包头解析
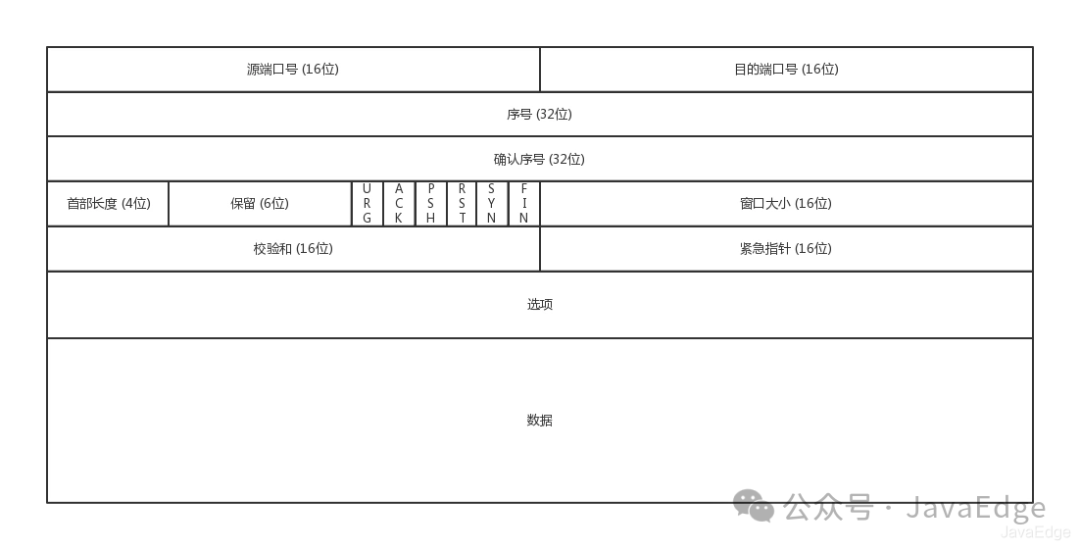
TCP头
① 源、目标端口号
和UDP一样。没这俩端口号,数据就不知该发给哪个应用。
② 包的序号
为啥要给包编号?解决乱序。不编号,咋确认哪个该先来,哪个该后到?
③ 确认序号
发出去的包应该有确认。若没收到就该重发,直到送达,以不丢包。
TCP是靠谱协议,但不代表它所处的网络环境很好。IP层来看,若网络状况差,无任何可靠性保证,即使是IP的上一层TCP也无能为力,能做的只是更努力,不断重传,通过各种算法尽量保证。即对于TCP,IP层你丢不丢包,我管不着,但在我TCP层会尽力保证可靠性。
④ 状态位
- SYN:发起一个连接
- URG : 紧急指针有效
- ACK:确认号有效
- RST:重新连接
- FIN:结束连接
- PSH: 无需缓存直接发送给应用程序
TCP是面向连接,因而双方要维护连接状态,这些带状态位的包的发送,会引起双方状态变更。
⑤ 窗口大小
TCP要做流量控制,通信双方各声明一个窗口,标识自己当前能够的处理能力,别发送太快或太慢。 拥塞控制,对于真正的通路堵车不堵车,它无能为力,唯一能做的就是控制自己,也即控制发送的速度。
4 TCP的三次握手和四次挥手
三次握手
先建立一个连接,TCP的连接建立,称为三次握手。
- A:你好,我是A
- B:你好A,我是B
- A:你好B
也常称“请求->应答->应答之应答”的三回合。
为啥三次,两次不够吗?
生活里两人打招呼,一来一回就够,那既然为了可靠,为啥不四次?
假设这个通路非常不可靠,A要发起一个连接,当发了第一个请求,无响应,会有很多可能性:
- 第一个请求包丢了
- 没丢,但绕了弯路,超时了
- B没响应,不想和我连接
A不能确认结果,于是再发发发。终于有个请求包到了B,但请求包到了B这件事,A还不知道,所以A可能再发。
B收到请求包,就知道了A的存在,且知道A要和它建立连接。若B:
- 不情愿建立连接,则A会重试一阵后放弃,连接建立失败
- 乐意建立连接,则会发送应答包给A
对于B,这个应答包也不知道能否到达A。这时B自然也不能认为连接是建立好了,因为应答包可能:
- 会丢
- 会绕弯路
- A挂了
网络延迟或包丢失
这时B还能碰到诡异现象:A和B原来建立了连接,简单通信后,结束了连接。
假设A和B之间已经建立过一次连接,并且这次连接已经顺利地建立并结束了。在连接结束后,网络中的某个节点因为某种原因出现了延迟,导致A最初发送的一个“连接请求”包(SYN)绕了一大圈,直到连接结束后才被B收到。这时B收到这个延迟的SYN包,会认为这是A再次发起的连接请求,而B并不知道这是一个“历史遗留”的请求包。
此时B基于这个延迟到达的SYN包,重新建立了一个新的连接。这就是所谓的“单相思”现象:实际上A已经结束了连接,但由于网络延迟,B误以为A重新发起了连接请求,于是建立了一个新的连接。但因为A其实并没有发起新的连接,所以B的这个连接不会真正进行下去,导致一种“诡异”的情况——B在与一个“已经结束通信的A”进行通信。
所以两次握手不够!
B发送的应答可能发送多次,但只要一次到达A,A就认为连接已建立,因为对于A,他的消息【有去有回,请求响应】。A会给B发送应答的应答,而B也在等这个消息,才能确认连接建立了,只有等到这消息,对于B,才算它的消息【有去有回,请求响应】。
当然A发给B的应答的应答也可能:
- 丢了
- 绕路
- B挂了
看起来应该还有个应答的应答的应答,但这样下去就没底。所以四次握手可,四十次都可,关键四百次你也不能保证就真可靠。所以只要保证:双方的消息都有去有回即可。
大部分情况下,AB建立连接后,A会马上发数据,一旦A发数据,则很多问题都得到解决。 如A发给B的应答丢了,当A后续发送的数据到达时,B可认为该连接已建立,或B就是挂了,A发送的数据,会报错,说明B不可达,A就知道B有异常。
当然你可以说A比较坏,就不发数据,建立连接后一直空着。可开启keepalive机制,即使没有真实数据包,也有探活包。作为服务端B的开发人员,对于A这种长时间不发包的客户端,可主动关闭,从而空出资源响应其它客户端。
三次握手还为了解决:
2.2 TCP包的序号问题
A要告诉B,我这面发起的包的序号起始号,B也要告诉A,B发起的包的序号起始号。
为啥序号不都从1开始?
会出现冲突。如A连上B后,发1、2、3三包。发3时,中间丢了或绕路了,于是重发。
后来A掉线了,重连上B后,序号又从1开始,然后发送2,但没想过发送3,但上次绕路的那个3又回来了,发给了B,B自然认为,这就是下一个包,发生错误!
所以每个连接要有不同序号。序号的起始序号随时间变化,可看成一个32位计数器,每4ms加一。稍稍计算,若重复,需4h+,那个绕路的包也早就没了,因为IP包头里有个TTL。
最后双方终于成功建立连接。为维护该连接,双方都要维护一个状态机。
2.3 连接建立过程中的双方状态变化时序图
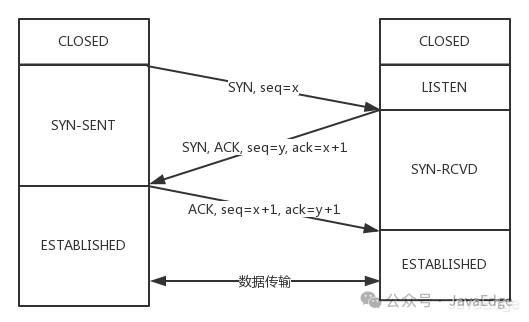
0102da048a9eefe08e47086042af141d.png
0102da048a9eefe08e47086042af141d.png
- 起初,客户端(Client)、服务端(Server)处CLOSED态
- Server主动监听某端口,处LISTEN态
- 然后Client主动发起连接SYN,之后处于SYN-SENT状态
- Server收到发起的连接,返回SYN,并ACK客户端的SYN,之后处于SYN-RCVD态
- Client收到Server发送的SYN和ACK后,发送ACK的ACK,之后处ESTABLISHED态,因为它一发一收成功了
- 服务端收到ACK的ACK后,处于ESTABLISHED状态,因为它也一发一收
★ TCP协议中,**监听某端口(Listen on a port)**是指服务器端准备接收来自客户端的连接请求。更具体地说,服务器会在某个特定的端口上开启一个监听进程,等待客户端发起的连接。 详解
- 端口:
- 端口号是计算机网络中用来标识网络进程或服务的逻辑编号。
- 每个网络服务(例如HTTP、FTP、SSH)都在特定的端口号上运行,比如HTTP服务通常运行在80端口,HTTPS服务运行在443端口。
监听:
- 当服务端程序希望接受客户端的连接时,它会对某个端口执行“监听”操作。这意味着服务端在这个端口上“等待”客户端的连接请求。
- 监听的含义就是服务端程序告知操作系统,它准备好在这个特定的端口上接收新的网络连接。
如何监听:
- 服务器通常会调用系统的
listen()函数来使自己进入监听状态。当服务端处于LISTEN状态时,它会接收进入该端口的连接请求,并且在收到来自客户端的SYN(连接请求)时响应。
例子 假设有一个Web服务器,它运行在80号端口并开始监听:
- 服务器调用
listen()函数,告诉操作系统它准备在80号端口接收客户端的连接。 - 当客户端发起请求,例如通过浏览器访问一个网页时,客户端会向服务器的IP地址和80号端口发送一个SYN包(连接请求)。
- 服务器收到请求后,确认连接请求并与客户端建立连接。
总结 监听某端口就是服务器在某个端口上开启服务,等待客户端的连接请求。当服务端进入LISTEN状态时,它已经准备好处理任何发往该端口的连接请求。 ”
3 四次挥手
好说好散,四次挥手。
- A:B啊,我不想玩了
- B:哦,你不想玩了啊,我知道了
这时,还只是A不想玩了,即A不会再发数据,但B能在ACK时直接关闭吗?
当然不可以,很可能A发完最后的数据就准备不玩,但B还没做完自己的事,还是可发送数据,所以称半关闭状态。这时A可选择:
- 不再接收数据
- 或最后再接收一段数据,等待B也主动关闭
B:A啊,好吧,我也不玩了,拜拜 A:好的,拜拜
这样整个连接就关闭了。这才是和平分手。
A开始说“不玩了”,B说“知道了”,这没问题,因为此前,双方还处合作态。
若A说“不玩了”,没收到回复,则A会重发“不玩了”。但这回合结束后,可能出现异常,因为已有一方率先撕破脸:
- A说完“不玩了”后,直接跑路,就有问题,因为B还没发起结束,而若A跑路,B就算发起结束,也得不到回答,B就不知道该咋办了
- A说完“不玩了”,B直接跑路,也有问题,因为A不知道B是还有事要处理,还是过一会儿会发送结束回来
咋办?TCP协议专门设计几个状态处理这些问题。
3.1 断开连接时的状态时序图
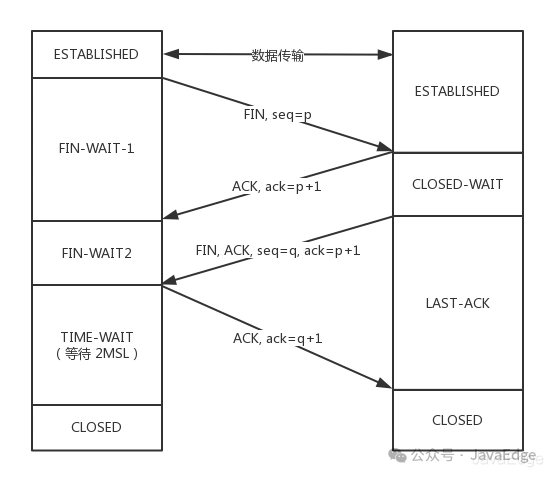
c9b536fa7427809e0a6cdf1b386ac4d2.png
c9b536fa7427809e0a6cdf1b386ac4d2.png
断开时可见:
- 当A说“不玩了”,就进入FIN_WAIT_1态
- B收到“A不玩”消息后,发送知道了,进入CLOSE_WAIT态
- A收到“B说知道了”,就进入FIN_WAIT_2态。若此时B直接跑路,则A将永远在这状态。TCP协议里并没有对这个状态的处理,但Linux有,可调整tcp_fin_timeout参数,设置一个超时时间
- 若B没跑路,发送“B也不玩了”请求到达A时
- A发送“知道B也不玩了”ACK后,从FIN_WAIT_2态结束。按理说,A现在可以跑路了,但最后这ACK万一B收不到?则B会重发一个“B不玩了”,这时若A已跑路,B就再也收不到ACK,所以TCP协议要求A最后等待一段时间TIME_WAIT,这时间要够长,长到如果B没收到ACK,“B说不玩了”会重发的,A会重新发一个ACK且足够时间到达B
A直接跑路还有个问题:A的端口就直接空出,但B不知道,B原来发过的很多包可能还在路上。此时若A的端口被一个新应用占用,新应用会收到上个连接中B发过来的包,虽然序列号是重新生成的,但这里要上一个双保险,防止混乱,因而也要等够长时间,等原来B发送的所有的包都死翘翘,再空出端口。
MSL
等待的时间设为2MSL,MSL(Maximum Segment Lifetime,报文最大生存时间),是任何报文在网络上存在的最长时间,超过这时间,报文将被丢弃。因为TCP报文基于IP协议,而IP头有个TTL域,是IP数据报可经过的最大路由数,每经过一个处理他的路由器,此值-1,值为0则数据报将被丢弃,同时发送ICMP报文通知源主机。协议规定MSL为2min,实际应用中常用30s,1min和2min等。
Q:若B超过2MSL,依然没收到它发的FIN的ACK,咋办? A:按TCP原理,B会重发FIN,这时A再收到这个包后,A就表示,我已在此等这么久,仁至义尽,之后的我也不认了,于是直接发送RST,B就知道A早已跑了。
4 TCP状态机
综合连接建立、连接断开的时序状态图,就是著名的TCP状态机。建议将状态机和时序状态机对照着便于理解:
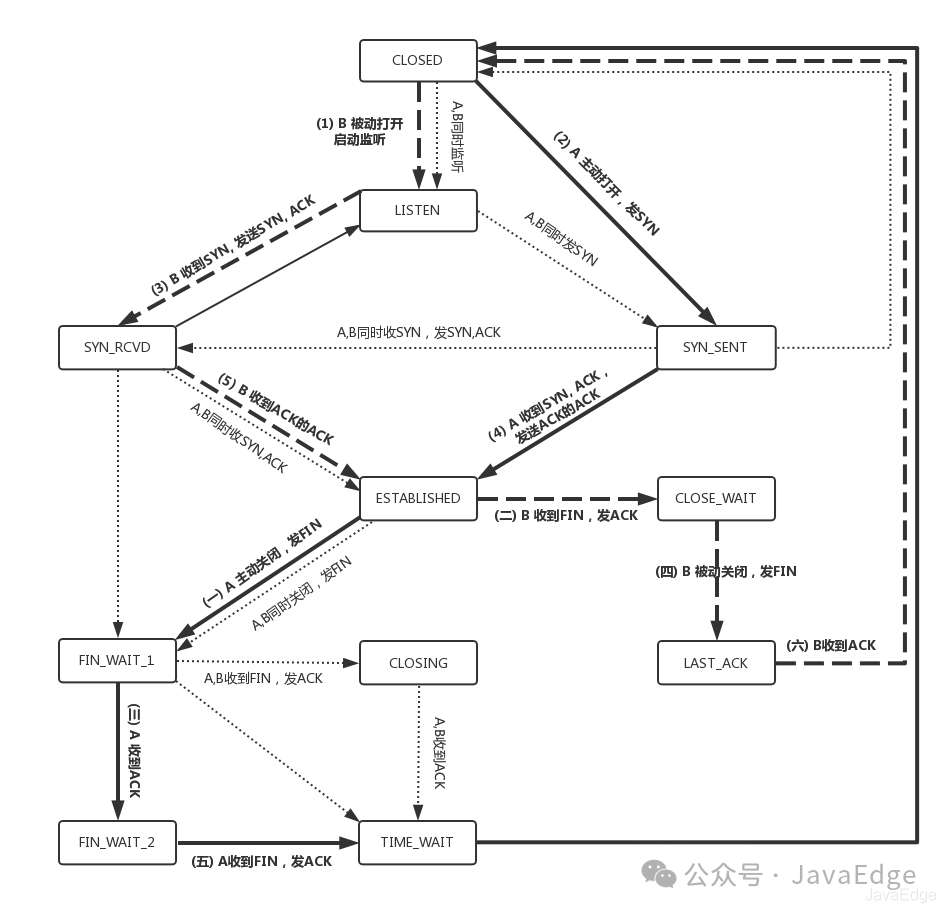
58c15d431a292a6c54cf950a569392b7.png
58c15d431a292a6c54cf950a569392b7.png
阿拉伯数字序号,是连接过程中的顺序,而大写中文数字的序号,是连接断开过程中的顺序。
- 粗实线:Client A的状态变迁
- 粗虚线:Server B的状态变迁
5 大端存储与小端
在计算机系统中,数据的存储方式对性能、兼容性以及编程有着深远的影响。
现代计算机都是以字节编址的,即每个地址下标对应一个字节,如果我们要以地址下标指代一个多字节数据(如 4 字节的 int),就需要考虑四个字节的排列顺序。大端(Big Endian)和小端(Little Endian)是两种常见的数据存储顺序,它们决定了多字节数据在内存中的排列方式。
大端和小端
大端(Big Endian)和小端(Little Endian)是指多字节数据(如32位或64位整数)在计算机内存中的存储顺序。
- 大端模式(Big Endian):在这种模式下,数据的高字节存储在低地址处,低字节存储在高地址处。例如,一个32位整数0x12345678在内存中的存储顺序是:
地址 数据
0x00 0x12 (高字节)
0x01 0x34
0x02 0x56
0x03 0x78 (低字节)- 小端模式(Little Endian):在小端模式下,数据的低字节存储在低地址处,高字节存储在高地址处。以相同的32位整数0x12345678为例,在内存中的存储顺序是:
地址 数据
0x00 0x78 (低字节)
0x01 0x56
0x02 0x34
0x03 0x12 (高字节)从以上示例可以看出,字节的排列顺序在两种模式中是完全相反的。
排列方式
在实际的计算机硬件架构中,处理器通过指定的内存地址访问数据。由于大端和小端存储顺序的不同,处理器在执行指令时需要根据内存中数据的存储顺序来进行适当的读取或写入操作。
考虑以下C语言代码,演示如何将一个32位整数存储到内存中:
#include <stdio.h> int main()
{
int num = 0x12345678;
unsigned char *byte_ptr = (unsigned char *)#
for (int i = 0; i < sizeof(num); i++)
{
printf("Byte %d: 0x%02x\n", i, byte_ptr[i]);
}
return 0;
}在大端模式下,程序将输出:
Byte0:0x12 Byte1:0x34 Byte2:0x56 Byte3:0x78而在小端模式下,程序将输出:
Byte0:0x78 Byte1:0x56 Byte2:0x34 Byte3:0x12可以看出,地址按字节编址,一个地址�p若指示某字节,当然指的是字节本身;若指代一个 int,则指代该 int 的 p,p+1,p+2,p+3,四个字节,大端用 �p 存储最高位,小端则反过来。当然每个字节内还是按顺序存储的。我们还可以看出,在大端模式下,符号位(最高位)存储在最低地址(最先被读取的字节)上,是第一个字节的最高位,这样只需要访问最低地址的字节(即高位字节)就可以立刻判断符号。而小端共容易截断,因为低位字节存储在低地址,所以当你需要对多字节数据进行截断(比如丢弃高位),你可以直接访问低地址的字节。
大端小端仅对数据有效,取指令时若从�p取值,完整的指令一定是从低到高,但指令中的多字节操作数仍遵循大端小端规律。
实际编程中的影响
对于大部分程序员而言,大端和小端的概念通常不会直接影响日常的开发工作,尤其是在现代编程语言中,编译器和操作系统往往会抽象掉这一层细节。然而,在一些低级编程(如操作系统开发、嵌入式开发、网络协议栈开发等)中,了解并正确处理字节顺序变得至关重要。
- 在跨平台的应用程序开发中,尤其是当涉及到二进制数据存储和传输时,确保数据的字节顺序一致是至关重要的。常见的做法是使用网络字节顺序(通常是大端顺序)来进行数据交换。例如,TCP/IP协议中的数据传输就是以大端顺序进行的。因此,在网络编程中,经常需要使用诸如
htonl()、ntohl()这样的函数来进行字节序的转换。 - 许多文件格式(如图像文件、音频文件等)可能规定了字节顺序。在这种情况下,读取文件时需要正确解释数据的字节序列,否则将导致数据的误解读。
- 在现代处理器上,大端和小端的性能差异通常微乎其微。但在一些嵌入式系统中,硬件支持某种字节顺序可能会影响数据访问的效率。例如,某些处理器在读取内存时,可能更倾向于优化小端顺序的访问。
历史沿革
字节顺序的选择,最初源自计算机硬件设计的不同。不同的处理器设计对字节顺序有不同的偏好。例如,早期的IBM大型机采用了大端模式,而X86架构的个人计算机则使用了小端模式。
最初,字节顺序的选择并没有严格的标准。随着不同架构的出现,不同的硬件平台采用了各自不同的字节序约定。这种差异影响了软件的移植性,尤其是在需要对不同平台进行数据交换时。
为什么个人PC总是小端?
在你的笔记本电脑上测试上述代码,结果一定是小端,这是因为个人计算机(PC)大多数使用x86架构,而x86处理器都是小端架构。这一选择的历史原因与硬件设计紧密相关。x86架构最早由Intel设计,Intel选择了小端模式。小端的选择在当时是为了简化硬件设计,尤其是在处理器对数据访问的优化方面,小端顺序可以更高效地处理低地址部分的字节。
随着x86架构的普及,个人PC几乎都采用了小端模式,成为了行业的标准。虽然现代计算机处理器(如AMD64、ARM等)支持多种字节顺序,但由于向下兼容的原因,个人PC仍然保留了小端顺序。
哪些机器使用大端和小端?
- 大端:早期的PowerPC、SPARC、MIPS等架构采用了大端模式。许多嵌入式系统和网络设备(如路由器、交换机等)也使用大端模式,特别是在需要与其他大端系统(如网络协议、某些数据库格式)进行数据交换时。
- 小端:Intel的x86和x86-64架构(也就是个人PC的主流架构)使用小端模式。此外,许多现代的ARM处理器也支持小端模式。
有些处理器(如某些ARM架构)甚至可以在运行时切换大端和小端模式,这种灵活性有助于它们适应不同的应用场景。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号