OpenAI发布的o1大模型原理初探
原创

OpenAI终于发布新的模型,这个模型被称为o1。ChatGPT官网已经可以看到有两个模型,一个是o1-preview,另一个是o1-mini。
从官方发布的模型效果来看,这个模型的推理能力简直逆天(现在还有谁敢说OpenAI已经不行了?),那么o1模型其背后的原理是怎么样的呢?这篇文章带你初步探究一下其o1模型的一些亮点。
o1模型效果惊人
首先我们来思考一下,人类在解决逻辑问题的时候,往往会有一系列的慢思考环节。比如我们会把一个比较难的题目进行拆解,得到多个小问题之后,再用自己的现有知识去解决每一个小问题,最后就可以对这个问题推理得到正确的答案。
但是在以往大模型遇到难的推理问题的时候,就没有这种思考环节,导致对于这类问题解决程度不足。
那么如何让大模型也能够像人一样具有逻辑推理能力呢?这里研究者会引入COT(思维链)的方式,让大模型去拆解问题,然后思考。所以o1模型其实本质就是这样,在给出答案的时候,会首先在内部生成思维链,把问题拆解后再解答。
而这使得o1模型在数学推理能力和其coding能力上取得的成绩令人惊讶。
- 数学能力大幅提升:在国际数学奥林匹克(IMO)资格考试中,GPT-4o只正确解决了 13% 的问题,而o1推理模型的得分为 83%。
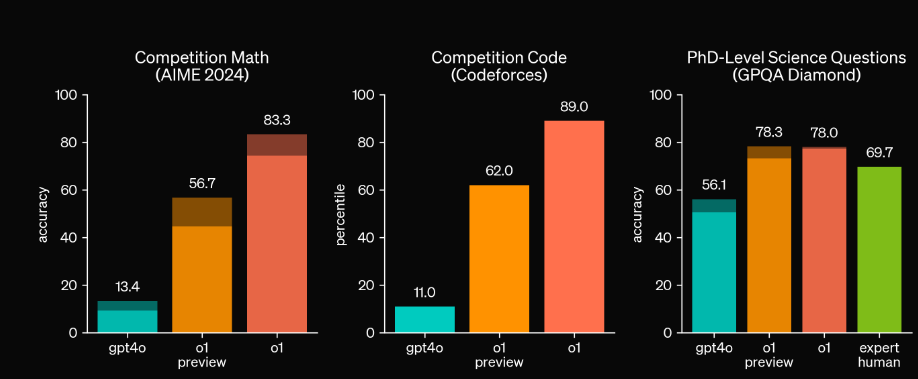
- Coding能力相比于gpt4o也有明显提升
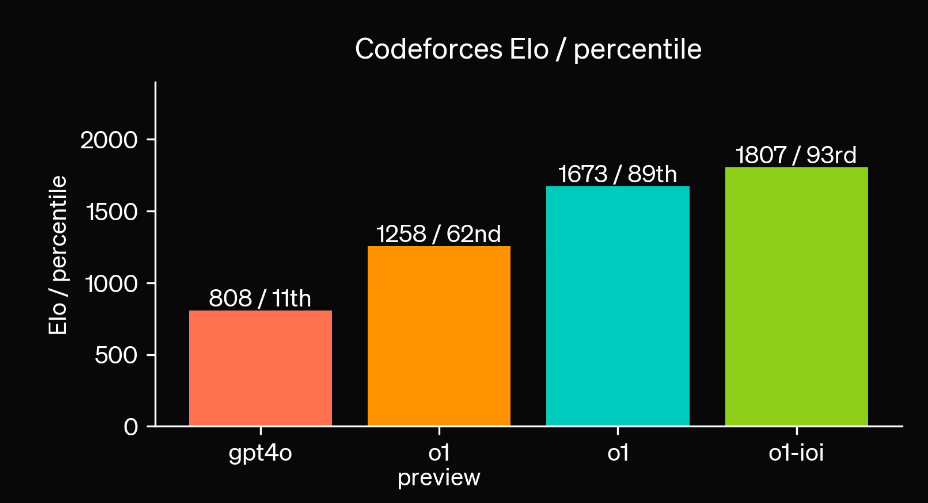
但是由于引入了模型的反思机制,整体的推理速度明显比之前的所有模型要慢得多:
对于同样一个问题,虽然 GPT-4o 没有正确回答,但 o1-mini 和 o1-preview 都正确回答,并且 o1-mini 达到答案的速度大约是 3-5 倍。
o1模型的原理是什么
- 原理1:主要来自于“自动化COT”来优化prompt输入
在以前我们可以利用COT(思维链)技术,来让模型举一反三。在大模型的应用中,COT的方法能够激发大模型预训练过程中的先验知识,更好的帮助模型理解人类输入的问题。举个例子,在下面的例子中,大模型基于问题是不能够给出正确的答案,它的效果往往会比较差

但是如果你把人类的思维方式给到大模型,那么他就会通过你给出的推导例子,正确回答出你提到的问题。
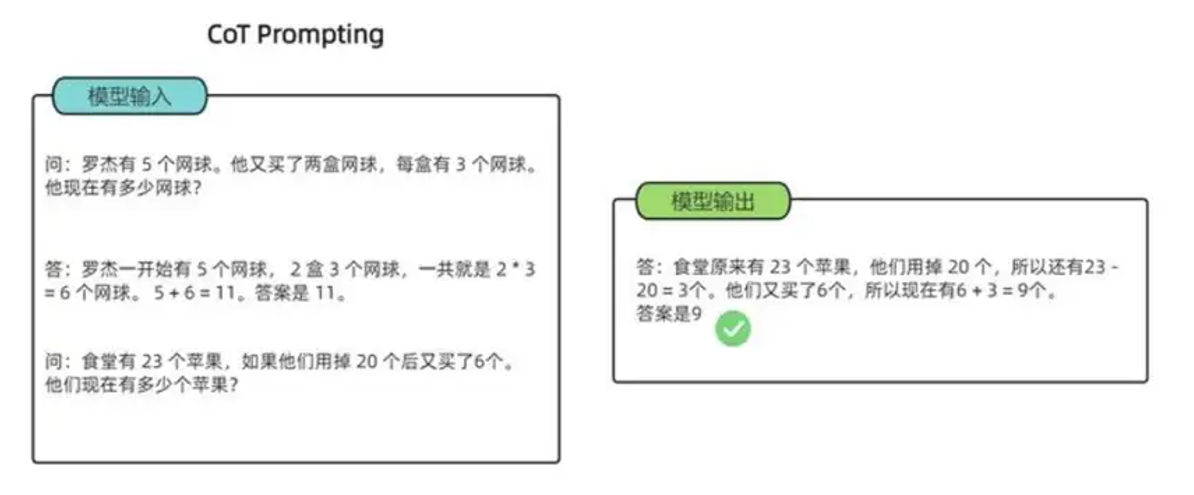
上述过程存在一个主要缺陷,即需要人工大量编写COT规则。对于一类问题尚可,但若需为每个问题编写推导逻辑,这显然不可行。因此,OpenAI借鉴AlphaGo的MCTS(蒙特卡洛树搜索)和强化学习方法,使LLM能快速找到CoT路径,而且这个过程不需要人工进行干预,模型即可自动生成。
科罗拉多大学博尔德分校计算机教授Tom Yeh制作了一个动画,展示了OpenAI是如何训练o1模型的。
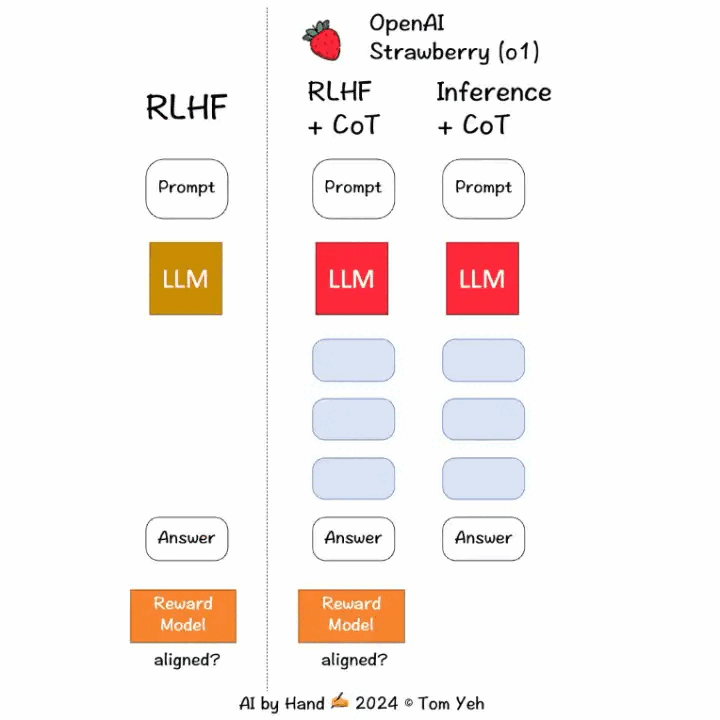
在训练阶段,不仅仅只考虑输入prompt和answer,而是利用强化学习把COT来考虑进来,更新大模型的参数。这样做的目的是让大模型能够自己学会自动生成COT逻辑思维链。
在推理阶段,则先让大模型自动化生成COT token,这样能够显著提高模型的推理能力,缺点就是这个过程往往会耗费大量的时间。
- 原理2:“过程监督”中的优化替代了“结果监督”
OpenAI在上一年5月份发布的一项技术,该技术通过“过程监督”而非“结果监督”来解决数学问题。
OpenAI通过对每个正确的推理步骤进行奖励(“过程监督”)来提高解决数学问题的水平,而不是像之前一样只是简单地奖励最终的正确答案(“结果监督”)。
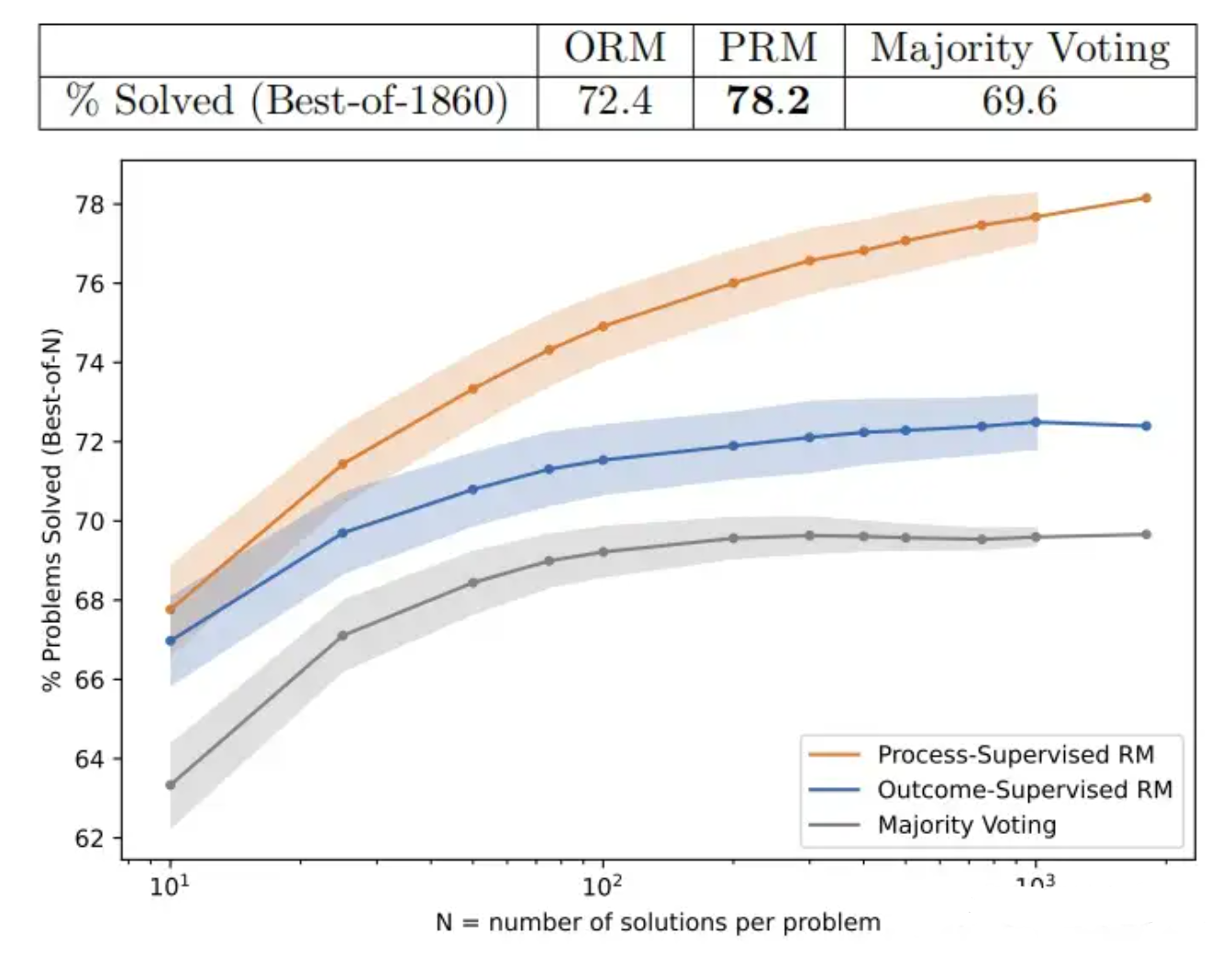
它主要是使用MATH测试集里面的问题来评估“过程监督”和“结果监督”奖励模型,并为每个问题生成了许多解答方案,然后选择每个奖励模型排名最高的解答方案。(上图展示了一个函数,即每个奖励模型选择的解答方案数量(number of samples)与选择的解答方案最终能够达到正确结果的百分比(% Problems Solved (Best-of-N))之间的关系。)
除了提高与结果监督相关的性能外,过程监督还有一个重要的对齐好处:它直接训练模型以产生人类认可的思维链。

从之前OpenAI发布的论文来看,使用过程监督有以下优点:
1.过程监督更有效,从具有挑战性的 MATH 数据集的一个子集中解决了 78% 的问题。 2.主动学习提高了流程监督的有效性,数据效率提升了2.6倍。
- 原理3:OpenAI提出的新的Post-Training Scaling Laws原理
从目前来看,可能模型在预训练阶段pre-training的scaling laws真正慢慢的失效,也就是说在预训练阶段增加训练时间和扩大模型规模,最后的收益是不大的。
而这次OpenAI则主要尝试提升后训练Post-Training和推理阶段中的算力,发现整体模型的准确率有明显的提升效果。
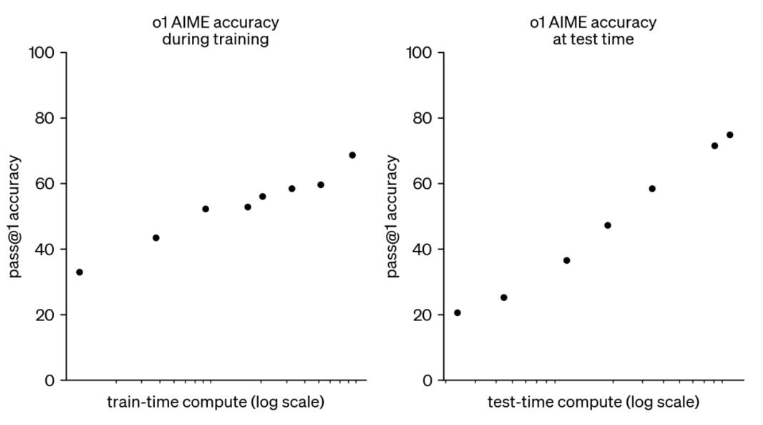
这里的OpenAI的后训练Post-Training Scaling law 与 预训练 Pre-training Scaling law 不同。它们分别在模型训练和推理过程的不同阶段。随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算), o1 的性能也在不断提升,并且目前Post-Training Scaling Laws还远没有到瓶颈。
这里总结一下三个主要的原理:
- “自动化COT”:让模型在训练阶段就可以自动学习推到思维链,不需要人工进行干预,从而把大问题进行拆解和解答,提升模型回复的准确率。
- “过程监督”:则让模型不再局限于学习结果数据,想人类一样学习每个步骤的思考过程。
- Post-Training Scaling Laws:意味着 AI 能力的提升不再局限于预训练阶段,还可以通过在 Post-Training 阶段中提升 RL 训练的探索时间和增加模型推理思考时间来实现性能提升,即 Post-Training Scaling Laws。
通过这三个步骤,最后使得o1模型的推理能力大幅上涨,并能够提升对于未见过的复杂问题的解决能力。
o1模型有自我意识了吗?
这可能是大部分人都关注的问题,一直以来,人类都想通过打造一个超级大模型来创造一个有自我意识的AI。那么这次o1模型它的推理能力有这么明显的提升,它的智力水平怎么样?
从下图可以看到,在门萨会员的离线智商测试中,o1模型拿到了第一名。
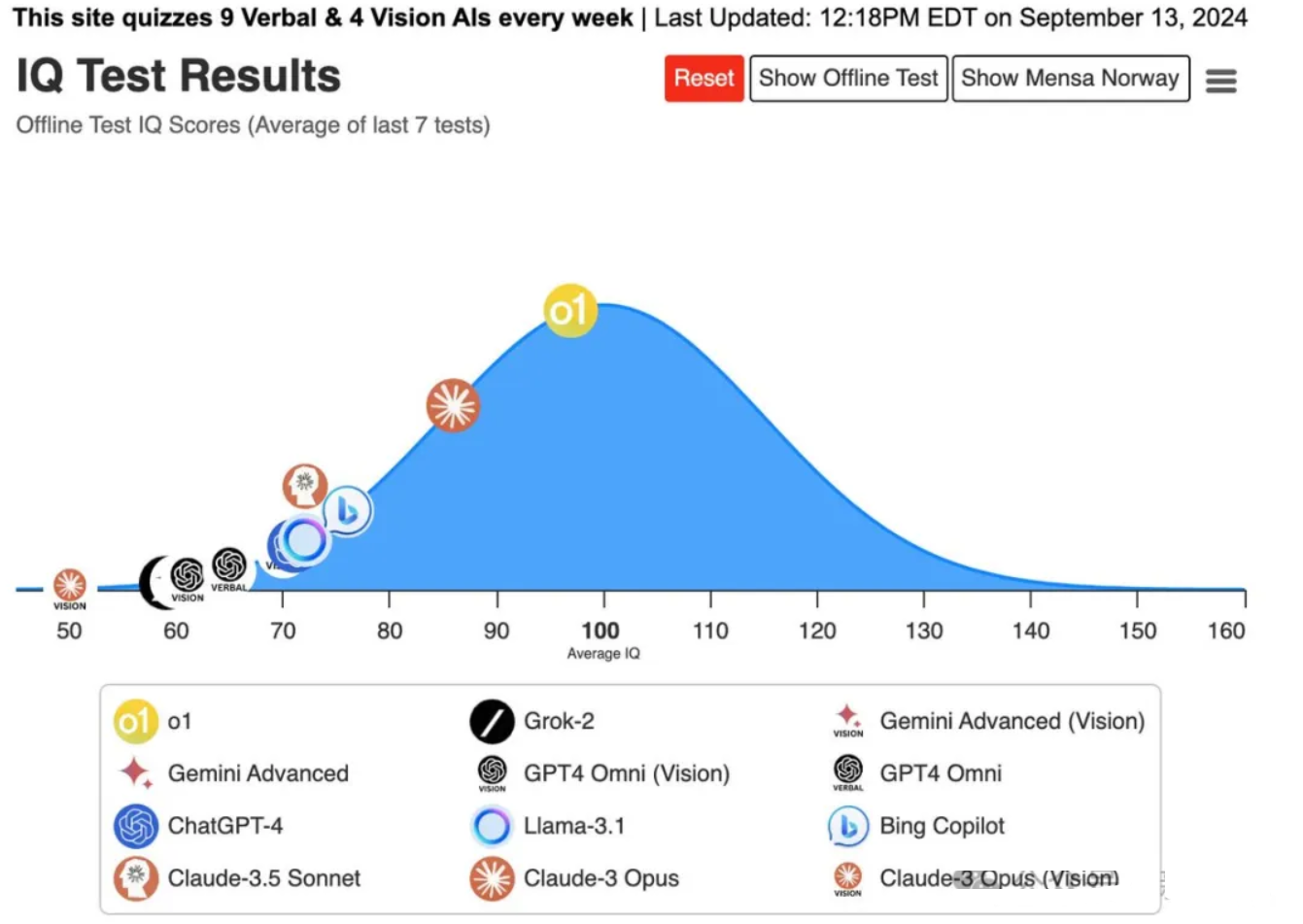
越来越多的人都相信现在的AI可能已经初步具备了人类的意识。比如,OpenAI研究副总裁Mark Chen在o1发布后表示:“现在的大模型可能已经出现了一些意识”

OpenAI目前把人工智能划分成5个等级,认为这次的o1大模型其实已经处于第二个阶段,因为它本身具备了较强的推理能力,而且是一个飞跃式的超越之前的大模型的效果。
- 第一级别是chatbots,就是现有生成式大模型处于的阶段,能够与人类进行对话解决问题
- 第二级别是推理者 Reasoners,具有一定的推理能力,能够解决人类水平的一些问题
- 第三级别是智能体Agents,表明人工智能达到了一个整体系统,在系统中自主采取行为解决问题
- 第四级别是创新者 Innovators。不依赖于人工,而是自身有创新思维
- 第五级别是组织 Organizations,这已经达到或者超越人类水平,能够提升工作中的效率。

对o1模型的一些实测案例
coding测试
coding能力测试,这里拿了leetcode中“第4151场周赛”题目进行测试,选择了最困难的题目:
https://leetcode.cn/problems/minimum-number-of-valid-strings-to-form-target-ii/
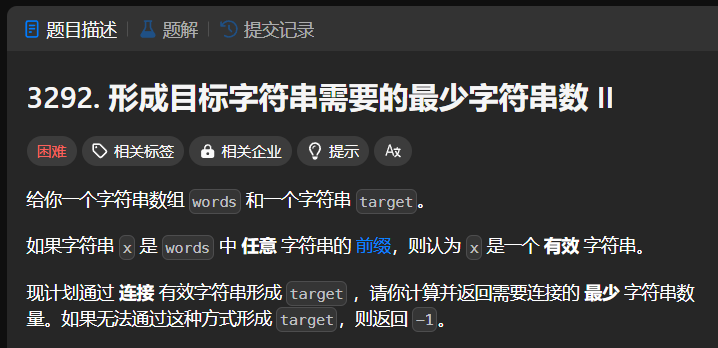
o1模型给出的代码,其运行结果通过了799个测试用例(共807个)
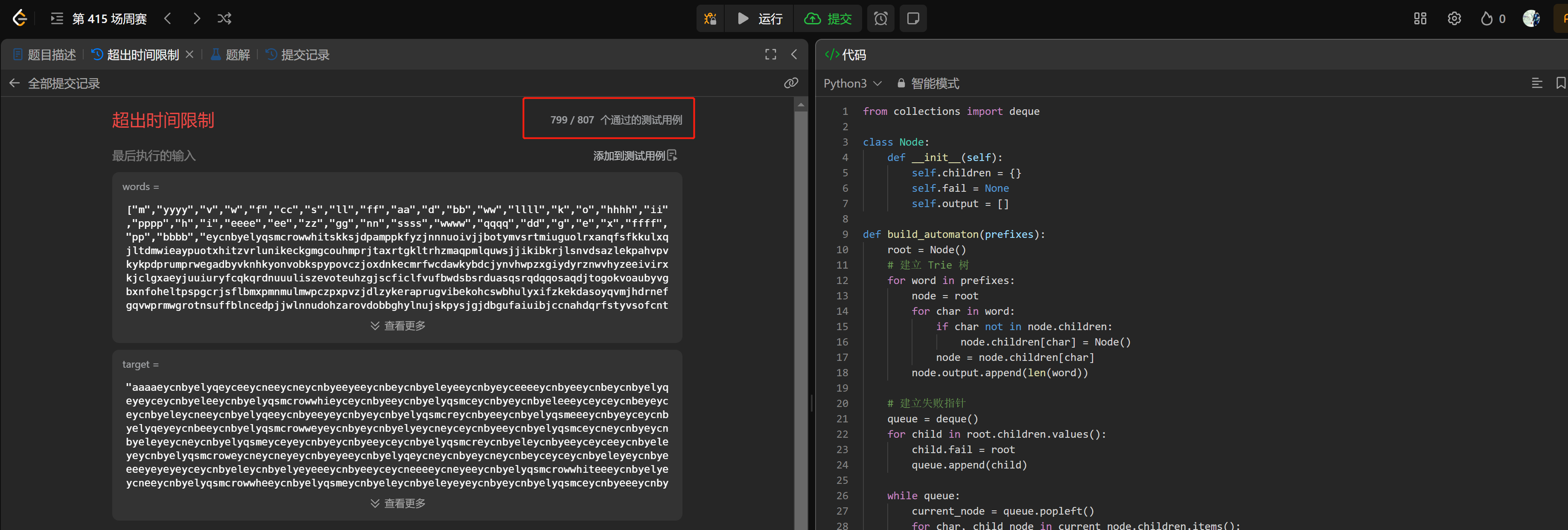
而对于Claude 3.5 Sonnet模型来看,其运行结果则通过了798个测试用例:
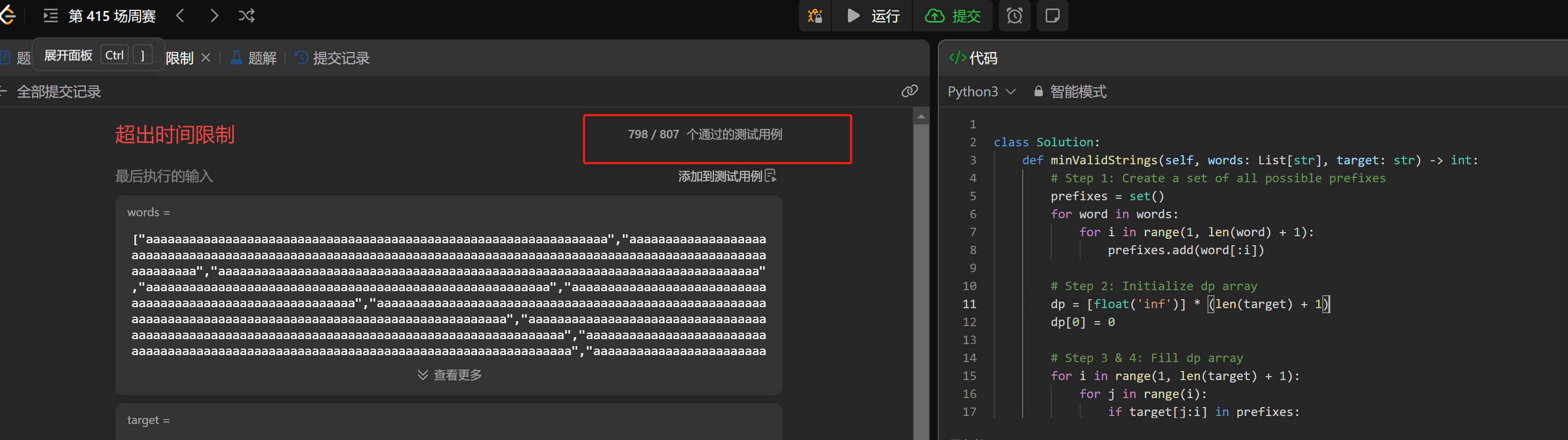
好像两个模型差距并不大。
再来一道困难题目,是第414场周赛的困难题目:
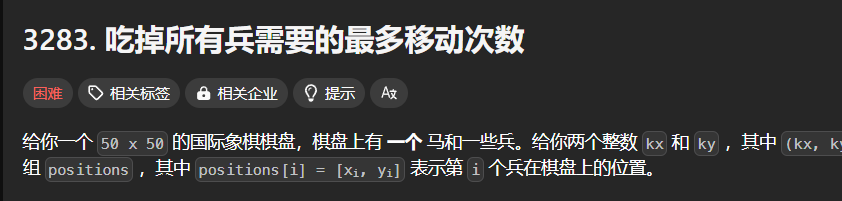
这次o1模型能够一遍就可以成功,而且其执行效率还算可以:
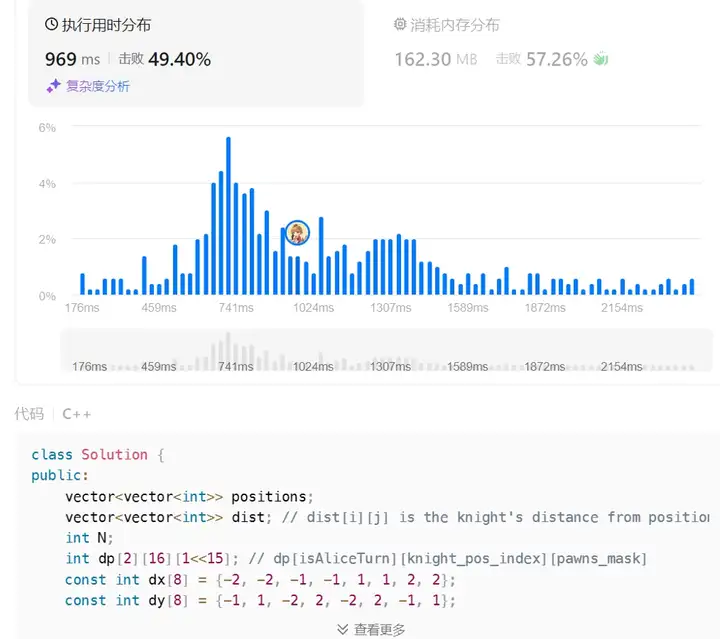
而对于Claude 3.5 Sonnet并没有给出正确的答案。对于GPT4来说,再23年3月份的时候,对于困难的题目只有3/45的准确率,这也是在一定程度上说明了o1模型推理能力确实提升了不少。
数学能力测试
Reddit用户@FitAirline8359用高中的数学期末考试题去测试o1模型的效果,结果还是很不错的。
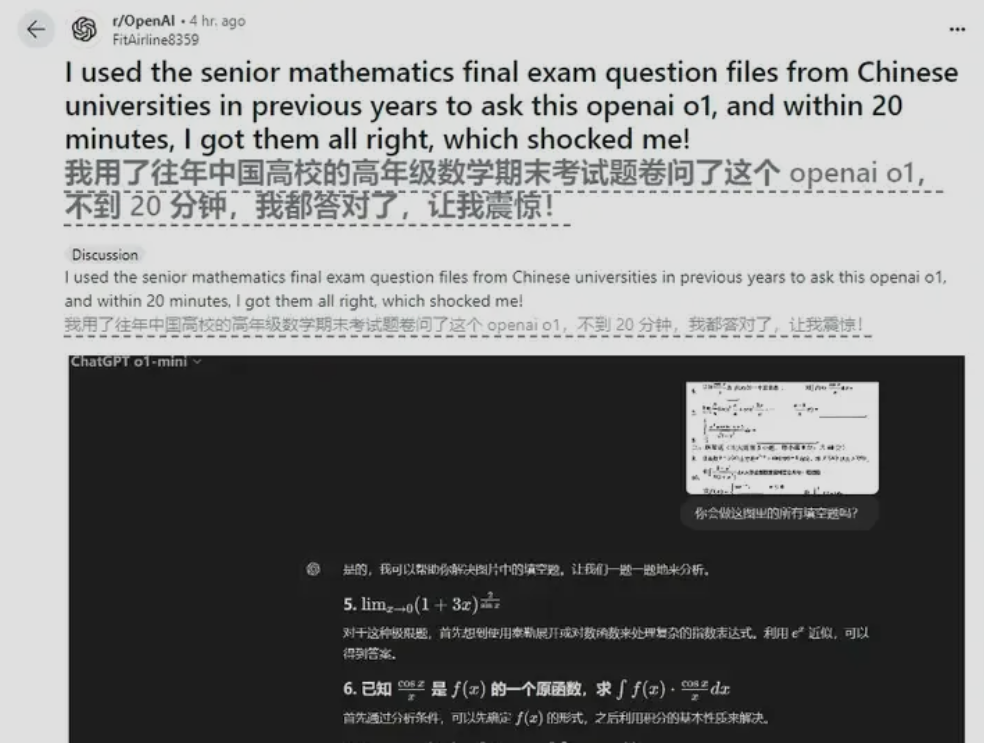
他利用图像转文字工具将试卷转化为文本,再让OpenAI o1解答。结果,短短20分钟内,OpenAI o1就准确解答了所有题目。

这证明了OpenAI o1在处理数学问题上具有优秀能力,可能成为未来教育学习的有力工具。
而有人也拿高考题对o1大模型进行测试,其做高考题的水平确实取得了比较长足的进步。

总结
o1模型的发布,预示着隐式化的COT生成和Post-training Scaling Laws能够有效提升大模型的能力,相信国内外的各个公司应该会在短期内跟进这一技术,毕竟OpenAI已经证明了这条路的可行性。不得不说,OpenAI每次发布的新模型确实能够让人眼前一亮,尽管它的技术不一定是最新(很多技术都是之前已有的),但是它把各个技术的融合在一起的能力确认没得说。
目前发布的这个o1虽然在全面性上肯定比不上GPT-4o,但是其强大的推理能力说明它具有其他模型比不了的地方。何况现在各家大模型同质化这么严重,此时推出o1模型能够重新稳固OpenAI在大模型的领先地位。这一次,可能一个新的时代要到来。
参考:
1.https://www.zhihu.com/question/666992879/answer/3625268162
3.https://www.zhihu.com/question/666991594/answer/3624060495
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号