手撕Python之正则


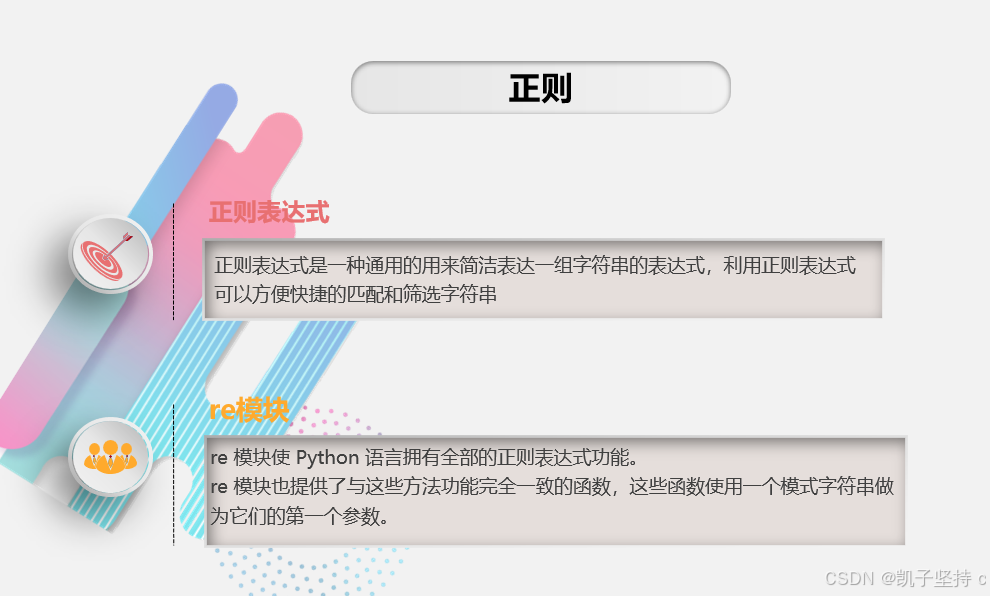
正则表达式是一种通用的用来简洁表达一组字符串的表达式,利用正则表达式可以方便快捷的匹配和筛选字符串
举个例子:在一堆数据中进行电话号码的寻找,我们需要根据电话号码的特征在这一堆数据进行电话的寻找,电话是11位数的,全是数字,基于特征进行寻找
正则的一些方法都是放在re模块的
re 模块使 Python 语言拥有全部的正则表达式功能。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
所以我们如果想使用正则表达式的话,我们是先进行将正则表达式导入re的操作
正则在爬虫里面很常见的,在大量的字符串里面进行数据的寻找
对于正则表达式来说,我们需要描述我们的需求,我们怎么写
对什么样的数字进行一系列的操作
比如说我们需要进行电话号码的匹配
11位,并且是数字
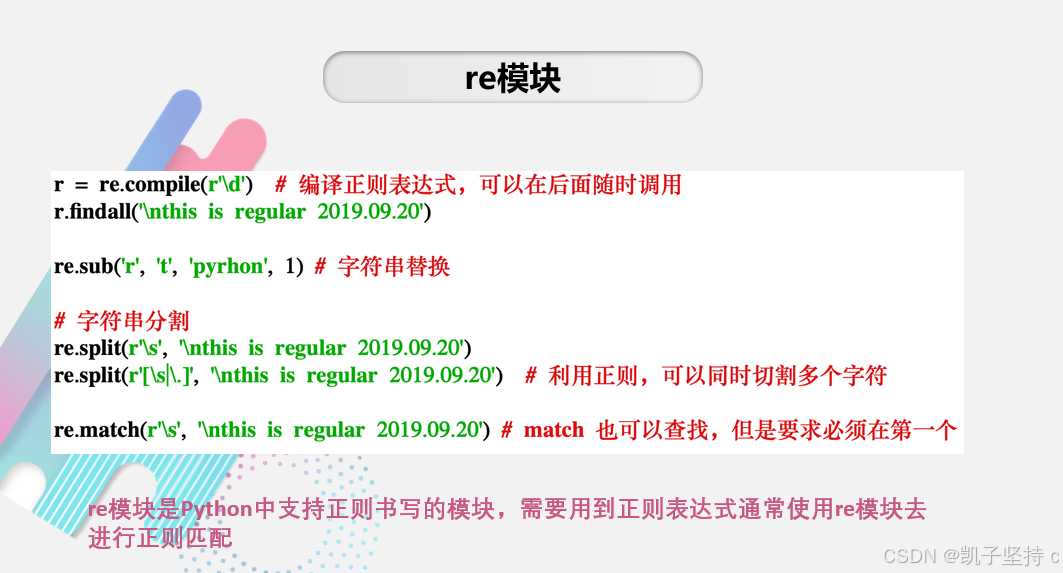
'\d{11}'
'1[3-9]\d{9}'----第一个数字只能是1,第二个数字是3-9之间的,后面的就是\d了,然后总长度限制为9
2.re模块的一些方法
re.match--从字符串开头进行匹配---匹配一次
re.match()必须从字符串开头匹配,match方法尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。

只会匹配一次数据
从字符串开头进行匹配
如果匹配失败的话那么就返回None
如果成功的话就会返回匹配的范围区间
必须从头进行匹配,不然是不成功的
从第一个字符一一开始进行比对
import re
r=re.match('test','testabcdfgsdtest')
print(r)
#<re.Match object; span=(0, 4), match='test'>
r=re.match('test','Testabcdfgsdtest')
print(r)
#None通过group将匹配的数据拿出来
#如果我们想将匹配的内容拿出来的话,我们可以使用下面的方法
import re
r=re.match('test','testabcdfgsdtest')
print(r)
print(r.group())
#test获取到匹配数据的位置
通过span获取匹配到的数据的下标位置
import re
r=re.match('test','testabcdfgsdtest')
print(r)
print(r.span())
#(0, 4)这里的(0,4)是一个左闭右开的内容
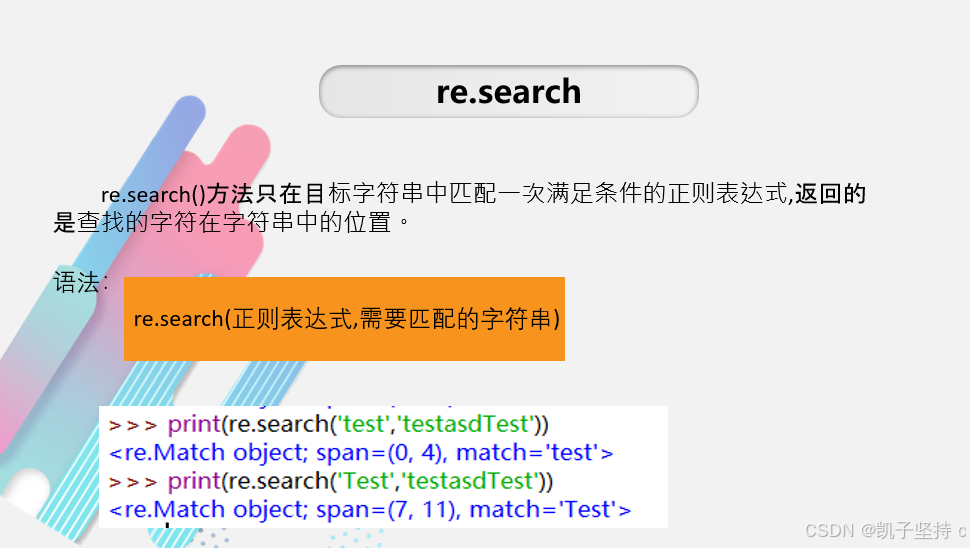
re.search---在字符串任意位置都能进行查找---匹配一次
re.search()方法只在目标字符串中匹配一次满足条件的正则表达式,返回的是查找的字符在字符串中的位置。
从字符串中进行内容的匹配,不管在那个位置,都可以进行目标的寻找
只会匹配一次数据(就是字符串里面第一个满足条件的一串字符)
import re
r=re.search('test','tdestabcdfgsdtest')
print(r)
print(r.group())
print(r.span())
#<re.Match object; span=(13, 17), match='test'>
r=re.search('test','Testatfsegsdtest')
print(r)
print(r.group())
print(r.span())
#<re.Match object; span=(12, 16), match='test'>re.findall--找打字符串中所有匹配的内容---匹配多次
从字符串中匹配内容,进行多次匹配,有多少次满足项,就匹配多少个
#<re.Match object; span=(12, 16), match='test'>
r=re.findall('test','tdestabtestcdfgsdtest')
print(r)
#['test', 'test']返回的结果是以列表的形式进行存储的

3.匹配单个字符
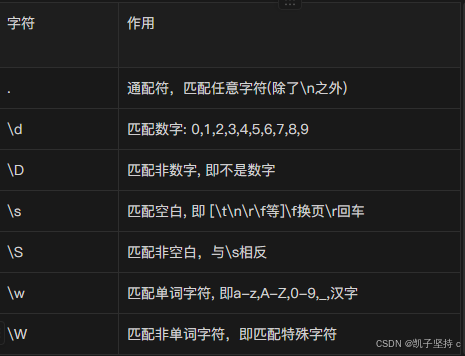
\w 匹配单词字符,如字母、数字、下划线、汉字
.的匹配操作
import re
#.匹配任意字符,除了\n
print(re.findall('.','test\tand\n'))
#['t', 'e', 's', 't', '\t', 'a', 'n', 'd']
#可以将整个字符串进行一个拆分,将每个元素进行一个获取放到列表中存放可以将整个字符串进行一个拆分,将每个元素进行一个获取放到列表中存放
除了\n都能进行匹配的操作

r=re.match('aaa.','aaa1212bbb')
print(r.group())
#aaa1
'''
正则表达式'aaa.'将会匹配字符串'aaa1212bbb'中的'aaa'
后面紧跟着的第一个字符,也就是数字'1'。因此,r.group()将会输出'aaa1'。
'''\d的匹配操作
将字符串中的数字提取出来
import re
print(re.findall('\d','abd6c123'))
#['6', '1', '2', '3']\D的匹配操作
将字符串中的非数字匹配提取出来
import re
print(re.findall('\D','abd6c123'))
#['a', 'b', 'd', 'c']\s的匹配操作
匹配空白字符
import re
print(re.findall('\s','ted \t anfdsa sd '))
#[' ', '\t', ' ', ' ', ' ']\S的匹配操作
匹配非空白字符
import re
print(re.findall('\S','ted \t anfdsa sd '))
#['t', 'e', 'd', 'a', 'n', 'f', 'd', 's', 'a', 's', 'd']只要不是空白都能提取出来
\w的匹配操作
标点符号啥的都不进行匹配操作
匹配单词字符,如字母数字下划线等
import re
print(re.findall('\w','hi,小明!'))
#['h', 'i', '小', '明']\W的匹配操作
作用与\w相反的
import re
print(re.findall('\W','hi,小明!'))
#['h', 'i', '小', '明']
#[',', '!'][ ] 匹配[ ]列举的任意字符
我们上面的方法里面没有单独将字母进行分离出来的字符
import re
print(re.findall('[a-z]','hi,小明!123'))
#['h', 'i']括号里面是字母的范围,只要字符串里面有满足这个条件的都会进行剥离出来的
只会匹配括号内列举出来的,一次匹配一个
import re
print(re.findall('[a-z,A-Z]','hi,小明DFS!123'))
#['h', 'i', ',', 'D', 'F', 'S']在这个例子中,我们在括号内列举了a-z和A-Z,然后中间有个逗号
都算进了寻找的范围
那么如果我们想单单寻找小写和大写的字母的话,这么写
import re
print(re.findall('[a-zA-Z]','hi,小明DFS!123'))
#['h', 'i', 'D', 'F', 'S']这么写就没有其他多余的元素了
我们想寻找什么东西就把这个写在[ ]内就行了
匹配数字
import re
print(re.findall('[0-9]','hi,小明DFS!123'))
#['1', '2', '3']在括号内输入寻找数字的范围就行了
匹配数字,但不包含4
import re
print(re.findall('[0-35-9]','hi,小明DFS!124653'))
#['1', '2', '6', '5', '3']输入范围0-3 5-9
4.匹配多个字符
匹配多个字符是基于单个字符的
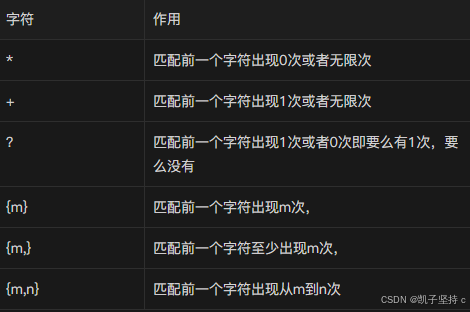

*的匹配使用
import re
print(re.findall('\S*','hi,my name is xiaoming'))
#['hi,my', '', 'name', '', 'is', '', 'xiaoming', '']*允许匹配0次,返回一个空白字符,所以会算上这个空格的
+的匹配使用
import re
print(re.findall('\S+','hi,my name is xiaoming'))
#['hi,my', 'name', 'is', 'xiaoming']至少匹配1次,所以我们是不会算上空格的
所以说在空格之前都算上匹配中的
*和+的比较
通过比较我们能发现这个用*的话多了很多的空格
因为*允许匹配0次,返回一个空白字符
设置匹配的长度---{m }--匹配长度为m
import re
print(re.findall('\d{3}','1233456'))
#['123', '345']我们使用{}进行长度的限制,长度至少是3才能进行匹配的操作
至少匹配次数---{m, }
import re
print(re.findall('\S{4,}','hi,my name is xiaoming'))
#['hi,my', 'name', 'xiaoming']这里我们至少匹配4次才会算数的
这里的is就没有算进去,因为长度是不够的,不满足
匹配{m,n}次
至少匹配m次,最多匹配n次
import re
print(re.findall('\S{2,4}','hi,my name is xiaoming'))
#['hi,m', 'name', 'is', 'xiao', 'ming']至少两次,最多4次
在这里我们没有进行y的输出,因为不满足条件了,而且后面有个空格,然后就进行下一组的匹配了
5.贪婪和非贪婪
贪婪:满足匹配的情况下,尽可能匹配多的数据
非贪婪:满足匹配的情况下,尽可能匹配少的数据

默认是贪婪模式
import re
print(re.findall('\S{2,4}','hi,my name is xiaoming'))
#['hi,m', 'name', 'is', 'xiao', 'ming']这拿xiaoming 来举例子
我们xiao里面拿两个(xi)也能进行匹配,四个(xiao)也能进行匹配
但是我们这里选择了4个
所以我们这里是贪婪的
贪婪模如何修改为非贪婪模式呢?在匹配多个的后面加上问号?
import re
print(re.findall('\S{2,4}?','hi,my name is xiaoming'))
#['hi', ',m', 'na', 'me', 'is', 'xi', 'ao', 'mi', 'ng']这种就是非贪婪的,满足条件的情况下尽量匹配少的数据
最上面的那种一次匹配4次,尽可能匹配多的数据,这个就是贪婪的情况
r=re.match('aaa.','aaa1212bbb')
print(r.group())
#aaa1
'''
正则表达式'aaa.'将会匹配字符串'aaa1212bbb'中的'aaa'
后面紧跟着的第一个字符,也就是数字'1'。因此,r.group()将会输出'aaa1'。
'''
#贪婪
r=re.match('aaa.+','aaa1212bbb')
print(r.group())
#aaa1212bbb
#非贪婪
r=re.match('aaa.+?','aaa1212bbb')
print(r.group())
#aaa1
#至少匹配1次并且是非贪婪的,那么尽可能少,正则表达式'aaa.'将会匹配字符串'aaa1212bbb'中的'aaa'
后面紧跟着的第一个字符,也就是数字'1'。因此,r.group()将会输出'aaa1'。
aaa.+至少匹配一次
但是后面加个?的话那么就只会匹配一次了,
因为是非贪婪了
6.匹配开头(^)和匹配结尾($)的设置
^可以进行开头字符的设置
import re
#以t开头
print(re.findall('^t\w+','testabctest'))
#['testabctest']
'''
^t----设置以t开头
\w匹配字母数字下划线
+至少匹配一次
'''
import re
#以t开头
print(re.findall('^t\w+','Testabctest'))
#[]如果字符串中的开头不是T的话,返回的就是个空列表了
$ 设置匹配的结尾字符
import re
#以t结尾
print(re.findall('^t\w+t$','testabctest'))
#['testabctest']
import re
#以T结尾
print(re.findall('^t\w+T$','testabctest'))
#[]此时我们设置了开头和结尾,那么我们在+后面添加一个问号看看
import re
#以T结尾
print(re.findall('^t\w+?t$','testabctest'))
#['testabctest']
#我们设置好了第一个和最后一个
#结尾字符指的就是字符串的最后面一个字符
#我们必须将中间的匹配完我们才能拿到
#我们加上?的话就没啥用,就不存在贪婪和非贪婪的说法了我们已经将字符串的开头和结尾设置好了,不存在什么贪婪和非贪婪的说法了,中间的必须进行匹配的操作
7. ^[]和[]的区别
^[ ]:匹配 [ ] 中列举的字符开头
[^ ]:匹配的不是 [ ]中列举的内容,就是取反操作,就是里面的我们不匹配,不是里面的我们都匹配
^[]的使用方法:
import re
#匹配[]内列举的内容
print(re.findall('^[Tt]\w+','Testabctest'))
#['Testabctest'][^]的使用方法:不取括号内的元素吗,其他的都会进行匹配操作
import re
#不匹配[]内列举的内容
print(re.findall('[^Tt]','Testabctest'))
#['e', 's', 'a', 'b', 'c', 'e', 's']
8.()分组匹配
进行括号的匹配
r=re.match( '<.+>(.*)<.+>','<h1>python<\h1>')
print(r.group())
#<h1>python<\h1>
#获取到标签中间的句子
print(r.groups())
#('python',)
#以元组的形式进行存储
#尖括号对尖括号,那么这个圆括号就和python进行匹配上了使用.*的话会将整个字符串进行匹配操作的
如果findall中使用了(),返回的内容只有()中匹配的数据的,以列表形式返回的
print(re.findall('<.+>(.*)<.+>','<h1>python<\h1>'))
#['python']
9.re模块的其他方法
compile---将正则表达式对象化
compile(正则表达式)---将正则表达式转换为对象,用于多次调用的正则表达式
c=re.compile('<.+>(.*)<.+>')
print(c)
#re.compile('<.+>(.*)<.+>')
#通过对象进行方法的调用操作,那么就是省略掉了前面的正则表达式,写后面的字符串就行了
print(c.match('<h1>python<\h1>').groups())
#('python',)
print(c.search('<h1>python<\h1>').groups())
#('python',)
print(c.findall('<h1>python<\h1>'))
#['python']
#我们后面都没写正则表达式了,因为我们在前面就将正则表达式转换为对象了
#通过对象进行方法的调用,会将对象信息给到方法的我们后面都没写正则表达式了,因为我们在前面就将正则表达式转换为对象了
我们后面直接用对象进行方法的调用就行了
使用compile将正则表达式转换为对象,使后面的代码更加简洁了
sub()---进行大量数据中数据的替换方法
replace--进行字符串中指定元素的替换操作
s='hello 111word 222'
#现在我们想将连续的三个数字替换为666
s=s.replace('111','666')
print(s)
#hello 666word 222
s=s.replace('222','666')
print(s)
#hello 666word 666
#如果我们还存在其他的数字的话我们还需要进行替换的操作
#这样就会很麻烦的对于数据小的我们还可以使用字符串中的replace进行替换操作
但是如果是数据比较大的我们就不是很方便进行数据的替换操作了
sub(正则表达式,新数据,修改的字符串,替换次数)
通过正则表达式对字符串进行批量的替换
如果我们后面设置了数字的话,那么就根据我们设置的数字进行替换的次数
s1='hello 111word 222'
#我们需要将连续的三个字符进行替换了
s2=re.sub('\d{3}','666',s1)
print(s2)
#hello 666word 666
#第一个参数就是替换的字符串的特点
#第二个参数是替换的新数据
#第三个是需要进行替换的字符串将字符串中满足特点的条件的字符进行替换操作
split--通过正则进行拆分的操作
split(正则表达式,要拆分的字符串,拆分的次数)
s='huahua1xiaoming2lisi3lala'
#拆分出名字
l=re.split('\d',s)
print(l)
#['huahua', 'xiaoming', 'lisi', 'lala']将字符串中满足条件的数字进行拆分了,以数字进行拆分符号进行拆分
第一个参数是拆分符号的特点,第二个参数是要拆分的字符串
上面是第一种拆分的方法,我们还有第二种方法进行拆分
l=re.split('[123]',s)
print(l)
#['huahua', 'xiaoming', 'lisi', 'lala']直接将拆分的数字列举在括号内,然后进行拆分的操作
还可以这么写:
l=re.split('[1-3]',s)
print(l)
#['huahua', 'xiaoming', 'lisi', 'lala']10.匹配边界--单词边界

print(re.match('ve\b','ve2test'))
#None在Python中,re.match 函数是用来检查字符串是否从开始就符合给定的正则表达式模式。这里的正则表达式模式是 've\b'。
让我们分解一下这个正则表达式:
-
ve:这部分表示匹配文本中的 "ve" 这两个字符。 -
\b:这是一个正则表达式的边界匹配符,它匹配一个单词的边界,即它前后不能是字母、数字或下划线。
所以,re.match('ve\b', 've2test') 这个调用会检查字符串 "ve2test" 是否从开始就符合 "ve" 后面紧跟一个单词边界的模式。
在这个例子中,"ve2test" 以 "ve" 开头,但 "ve" 后面紧跟着的是数字 "2",而不是一个单词边界。因此,re.match 会返回 None,表示没有匹配成功。
如果你想匹配 "ve" 后面是单词边界的情况,你可以使用如下的正则表达式:
import re
print(re.match('ve\b', 've test'))这将会输出一个匹配对象,因为 "ve" 后面是一个空格,它是一个单词边界。

正则的转义字符,以\开头
字符串的转义字符,以\开
转义字符在执行时,先执行字符串转义,再执行正则的转义
我们需要在字符串前面加上r取消字符串的转义
对于这个\b的话
ve\b
e的左边是数字字母,那么右边就不能是数字字母了
数字字母设置了\b边界,那么后面就不能是数字字母,后面必须是非数字字母的内容
那么大写的b就是相反的情况
print(re.match('ve\b','ve2test'))
#None
print(re.match(r've\b','ve!2test'))
#<re.Match object; span=(0, 2), match='ve'>
print(re.match('ve\B','ve2test'))
#<re.Match object; span=(0, 2), match='ve'>
print(re.match('ve\B','ve!2test'))
#Noneb在正则里面是边界,但是在字符串里面是退格符

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号