xpath 爬取北京公交相关数据
原创

介绍
此程序使用xpath爬取北京公交路线信息,并且最终将数据存入mysql,爬取时间大概在12分钟左右
思路
- 点击北京公交网: https://beijing.8684.cn/
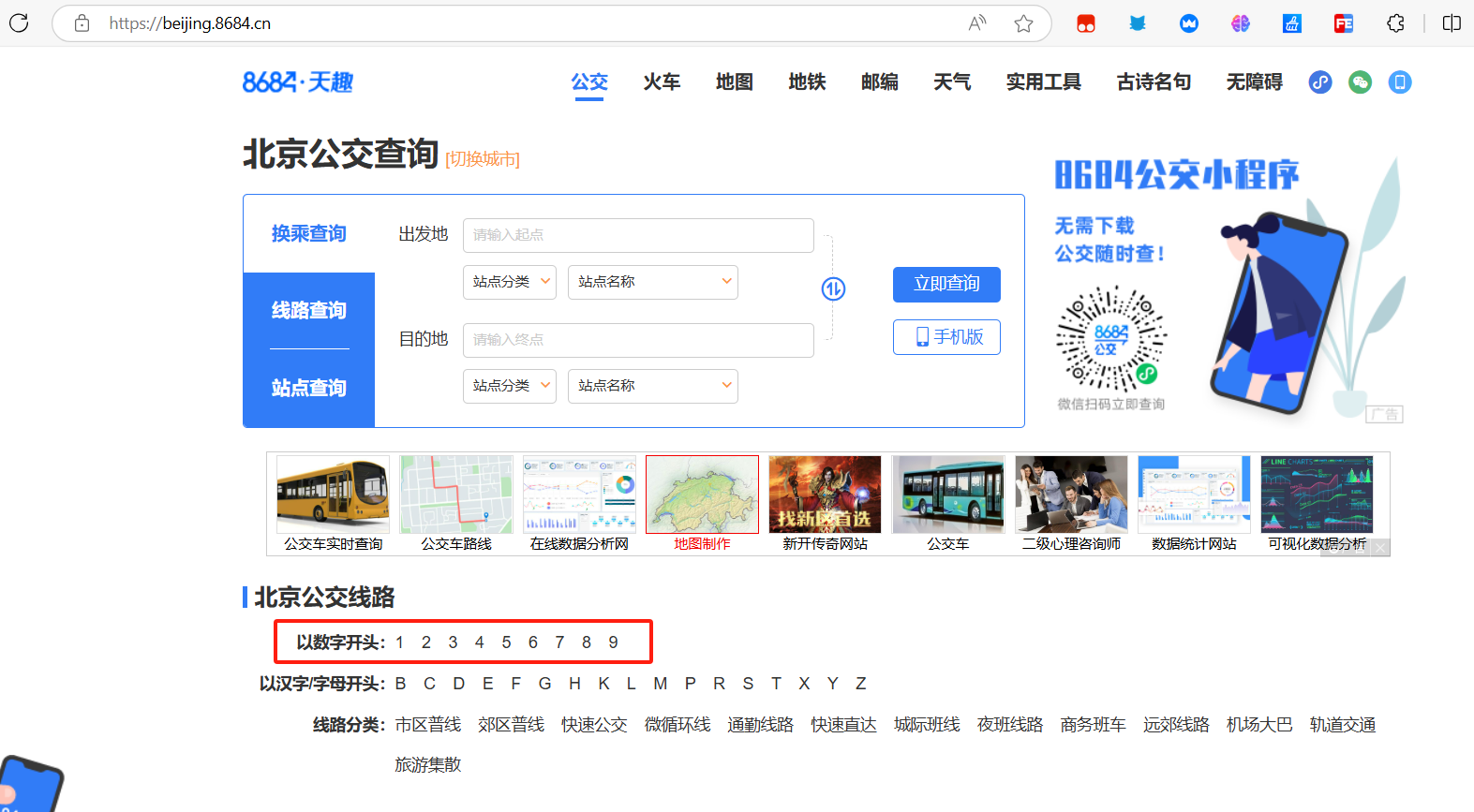
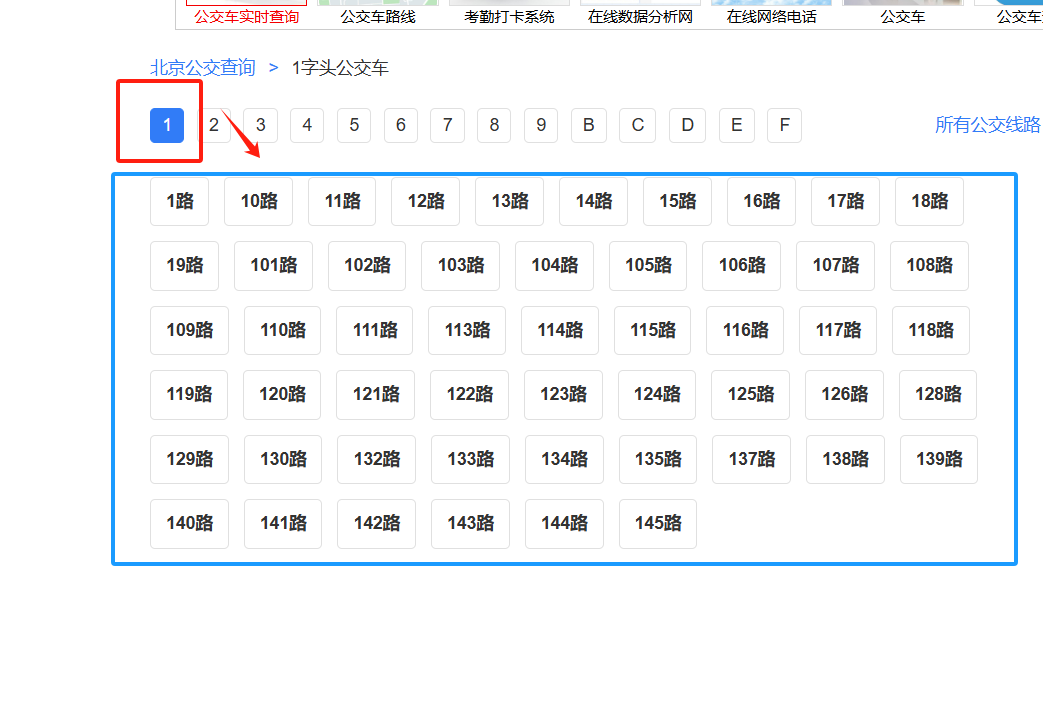
- 我们可以发现北京公交路线有以数字开头和字母开头的区分
- 点击进去可以发现这些数字或字母下面有众多线路
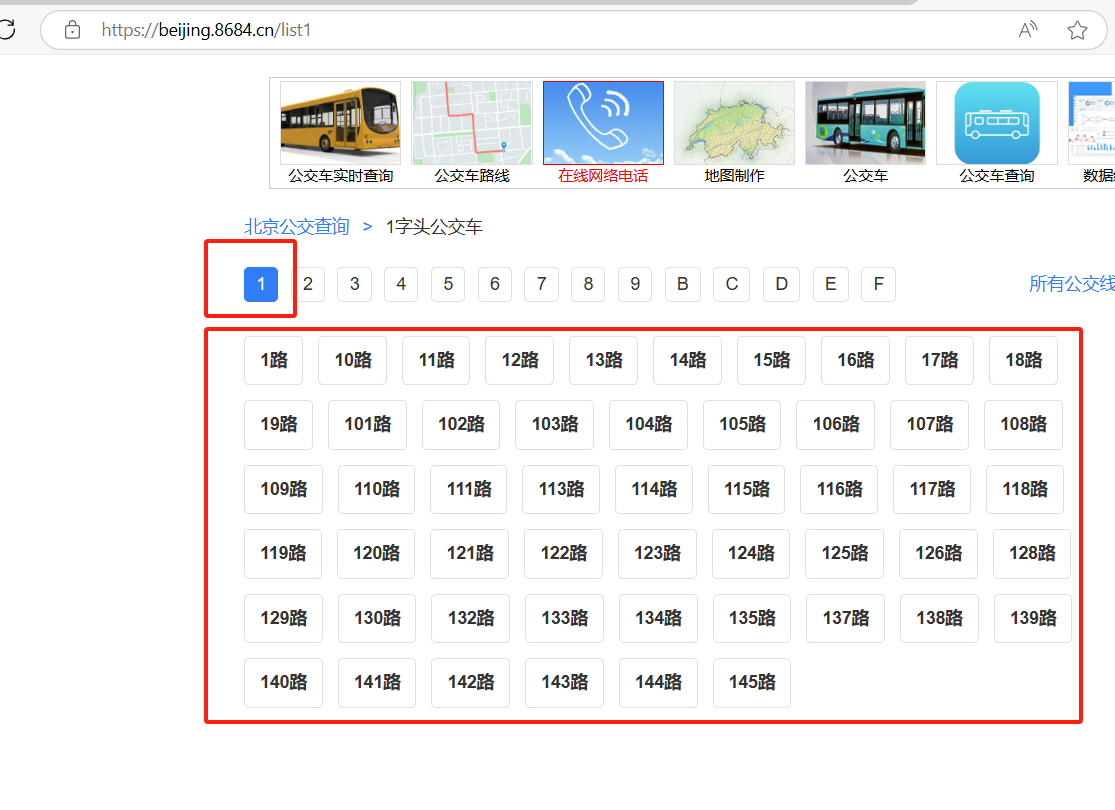
- 仔细观察可以发现这些数字或字母对应的网址是有规律的:https://beijing.8684.cn/list
n - 这个n分别是对应的数字和字母
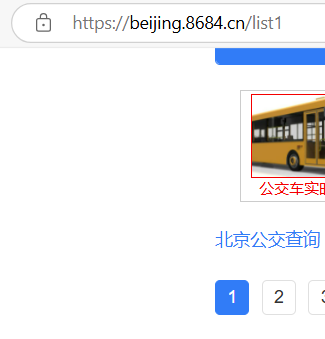
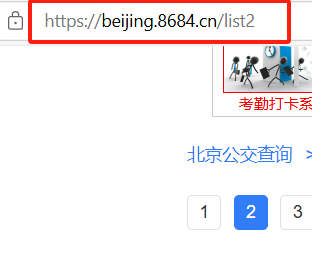
- 因此我们可以使用简单的循环以及字符串特点将这些网址编写出来
# 公交信息的基础 URL
url = 'https://beijing.8684.cn'
url_template = url + '/list{}'
# 生成要爬取的公交 URL 列表
bus_url_list_test = [i for i in range(1, 10)] # 修改范围以获取更多公交列表
bus_url_list = []
for num in bus_url_list_test:
urls = url_template.format(num)
bus_url_list.append(urls)- 此后,我们可以使用xpath技术对这些网址进行解析,获取每个网址对应的详细路线图网址
# 准备一个列表来存储每个公交详情的 URL
bus_load_num_list = []
# 从列表页面收集每个公交详情的 URL
for bul in bus_url_list:
response = requests.get(bul, headers=header) # 向每个公交列表页面发送请求
content = response.content.decode('utf-8')
html = etree.HTML(content)
# 使用 XPath 提取公交详情链接
bus_href_list = html.xpath("//div[@class='list clearfix']//a/@href")
for bus_href in bus_href_list:
url_str = url + bus_href
bus_load_num_list.append(url_str) # 将完整 URL 添加到列表中- 然后再根据这些详细路线图网址进行解析出对应的数据
完整程序
爬取公交数据至当前目录下的txt文件
import requests
from lxml import etree
from time import sleep
# 定义请求头,以模拟浏览器请求
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
# 公交信息的基础 URL
url = 'https://beijing.8684.cn'
url_template = url + '/list{}'
# 生成要爬取的公交 URL 列表
bus_url_list_test = [i for i in range(1, 10)] # 修改范围以获取更多公交列表
bus_url_list = []
for num in bus_url_list_test:
urls = url_template.format(num)
bus_url_list.append(urls)
# 准备一个列表来存储每个公交详情的 URL
bus_load_num_list = []
# 从列表页面收集每个公交详情的 URL
for bul in bus_url_list:
response = requests.get(bul, headers=header) # 向每个公交列表页面发送请求
content = response.content.decode('utf-8')
html = etree.HTML(content)
# 使用 XPath 提取公交详情链接
bus_href_list = html.xpath("//div[@class='list clearfix']//a/@href")
for bus_href in bus_href_list:
url_str = url + bus_href
bus_load_num_list.append(url_str) # 将完整 URL 添加到列表中
# 遍历每个公交详情 URL 以获取信息
for bln in bus_load_num_list:
try:
response = requests.get(bln, headers=header) # 请求详细的公交信息
content = response.content.decode('utf-8')
html = etree.HTML(content)
# 使用 XPath 提取公交信息
bus_name = html.xpath("//div[@class='info']//span/@aria-label")
bus_type = html.xpath("//h1[@class='title']//a/text()")
bus_info = html.xpath("//ul[@class='bus-desc']//li/text()")[:-1]
bus_time = bus_info[0]
ticket = bus_info[1:]
gongsi = html.xpath("//ul[@class='bus-desc']//li//a/@title")
gengxin = html.xpath("//ul[@class='bus-desc']//li//span/text()")
licheng = html.xpath("//div[@class='change-info mb20']//text()")
wang_info = html.xpath("//div[@class='trip']/text()")
fan_info = html.xpath("//div[@class='trip']/text()")[1:]
wang_fan_load_list = html.xpath("//div[@class='bus-lzlist mb15']//ol//a/text()")
# 将加载列表分为去程和返程两部分
wang_buff = wang_fan_load_list[:(len(wang_fan_load_list) // 2)]
fan_buff = wang_fan_load_list[(len(wang_fan_load_list) // 2):]
# 将所有提取的数据放入一个列表
data_list = [
bus_name[0] if bus_name else 'None',
bus_type[0] if bus_type else 'None',
bus_time if bus_time else 'None',
ticket[0] if ticket else 'None',
','.join(gongsi) if gongsi else 'None',
gengxin[1] if len(gengxin) > 1 else 'None',
licheng[0] if licheng else 'None',
wang_info[0] if wang_info else 'None',
','.join(wang_buff) if wang_buff else 'None',
fan_info[0] if fan_info else 'None',
','.join(fan_buff) if fan_buff else 'None'
]
# 将数据写入文件
with open('BeiJing_Bus_Info.txt', 'a', encoding='utf-8') as file:
file.write('@'.join(data_list) + '\n')
# 打印提取的数据
print(f"= = = = = = = = = = = = = = = = = {bus_name[0] if bus_name else '未知数据'} 爬取完成 = = = = = = = = = = = = = = = =")
except Exception as e:
# 如果发生错误,打印错误信息并将 data_list 设置为包含 'None' 的列表
print(f"从 {bln} 获取数据时发生错误: {e}")
data_list = ["None"] * 10 # 假设预期有 10 个字段
print(f"= = = = = = = = = = = = = = = = = 未知数据 爬取失败 = = = = = = = = = = = = = = = =")
sleep(1) # 暂停 1 秒以避免对服务器造成过大压力数据样式:

将txt文件转为csv文件
此步骤只为方便预览数据,可有可无
import csv
# 读取数据文本文件
with open('BeiJing_Bus_Info.txt', 'r', encoding='utf-8') as infile:
data = infile.readlines()
# 处理数据并写入CSV文件
with open('BeiJing_Bus_Info.csv', 'w', encoding='utf-8', newline='') as outfile:
csv_writer = csv.writer(outfile)
for line in data:
# 以@为分隔符分割每一行
row = line.strip().split('@')
# 写入CSV文件
csv_writer.writerow(row)
print("数据已成功写入 BeiJing_Bus_Info.csv")数据样式:

将txt文件导入mysql
# 登录mysql
# 建库
CREATE DATABASE `studb` DEFAULT CHARACTER SET utf8mb3;
# 建表
CREATE TABLE `stu_businfo` (
`id` int NOT NULL AUTO_INCREMENT,
`bus_name` varchar(1000) DEFAULT 'None',
`bus_type` varchar(1000) DEFAULT 'None',
`bus_time` varchar(1000) DEFAULT 'None',
`ticket` varchar(1000) DEFAULT 'None',
`gongsi` varchar(1000) DEFAULT 'None',
`gengxin` varchar(1000) DEFAULT 'None',
`licheng` varchar(1000) DEFAULT 'None',
`wang_info` varchar(1000) DEFAULT 'None',
`wang_buff` varchar(1000) DEFAULT 'None',
`fan_info` varchar(1000) DEFAULT 'None',
`fan_buff` varchar(1000) DEFAULT 'None',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
# 将文件拷贝一份至相应位置
cp BeiJing_Bus_Info.txt /var/lib/mysql-files/
# 将txt文件数据导入mysql
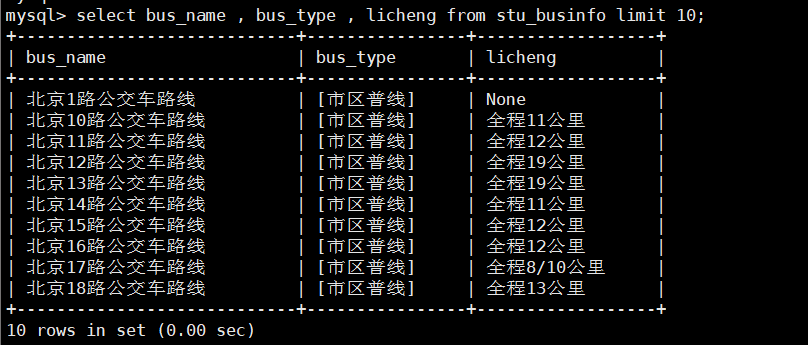
LOAD DATA INFILE '/var/lib/mysql-files/BeiJing_Bus_Info.txt' INTO TABLE stu_businfo FIELDS TERMINATED BY '@' LINES TERMINATED BY '\n' (bus_name,bus_type,bus_time,ticket,gongsi,gengxin,licheng,wang_info,wang_buff,fan_info,fan_buff);查看结果
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号