Scrapy 爬取北京公交相关信息
原创

前提准备
- 数据库建表
-- 使用数据库并建表
use studb;
DROP TABLE IF EXISTS `stu_businfo`;
CREATE TABLE `stu_businfo` (
`id` int NOT NULL AUTO_INCREMENT,
`bus_name` text,
`bus_type` text,
`bus_time` text,
`ticket` text,
`gongsi` text,
`gengxin` text,
`licheng` text,
`wang_info` text,
`wang_buff` text,
`fan_info` text,
`fan_buff` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=142 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;- dos-cmd创建scrapy项目
# 创建一个 Scrapy 项目
scrapy startproject beibus
# 在项目中生成一个爬虫,指定域名
scrapy genspider bei_bus beijing.8684.cn框架理解
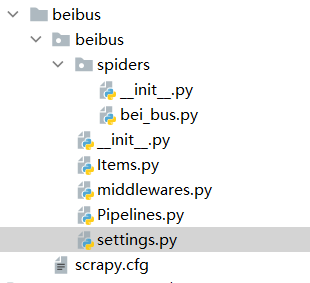
spiders:放置spider代码的目录,用于编写用户自定义的爬虫
items.py:项目中的item文件,用于定义用户要抓取的字段
pipelines.py:管道文件,当spider抓取到数据以后,这些信息在这里会被重新分配
settings.py:项目的设置文件,用来设置爬虫的默认信息,及相关功能的开启与否
middlewares.py:主要是对功能的拓展,用于用户添加一些自定义的功能
- 我们主要针对
settings 、pipelines、 items、 spiders.bei_bus进行对应程序的设置
程序
settings.py
BOT_NAME = "beibus"
# TODO 默认属性
SPIDER_MODULES = ["beibus.spiders"]
NEWSPIDER_MODULE = "beibus.spiders"
# TODO 使爬虫不遵循Robots协议
ROBOTSTXT_OBEY = False
# TODO 解除注释,添加User-Agent属性
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
# TODO 解除注释,并将其中的内容改为如下:
# TODO 解除注释,并将其中的内容改为如下:
ITEM_PIPELINES = {
"beibus.Pipelines.CSVPipeline": 200,
"beibus.Pipelines.MySQLPipelines": 300,
} # 数字代表优先级,数字越小,优先级越高
# TODO 默认属性
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# TODO 数据库相关参数
DB_HOST = "192.168.10.30"
DB_USER = "root"
DB_PWD = "000000"
DB = "studb"
DB_CHARSET = 'utf8'Items.py
import scrapy
class BeibusItem(scrapy.Item):
"""
TODO BeibusItem 类用于定义爬取的公交信息数据结构。
该类继承自 scrapy.Item,允许我们定义要提取的字段。
每个字段对应于公交信息的不同属性。
"""
# TODO 公交名称
bus_name = scrapy.Field()
# TODO 公交类型
bus_type = scrapy.Field()
# TODO 公交的运营时间
bus_time = scrapy.Field()
# TODO 公交票价
ticket = scrapy.Field()
# TODO 公交公司名称
gongsi = scrapy.Field()
# TODO 公交信息的最后更新时间
gengxin = scrapy.Field()
# TODO 公交的行驶里程
licheng = scrapy.Field()
# TODO 往程信息
wang_info = scrapy.Field()
# TODO 往程的具体路线
wang_buff = scrapy.Field()
# TODO 返程信息
fan_info = scrapy.Field()
# TODO 返程的具体路线
fan_buff = scrapy.Field()Pipelines.py
import pymysql
import csv
from . Items import BeibusItem
from . import settings
class CSVPipeline(object):
# TODO 初始化参数
def __init__(self):
self.csvfile = open('stu_businfo.csv', 'w', newline='', encoding='utf-8')
# TODO 创建一个示例 Item 对象以获取字段名
example_item = BeibusItem()
self.csv_writer = csv.DictWriter(self.csvfile, fieldnames=list(example_item.fields.keys()))
self.csv_writer.writeheader()
# TODO spider联系上下文
def process_item(self, item, spider):
self.csv_writer.writerow(dict(item)) # TODO 将 Item 转换为字典
return item
# TODO 关闭连接
def close_spider(self, spider):
self.csvfile.close()
class MySQLPipelines(object):
# TODO 初始化参数
def __init__(self):
self.host = settings.DB_HOST
self.user = settings.DB_USER
self.pwd = settings.DB_PWD
self.db = settings.DB
self.charset = settings.DB_CHARSET
self.connect()
# TODO 数据库连接
def connect(self):
self.conn = pymysql.connect(host=self.host,
user=self.user,
password=self.pwd,
db=self.db,
charset=self.charset)
self.cursor = self.conn.cursor()
# TODO 向数据库中插入数据,spider联系上下文
def process_item(self, item , spider):
sql = ('INSERT INTO stu_businfo '
'(bus_name, bus_type, bus_time, ticket, gongsi, gengxin, licheng, wang_info, wang_buff, fan_info, fan_buff) '
'VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)')
self.cursor.execute(sql, (
item['bus_name'], item['bus_type'], item['bus_time'], item['ticket'],
item['gongsi'], item['gengxin'], item['licheng'], item['wang_info'],
item['wang_buff'], item['fan_info'], item['fan_buff']
))
self.conn.commit()
return item
# TODO 关闭数据库连接
def close_spider(self):
self.conn.close()
self.cursor.close()bei_bus.py
from scrapy import Spider, FormRequest, Request
from urllib.parse import urljoin
from ..Items import BeibusItem
class BeiBusSpider(Spider):
name = "bei_bus" # TODO 爬虫的名称,Scrapy 通过该名称识别爬虫
allowed_domains = ["beijing.8684.cn"] # TODO 允许爬取的域名
start_url = "https://beijing.8684.cn" # TODO 爬虫的起始 URL
def start_requests(self):
# TODO 生成请求,爬取前 9 页公交信息
for page in range(9):
# TODO 构建每一页的 URL,页码从 1 开始
url = "{url}/list{page}".format(url=self.start_url, page = (page + 1))
# TODO 使用 FormRequest 发送请求,并指定回调函数
yield FormRequest(url, callback=self.parse_index)
def parse_index(self, response):
# TODO 从响应中提取公交信息的链接
beijingbus = response.xpath('//div[@class="list clearfix"]/a//@href').extract()
for href in beijingbus:
# TODO 将相对链接转换为绝对链接
url2 = urljoin(self.start_url, href)
# TODO 发送请求到公交详细信息页面,并指定回调函数
yield Request(url2, callback=self.parse_detail)
def parse_detail(self, response):
# TODO 解析公交详细信息页面,提取所需数据
bus_name = response.xpath("//div[@class='info']//span/@aria-label").get() or "None" # 获取公交名称
bus_type = response.xpath("//h1[@class='title']//a/text()").get() or "None" # 获取公交类型
# TODO 获取公交信息列表
bus_info = response.xpath("//ul[@class='bus-desc']//li/text()").getall()[:-1]
bus_time = bus_info[0] if len(bus_info) > 0 else "None" # 获取公交时间
ticket = bus_info[1] if len(bus_info) > 1 else "None" # 获取票价
# TODO 获取公司名称,若不存在则返回 "None"
gongsi = response.xpath("//ul[@class='bus-desc']//li//a/@title").get() or "None"
# TODO 获取更新信息,若不存在则返回 "None"
gengxin = response.xpath("//ul[@class='bus-desc']//li//span/text()").getall()[1] if len(response.xpath("//ul[@class='bus-desc']//li//span/text()").getall()) > 1 else "None"
# TODO 获取里程信息,若不存在则返回 "None"
licheng = response.xpath("//div[@class='change-info mb20']//text()").get() or "None"
# TODO 获取往返路线列表
wang_fan_load_list = response.xpath("//div[@class='bus-lzlist mb15']//ol//a/text()").getall()
wang_info = response.xpath("//div[@class='trip']/text()").get() or "None" # 获取往程信息
# TODO 获取往程的具体路线,若不存在则返回 "None"
wang_buff = ",".join(wang_fan_load_list[:(len(wang_fan_load_list) // 2)]) or "None"
# TODO 获取返程信息
fan_info = response.xpath("//div[@class='trip']/text()").getall()[1] if len(response.xpath("//div[@class='trip']/text()").getall()) > 1 else "None"
# TODO 获取返程的具体路线
fan_buff = ",".join(wang_fan_load_list[(len(wang_fan_load_list) // 2):]) or "None"
# TODO 创建 BeibusItem 实例用于存储提取的数据
bus_item = BeibusItem()
# TODO 将提取的数据存入 bus_item 中
# TODO bus_item.fields 是 BeibusItem 类中的一个属性,它返回一个字典,字典的键是字段名(字符串形式),值是对应的 Field 实例,每个Field实例就是一个字段名
for field in bus_item.fields:
bus_item[field] = eval(field) # TODO 使用 eval 动态赋值。eval() 函数的作用是将字符串当作 Python 表达式来执行,并返回结果。
yield bus_item # TODO 通过 `yield` 返回给 Scrapy, 触发管道,将数据传递给管道执行
切换至控制台,执行 scrapy crawl bei_bus(指定主程序)

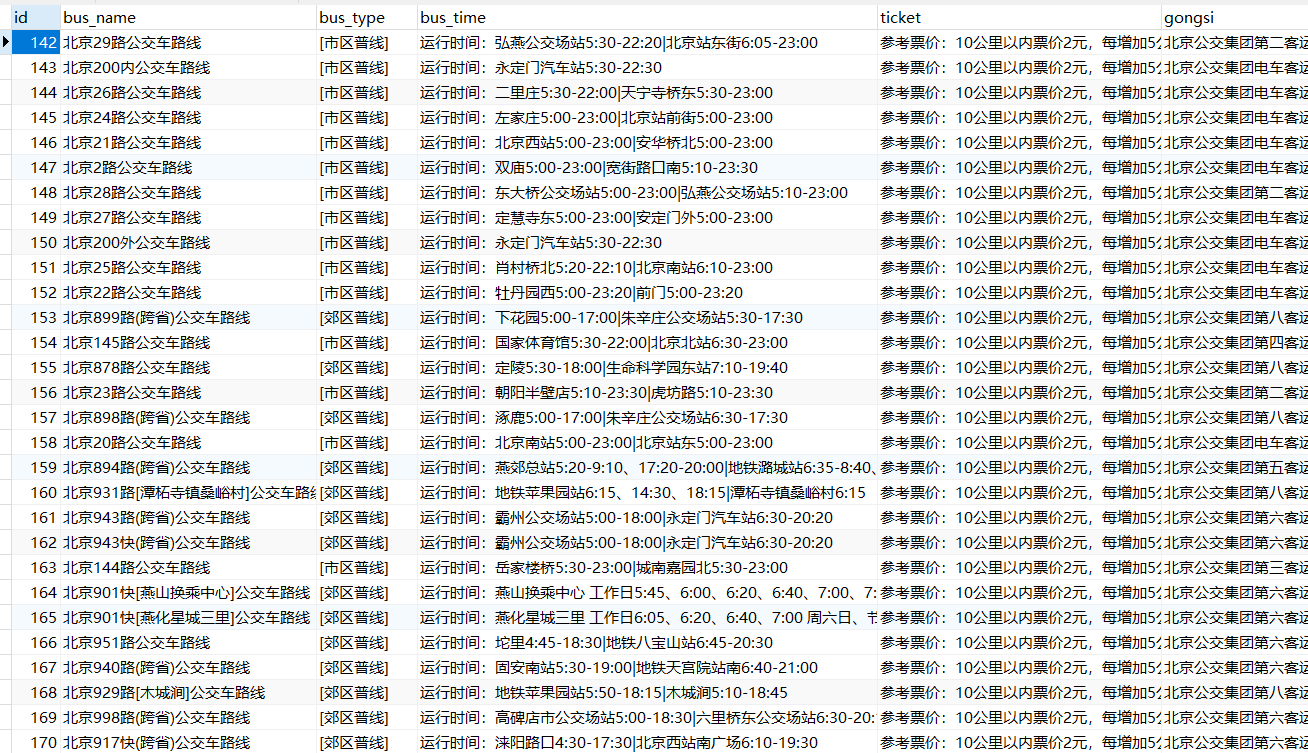
检查结果
- 根目录下生成一个csv文件,如有需要自行查看
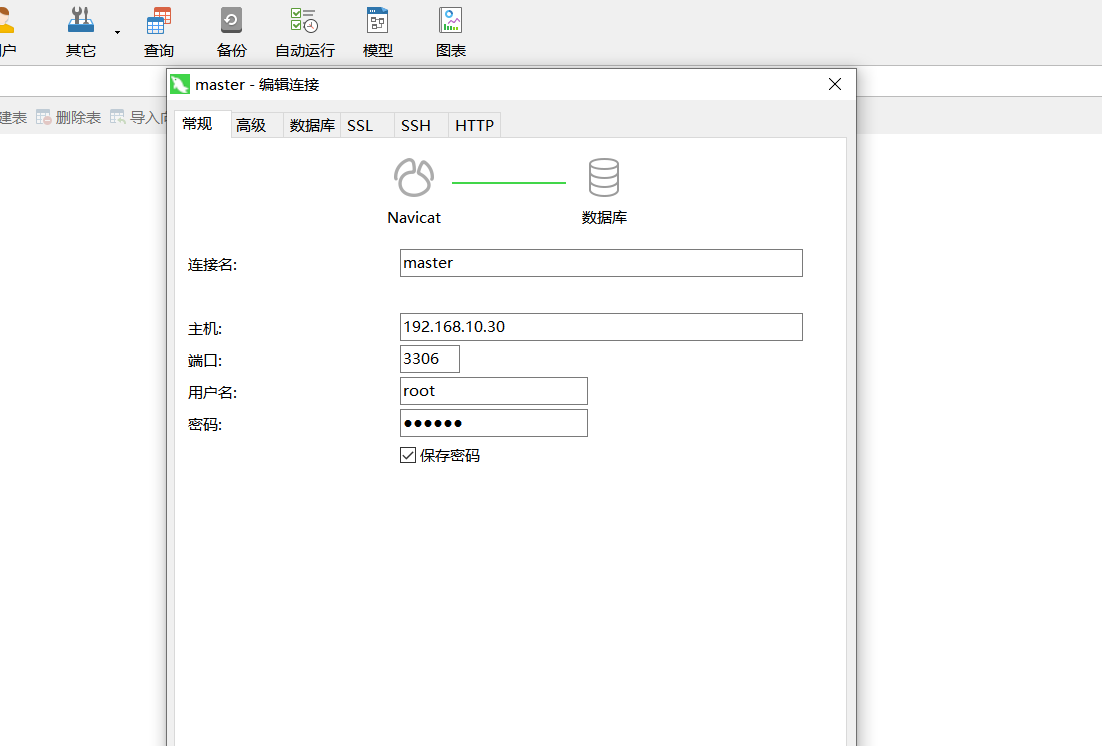
- navicat链接数据库,查看数据
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号