项目四 pig预处理北京公交线路
原创
项目四 pig预处理北京公交线路
原创
码农GT038527
发布于 2024-09-23 13:40:18
发布于 2024-09-23 13:40:18
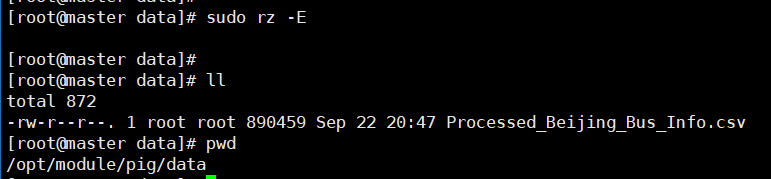
上传文件到指定目录
- 将爬虫获取到的csv文件使用
sudo rz -E命令上传至/opt/module/pig/data目录
将文件上传至hdfs
hadoop fs -mkdir /pig
hadoop fs -chmod -R 777 /pig
hadoop fs -put /opt/module/pig/data/Processed_Beijing_Bus_Info.csv /pig
web端查看是否上传成功
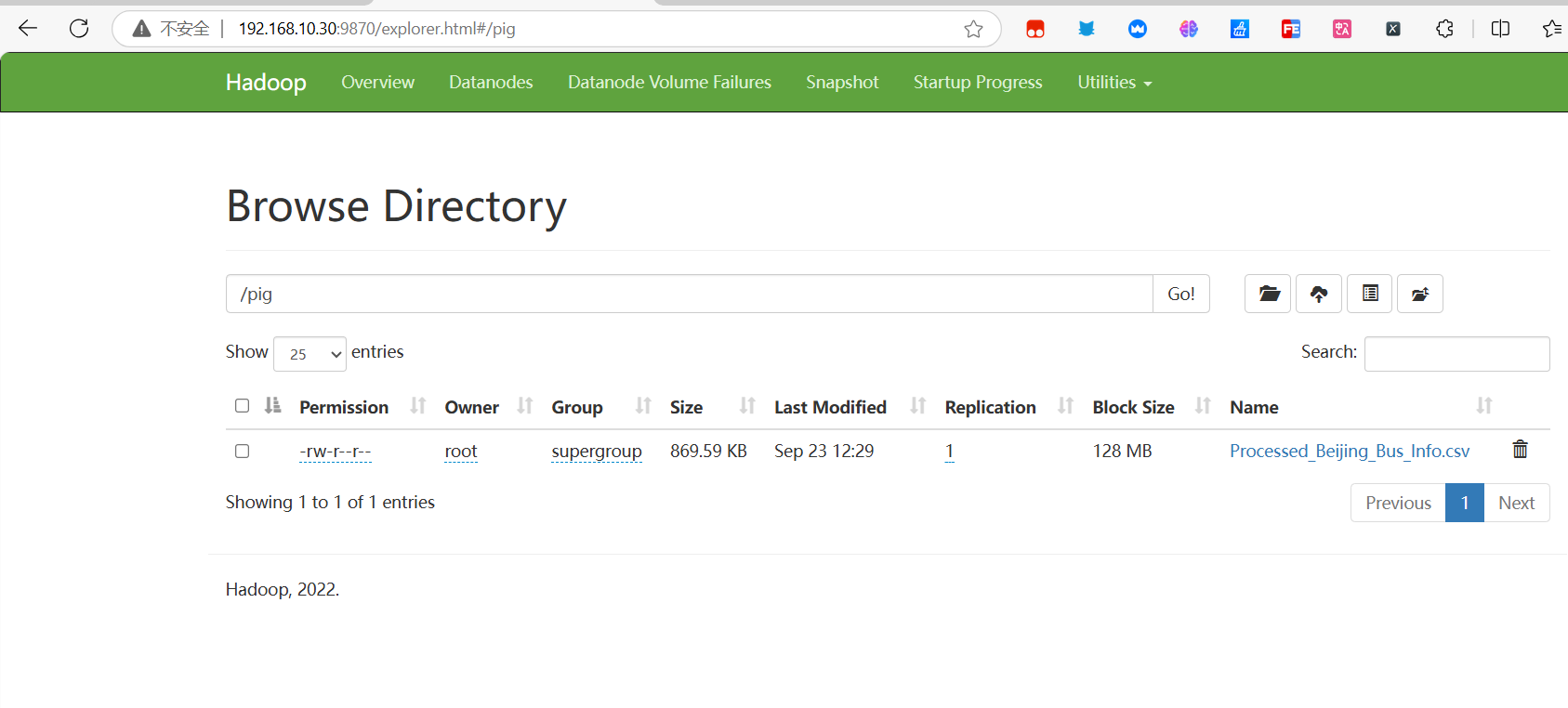
- 或直接使用
hadoop fs -ls /pig命令查看

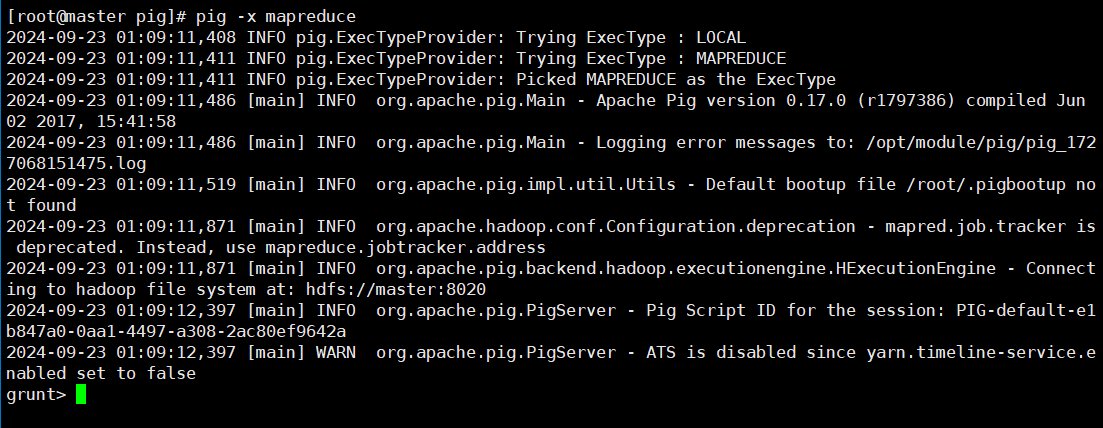
在pig中预处理数据
- 启动
pig -x mapreduce
- 数据预处理
# 注册 piggybank.jar 库,以便使用其自定义函数
REGISTER '/opt/module/pig/lib/piggybank.jar';
# 加载北京公交信息的 CSV 文件,并指定字段及其类型
bus_info = LOAD '/pig/Processed_Beijing_Bus_Info.csv' USING PigStorage(',') AS (
bus_name:chararray,
bus_type:chararray,
bus_time:chararray,
tieck:chararray,
licheng:chararray,
gongsi:chararray,
gengxin:chararray,
wang_info:chararray,
wang_buff:chararray,
fan_info:chararray,
fan_buff:chararray
);
# 输出加载的数据以供检查
DUMP bus_info;
# 通过 DISTINCT 操作去重数据
distinct_data = DISTINCT bus_info;
# 输出去重后的数据以供检查
DUMP distinct_data;
# 过滤掉包含空值的记录
filter_data = FILTER distinct_data BY
bus_name != '' AND
bus_type != '' AND
bus_time != '' AND
tieck != '' AND
licheng != '' AND
gongsi != '' AND
gengxin != '' AND
wang_info != '' AND
wang_buff != '' AND
fan_info != '' AND
fan_buff != '';
# 输出过滤后的数据
DUMP filter_data;
# 将过滤后的数据存储到 HDFS 指定路径
# 使用 PigStorage(',') 以逗号为分隔符存储数据
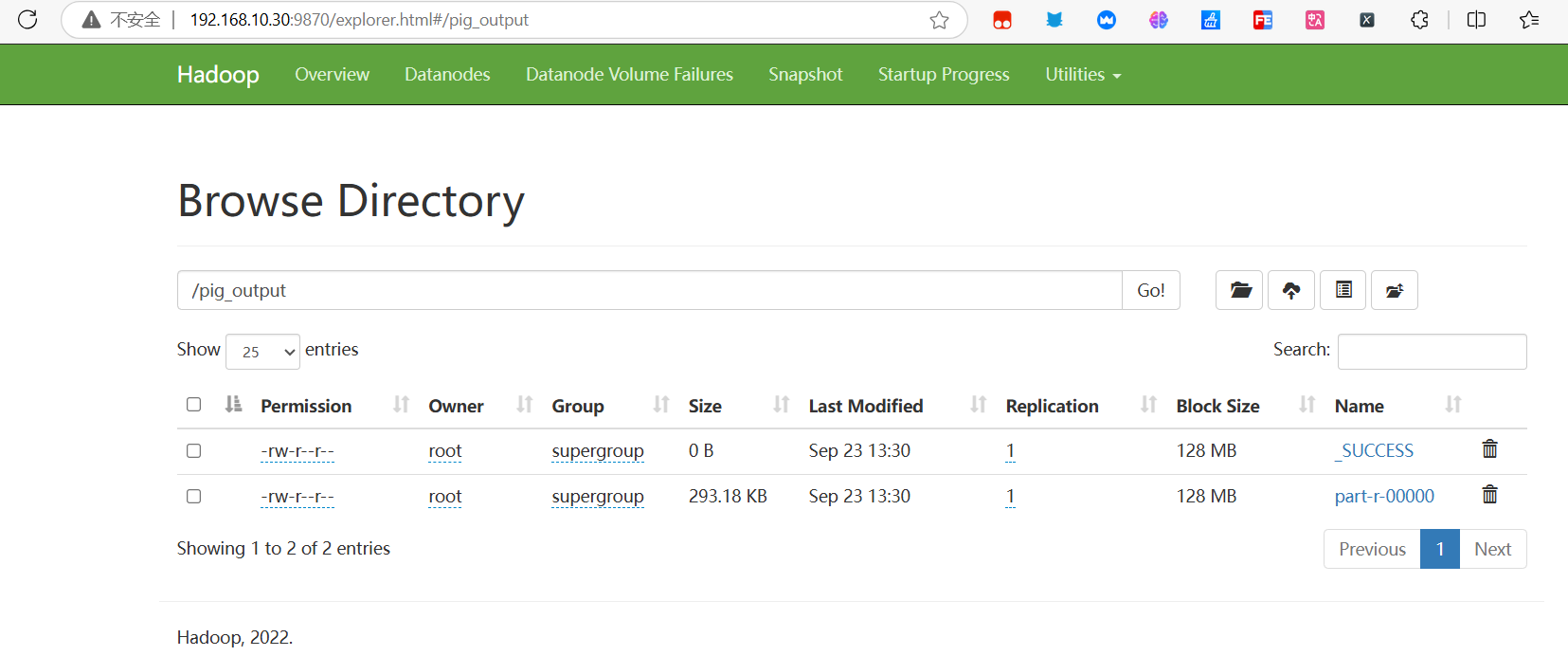
STORE filter_data INTO 'hdfs://master:8020/pig_output' USING PigStorage(',');- 最终运行成功标志
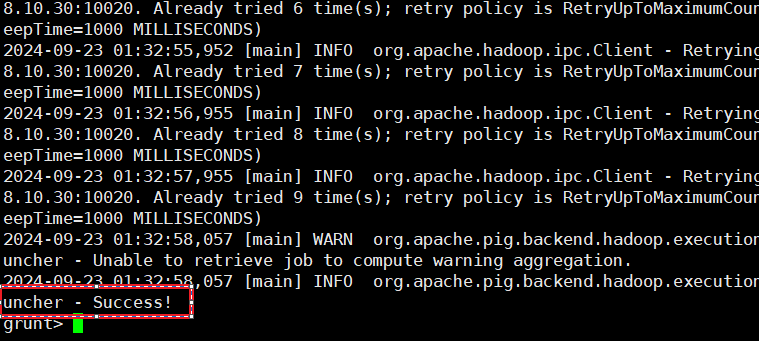
- 查看数据
hadoop fs -cat /pig_output/part-r-00000

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号